CoRL 2020奖项公布,斯坦福获最佳论文奖,华为等摘得最佳系统论文奖
机器之心报道
CoRL 2020 于 11 月 16-18 日线上举行,并颁发了多个奖项。来自斯坦福大学和弗吉尼亚理工的研究者摘得本届 CoRL 会议的最佳论文奖,华为诺亚方舟实验室和上海交大等机构学者荣获最佳系统论文奖,南加州大学研究获得最佳 Presentation 奖。

昨日,第四届机器人学习大会(CoRL)公布了最佳论文奖、最佳系统论文奖等奖项。来自斯坦福大学和弗吉尼亚理工学院的研究《Learning Latent Representations to Influence Multi-Agent Interaction》获得 CoRL 2020 最佳论文奖,最佳系统论文则由华为诺亚方舟实验室、上海交大和伦敦大学学院合作的《SMARTS: Scalable Multi-Agent Reinforcement Learning Training School for Autonomous Driving》摘得,南加州大学论文《Accelerating Reinforcement Learning with Learned Skill Priors》获得了最佳 Presentation 奖。
自 2017 年首次举办以来,CoRL 迅速成为机器人学与机器学习交叉领域的全球顶级学术会议之一。CoRL 是面向机器人学习研究的 single-track 会议,涵盖机器人学、机器学习和控制等多个主题,包括理论与应用。
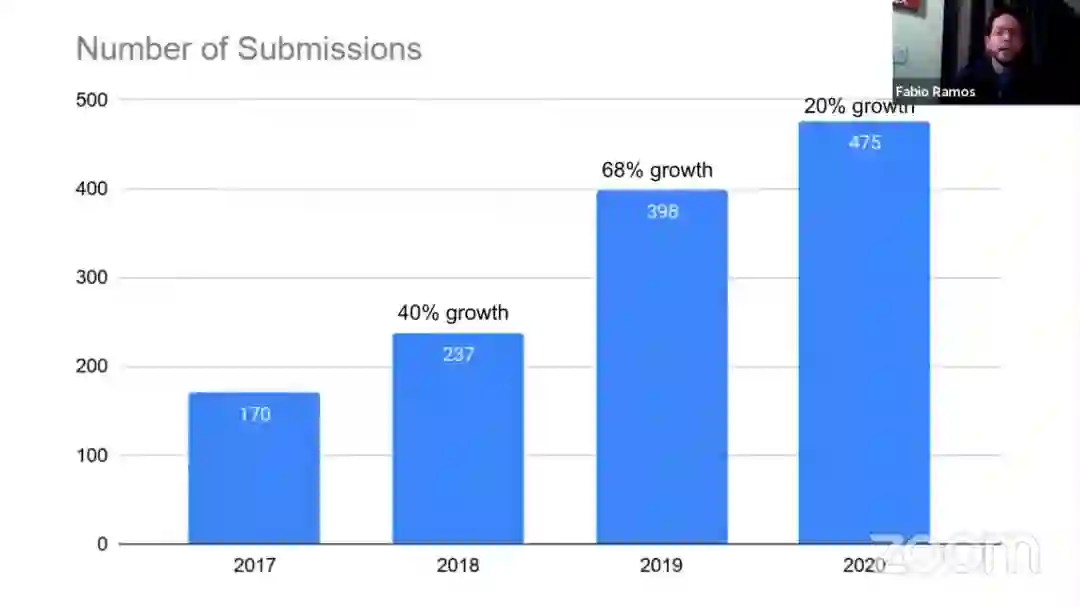
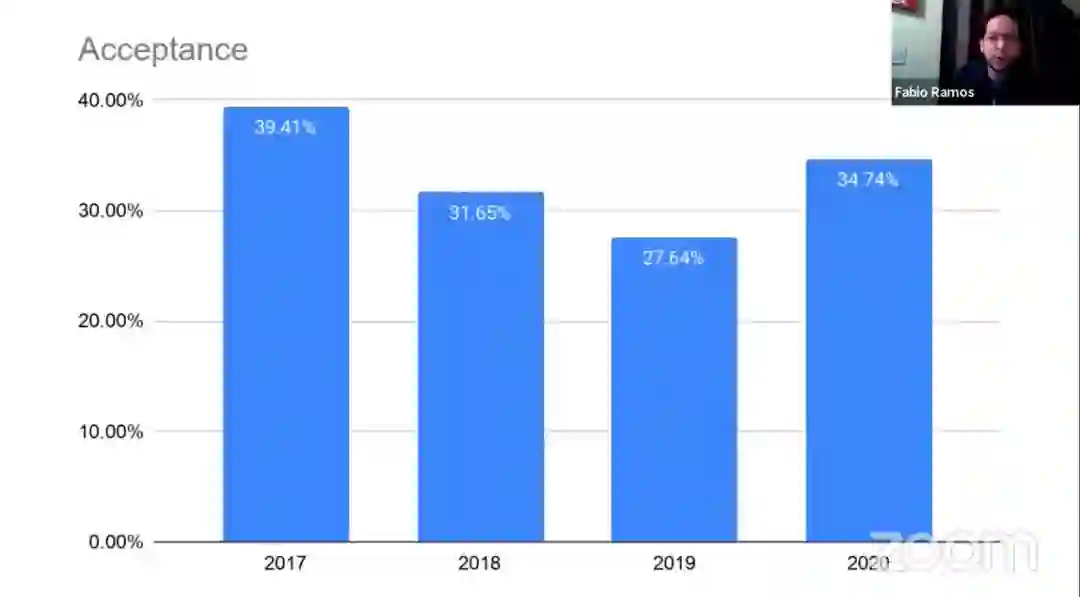
CoRL 2020 共收到论文 475 篇,相比 2019 年增长了 20%;接收论文 165 篇,接收率为 34.7%,高于去年的 27.6%。
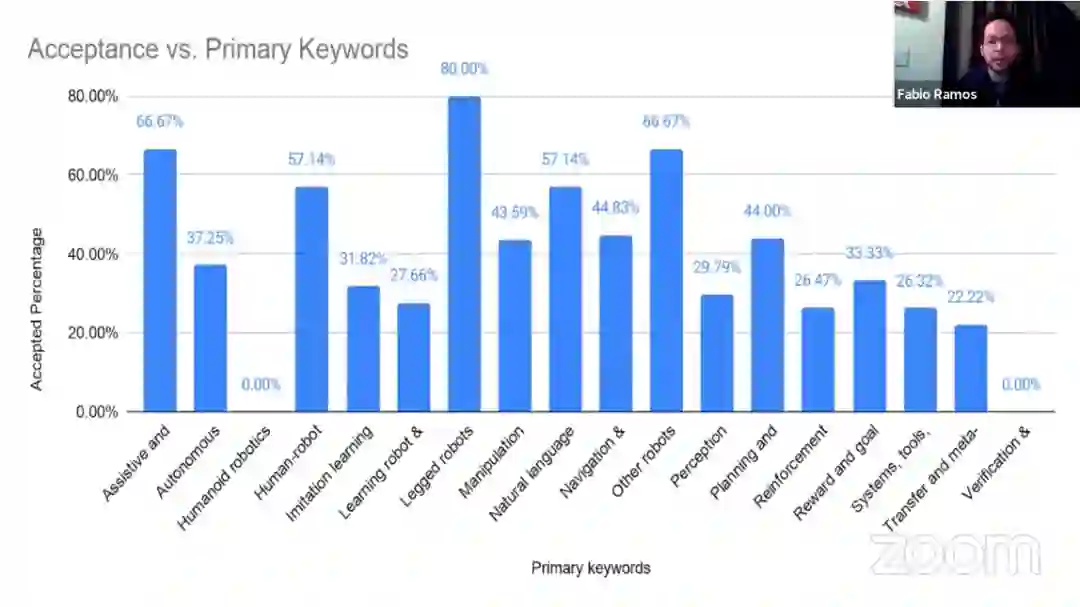
会议还公布了包含主要关键词(如 legged robots、perception 等)的论文接收率,参见下图:
最佳论文奖
CoRL 2020 颁发了最佳论文奖,来自斯坦福大学和弗吉尼亚理工大学的研究者合作的论文获得该奖项。大会认为这篇论文是「为包括物理机器人环境在内的多个领域中的难题提供了令人信服的解决方案」。

论文:Learning Latent Representations to Influence Multi-Agent Interaction
论文链接:https://arxiv.org/pdf/2011.06619.pdf
作者:Annie Xie、Dylan P. Losey、Ryan Tolsma、Chelsea Finn、Dorsa Sadigh
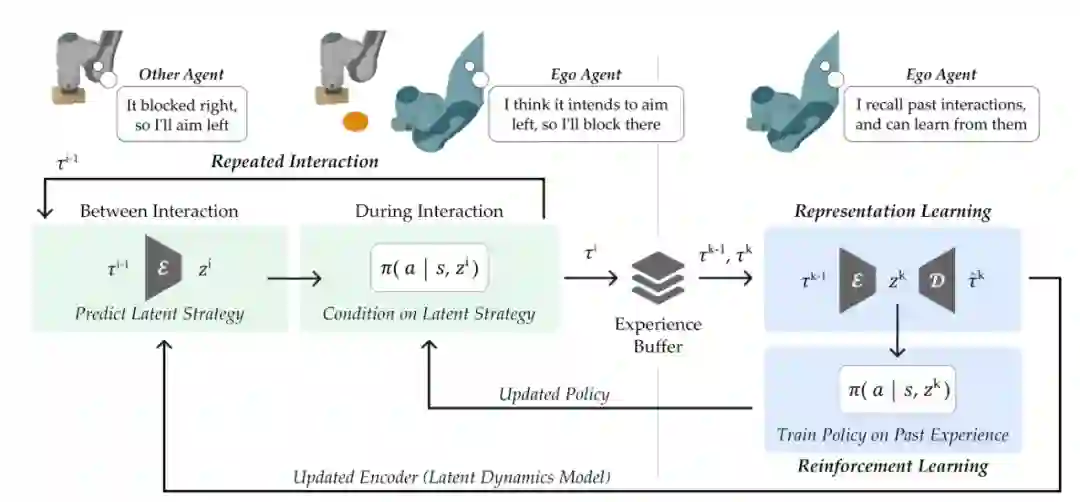
摘要:与机器人进行无缝交互非常困难,因为智能体是不稳定的。它们会根据 ego 智能体的行为更新策略,ego 智能体必须预见到可能的变化才能做到共同适应(co-adapt)。受人类行为的启发,研究者认识到机器人不需要明确地建模其他智能体将执行的每一个低级操作。相反,它可以通过高级表示来捕获其他智能体的潜在策略。
该研究提出一个基于强化学习的框架,用来学习智能体策略的潜在表示,其中 ego 智能体确定其行为与另一智能体未来策略之间的关系。然后 ego 智能体利用这些潜在动态来影响其他智能体,有目的地指导制定适合共同适应的策略。在多个模拟域和现实世界曲棍球游戏中,该方法优于其他方法,并学会影响其他智能体。
最佳论文入围名单
此次会议共有四篇论文入围最佳论文奖项,除了最终得奖的论文以外,其他三篇分别是:
-
论文:Guaranteeing Safety of Learned Perception Modules via Measurement-Robust Control Barrier Functions -
链接:https://arxiv.org/pdf/2010.16001.pdf -
作者:Sarah Dean, Andrew J. Taylor, Ryan K. Cosner, Benjamin Recht, Aaron D. Ames(加州大学伯克利分校、加州理工学院)
-
论文:Learning from Suboptimal Demonstration via Self-Supervised Reward Regression -
链接:https://arxiv.org/pdf/2010.11723.pdf -
作者:Letian Chen, Rohan Paleja, Matthew Gombolay(佐治亚理工学院)
-
论文:Safe Optimal Control Using Stochastic Barrier Functions and Deep Forward-Backward SDEs -
链接:https://arxiv.org/pdf/2009.01196.pdf -
作者:Marcus Aloysius Pereira, Ziyi Wang, Ioannis Exarchos, Evangelos A. Theodorou(佐治亚理工学院、斯坦福大学)

最佳系统论文奖
本届 CoRL 大会的最佳系统论文奖授予了华为诺亚方舟实验室、上海交大和伦敦大学学院研究者联合发布的论文《SMARTS: Scalable Multi-Agent Reinforcement Learning Training School for Autonomous Driving》。在颁奖词中,CoRL 称「该系统完备、考虑周密,为自动驾驶社区带来了强大的潜在影响」。

链接:https://arxiv.org/pdf/2010.09776.pdf
项目地址:https://github.com/huawei-noah/SMARTS.
作者:Ming Zhou、Jun Luo、Julian Villella、Yaodong Yang 等
摘要:多智能体交互是现实世界自动驾驶领域的基础组成部分。经历十几年的研究和发展,如何与多样化场景中各类道路使用者进行高效交互的问题依然未能很好地解决。学习方法可以为解决该问题提供很大帮助,但这些方法需要能够产生多样化和高效驾驶交互的真实多智能体模拟器。
所以,为了满足这种需求,来自华为诺亚方舟实验室、上海交大和伦敦大学学院的研究者开发了一个名为 SMARTS(Scalable Multi-Agent RL Training School)的专用模拟平台,该平台支持多样化道路使用者行为模型的训练、积累和使用。这些反过来又可以用于创建日益真实和多样化的交互,从而能够对多智能体交互进行更深更广泛的研究。
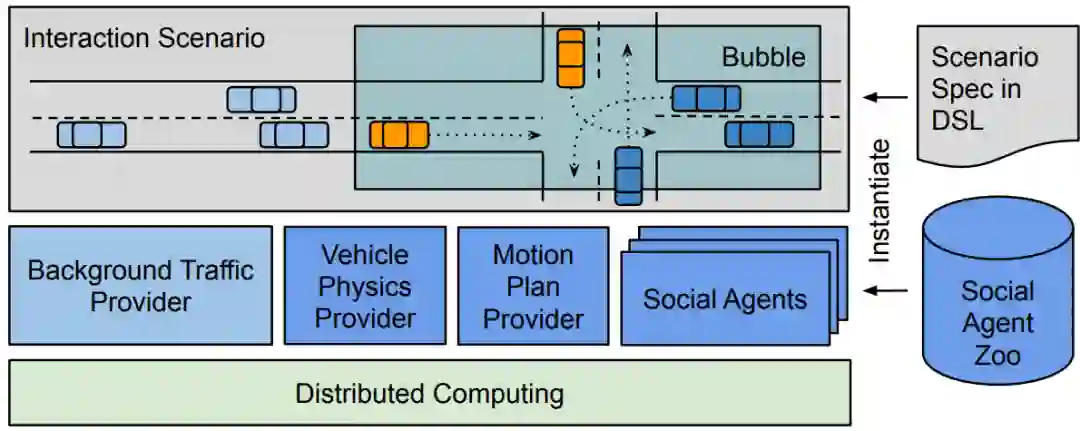
SMARTS 架构示意图。
此外,研究者描述了 SMARTS 的设计目标,解释了它的基本架构以及关键特征,并通过交互场景中具体的多智能体实验阐释了其使用流程。研究者还开源了 SMARTS 平台以及相关的基准任务和评估指标,以鼓励和推进自动驾驶领域多智能体学习的更多研究。
最佳系统论文奖入围论文
本届 CoRL 大会入围最佳系统论文奖的一篇论文是加州大学伯克利分校学者的《DIRL: Domain-Invariant Representation Learning for Sim-to-Real Transfer》。

链接:http://www.ajaytanwani.com/docs/Tanwani_DIRL_CORL_CR_2020.pdf
作者:Ajay Kumar Tanwani
最佳 Presentation 奖
会议还公布了最佳 Presentation 奖项,从所有 oral presentation 论文中选出了三篇入围论文,最终来自南加州大学的研究获得了该奖项。
论文:Accelerating Reinforcement Learning with Learned Skill Priors
链接:https://arxiv.org/pdf/2010.11944.pdf
作者:Karl Pertsch、Youngwoon Lee、Joseph J. Lim(南加州大学)

智能体在学习新任务时严重依赖之前的经验,大部分现代强化学习方法从头开始学习每项任务。利用先验知识的一种方法是将在之前任务中学到的技能迁移到新任务中。但是,随着之前经验的增加,需要迁移的技能也有所增多,这就对在下游学习任务中探索全部可用技能增加了挑战性。还好,直观来看,并非所有技能都需要用相等的概率进行探索,例如当前状态可以提示需要探索的技能。
南加州大学的这项研究提出了一个深度潜变量模型,可以联合学习技能的嵌入空间和来自离线智能体经验的技能先验。研究者将常见的最大熵强化学习方法进行扩展,以使用技能先验引导下游学习。
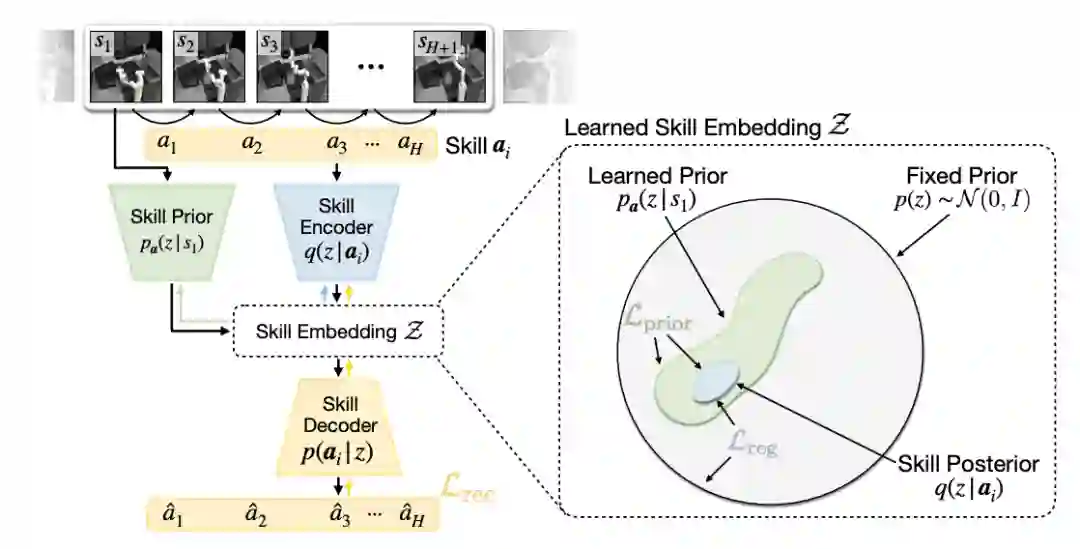
该研究在复杂的导航和机器人操作任务中对提出的方法 SPiRL (Skill-Prior RL) 进行验证,结果表明学得的技能先验对于从丰富数据集上进行高效技能迁移是必要的。
研究人员放出了其官方 PyTorch 实现,代码地址:https://github.com/clvrai/spirl。
项目主页:https://clvrai.github.io/spirl/
最佳 Presentation 奖入围论文
除最终获奖的南加州大学论文以外,另外两篇入围论文分别来自 Uber ATG 团队、多伦多大学与谷歌。
论文:Universal Embeddings for Spatio-Temporal Tagging of Self-Driving Logs
链接:https://arxiv.org/pdf/2011.06165.pdf
作者:Sean Segal、Eric Kee、Wenjie Luo、Abbas Sadat、Ersin Yumer、Raquel Urtasun(Uber ATG 团队、多伦多大学)
论文:Transporter Networks: Rearranging the Visual World for Robotic Manipulation
链接:https://arxiv.org/pdf/2010.14406.pdf
作者:Andy Zeng, Pete Florence, Jonathan Tompson, Stefan Welker, Jonathan Chien Maria Attarian, Travis Armstrong, Ivan Krasin, Dan Duong Vikas Sindhwani, Johnny Lee(Robotics at Google)

CoRL 2020 论文展示视频和直播参见:https://www.youtube.com/c/conferenceonrobotlearning
参考链接:https://syncedreview.com/2020/11/17/conference-on-robot-learning-corl-2020-underway-best-paper-finalists-announced/
Amazon SageMaker 1000元大礼包
点击阅读原文,填写表单后我们将与你联系,为你完成礼包充值。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com




