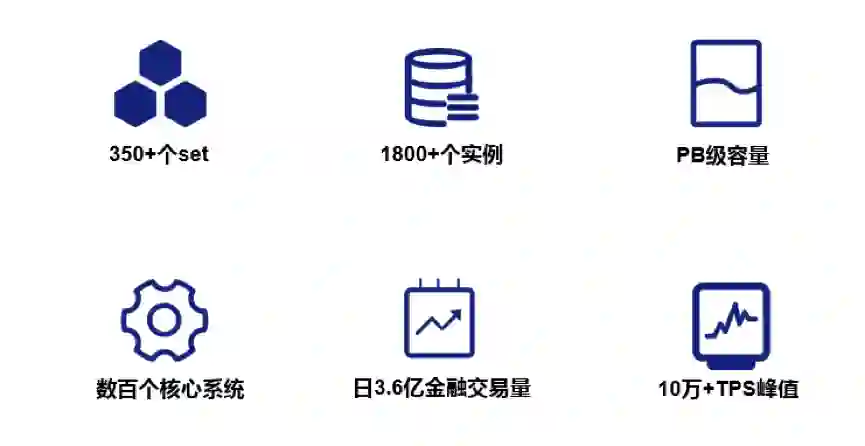
金融级数据库 TDSQL:已支持日 3.6亿+ 的交易量,TPS 10万+
2014年:基于分布式的基础架构
Why TDSQL?
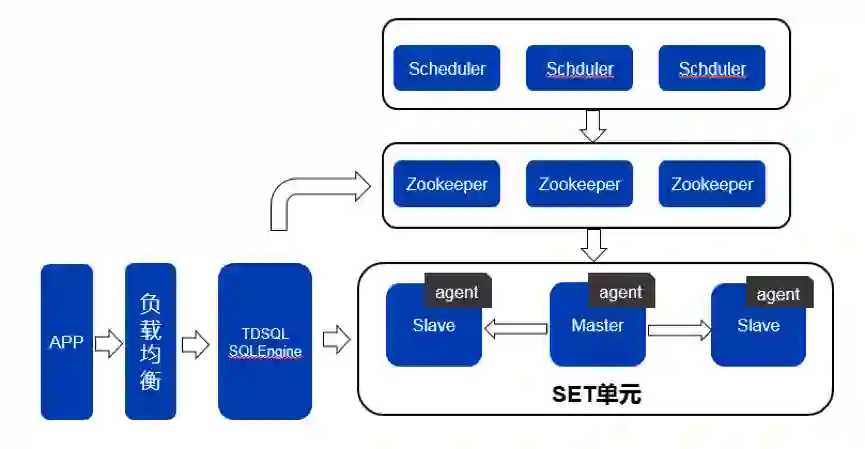
TDSQL架构介绍

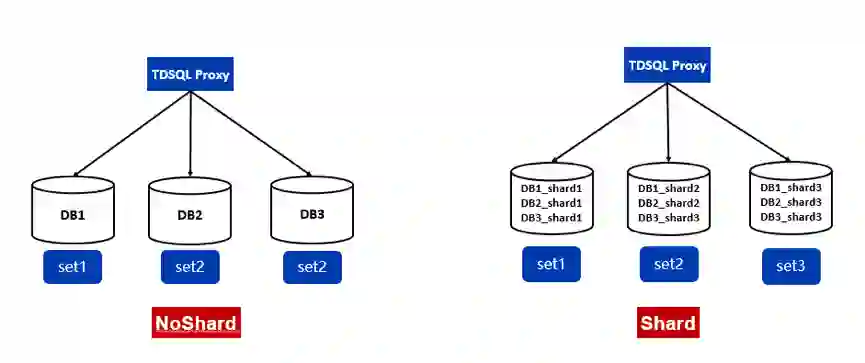
TDSQL noshard与shard模式
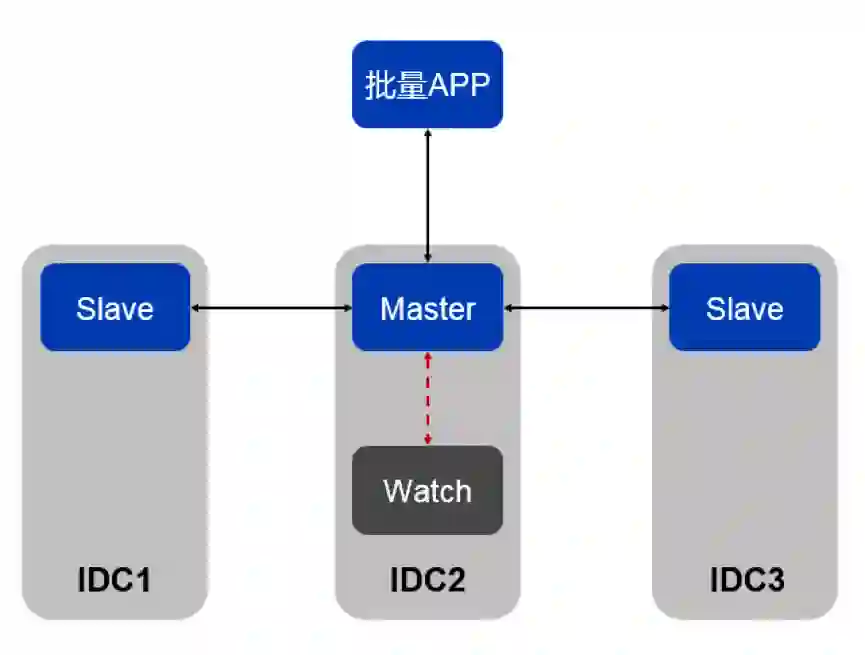
主备强一致切换与秒级恢复
Watch节点模式
自动化监控与运维
基于DCN的分布式扩展架构
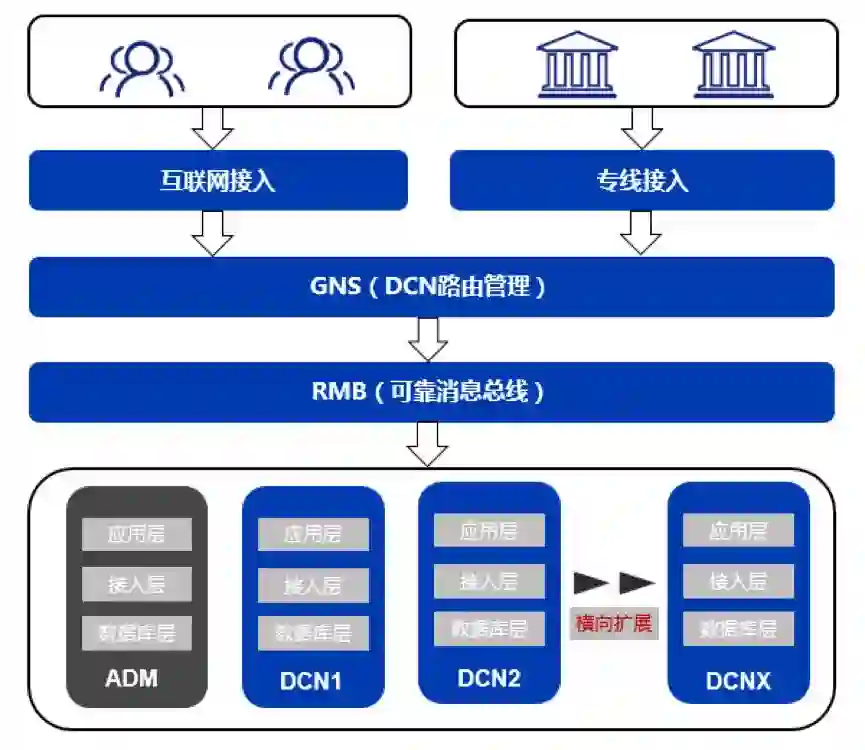
微众银行IDC架构
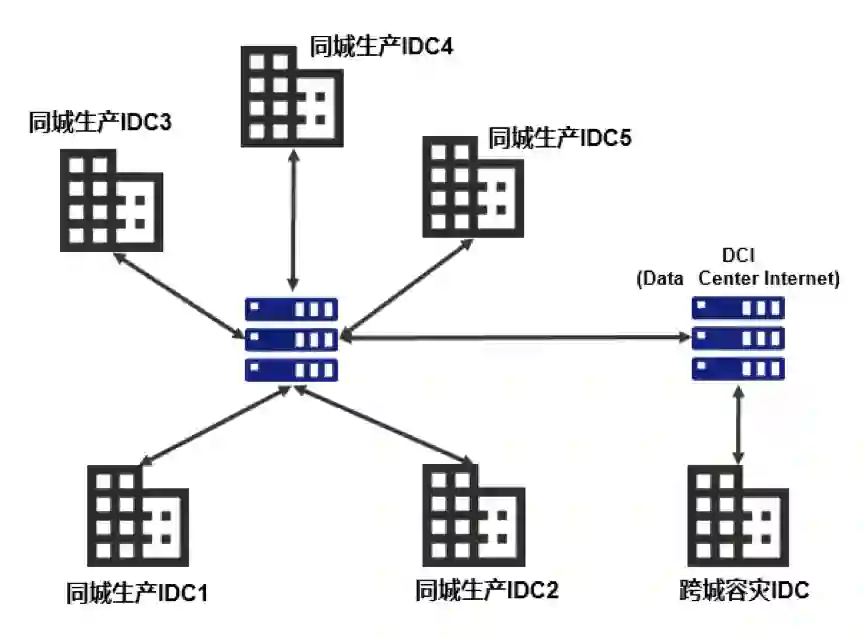
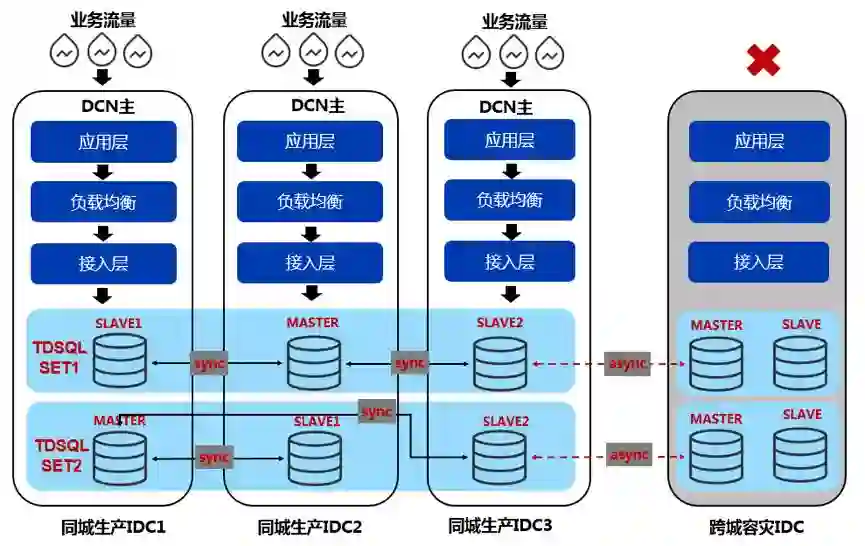
基于TDSQL的同城应用多活
TDSQL集群规模
微众银行数据库现状及未来发展

登录查看更多
相关内容



相关VIP内容
相关资讯
相关论文