资源 | TwenBN发布两个大型DL视频数据集:助力机器视觉通用智能
选自medium
作者:Moritz Mueller-Freitag
机器之心编译
参与:黄小天、Smith
TwenBN 是一家人工智能公司,运用先进的机器学习技术,做到让机器像人一样理解视频。近日,他们发布了两个大型视频数据集(256,591 个标注视频)Something-something 和 Jester 的快照(snapshot)版本,希望机器通用视觉智能的发展。第一个数据集 Something-something 可以使机器细致地理解物理世界中的基本动作;第二个数据集 Jester 关于动态手势,可谓人机交互创建稳健的认知模型。机器之心对该文进行了编译,数据集地址见文中,原文链接见文末。
数据集 Something-something:https://www.twentybn.com/datasets/something-something
数据集 Jester:https://www.twentybn.com/datasets/jester

我们数据集的视频示例
视频无处不在
视频在人类生活中发挥着越来越大的作用。我们每天花在视频观察上的时间多达数百万小时;而不观看视频时我们在用手机、GoPro 以及(很快)AR 眼镜生产着更多的视频。人们越来越多地使用视频记录生活,我们正从图像时代,迈向视频时代。

这一切仅仅是开始。未来几年,从智能家用式摄像头到无人驾驶汽车,会出现越来越多的互联设备。很多这些设备将依赖摄像头作为其主要的传感输入,理解并在世界中行动。随着技术的推进,视频智能将十分关键。很明显人眼无法处理全世界的海量视频数据,也很遗憾地无法规模化。我们需要能够分析并从视频中提取信息的软件层(software layer),它具备理解物理世界的学习算法,并通过内在的执行器(actor)展开无限的行动。
视频是计算机视觉的下一个前沿
深度学习近年来取得了历史性突破,其系统在静态图像的物体识别方面赶超——在某些情况下,超越——人类水平。尽管如此,让机器理解视频的时间、空间维度依然是一个无解的难题。原因很简单:十足的复杂度。照片是一张静态图像,而视频是动态的流。人们需要花时间手动注释视频,且存储和处理的计算成本昂贵。
神经网络无法更根本地推理复杂场景的主要原因是缺乏关于物理世界的尝试。视频数据包含了世界的大量而细致的信息,展示了物体的不同属性,例如,视频毫无遗漏地编码了诸如空间三维、材料属性、物体持久性、可供性(affordance)或重力等物理信息。尽管人类也可以直观地掌握这些概念,但相比于当前的人工智能和机器人应用,依然错失了大量的物理性细节信息。

现有的计算机视觉系统对于世界的(最佳)描述并不稳健。这里是一个模型的几个实例,它可以生成关于图像的自然语言描述(来源:http://cs.stanford.edu/people/karpathy/deepimagesent/)。
TwenBN 相信处理视频的智能软件是实现通用人工智能的一个先决条件。我们比较关注的一个应用领域是健康医疗,尤其是老年人看护。在这个方面,基本生活行为的变化往往先于生理变化,这会导致不佳的临床结果。想象一下我们能为那些年老之人做些什么,如果可以在固定位置上安装一些智能摄像头:我们可以监测其行为变化,提高其记忆力,并最终改善他们的健康。
为了实现诸如此类的应用,我们需要变革技术步骤,需要可以理解发生在视频中的语境和行动的系统。最佳的图像识别技术无法做到这一点,这是因为生活不仅仅是一堆图像的序列组合,感知这个世界也不仅仅是识别图像中的猫猫狗狗,而是关于时间中真正正在发生的东西。感知世界是「动词」,而不是「名词」。
一个实现视频理解的全新方法
阻碍视频理解进展的最大因素之一是大量而多元化的现实世界视频集的缺乏。目前推出的诸多视频数据集存在以下缺点:标注太少,缺乏多样性,或者编辑和后处理程度过高。但有几个值得一提的例外,比如 DeepMind 最近发布的 Kinetics 数据集,它聚焦于更短的视频片段,由于它展示了来自 YouTube 人类高水平的行为,难免存在无法表征最简单的物理对象交互的弊端,而这正是建模通用视觉(visual common sense)所需要的。
TwentyBN 去年致力于打造一个理解物理行动的基础性数据层。我们的方法基于一个相当简单直接的主意:为什么不利用人类本能性的且极其精确的运动技能来大规模地生成细致、复杂与多样的数据。最终我们每天观察的大多数动作模式实际上来自其他人。
为了生成神经网络需要学习的复杂、标注视频,我们使用了被我们称为「crowd acting」的方法,即指导成群的工作者录制短时频片段。这些视频基于小心预设和高度具体的描述,例如,「推它,直到其落下桌子」,「把物体 A 向物体 B 移动」,「竖起你左手的两个手指」。尽管我们搜集人类不同行为的数据,但更专注于灵巧地使用一只手或双手操控物体的数据。这是由于我们的手最擅长生成用于网络训练的高度可控、复杂的行为模式。「crowd acting」允许我们低成本地生成大量详细标注的、有意义的视频片段,而不再是痛苦地标注现有的视频数据。
今天,我们很高兴宣布这次数据搜集运动中的两项重要成果:人-物体交互数据集「Something-something」和世界上最大的分类动态手势的数据集「Jester」。这两个数据集是「快照」版本(初始版本),因为数据搜集已然在进行之中。我们一共发行了 256,591 个标注视频片段用于深度学习模型的有监督训练。这两个数据集都是根据知识共享署名 4.0 国际许可(CC BY-NC-ND 4.0)提供的,可免费用于学术研究,也可在许可之后商用。
1.「Something-something」数据集
这个数据集包含 108,499 个标注视频片段,它们每一个的时长都在 2 到 6 秒之间。这些视频展示了 175 种类别的物体和动作。这些文字题注(captions)都是基于模板的文字描述,比如「把某物丢进某物」这种文字模板。模板往往包含「某物」的「窄条」(slots),就像物体的占位符号(placeholders)。这就给网络中从文本到视频的编码过程(text-to-video encoding)提供了附加结构,从而来增强学习效果。

此数据集的目的不仅仅是在视频中检测和追踪物体,而且还是为了破译人类行为者(human actors)的表现和那些直接或间接地操作物体的动作。根据视频来预测文本标注往往需要强视觉特征(strong visual features),这些特征能够表征物体和这个世界中的大量物理特性。这就包括那些属性的相关信息,比如空间关系和材料属性。
2.「Jester」数据集
这个数据集包括 148,092 个标注视频片段,每一个时长 3 秒左右。这些视频涵盖了 25 个类别的人类手势和两个「无手势」的类别,从而来帮助网络结构对特定手势动作和未知手部动作进行区分。这些视频展示了人类行为者在网络摄像机面前完成各种一般的手势的过程,比如「向左或向右重击」,「两个手指向上或向下滑动」,「向前或向后摆手」。从视频中预测这些文本标注通常要求网络能够理解这些概念,比如三维空间的自由度(震荡、摇摆、举起等等)。
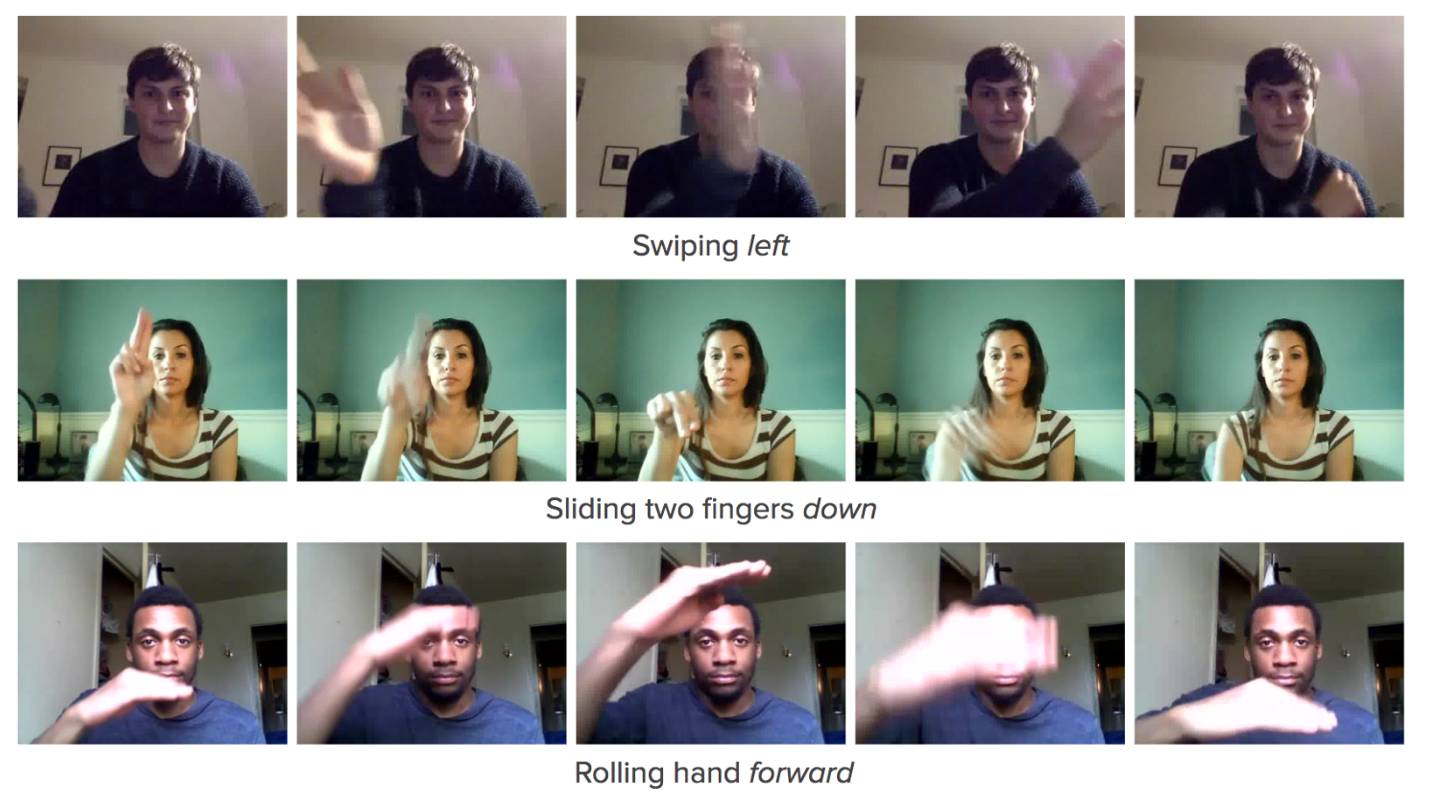
传统的手势识别系统往往需要像立体相机或深度传感器这样的特殊硬件,比如时差测距相机(time-of-flight cameras)。我们能够使用 Jester 数据集训练一个神经网络,它可以根据原始的三原色(RGB)输入对所有的 25 种手势进行检测和分类,测试精度可达 82%。此系统可在大量的嵌入式平台上进行实时运行,这些平台都使用网络摄像机进行视频输入。
两种数据集的关键特性
有监督学习:和其它一些试图通过使用预测性无监督学习来获取常识性信息的方法相比,我们把任务分化(phrase)成一个有监督学习的问题。这可以使表征式学习任务(representation learning task)更加易于处理,更明确。
密集式字注(Dense captioning):描述视频内容的标注被限制在很短的时间间隔内。这可以保证视频内容和对应字注进行紧密的同步。
群体动作视频(Crowd-acted video):和其它学术性数据集(YouTube 的源文件和视频片段)相比,我们使用「crowd acting」创建了我们的数据集。我们的专有「crowd acting」平台允许我们让工作人员来提供「给定字注模板」的视频。这就促进了标注式录像(labeled recordings)的生成,而不仅仅是对已有视频进行标注。
聚焦于人(Human focused):除了像海浪和风中落叶这样的运动「肌理」(motion「textures」)之外,我们看到的最复杂的运动模式其实是人类产生的。我们的数据集是以人为中心的,有着复杂的时空模型,可以对清晰度(articulation)、自由度(degrees of freedom)等等这些特征进行编码。
自然视频场景(Natural video scenes):我们的视频是用许多不同的装置和变化的缩放因子来进行拍摄的。这些数据集的特征场景有自然光,局部遮挡(partial occlusions),运动模糊(motion blur)和背景噪点(background noise)。这保证了数据集可以最小的区域移位(domain shift)来切换到真实的使用场景。
视频片段是具有挑战性的,因为它捕捉了真实世界的杂乱状况(messiness)。为了给你提供帮助,你可以看一看 Jester 数据集的视频片段,它展示了一个正在做手势的人:

尽管手势可以被人眼所捕捉,但是它很难被计算机识别,因为录像往往包括次优级(sub-optimal)的光线条件和背景噪点(比如猫在场景里走动)。在 Jester 上进行训练可以迫使神经网络学习相关的视觉线索,或者「分层特征」(「hierarchical features (https://en.wikipedia.org/wiki/Feature_%28machine_learning%29)」),以使信号(手部动作)从噪声(背景运动)中分离出来。显然,基本的运动检测是不够的。
通用视觉智能的实际应用
我们怎样从对物理概念的理解当中去提取实用的、真实的解决方案呢?我们相信可以在一个叫做迁移学习(transfer learning)的技术概念中找到这个答案。
我们人类是善于通过类比(analogy)来进行思考的。从一个领域当中提出一个理念,然后应用到另一个领域中,就像 Douglas Hofstadter (https://www.amazon.com/Surfaces-Essences-Analogy-Fuel-Thinking/dp/0465018475) 说的那样,这就是「思考的燃料和火种」(「the fuel and fire of our thinking」)。在人工智能领域,通过类比进行推理的步骤就是迁移学习。通过迁移学习,我们可以得到一个在 Something-something 和 Jester 上训练过的神经网络,并且通过对它的性能进行迁移,来给特定的商业应用做出贡献。具体来说,拥有内在表征(关于物体之间怎样在真实世界中进行交流)的网络,可以通过迁移这个内在知识信息,来解决那些曾基本观点所断言的拥有高阶复杂度的问题。
迁移学习已经在大量基于图像的视觉任务中取得了令人震惊的成果(比如:https://arxiv.org/abs/1403.6382、https://arxiv.org/abs/1411.1792、http://cs.stanford.edu/people/karpathy/deepimagesent/)。我们相信类似的突破即将要在深度视频理解(deep video understanding)的领域发生了。影响视频领域中迁移学习的先决条件是那些高质量、已标注的视频数据的可用性,它们可以使神经网络对视觉常识信息进行建模。这就是 TwentyBN 的使命所在。我们公司的数据收集从难以识别但是可解决的问题领域(已经有一些证明点,像手势识别)横跨到那些很难而且还不能解决的问题领域。而这个领域的终点就是通用人工智能(general AI)。
怎样获取数据并且在哪里用基准问题测试你的结果
两个数据集都可以通过我们的网站进行下载(https://www.twentybn.com/datasets)。你可以从我们的技术报告(https://arxiv.org/abs/1706.04261)中找到它们的相关信息和我们得技术细节。如果你想要用基准问题来测试你自己在数据集上完成的模型的精度,你也可以在我们的网站上传你的结果,这也将被展示在一个排行榜上。如果想获得我们的数据集的商用许可,请和我们联系。我们发布这两个数据集的目的是促进机器的发展,使它们可以像人类一样去感知世界。我们的工作是在过去和现在的一些研究者的肩膀上进行的。我们也热衷于回报这个充满活力的群体。

原文链接:
https://medium.com/twentybn/learning-about-the-world-through-video-4db73785ac02
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
点击阅读原文,查看机器之心官网↓↓↓




