AAAI 2018 | CMU研究:门控关注架构解决面向任务语言接地问题
CMU的研究人员Devendra Singh Chaplot等的论文Gated-Attention Architectures for Task-Oriented Language Grounding提出了一个名为门控关注的多模态融合单元。3D环境下的面向任务的语言接地问题中,门控关注单元的表现超过了以往传统的连接方法。
论文作者将在AAAI 2018上作口头报告,前天(2018年1月9日)更新了发表在预印本文库上的论文。下面我们将根据论文的最新版本,介绍这一研究成果。
面向任务的语言接地问题
为了执行以自然语言方式给出的指令,代理需要从自然语言中提取出有意义的语义表示,并将语义表示映射到行动和环境中的可视元素。这就是所谓的面向任务的语言接地(task-oriented language grounding)问题。

这一问题可以拆解成以下步骤:
辨识以原始像素形式作为输入的物体
探索环境(因为目标可能被遮挡,甚至在视野之外)
接地语义表示与行动、环境元素
理解自然语言中的语用成分,例如,对于指令“去最大物体处”,代理需要理解“最大”的含义
导航以到达目标所在位置

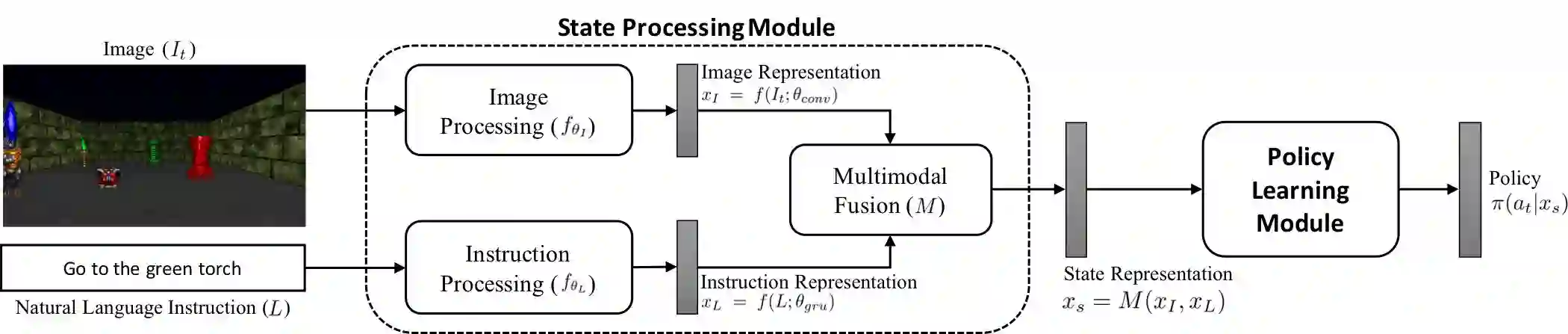
用形式化的语言表述,将当前状态记为St,将采取的行动记为at,(t表示时刻)我们要求解的是根据当前状态得出将采取的行动的最佳策略π(at|St)。
其中,St = {It, L}。It为当前环境的像素层次的图像,L为自然语言指令。
模型
从上一节问题的形式化表述出发,相应的模型的架构分为两部分,第一部分建模St,第二部分学习策略。
我们首先来看模型的第一部分。如前所述,St由当前环境的像素层次的图像It和自然语言指令L组成。It既然是图像,那么很自然地,可以用CNN(卷积神经网络)来处理。自然语言指令L是一个序列,对于这种序列化的数据,常用的模型是RNN(循环神经网络)以及RNN的变体(LSTM、GRU等),研究人员选用的是GRU。
具体而言,CNN接受图像It作为输入,输出图像的表示xI,即f(It; θconv) ∈ RdxHxW。其中,θconv代表CNN的参数,d代表特征映射的数目,H和W分别代表特征映射的高度和宽度。
GRU则接受自然语言指令L,输出指令的表示xL,即f(L; θgru)。其中,θgru代表GRU的参数。
接下来我们需要将xI和xL结合起来。很自然的想法是通过连接(concatenation),这也正是以往的研究中常用的方法。不过,研究人员并不满足于此。因为,特定的自然语言指令,不一定需要用到图像的特征映射xI中全部的信息。比如,假设指令是“去绿色物体处”,那么我们仅仅关注“绿色”这一颜色特征;再如,假设指令是“去柱子处”,那么我们仅仅关注“柱子”这一形状特征;而当指令是“去绿色柱子处”时,我们同时关注“绿色”和“柱子”两个特征。
所以说,单纯的连接没有充分利用自然语言指令给出的信息,不加选择地包括了图像的所有特征映射。我们需要的是能表达关注(Attention)的模型来融合xI和xL,根据xL给出的关注(Attention)信息让图像的特征映射xI选择性地进入(门控 Gated)。
因此,研究人员没有简单地使用连接,而是定制了一个多模态融合单元(multimodal fusion unit)。研究人员将这个单元命名为门控关注(Gated Attention)。
门控关注多模态融合单元的设计,受到了Dhingra等2017年发表的《Gated-attention readers for text comprehension》(用于文本理解的门控关注阅读器)一文的启发。和前述图像特征映射与自然语言指令的关系类似,特定的查询,不一定需要用到文本表示的全部信息。基于查询的关注,可以进一步优化文本表示。门控关注阅读器融合了查询的嵌入(query embedding)与基于循环神经网络的文档阅读器的中间状态。
研究人员使用一个采用sigmoid激活函数的全连接层提取自然语言指令中的关注信息,即aL = h(xL) ∈ Rd。其中,aL为关注向量(attention vector)。
最后,研究人员用aL矩阵与xI的Hadamard乘积得到门控关注融合MGA(xI, xL)。
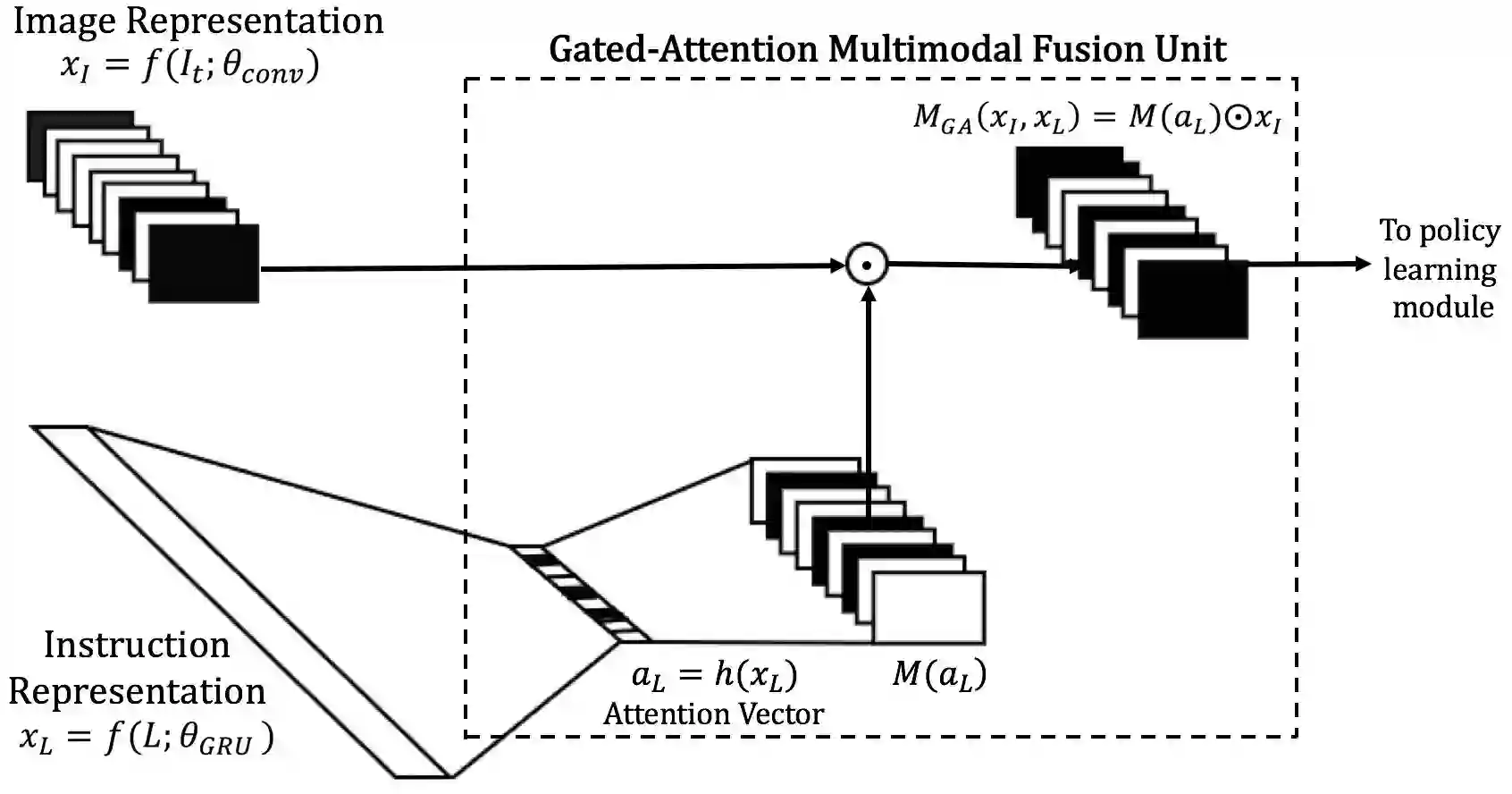
以上整个门控关注单元是可微的,便于网络训练。
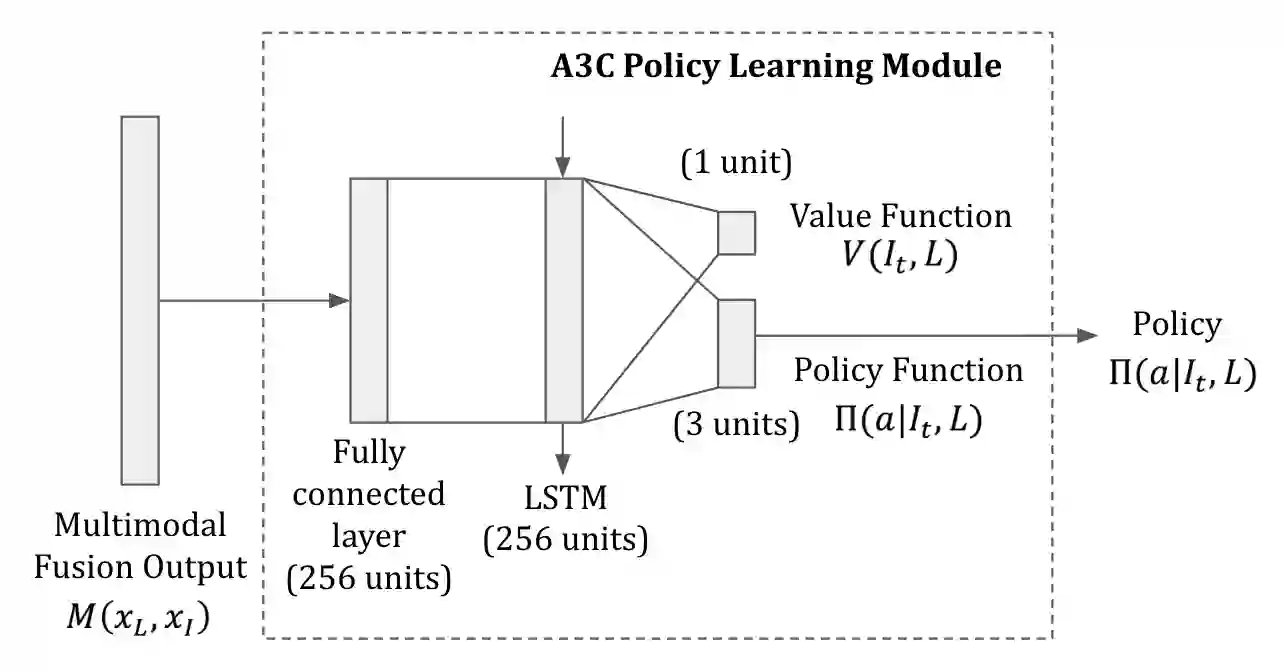
门控关注融合单元的输出传递给策略学习模块作为输入。
研究人员分别使用了两种不同的策略学习方法:模仿学习(Imitation Learning)和强化学习(Reinforcement Learning)。
关于模仿学习,研究人员分别使用了2011年Ross、Gordon、Bagnell提出的DAgger(数据集聚合)算法和2015年Bagnell提出的Behavioral Cloning(行为克隆)算法。这两种算法都基于给定当前状态返回最佳行动的神谕(oracle)。整个环境基于游戏引擎,因此神谕基于从引擎中提取的代理和物体位置信息生成。
关于强化学习,研究人员使用了Mnih等2016年提出的Asynchronous Advantage Actor-Critic(A3C)方法。该方法使用一个包含全连接层和LSTM层的深度神经网络学习策略和值函数(value function)。
环境和配置
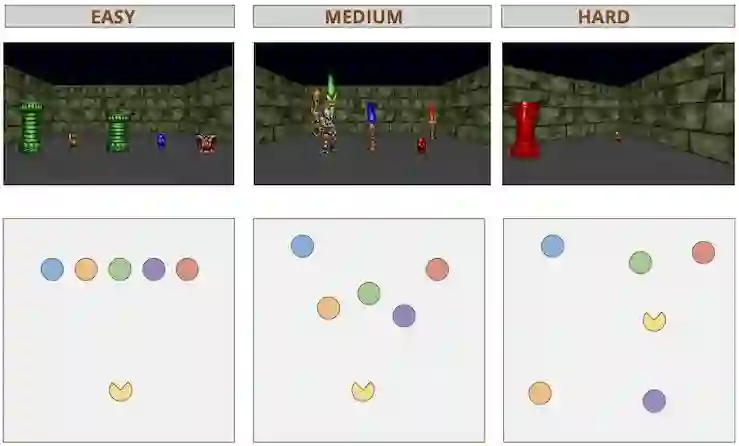
研究人员基于ViZDoom构建了一个3D环境。ViZDoom基于3D游戏引擎Doom,提供了每一时刻第一人称视角的原始视觉信息。
为了简化问题,研究人员对自然语言指令作了限制,每个指令只包含一个动作和物体,物体具有颜色、形状和尺寸三个属性。另外,每个场景统一放置5个物体,其中有且仅有1个物体是符合条件的。

根据物体放置的不同,研究人员划分了3个难度等级:

研究人员基于70条手工生成的指令训练了模型。

训练完毕后,研究人员在新地图上进行了测试,根据指令是否已知,测试分为两种:

未知地图指随机摆放的物体组合没有在训练集中出现过。多任务测试了模型是否存在过拟合问题,以及代理是否通过记忆训练地图的方式作弊。
多任务测试
零样本测试
结果
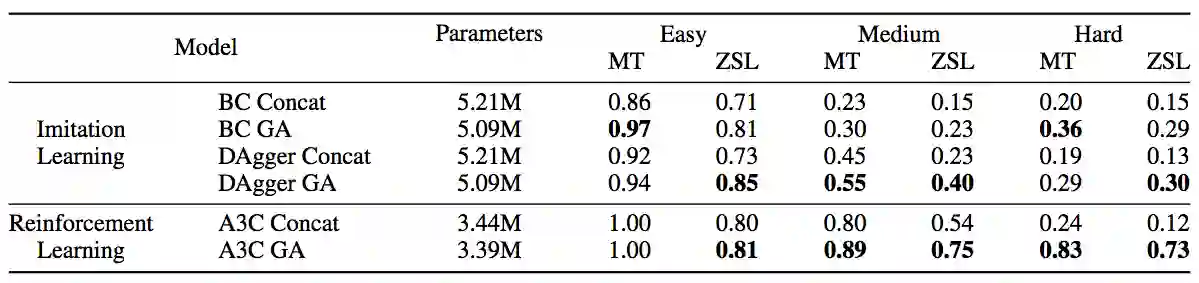
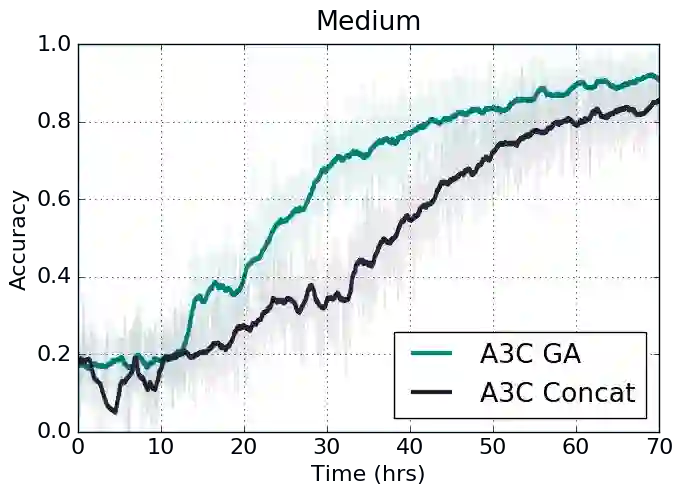
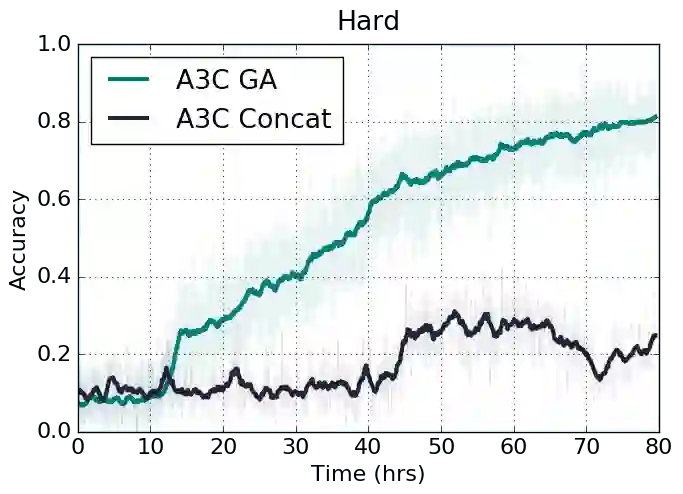
最终结果表明,在3种难度、2种方法的测试上,相比基准(前文所述的基于连接的结合),使用了门控关注的模型总体而言表现更好。
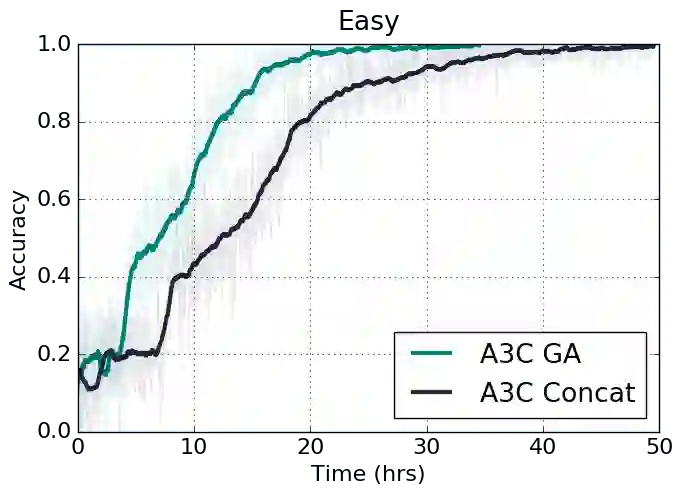
3种难度下,使用了门控关注的强化学习A3C算法,在训练不久后就超越了使用连接的基准。
可视化
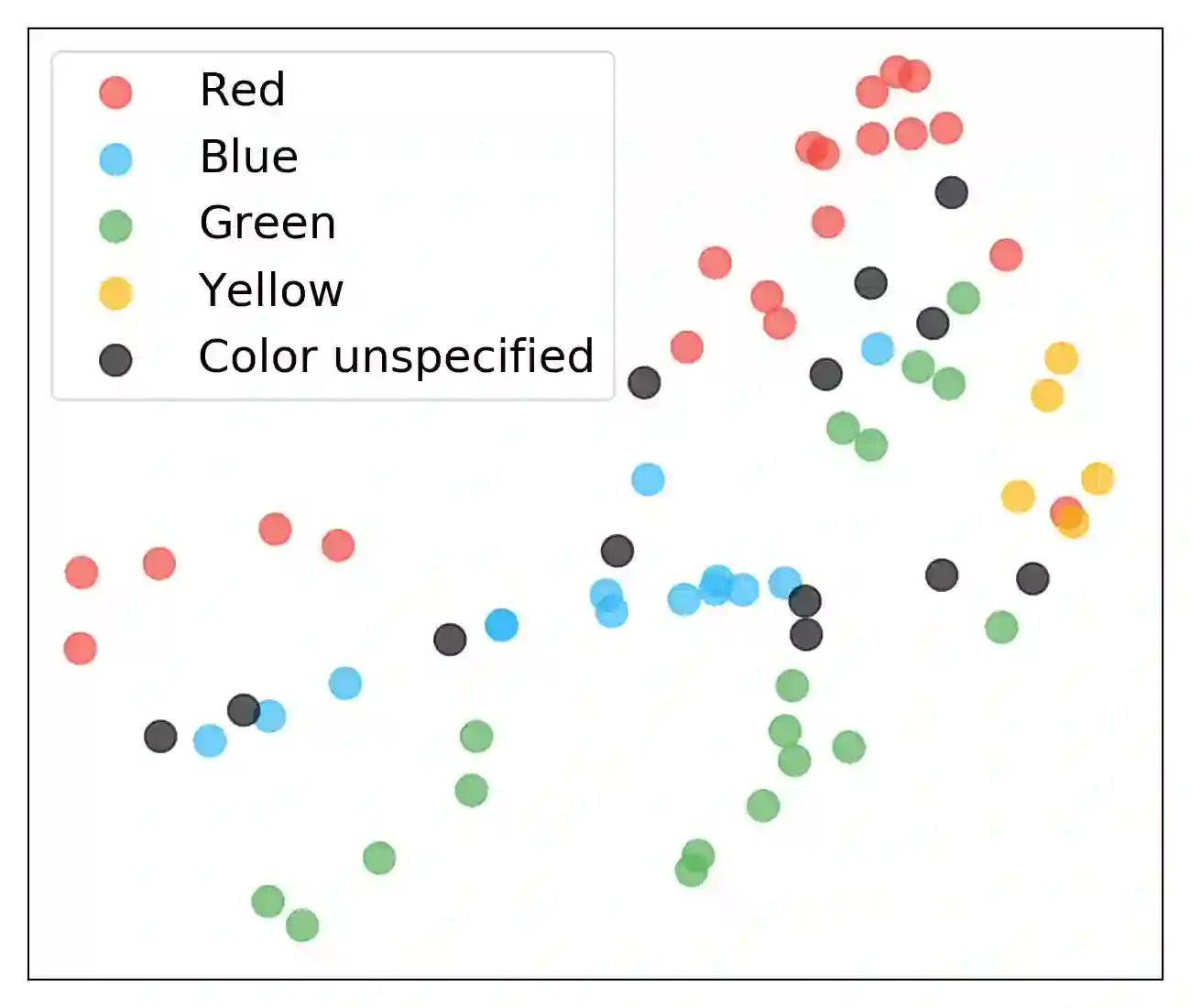
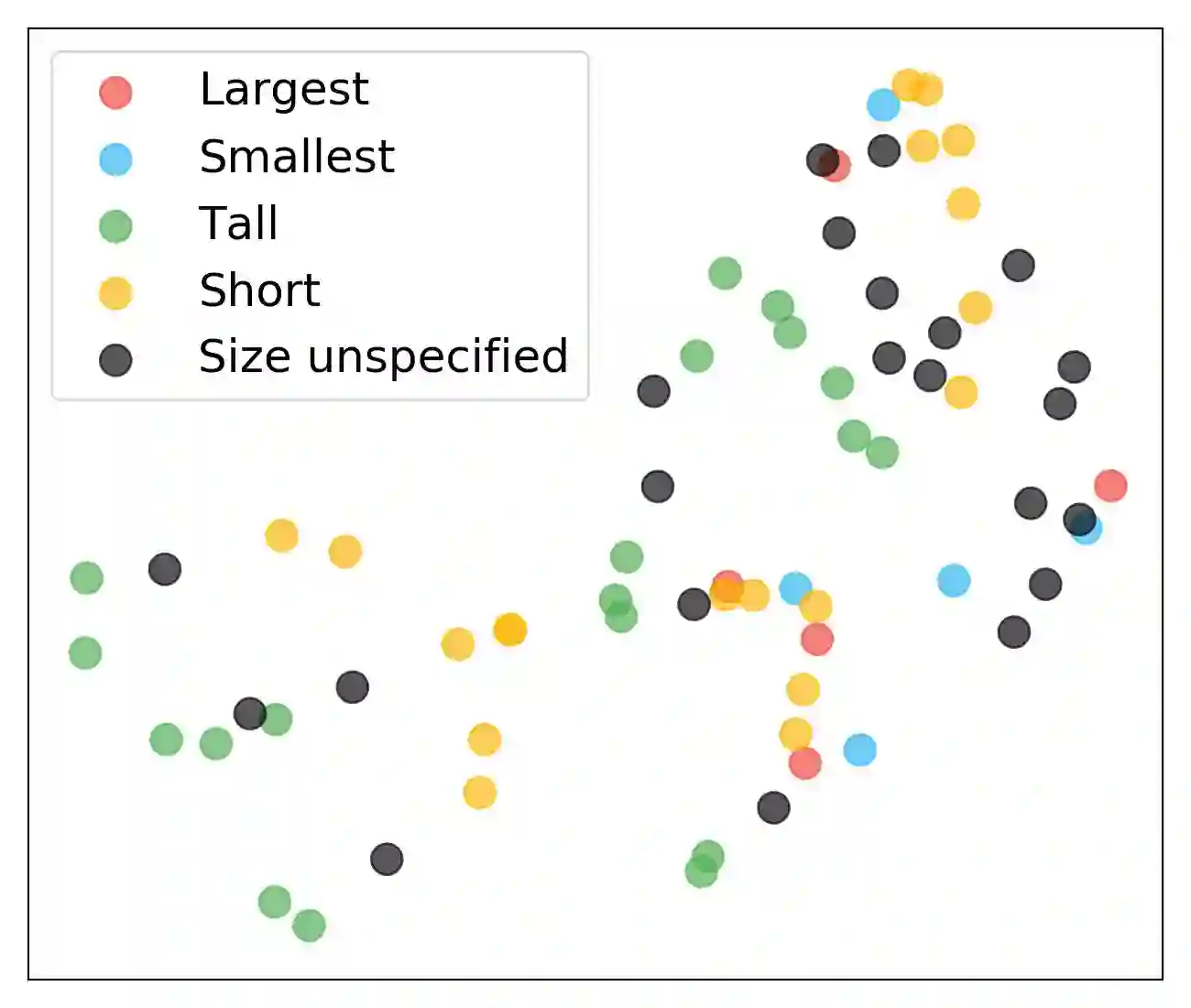
研究人员可视化了门控关注单元的关注权重。
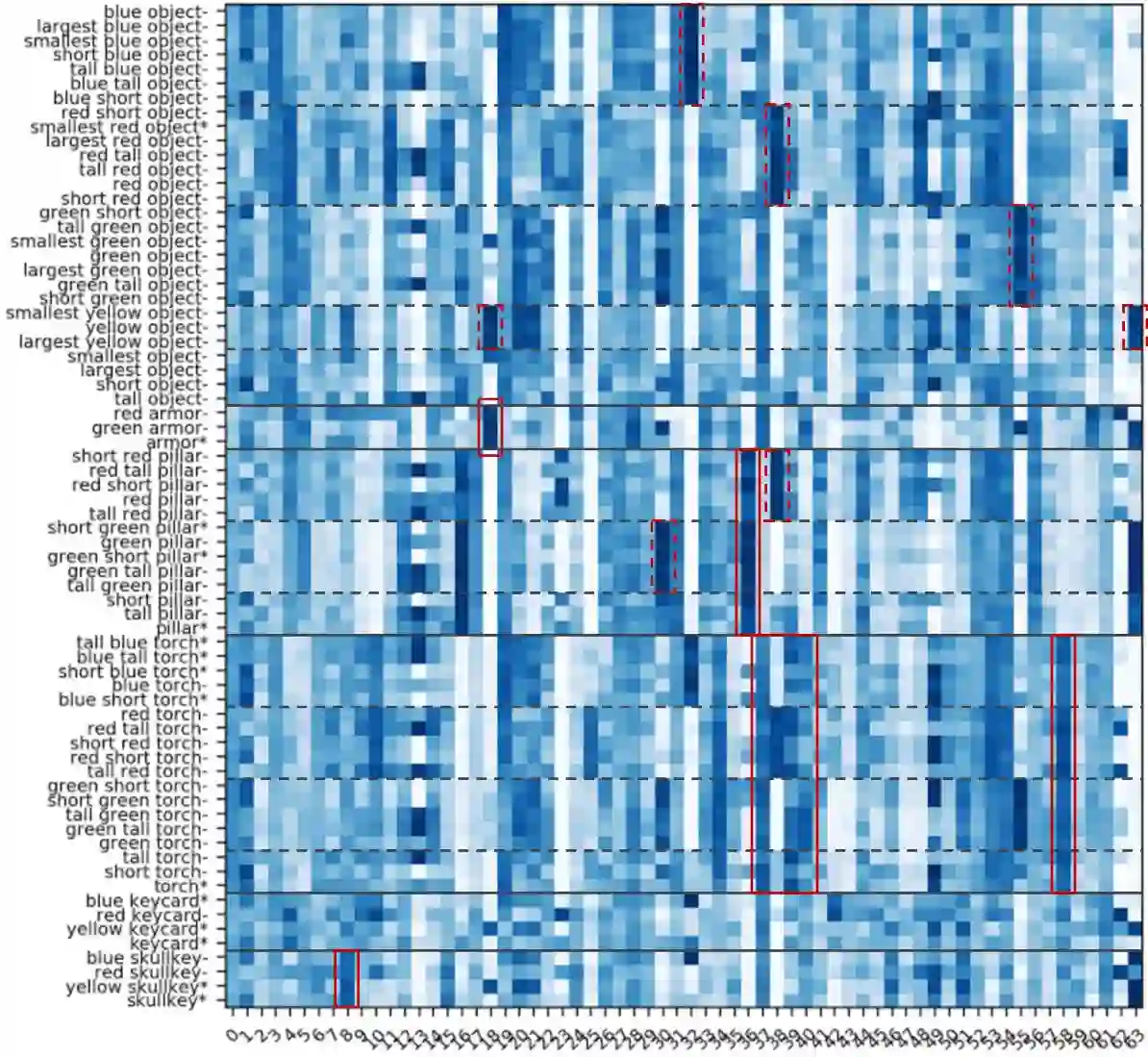
上图表明,模型确实学习识别了物体的属性。例如,维度8对应“骷髅钥匙”,维度18对应“装甲”,维度36对应“柱子”。另外,热图开始的“物体”(object)类别中,没有一个统一的高热维度。这意味着模型学习到了“物体”并不对应具体的物体类别或形状。同理,红色点框表明模型学习识别了物体的颜色。带*的指令属于未知指令,热图表明模型能够识别未知指令中的物体属性。
研究人员还可视化了关注向量的t-SNE点。下图中的聚类表明模型能够通过学习相似物体的相似关注向量来识别物体的属性。