开源入侵检测系统 Snort
午一次性进群,长期免费索取教程,没有付费教程。
教程列表见微信公众号底部菜单
进微信群回复公众号:微信群;QQ群:16004488

微信公众号:计算机与网络安全
ID:Computer-network
在1998年,Marty Roesch先生用C语言开发了开放源代码(Open Source)的入侵检测系统Snort 。直至今天,Snort已发展成为一个多平台(Multi-Platform),实时(Real-Time)流量分析,网络IP数据包(Pocket)记录等特性的强大的网络入侵检测/防御系统(Network Intrusion Detection/Prevention System),即NIDS/NIPS 。Snort符合通用公共许可(GPL——GNU General Pubic License),在网上可以通过免费下载获得Snort,并且只需要几分钟就可以安装并开始使用它。snort基于libpcap。
一、Snort 的工作模式
Snort有三种工作模式:数据包采集、数据包记录器、网络入侵检测系统。数据包采集模式仅仅是从网络上读取数据包并作为连续不断的流显示在终端上。数据包记录器模式把数据包记录到硬盘上。网络入侵检测模式是最复杂的,而且是可配置的。我们可以让snort分析网络数据流以匹配用户定义的一些规则,并根据检测结果采取一定的动作。
1、数据包采集
所谓的数据包采集模式就是 snort 从网络上读出数据包然后显示在用户的控制台上。首先,我们从最基本的用法入手。如果要把TCP/IP包头信息显示在屏幕上,只需要使用如下的命令:
./snort -v
使用这个命令将使snort只输出IP和TCP/UDP/ICMP的包头信息。如果需要看到应用层的数据,可以使用:
./snort -vd
这条命令使snort在输出包头信息的同时显示包的数据信息。如果还要显示数据链路层的信息,就使用下面的命令:
./snort -vde
注意这些选项开关还可以分开写或者任意结合在一块。例如:下面的命令就和上面最后的一条命令等价:
./snort -d -v –e
2、数据包记录器
如果要把所有的包记录到硬盘上,则需要指定一个日志目录,snort就会自动记录数据包:
./snort -dev -l ./log
当然,./log目录必须存在,否则snort就会报告错误信息并退出。当snort在这种模式下运行,它会记录所有看到的包将其放到一个目录中,这个目录以数据包目的主机的IP地址命名,例如:192.168.10.1
如果只指定了-l命令开关,而没有设置目录名,snort有时会使用远程主机的IP地址作为目录,有时会使用本地主机IP地址作为目录名。为了只对本地网络进行记录,需要给出本地网络:
./snort -dev -l ./log -h 192.168.1.0/24
这个命令告诉snort把进入C类网络192.168.1的所有包的数据链路、TCP/IP,以及应用层的数据记录到目录./log中。
如果网络速度很快,或者希望让日志更加紧凑以便以后的分析,那么应该使用二进制的日志文件格式。所谓的二进制日志文件格式就是tcpdump程序使用的格式。使用下面的命令可以把所有的包记录到一个单一的二进制文件中:
./snort -l ./log -b
注意此处的命令行和上面的有很大的不同。我们不需要指定本地网络,因为所有的东西都被记录到一个单一的文件;也不必冗余模式或者使用-d、-e 功能选项,因为数据包中的所有内容都会被记录到日志文件中。
可以使用任何支持tcpdump二进制格式的数据包采集程序从这个文件中读出数据包,例如:tcpdump或者Ethereal。使用-r功能开关,也能使snort读出包的数据。snort在所有运行模式下都能够处理 tcpdump格式的文件。例如:如果想在数据包采集模式下把一个 tcpdump格式的二进制文件中的包打印到屏幕上,可以输入下面的命令:
./snort -dv -r packet.log
在日志包和入侵检测模式下,通过 BPF(BSD Packet Filter)接口,可以使用许多方式维护日志文件中的数据。例如,如果只想从日志文件中提取 ICMP 包,只需要输入下面的命令行:
./snort -dvr packet.log icmp
3、网络入侵检测系统
snort最重要的用途还是作为网络入侵检测系统(NIDS),使用下面命令行可以启动这种模式:
./snort -dev -l ./log -h 192.168.1.0/24 -c snort.conf
snort.conf 是规则集文件。snort 会对每个包和规则集进行匹配,发现这样的包就采取相应的行动。如果没有指定输出目录,snort就输出到/var/log/snort目录。
注意:如果希望长期使用 snort 作为自己的入侵检测系统,最好不要使用-v 选项。因为使用这个选项,使snort向屏幕上输出一些信息,会大大降低snort的处理速度,从而在向显示器输出的过程中丢弃一些包。
此外,在绝大多数情况下,也没有必要记录数据链路层的包头,所以-e 选项也可以不用:
./snort -d -h 192.168.1.0/24 -l ./log -c snort.conf
这是使用snort作为网络入侵检测系统最基本的形式,日志符合规则的包,以ASCII 形式保存在有层次的目录结构中。
4、网络入侵检测模式下的输出选项
在NIDS模式下,有很多的方式来配置snort的输出。在默认情况下,snort以ASCII格式记录日志,使用full报警机制。如果使用full报警机制,snort会在包头之后打印报警消息。如果不需要日志包,可以使用-N选项。
snort有6种报警机制:full、fast、socket、syslog、smb(winpopup)和none。其中有4个可以在命令行状态下使用-A选项设置。这4个是:
-A fast:报警信息包括:一个时间戳(timestamp)、报警消息、源/目的IP地址和端口。
-A full:是默认的报警模式。
-A unsock:把报警发送到一个UNIX套接字,需要有一个程序进行监听,这样可以实现实时报警。
-A none:关闭报警机制。
使用-s选项可以使snort 把报警消息发送到 syslog,默认的设备是 LOG_AUTHPRIV 和LOG_ALERT。可以修改snort.conf文件修改其配置。
snort还可以使用SMB报警机制,通过SAMBA把报警消息发送到Windows主机。为了使用这个报警机制,在运行./configure脚本时,必须使用--enable-smbalerts选项。
下面是一些输出配置的例子:
使用默认的日志方式(以解码的ASCII格式)并且把报警发给syslog:
./snort -c snort.conf -l ./log -s -h 192.168.1.0/24
使用二进制日志格式和SMB报警机制:
./snort -c snort.conf -b -M WORKSTATIONS
二、编写Snort 规则
snort使用一种简单的,轻量级的规则描述语言,这种语言灵活而强大。大多数 snort规则都写在一个单行上,或者在多行之间的行尾用/分隔。Snort 规则被分成两个逻辑部分:规则头和规则选项。规则头包含规则的动作、协议、源和目标IP地址与网络掩码,以及源和目标端口信息;规则选项部分包含报警消息内容和要检查的包的具体部分。
下面是一个规则范例:
alert tcp any any -> 192.168.1.0/24 111 (content:"|00 01 86 a5|"; msg: "mountd access";)
第一个括号前的部分是规则头(rule header),包含的括号内的部分是规则选项(rule options)。规则选项部分中冒号前的单词称为选项关键字(option keywords)。注意,不是所有规则都必须包含规则选项部分,选项部分只是为了使对要收集或报警,或丢弃的包的定义更加严格。组成一个规则的所有元素对于指定的要采取的行动都必须是真的。当多个元素放在一起时,可以认为它们组成了一个逻辑与(AND)语句。同时,snort规则库文件中的不同规则可以认为组成了一个大的逻辑或(OR)语句。
除了规则之外,Snort还支持一些配置和定义选项,常见的选项见表1。
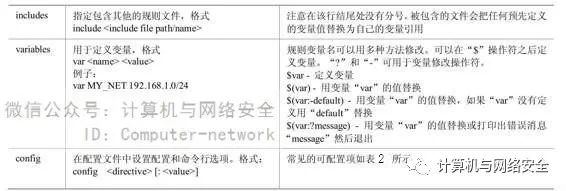
表1 常见的规则文件定义

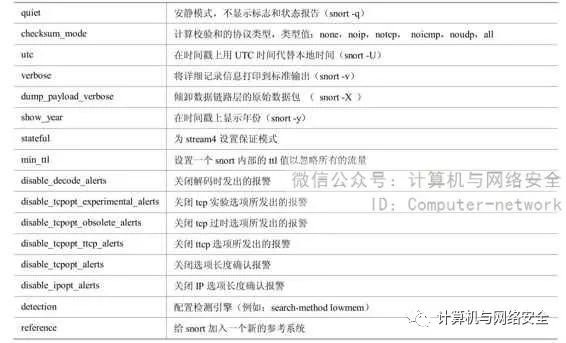
表2 Config所对应的可配置项
1、规则动作
规则的头包含了定义一个包的who、where和what信息,以及当满足规则定义的所有属性的包出现时要采取的行动。规则的第一项是“规则动作”(rule action),“规则动作”告诉snort在发现匹配规则的包时要干什么。在snort中有五种动作:alert、log、pass、activate和dynamic。
Alert——使用选择的报警方法生成一个警报,然后记录(log)这个包。
Log——记录这个包。
Pass——丢弃(忽略)这个包。
activate——报警并且激活另一条dynamic规则。
dynamic——保持空闲直到被一条activate规则激活,被激活后就作为一条log规则执行。
当然,Snort也允许自定义规则类型并且附加一条或者更多的输出模块给它,然后就可以使用这些规则类型作为snort规则的一个动作。
下面这个例子创建一条规则,记录到tcpdump。
ruletype suspicious
{
type log output
log_tcpdump: suspicious.log
}
下面这个例子创建一条规则,记录到系统日志和MySQL数据库
ruletype redalert
{
type alert output
alert_syslog: LOG_AUTH LOG_ALERT
output database: log,mysql,user=snort dbname=snort host=localhost
}
2、协议
规则的下一部分是协议。Snort当前分析可疑包的IP协议有四种:TCP、UDP、ICMP和IP。将来可能会更多,例如ARP、IGRP、GRE、OSPF、RIP、IPX等。
规则头的下一个部分处理一个给定规则的 IP地址和端口号信息。关键字“any”可以被用来定义任何地址。Snort没有提供根据IP地址查询域名的机制。地址就是由直接的数字型ip地址和一个cidr块组成的。Cidr块指示作用在规则地址和需要检查的进入的任何包的网络掩码。/24 表示 c 类网络,/16 表示 b 类网络,/32 表示一个特定的机器的地址。例如,192.168.1.0/24代表从192.168.1.1到192.168.1.255的地址块。在这个地址范围的任何地址都匹配使用这个 192.168.1.0/24 标志的规则。这种记法给我们提供了一个很好的方法来表示一个很大的地址空间。
有一个操作符可以应用在IP地址上,它是否定运算符(negation operator)。这个操作符告诉snort匹配除了列出的IP地址以外的所有IP地址。否定操作符用“!”表示。下面这条规则对任何来自本地网络以外的流都进行报警。
alert tcp !192.168.1.0/24 any -> 192.168.1.0/24 111 (content: "|00 01 86 a5|";msg: "external mountd access";)
这个规则的IP地址代表“任何源IP地址不是来自内部网络而目标地址是内部网络的TCP包”。
也可以指定IP地址列表,一个IP地址列表由逗号分割的IP地址和CIDR块组成,并且要放在方括号“[]”内。此时,IP列表可以不包含空格在IP地址之间。下面是一个包含IP地址列表的规则的例子。
alert tcp ![192.168.1.0/24,10.1.1.0/24]any ->[192.168.1.0/24,10.1.1.0/24]111 (content: "|00 01 86 a5|"; msg: "external mountd access";)
4、端口号
端口号可以用几种方法表示,包括“any”端口、静态端口定义、范围,以及通过否定操作符。“any”端口是一个通配符,表示任何端口。静态端口定义表示一个单个端口号,例如111表示portmapper,23表示telnet,80表示http等等。端口范围用范围操作符“:”表示。范围操作符可以有数种使用方法,如下所示:
log udp any any -> 192.168.1.0/24 1:1024
记录来自任何端口的,目标端口范围在1到1024的udp流
log tcp any any -> 192.168.1.0/24 :6000
记录来自任何端口,目标端口小于等于6000的tcp流
log tcp any :1024 -> 192.168.1.0/24 500:
记录来自任何小于等于1024的特权端口,目标端口大于等于500的tcp流
端口否定操作符用“!”表示。它可以用于任何规则类型(除了 any)。例如,由于某个古怪的原因需要记录除x windows端口以外的所有一切,则可以使用类似下面的规则:
log tcp any any -> 192.168.1.0/24 !6000:6010
5、方向操作符
方向操作符“→”表示规则所施加的流的方向。方向操作符左边的IP地址和端口号被认为是流来自的源主机,方向操作符右边的IP地址和端口信息是目标主机,还有一个双向操作符“< >”。它告诉snort把地址/端口号对既作为源,又作为目标来考虑。这对于记录/分析双向对话很方便,例如telnet或者pop3会话。用来记录一个telnet会话的两侧的流的范例如下:
log !192.168.1.0/24 any <> 192.168.1.0/24 23
6、规则选项
规则选项组成了Snort入侵检测引擎的核心,既易用又强大还灵活。所有的Snort规则选项用分号“;”隔开。规则选项关键字和它们的参数用冒号“:”分开。按照这种写法,Snort的规则选项关键字见表3。
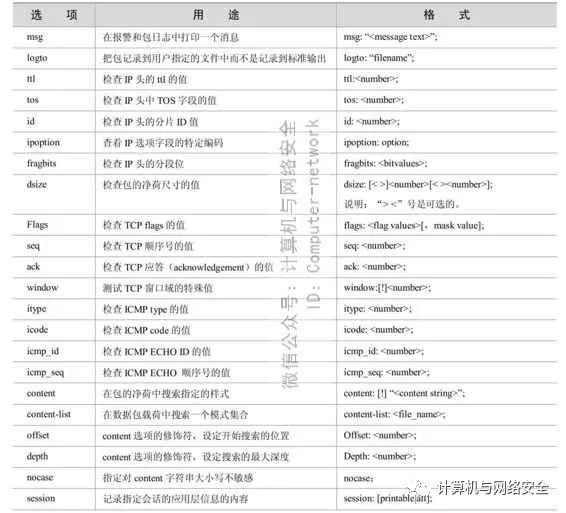
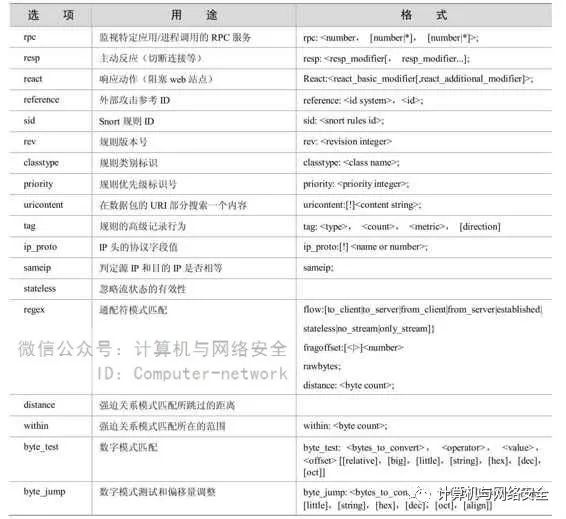
表3 Snort规则选项关键字
msg:msg规则选项告诉记录和报警引擎,记录或报警一个包的内容的同时打印的消息。它是一个简单的文本字符串,转义符是“\”。
logto:logto选项告诉Snort把触发该规则的所有的包记录到一个指定的输出日志文件中。这在把来自诸如nmap活动、http cgi扫描等的数据组合到一起时很方便。需要指出的是当Snort工作在二进制记录模式下时这个选项不起作用。
ttl:这个规则选项用于设置一个要检查的存活期的值。只有确切地匹配时它所进行的检查才成功。这个选项关键字用于检测traceroute。
TOS:tos关键字允许用户验证IP头中TOS字段为一个特殊的值。只有匹配时才执行成功。
id:这个选项关键字用于检测IP头的分片ID的值。有些攻击者工具(以及别的程序)为了各种目的设置这个域的值,例如一些攻击者常使用 31337。用一个简单的规则检查这个值就可以对付他们。
ipoption:如果数据包中使用了IP选项,Ipoption选项会查找使用中的某个特别IP选项,比如源路由。这个选项的合法参数如表4所示。

表4 常见的ipoption
松散和严格源路由是IP选项中最经常被检查的内容,但是它们并没有被用在任何广泛使用的Internet应用中。每一个特定的规则只能用这个选项一次。
fragbits:这条规则检测IP头中的分段和保留位字段的值,共有三个位能被检测,保留位RB(Reserved Bit)、更多分段位MF(More Fragments)和不分段位DF(Don’t Fragment)。这些位可以结合在一起来检测。使用下面的值来代表这些位,R-RB、M-MF、D-DF。也可以使用修饰语对特殊的位来指出合理的匹配标准。
dsize:dsize 选项用于检查包的净荷的大小。它可以设置成任意值,可以使用大于/小于符号来指定范围。例如,如果知道某个特定的服务有一个特定大小的缓冲区,则可以设定这个选项来监视缓冲区溢出的企图。它在检查缓冲区溢出时比检查净荷内容的方法要快得多。
content:content关键字是Snort中比较重要的一个。它允许用户设置规则在包的净荷中搜索指定的内容并根据内容触发响应。当进行content选项模式匹配时,Boyer-Moore模式匹配函数被调用,并且对包的内容进行检查(很花费计算能力)。如果包的净荷中包含的数据确切地匹配了参数的内容,这个检查成功并且该规则选项的其他部分被执行。注意这个检查是大小写敏感的。
content关键字的选项数据比较复杂;它可以包含混合的文本和二进制数据。二进制数据一般包含在管道符号中(“|”),表示为字节码(bytecode)。字节码把二进制数据表示为16进制数字,是描述复杂二进制数据的好方法。下面是包含了一个混合数据的Snort规则范例。
alert tcp any any -> 192.168.1.0/24 143 (content: "|90C8 C0FF FFFF|/bin/sh";msg: "IMAP buffer overflow!";)
注:多内容的规则可以放在一条规则中,还有(: ; / ―)不能出现在content规则中。如果一条规则前面有一个“!”。那么那些不包含这些内容的数据包将触发报警。这对于关注那些不包含一定内容的数据包是有用的。
offset:offset规则选项被用作使用content规则选项关键字的规则的修饰符。这个关键字修饰符指定模式匹配函数从包净荷开始处开始搜索的偏移量。它对于 cgi 扫描检测规则很有用,cgi扫描的内容搜索字符串不会在净荷的前4个字节中出现。小心不要把这个偏移量设置得太严格了,会有可能漏掉攻击!这个规则选项关键字必须和content规则选项一起使用。
depth:depth也是一个content规则选项修饰符。它设置了内容模式匹配函数从他搜索的区域的起始位置搜索的最大深度。它对于限制模式匹配函数超出搜索区域指定范围而造成无效搜索很有用(也就是说,如果在一个Web包中搜索“cgi-bin/phf”,你可能不需要浪费时间搜索超过净荷的头20个字节)。例子:
alert tcp any any -> 192.168.1.0/24 80 (content: "cgi-bin/phf"; offset: 3;depth: 22; msg: "CGI-PHF access";)
nocase:nocase选项用于取消content规则中的大小写敏感性。它在规则中指定后,任何与包净荷进行比较的ASCII字符都被既作为大写又作为小写对待。例子:
alert tcp any any -> 192.168.1.0/24 21 (content: "USER root"; nocase; msg:"FTP root user access attempt";)
flags:这个规则检查TCP标志。在Snort中有9个标志变量:
F - FIN (LSB in TCP Flags byte)
S - SYN
R - RST
P - PSH
A - ACK
U - URG
2 - Reserved bit 2
1 - Reserved bit 1 (MSB in TCP Flags byte)
0 - No TCP Flags Set
在这些标志之间还可以使用逻辑操作符:
+ALL flag,匹配所有的指定的标志外加一个标志。
* ANY flag,匹配指定的任何一个标志。
! NOT flag,如果指定的标志不在这个数据包中就匹配成功。
保留位可以用来检测不正常行为,例如IP栈指纹攻击或者其他可疑的行为。例子:
alert any any -> 192.168.1.0/24 any (flags: SF,12; msg: "Possible SYNFIN scan";)
seq:这个规则选项引用TCP顺序号(sequence number)。基本上,它探测一个包是否有一个静态的顺序号集,因此很少用。它是为了完整性而包含进来的。
ack:ack 规则选项关键字引用 TCP 头的确认(acknowledge)部分。这个规则的一个实用的目的是:检查nmap tcp ping,nmap tcp ping把这个域设置为0,然后发送一个tcp ack flag置位的包来确定一个网络主机是否活着。例子:
alert any any -> 192.168.1.0/24 any (flags: A; ack: 0; msg: "NMAP TCP ping";)
window:这条规则选项指向 TCP 窗口大小。这个选项检查静态窗口大小,此外别无他用。包括它只是为了完整性。
itype:这条规则测试ICMP的type字段的值。它被设置为使用这个字段的数字值。要得到所有可能取值的列表,可以参见Snort包中自带的decode.h文件,任何ICMP的参考资料中也可以得到。应该注意的是,type字段的取值可以超过正常范围,这样可以检查用于拒绝服务或flooding攻击的非法type值的ICMP包。
icode:icode规则选项关键字和itype规则非常接近,在这里指定一个数值,Snort会探测使用该值作为code值的ICMP包。超出正常范围的数值可用于探测可疑的流量。
session:session关键字用于从TCP会话中抽取用户数据。要检查用户在telnet,rlogin,ftp或web sessions中的用户输入,这个规则选项特别有用。Session规则选项有两个可用的关键字作为参数:printable或all。Printable关键字仅仅打印用户可以理解或者可以键入的数据。All关键字使用16进制值来表示不可打印的字符。该功能会显著地降低Snort的性能,所以不能用于重负载环境。它适合于对二进制(tcpdump格式)log文件进行事后处理。例子:
log tcp any any <> 192.168.1.0/24 23 (session: printable;)
icmp_id:icmp_id选项检查ICMP ECHO数据包中ICMP ID数值是否是指定值。许多秘密通道(covert channel)程序使用静态ICMP字段通信,所以该选项在检查这种流量时非常有用。这个特别的插件用于增强由Max Vision编写的stacheldraht探测规则,但是在探测一些潜在攻击时确实有效。
icmp_seq:icmp_seq选项检查ICMP ECHO数据包中ICMP sequence字段数值是否是指定值。许多秘密通道(covert channel)程序使用静态ICMP字段通信,所以该选项在检查这种流量时非常有用。这个特别的插件用于增强由Max Vision编写的stacheldraht探测规则,但是在探测一些潜在攻击时确实有效(该字段的信息和 icmp_id 的描述几乎完全相同,实际上它们就是同样的东西)。
rpc:这个选项查看 RPC请求,并自动将应用(Application)、过程(procedure)和程序版本(program version)译码,如果所有三个值都匹配的话,该规则就显示成功。这个选项的格式为“应用、过程、版本”。在过程和版本域中可以使用通配符“*”。例子:
alert tcp any any -> 192.168.1.0/24 111 (rpc: 100000,*,3; msg:"RPC getport (TCP)";)
alert udp any any -> 192.168.1.0/24 111 (rpc: 100000,*,3; msg:"RPC getport (UDP)";)
alert udp any any -> 192.168.1.0/24 111 (rpc: 100083,*,*; msg:"RPC ttdb";)
resp:resp 关键字可以对匹配一条 Snort 规则的流量进行灵活的反应(flexible reponse-FlexResp)。FlexResp代码允许Snort主动地关闭恶意的连接。该插件合法的参数如表5所示。

表5 常见的响应选项
在向目标主机发送多种响应数据包时,这些选项组合使用。多个参数之间使用逗号分隔。使用resp选项时要小心,因为很容易就会使Snort陷入无限循环中,例如如下规则:
alert tcp any any -> 192.168.1.1/24 any (msg: "aiee!"; resp: rst_all;)
content_list:content_list 关键字允许多内容字符串被放在一个单独的内容匹配选项中,被匹配的字符串被存放在指定的文件中,而且每个字符串要单独占用一行。否则它们就等同于一个content字符串。这个选项是react关键字的基础。
react:注意,使用这个功能很容易使网络流量陷入回路。React关键字以匹配一个规则时所作出的灵活的反应为基础。基本的反应是阻塞一些引人注意的站点的用户的访问。响应代码允许Snort积极地关掉有冒犯行为的访问和/或发送一个通知给浏览者。这个通知可以包含用户自己的注释。这个选项包括如下的基本修饰词:block用来关闭连接并且发送一个通知;warm用来发送明显的警告信息。
基本修饰词可以和如下的附加修饰词组合使用:msg用来把msg选项的内容包含进阻塞通知信息中;proxy<port_nr>表示使用代理端口发送通知信息。大量的附加修饰词由逗号隔开,react 关键字将被放在选项的最后一项。例子:
alert tcp any any <> 192.168.1.0/24 80 (content: "bad.htm"; msg: "Not for children!"; react: block,msg;)
reference:这个关键字允许规则包含一个外面的攻击识别系统,这个插件目前支持几种特定的系统。这个插件被输出插件用来提供一个关于产生报警的额外信息的连接。例子:
alert tcp any any -> any 7070 (msg: "IDS411/dos-realaudio"; flags: AP; content:"|fff4 fffd 06|"; reference: arachNIDS,IDS411;)
alert tcp any any -> any 21 (msg: "IDS287/ftp-wuftp260-venglin-linux"; flags:AP; content: "|31c031db 31c9b046 cd80 31c031db|"; reference: arachNIDS,IDS287;reference: bugtraq,1387; reference: cve,CAN-2000-1574; )
sid:这个关键字被用来识别 Snort规则的惟一性。这个信息允许输出插件很容易地识别规则的 ID 号。sid 的范围是这样分配的,小于 100 保留做将来使用;100~1000000 包含在Snort发布包中;大于 1000000 作为本地规则使用。文件sid-msg.map 包含一个从msg标签到Snort规则ID的映射。这将被post-processing 输出模块用来映射一个ID到一个报警信息。
rev:这个关键字是被用来识别规则修改的。修改,随同Snort规则ID、允许签名和描述被较新的信息替换。
classtype:这个关键字把报警分成不同的攻击类。通过使用这个关键字和使用优先级,用户可以指定规则类中每个类型所具有的优先级。具有 classification 的规则有一个缺省的优先级。在文件classification.config中定义规则类。这个配置文件使用如下的语法:
config classification:<class name>,<class description>,<default priority>
priority:这个关键字给每条规则赋予一个优先级。一个classtype规则具有一个缺省的优先级,但这个优先级是可以被一条priority规则重载的。
uricontent:这个关键字允许只在一个请求的URI(URL)部分进行搜索匹配。它允许一条规则只搜索请求部分的攻击,这样将避免服务数据流的错误报警。关于这个关键字的参数的描述可以参考content关键字部分。这个选项将和HTTP解析器一起工作(只能搜索第一个“/”后面的内容)。
tag:这个关键字允许规则记录不仅仅是触发这条规则的那个数据包。一旦一条规则被触发,来自这个主机的数据包将被贴上“标签”。被贴上标签的数据流将被记录用于随后的响应代码和提交攻击流量的分析。
session 记录触发这条规则的会话的数据包。
host 记录激活tag规则的主机的所有数据包(这里将使用[direction]修饰词)。
count Count 指定一个单位的数量。这个单位由<metric>给出。
metric
packets 标记主机/会话的<count>个数据包。
seconds 标记主机/会话的<count>秒。
例子:
alert tcp !$HOME_NET any -> $HOME_NET 143 (flags: A+; content: "|e8 c0ff ffff|/bin/sh"; tag: host, 300, packets, src; msg: "IMAP Buffer overflow,tagging!";)
alert tcp!$HOME_NET any-> $HOME_NET 23(flags: S;tag:session,10,seconds;msg: "incoming telnet session";)
ip_proto:ip_proto 关键字允许检测 IP 协议头。这些协议可以是由名字标识的,参考/etc/protocols文件。在规则中要谨慎使用ip_protocol关键字。例子:
alert ip !$HOME_NET any -> $HOME_NET any (msg: "IGMP traffic detected"; ip_proto: igmp;)
sameIP:Sameip关键字允许规则检测源IP和目的IP是否相等。例子:
alert ip $HOME_NET any -> $HOME_NET any (msg: "SRC IP==DST IP"; sameip;)
flow:这个选项要和TCP流重建联合使用。它允许规则只应用到流量流的某个方向上。这将允许规则只应用到客户端或者服务器端。这将能把内网客户端浏览Web页面的数据包和内网服务器所发送的数据包区分开来。这个确定的关键字能够代替标志:A+这个标志在显示已建立的TCP连接时都将被使用。选项:
to_client 触发服务器上从A到B的响应。
to_server 触发客户端上从A到B的请求。
from_client 触发客户端上从A到B的请求。
from_server触发服务器上从A到B的响应。
established 只触发已经建立的TCP连接。
stateless 不管流处理器的状态都触发(这对处理那些能引起机器崩溃的数据包很有用)。
no_stream 不在重建的流数据包上触发(对dsize 和 stream4 有用)。
only_stream 只在重建的流数据包上触发。
例子:
alert tcp !$HOME_NET any -> $HOME_NET 21 (flow: from_client; content: "CWD incoming"; nocase; msg: "cd incoming detected"; )
alert tcp !$HOME_NET 0 -> $HOME_NET 0 (msg: "Port 0 TCP traffic"; flow: stateless;)
fragoffset:这个关键字允许把 IP 分段偏移值和一个十进制数相比较。为了抓到一个 IP会话的第一个分段,可以使用这个 fragbits 关键字并且和 fragoffset:0 选项一起查看更多的分段选项。例子:
alert ip any any -> any any (msg: "First Fragment"; fragbits: M; fragoffset: 0;)
rawbytes:rawbytes关键字允许规则查看telnet 解码数据来处理不常见的数据。这将使得telnet 协议代码独立于预处理程序来检测。这是对前面的content 的一个修饰。例子:
alert tcp any any -> any any (msg: "Telnet NOP"; content: "|FF F1|"; rawbytes;)
distance:distance 关键字是content关键字的一个修饰词,确信在使用 content时模式匹配间至少有N个字节存在。它被设计成在规则选项中和其他选项联合使用。例子:
alert tcp any any -> any any (content: "2 Patterns"; content: "ABCDE"; content:"EFGH"; distance: 1;)
within:Winthin关键字是content关键字的一个修饰词,确保在使用content时模式匹配间至多有N个字节存在。它被设计成在规则选项中和distance选项联合使用。例子:
alert tcp any any -> any any (content: "2 Patterns"; content: "ABCDE"; content:"EFGH"; within: 10;)
Byte_Test:测试一个字节的域为特定的值。能够测试二进制值或者把字节字符串转换成二进制后再测试。
bytes_to_convert 从数据包取得的字节数。
operator 对检测执行的操作 (<、>、=、!)。
value 和转换后的值相测试的值。
offset 开始处理的字节在负载中的偏移量。
relative 使用一个相对于上次模式匹配的相对的偏移量。
big 以网络字节顺序处理数据(缺省)。
little 以主机字节顺序处理数据。
string 数据包中的数据以字符串形式存储。
hex 把字符串数据转换成十六进制数形式。
dec 把字符串数据转换成十进制数形式。
oct 把字符串数据转换成八进制数形式。
例子:
alert udp $EXTERNAL_NET any -> $HOME_NET any (msg:"AMD procedure 7 plog overflow"; content: "|00 04 93 F3|"; content: "|00 00 00 07|";distance: 4; within: 4;byte_test: 4,>,1000,20,relative;)
alert tcp $EXTERNAL_NET any -> $HOME_NET any (msg:"AMD procedure 7 plog overflow"; content: "|00 04 93 F3|"; content: "|00 00 00 07|"; distance: 4; within: 4;byte_test: 4,>,1000,20,relative;)
Byte_Jump:Byte_jump 选项用来取得一定数量的字节,并把它们转换成数字形式,跳过一些字节以进一步进行模式匹配。这就允许相对模式匹配在网络数据中进行数字值匹配。
bytes_to_convert 从数据包中选出的字节数。
offset 开始处理的字节在负载中的偏移量。
relative 使用一个相对于上次模式匹配的相对的偏移量。
big 以网络字节顺序处理数据(缺省)。
little 以主机字节顺序处理数据。
string 数据包中的数据以字符串形式存储。
hex 把字符串数据转换成十六进制数形式。
dec 把字符串数据转换成十进制数形式。
oct 把字符串数据转换成八进制数形式。
align 以32位为边界对转换的字节数对齐,即转换的字节数为4的倍数。
例子:
alert udp any any -> any 32770:34000 (content: "|00 01 86 B8|"; content: "|00 00 00 01|";distance:4;within:4;byte_jump:4,12,relative,align;byte_test:4,>,900,20,relative; msg: "statd format string buffer overflow";)
三、预处理程序
预处理程序从Snort版本1.5开始引入,使得Snort的功能可以很容易地扩展,用户和程序员能够将模块化的插件方便地融入Snort之中。预处理程序代码在探测引擎被调用之前运行,但在数据包译码之后。通过这个机制,数据包可以通过额外的方法被修改或分析。使用preprocessor关键字加载和配置预处理程序。在Snort规则文件中的preprocessor指令格式如下:
preprocessor <name>: <options>
例子:
preprocessor minfrag: 128
1、HTTP Decode
HTTP Decode用于处理HTTP URI字符串并且将串中的数据转化为可读的ASCII字串。HTTP对于一些特性定义了一个十六进制编码方法,例如字符串%20被解释成一个空格。Web服务器被设计成能够处理无数的客户端并且支持多种不同的标准。
格式:
http_decode:<port list> [unicode] [iis_alt_unicode] [ double_encode][iis_flip_slash] [full_whitespace]
例子:
preprocessor http_decode: 80 8080 unicode iis_flip_slash iis_alt_unicode
2、Portscan Detector
Snort Portscan预处理程序的用处是向标准记录设备中记录从一个源IP地址来的端口扫描的开始和结束。如果指定了一个记录文件,在记录扫描类型的同时也记录目的IP地址和端口。
端口扫描定义为在时间T(秒)之内向超过P个端口进行TCP连接尝试,或者在时间T (秒)之内向超过P个端口发送UDP数据包。端口扫描可以是对任一IP地址的多个端口,也可以是对多个IP地址的同一端口进行。现在这个版本可以处理一对一和一对多方式的端口扫描,下一个完全版本将可以处理分布式的端口扫描(多对一或多对多)。端口扫描也包括单一的秘密扫描(stealth scan)数据包,比如NULL,FIN,SYNFIN,XMAS等。如果包括秘密扫描的话,端口扫描模块会对每一个扫描数据包告警。为避免这种情况,可以在 Snort 标准发行版中的 scan-lib 文件里把有关秘密扫描数据包的小节注释掉,这样对每次扫描就只记录一次。如果使用外部记录特性,可以在记录文件中看到(端口扫描的)技术和类型。该模块的参数如下:
network to monitor - 监视端口扫描的目标网络以network/CIDR表示。
number of ports - 在探测期间访问的端口数目。
detection period - 以秒计数的端口访问时间限制。
logdir/filename - 告警信息存放的目录/文件名,告警也可以写入标准的告警文件中。
格式:
portscan:<monitor network><number of ports><detection period><file path>
例子:
preprocessor portscan: 192.168.1.0/24 5 7 /var/log/portscan.log
Portscan Ignorehosts
如果用户的服务器(比如NTP,NFS和DNS服务器)会妨碍端口扫描的探测,可以通知portscan模块忽略源自这些主机的TCP SYN和UDP端口扫描。该模块的参数为IPs/CIDR的列表。
格式:
portscan-ignorehosts: <host list>
例子:
preprocessor portscan-ignorehosts: 192.168.1.5/32 192.168.3.0/24
Frag2
Frag2 是一个新的 IP 碎片重组预处理器。Frag2 的内存使用和碎片时间超时选项是可配置的。不给出参数,Frag2 将使用缺省的内存量(4MB)和时间超时值(60s)。这个时间值用来决定一个没有重组的分段将被丢弃的时间长度。
格式
preprocessor frag2: [memcap <xxx>], [timeout <xx>], [min_ttl <xx>],[detect_state_problems],[ttl_limit<xx>]
timeout<seconds> 在状态表中保存一个不活跃的流的最大时间值,如果发现活动就重新刷新对话并且这个会话被自动拾起。缺省值是30s。
memcap<bytes> 内存消耗的最大值,如果超出这个值,Frag2就强制削减那些不活跃的会话,缺省值是 4MB。detect_state_problems turns on alerts for events such as overlapping fragments
min_ttl<xx> 设置Frag2接受的最小ttl值。
detect_state_problems 发现重叠分段时报警。
ttl_limit<xx> 设置ttl的极限值,它可以避免报警 (初始化段 TTL+/- TTL Limit)。
例子:
preprocessor frag2: memcap 16777216,timeout 30
3、Stream4
Stream4 模块使 Snort 具有 TCP 流重新组装和状态分析能力。强壮的流重组能力使得Snort能够忽视无“状态”攻击,例如,stick粘滞位攻击。Stream4也能够给大量用户提供超过256个TCP同步连接。Stream4缺省配置时能够处理32768个TCP同步连接。Stream4有两个可配置的模块,stream4 preprocessor 和相关的 stream4_reassemble 插件。stream4_reassemble有如下选项:
Stream4 格式:
preprocessor stream4: [noinspect], keepstats [machine|binary], [timeout<seconds>], [memcap <bytes>], [detect_scans], [detect_state_problems],[disable_evasion_alerts],[ttl_limit<count>]
noinspect 关闭状态监测能力。
keepstats [machine|binary]保持会话统计,如果是“machine”选项就从机器以平坦的模式读入,如果是“binary”选项就用统一的二进制模式输出。
timeout<seconds> 在状态表中保存一个不活跃的流的最大时间值,如果发现活动就重新刷新对话并且这个会话被自动拾起。缺省值是30秒。
memcap<bytes> 内存消耗的最大值,如果超出这个值,Frag2就强制削减那些不活跃的会话,缺省值是8MB。
detect_scans 打开portscan 的报警能力。
detect_state_problems 打开流事件报警能力,例如,没有RST的数据包、带有数据的SYN包和超出窗口序列号的包。
disable_evasion_alerts 关闭事件报警能力,例如,TCP重叠。
ttl_limit 设置ttl的极限值。
Stream4_Reassemble 格式:
preprocessor stream4_reassemble: [clientonly],[serveronly],[noalerts],[ports <portlist>]
clientonly 对一个连接的客户端提供重组
serveronly 对一个连接的服务器端提供重组
noalerts 对于插入和逃避攻击事件不发出报警
ports<portlist> - 一个空格分隔的执行重组的端口列表,all将对所有的端口进行重组。缺省对如下端口重组:21 23 25 53 80 110 111 143和513。
注:在配置文件中仅仅设置 stream4 和 stream4_reassemble 命令而没有参数,它们将会使用缺省的参数配置。Stream4引入了一个新的命令行参数:-z 。在TCP流量中,如果指定了 –z 参数,Snort将只对那些通过三次握手建立的流以及那些协作的双向活动的流(即,一些流量走一个方向而其他一些除了一个RST或FIN外走相反方向)检测报警。当设置了-z 选项后Snort就完全忽略基于TCP的stick/snot攻击。
4、Conversation
Conversation 预处理器使 Snort 能够得到关于协议的基本的会话状态而不仅仅是由spp_stream4处理的TCP状态。
目前它使用和stream4相同的内存保护机制,所以它能保护自己免受DOS攻击。当它接收到一个网络不允许的协议的数据包时,它也能产生一个报警信息。要做到这一点,请在IP协议列表中设置允许的IP协议,并且当它收到一个不允许的数据包时,它将报警并记录这个数据包。
格式:
preprocessor conversation: [allowed_ip_protocols <protonumbers|all>],[timeout<sec>],[alert_odd_protocols],[max_conversations<number>]
5、Portscan2
这个模块将检测端口扫描。它要求包含 Conversation预处理器以便判定一个会话是什么时间开始的。它的目的是能够检测快速扫描,例如,快速的nmap扫描。
格式:
preprocessor portscan2: [scanners_max <num>], [targets_max <num>],[target_limit<num>],[port_limit<num>],[timeout<sec>]
scaners_max 一次所支持的扫描一个网络的主机数
targets_max 分配代表主机的节点的最大数
target_limit 在一个扫描触发前,一个扫描器所允许扫描的最大的主机数
port_limit 在一个扫描触发前,一个扫描器所允许扫描的最大的端口数
timeout 一个扫描行为被忘记的秒数
6、Telnet Decode
telnet_decode 预处理器使Snort能够标准化telnet会话数据的控制协议字符。它把数据包规格后分开保存,这样原始数据就能够通过 rawbytes content 修饰词来记录或者检验了。缺省情况下,它运行在21,23,25和119端口。
格式:
preprocessor telnet_decode: <ports>
RPC Decode
Rpc_decode 预处理器将 RPC的多个碎片记录组合成一个完整的记录。它是通过将数据包放在标准缓存中来做到这一点的。如果打开 stream4 预处理器功能。它将只处理客户端的流量。它缺省运行在 111和 32771端口。
格式:
preprocessor rpc_decode: <ports> [ alert_fragments ] [no_alert_multiple_requests] no_alert_large_fragments] [no_alert_incomplete]
7、Perf Monitor
这个模块是用来评估 Snort 各方面性能的一个工具。它的输出格式和参数格式都是变化的,在这里就不给出注释了。
8、Http Flow
使用这个模块可以忽略HTTP头后面的HTTP服务响应。
四、输出插件
输出插件使得Snort在向用户提供格式化输出时更加灵活。输出插件在Snort的告警和记录子系统被调用时运行,在预处理程序和探测引擎之后。规则文件中指令的格式非常类似于预处理程序。
注意:如果在运行时指定了命令行的输出开关,在 Snort 规则文件中指定的输出插件会被替代。例如,如果在规则文件中指定了alert_syslog插件,但在命令行中使用了“-A fast”选项,则alert_syslog插件会被禁用而使用命令行开关。多个输出插件是在Snort的配置文件中指定的。当指定多个输出插件时,它们被压入栈并且在事件发生时按顺序调用。关于标准的记录和报警系统,输出模块缺省把数据发送到 /var/log/snort,或者通过使用-l 命令行参数输出到一个用户指定的目录。在规则文件中通过指定output关键字,使得在运行时加载输出模块。
格式:
output <name>: <options>
例子:
output alert_syslog: LOG_AUTH LOG_ALERT
Alert_syslog
该插件向 syslog 设备发送告警(很像命令行中的-s 开关)。该插件也允许用户指定记录设备,优先于Snort规则文件中的设定,从而在记录告警方面给用户更大的灵活性。
可用关键字:
选项(Options)
LOG_CONS
LOG_NDELAY
LOG_PERROR
LOG_PID
设备(Facilities)
LOG_AUTH
LOG_AUTHPRIV
LOG_DAEMON
LOG_LOCAL0
LOG_LOCAL1
LOG_LOCAL2
LOG_LOCAL3
LOG_LOCAL5
LOG_LOCAL6
LOG_LOCAL7
LOG_USER
优先级(Priorities)
LOG_EMERG
LOG_ALERT
LOG_CRIT
LOG_ERR
LOG_WARNING
LOG_NOTICE
LOG_INFO
LOG_DEBUG
格式:
alert_syslog: <facility> <priority> <options>
Alert_fast
将报警信息快速地打印在指定文件的一行里。它是一种快速的报警方法,因为不需要打印数据包头的所有信息。
格式:
alert_fast: <output filename>
例子:
output alert_fast: alert.fast
Alert_full
打印数据包头所有信息的报警。这些报警信息写到缺省的日志目录(/var/log/snort)或者写到命令行指定的目录。在日志目录内,每个IP都创建一个目录。产生报警的数据包被解码后写到这个目录下的文件里。这些文件的创建将大大降低 Snort 的性能。所以这种输出方法对大多数不适用,但那些轻量级的网络环境还是可以使用的。
格式:
alert_full: <output filename>
例子:
output alert_full: alert.full
Alert_smb
这个插件将把WinPopup报警信息发送给NETBIOS命名的机器上的一个文件。并不鼓励使用这个插件,因为它以Snort权限执行了一个外部可执行二进制程序,通常是 root权限。那个工作站上接受报警信息的文件每行存放一条报警信息。
格式:
alert_smb: <alert workstation filename>
例子:
output alert_smb: workstation.list
Alert_unixsock
打开一个UNIX套接字,并且把报警信息发送到那里。外部的程序/进程会在这个套接字上侦听并实时接收这些报警数据。
格式:
alert_unixsock
例子:
output alert_unixsock
Log_tcpdump
log_tcpdump 插件将数据包记录到 tcpdump 格式的文件中。这便于使用已有的多种检查tcpdump格式文件的工具,来对收集到的流量数据进行后处理工作。该插件只接受一个参数,即输出文件名
格式:
log_tcpdump: <output filename>
例子:
output log_tcpdump: snort.log
database
该插件由Jed Pickel提供将Snort数据记录到Postgres SQL数据库中。更多的有关安装和配置该插件的信息可以在Incident.org (http://www.incident.org/snortdb)找到。这个插件的参数是数据库名称和一个参数列表。参数由格式parameter=argument来指定。可用参数如下:
host - 连接主机。如果指定了一个非零字串,就使用TCP/IP通信。如果不指定主机名,就会使用Unix domain socket连接。
port - 连接服务器主机的端口号,或者是Unix-domain连接的socket文件名扩展。
dbname - 数据库名。
user - 数据库中身份认证用的用户名。
password - 如果数据库要求口令认证,就使用这个口令。
sensor_name 为snort指定一个名字。如果不指定,这里就自动产生一个。
encoding 因为数据包负载和选项都是二进制的,所以没有一个简单的方法把它存储在数据库中。没有使用 BLOBS,因为它们在跨数据库时不是那么轻便的。所以提供了一个encoding 选项。
detail 要存储多少细节数据,可以选择:full (缺省值)记录一个引起报警数据包的所有的细节(包括 ip/tcp 选项和负载)。fast 只记录少量数据。如果选择了这个选项,将削减了潜在的分析能力,但这仍是一些应用的最佳选项。这将记录下面的字段(timestamp、signature、source ip、destination ip、source port、destination port、tcp flags、protocol)。
此外,还必须定义一个记录方法和数据库类型。有两种记录方法,log 和 alert。设置为log类型,将启动这个程序的数据库记录功能。如果设置为log类型,输出链表将调用这个插件。设置为alert类型,将启动这个程序的数据库报警输出功能。
当前共有四种数据库类型:MySQL、PostgreSQL、Oracle和 unixODBC-兼容数据库。
格式:
output database: log,mysql,dbname=snort user=snort host=localhost password=xyz
CSV
CSV输出插件可以将报警数据以一种方便的形式输出到一个数据库。这个插件要求两个参数,一个全路径文件名和输出模式选项。下面是模式选项列表。如果模式选项缺省,就按模式选项列表中的顺序输出。
timestamp
msg
proto
src
srcport
dst
dstport
ethsrc
ethdst
ethlen
tcpflags
tcpseq
tcpack
tcplen
tcpwindow
ttl
tos
id
dgmlen
iplen
icmptype
icmpcode
icmpid
icmpseq
格式:
output alert_CSV: <filename> <format>
例子:
output alert_CSV: /var/log/alert.csv default
output alert_CSV: /var/log/alert.csv timestamp,msg
Unified
Unified输出插件被设计成尽可能快的事件记录方法。它记录一个事件到一个报警文件和一个数据包到一个日志文件。报警文件包含一个事件的主要信息(ips、protocol、port、 message id)。日志文件包含数据包信息的细节(一个数据包拷贝及相关的事件ID)。
这两个文件都是以spo_unified.h文件中描述的二进制形式写的。以unix秒为单位的时间将附加到每个文件的后面写出。
格式:
output alert_unified: <file name>
output log_unified: <file name>
例子:
output alert_unified: snort.alert
output log_unified: snort.log
Log Null
有时创建这样的规则是必要的,即在某些情况下能够发出报警而不记录数据包。当使用log_null插件时就相当于命令行的-N选项,但这个插件可以工作在一个规则类型上。
格式:
output log_null
ruletype info {
type alert
output alert_fast: info.alert
output log_null
}
当编写 Snort 规则时,首先考虑的是效率和速度。好的规则要包含 content 选项。2.0版本以后,Snort 改变了检测引擎的工作方式,在第一阶段就作一个集合模式匹配。一个content 选项越长,这个匹配就越精确。如果一条规则不包含 content 选项,它们将使整个系统慢下来。
当编写规则时,尽量要把目标定位在攻击的地方(例如,将目标定位在1025的偏移量等)而不仅仅是泛泛的指定(如,在这匹配脚本代码)。Content 规则是大小写敏感的(除非使用了nocase选项)。不要忘记content是大小写敏感的和大多数程序的命令都是大写字母。FTP就是一个很好的例子。考虑如下的规则:
alert tcp any any -> 192.168.1.0/24 21 (content: "user root"; msg: "FTP root login";)
alert tcp any any -> 192.168.1.0/24 21 (content: "USER root"; msg: "FTP root login";)
上面的第二条规则能检测出大多数的自动以 root 登录的尝试,而第一条规则就不行。Internet 守护进程在接受输入时是很随便的。在编写规则时,很好地理解协议规范将降低错过攻击的机会。
探测引擎运用规则的顺序和它们在规则中的书写顺序无关。内容规则选项总是最后一个被检验。利用这个事实,应该先运用别的快速规则选项,由这些选项决定是否需要检查数据包的内容。例如:在TCP会话建立起来后,从客户端发来的数据包,PSH和ACK这两个TCP标志总是被置位的。如果想检验从客户端到服务器的有效数据,利用这个事实,就可以先进行一次TCP标志检验,这比模式匹配算法(pattern match algorithm)在计算上节约许多。使用内容选项的规则要加速的一个简便方法就是也进行一次标志检验。基本思想是,如果PSH和 ACK 标志没有置位,就不需要对数据包的有效数据进行检验。如果这些标志置位,检验标志而带来的计算能力消耗是可以忽略不计的。
微信公众号:计算机与网络安全
ID:Computer-network