卡内基梅隆研究成果分享:送给DBA,让数据库自己解决繁琐调参!

数据库有很多参数,比如MySQL有几百个参数,Oracle有上千个参数。这些参数控制着数据库的方方面面,很大程度的影响了数据库的性能。比如缓存容量和检查点频次。
DBA会花大量时间根据经验来调优数据库的参数,而公司需要花很大的价钱来雇资深的DBA。但是对于不同的硬件配置,不同的工作负载,对应的最优参数文件都是不同的。DBA不能简单的重复使用之前调好的参数文件。这些复杂性令数据库调优变得更加困难。
为解决这些问题,卡内基梅隆大学数据库小组的教授、学生和研究人员开发了一个数据库自动调参工具OtterTune,它能利用机器学习对数据库的参数文件自动化的调优,能利用已有的数据训练机器学习模型,进而自动化的推荐最优参数。它能很好的帮助DBA进行数据库调优,将DBA从复杂繁琐的调参工作中解放出来。
以前网上就有对OtterTune的报道,标题都比较吓人。比如这篇:运维要失业了? 机器学习可自动优化你的数据库管理系统[1]。
OtterTune的目的是为了帮助DBA,让数据库部署和调优更加容易,用机器来代替数据库调参这个冗繁但又很重要的工作,甚至不需要专业知识也能完成。
OtterTune现在完全开源,Github上的版本就可以使用[2]。这个文档中有一个步骤较全的例子可以上手,在AWS的m5d.xlarge机子上调优PostgreSQL 9.6数据库,吞吐量从默认参数文件的每秒约500个事务提高到每秒约1000个事务,有兴趣的朋友不妨试一试。
不过惊喜的是,我们发现这个通用模型在业界的很多地方都有真实的应用,不仅能调优数据库的参数,还能够调优操作系统内核的参数,甚至可以尝试调优机器学习模型的参数。比如以下场景:
某欧洲银行需要自动化调优数据库集群的参数以提高性能,减少人工成本。
某大型云厂商需要在不影响性能的前提下尽量调低分配的资源(如内存), 减少硬件成本。
某纽约高频交易公司需要调优机器的操作系统参数以优化机器性能,减少延迟,从而增加利润。
本文将介绍OtterTune的内部原理,以及OtterTune的一些最新进展和尝试,如用深度强化学习来调优数据库参数。
由于本人水平有限,写的不对的地方欢迎大家指正。更多资料请参考2017年SIGMOD[3]和2018年VLDB的论文[4]。
一、客户端和服务端
OtterTune分为客户端和服务端。目标数据库是用户需要调优参数的数据库:
OtterTune的客户端安装在目标数据库所在机器上,收集目标数据库的统计信息,并上传到服务端。
服务端一般配置在云上,它收到客户端的数据,训练机器学习模型并推荐参数文件。
客户端接到推荐的参数文件后,配置到目标数据库上,测量其性能。以上步骤可以重复进行直到用户对OtterTune推荐的参数文件满意。
当用户配置好OtterTune时,它能自动的持续推荐参数文件并把所得结果上传到服务端可视化出来,而不需要DBA的干预。这样能很大简化DBA的工作,比如DBA可以配置好OtterTune后回家睡觉,第二天早上OtterTune可能就在一晚上的尝试中找到了好的参数文件。
而OtterTune尝试的所有参数文件及对应的数据库性能和统计信息都能在服务端的可视化界面上轻易找到。

上图是OtterTune的整体架构:
客户端中controller由Java实现,用JDBC访问目标数据库来收集其统计信息;driver则用了Python的fabric,主要与服务端交互。
服务端用了Django来构建网站,并用Celery来调度机器学习任务;机器学习则调了tensorflow和sklearn。
关于OtterTune架构更详细的内容可以参考2018 VLDB的demo paper[4].
二、随机采样
为了叙述方便,我们不妨假设参数文件中有10个重要参数需要调优。
我们将参数文件表示为:X=(x1,x2,…x10)
对应的数据库性能为Y。Y可以是吞吐量,延迟时间,也可以是用户自己定义的测量量。
我们假设目标测量量是延迟时间。则我们需要做的是调整这10个数据库参数的值,使得数据库的延迟尽可能少。即找到合适的X,使Y尽可能小。一个好的参数文件会降低数据库的延迟,即X对应的Y越小,我们说X越好。
最简单和直观的方法便是随机的进行尝试,即给这10个要调的参数最大和最小值,在这范围内随机地选择值进行尝试。显然这样随机的方法并不高效,可能需要试很多次才能得到好的参数文件。OtterTune也支持这种随机方法以在没有训练数据时收集数据。
相比随机采样,还有一种更有效率的采样方法叫做拉丁超立方采样。
比如在0到3之间随机找3个数,简单随机抽样可能找的三个数都在0到1之间。而拉丁超立方采样则在0到1间找一个数,1到2间找一个数,2到3间找一个数,更加分散。
推到高维也是类似的情况。如下图是二维的情形,x1和x2取值都在0到1之间,用拉丁超立方采样来取5个样本点,先将x1和x2分成不同的范围,再取样本点使得每一行中只有一个样本点,每一列中也只有一个样本点。这样能避免多个样本点出现在相近的范围内,使其更加分散。
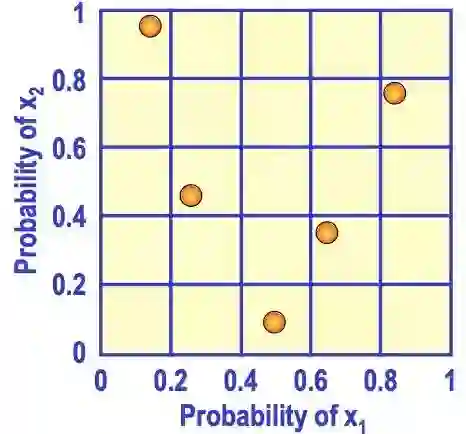
对于OtterTune来说,简单随机采样尝试的参数文件可能更集中和相似,而拉丁超立方采样尝试的参数文件更分散和不同。显然后者能给我们更多的信息,因为尝试相似的参数文件很可能得到的数据库性能也相似,信息量少,而尝试很不同的参数文件能更快的找到效果好的一个。
三、高斯过程回归
上述的采样方法并没有利用机器学习模型对参数文件的效果进行预测。
当OtterTune没有数据来训练模型时,可以利用上述方法收集初始数据。
当我们有足够的数据(X,Y)时,OtterTune训练机器学习模型进行回归,即估计出函数f:X→Y,使得对于参数文件X,用f(X)来估计数据库延迟Y的值。则问题变为寻找合适的X,使f(X)的值尽量小。这样我们在f上面做梯度下降即可找出合适的X。
如下图所示,横坐标是两个参数——缓存大小和日志文件大小,纵坐标是数据库延迟(越低越好):
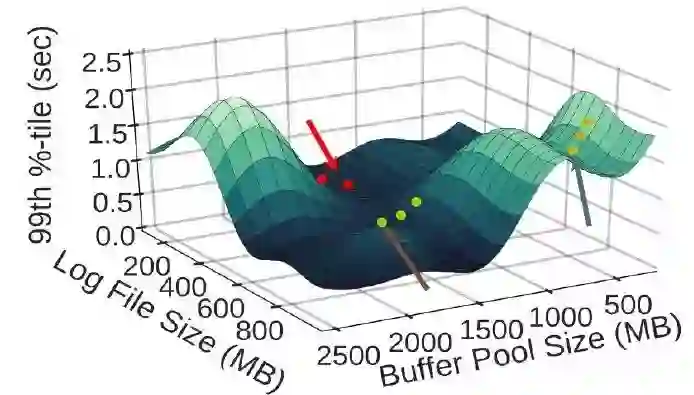
OtterTune用回归模型估计出了f,即给定这两个参数值,估计出其对应的数据库延迟。接着用梯度下降找到合适的参数值使延迟尽可能低。
OtterTune用高斯过程回归来估计上述的函数f。用高斯回归的好处之一是它不仅能在给定X时估计对应的Y值,还能估计它的置信区间。
这能恰当的刻画调参的情况:对于同样的参数文件X, 在数据库上多次跑相同的查询时,由于误差缘故,每次得到的数据库性能也可能不一样。比如同样的参数文件和查询语句,这次执行的数据库延迟是1.8秒,下次执行的延迟可能是2秒,但每次得到的延迟很大概率是相近的。
高斯过程回归能估计出均值m(X)和标准差s(X),进而能求出置信区间。比如上述例子中,通过回归我们估计其延迟的均值是1.9秒,标准差是0.1秒,则其95%的概率在1.7秒和2.1秒之间。
再来说说探索(exploration)和利用(exploitation):
探索即在数据点不多的未知区域探索新的点。
利用即在数据点足够多的已知区域利用这些数据训练机器学习模型进行估计,再找出好的点。
比如说我们已知10个数据点(X,Y),有9个点的X在0到1之间,有1个点的X在1到2之间。X在0到1之间的数据点较多,可以利用这些数据点进行回归来估计f:X->Y,再利用f来找到合适的X使估计的Y值尽量好,这个过程即为利用。
而探索则是尝试未知区域新的点,如X在1到2间的点只有一个已知点,信息很少,很难估计f。我们在1到2间选一个X点进行尝试,虽然可能得到的效果不好,但能增加该区域内的信息量。当该区域内已知点足够多时便能利用回归找到好的点了。
OtterTune推荐的过程中,既要探索新的区域,也要利用已知区域的数据进行推荐。即需要平衡探索和利用,否则可能会陷入局部最优而无法找到全局最优的点。比如一直利用已知区域的数据来推荐,虽然能找到这个区域最好的点,但未知区域可能有效果更好的点未被发现。
如何很好的平衡探索和利用一直是个复杂的问题,既要求能尽量找到好的点,又要求用尽量少的次数找到这个点。
而OtterTune采用的高斯过程回归能很好的解决这个问题。核心思想是当数据足够多时,我们利用这些数据推荐;而当缺少数据时,我们在点最少的区域进行探索,探索最未知的区域能给我们最大的信息量。
以上利用了高斯过程回归的特性:它会估计出均值m(X)和标准差s(X),若X周围的数据不多,则它估计的标准差s(X)会偏大,直观的理解是若数据不多,则不确定性会大,体现在标准差偏大。反之,数据足够时,标准差会偏小,因为不确定性减少。
而OtterTune用置信区间上界Upper Confidence Bound来平衡探索和利用。
不妨假设我们需要找X使Y值尽可能大。则U(X) = m(X) + k*s(X), 其中k > 0是可调的系数。我们只要找X使U(X)尽可能大即可。
若U(X)大,则可能m(X)大,也可能s(X)大。
若s(X)大,则说明X周围数据不多,OtterTune在探索未知区域新的点。
若m(X)大,即估计的Y值均值大, 则OtterTune在利用已知数据找到效果好的点。公式中系数k影响着探索和利用的比例,k越大,越鼓励探索新的区域。
四、有数据和没数据
OtterTune用来训练模型的数据好坏很大程度上影响了其最终效果。只要有合适的训练数据,一般OtterTune前几次推荐的参数文件就能得到理想的效果。
而当缺少训练数据(或数据集中),甚至没有任何之前的数据时,OtterTune又该如何处理?
当OtterTune没有任何数据时,高斯过程回归也能有效的在尽量少的次数内找到好的参数文件。当数据少时,OtterTune倾向探索而非利用,而每次探索新的参数文件时都能尽量的增加信息量,从而减少探索的次数。
这种方法比随机采样和拉丁超立方采样都要高效。同时OtterTune也可先用拉丁超立方采样选取少量的一些参数文件进行尝试作为初始数据,之后再用高斯过程回归进行推荐。
其实在OtterTune之前,有系统iTuned[5]就用高斯过程回归在没有数据时推荐参数文件。
而OtterTune的最大的改进是利用之前收集的数据进行推荐以大幅度减少尝试的次数和等待时间,提高推荐效果。
想想看当OtterTune的一个服务端配置到云上,而多个客户端进行访问时,OtterTune会将所有用户尝试的参数文件和对应的性能数据存下来进行利用。这意味着用OtterTune的人越多,用的时间越长,它收集的训练数据越多,推荐效果越好。
除此之外,OtterTune还利用Lasso回归来自动的选取需要调整的重要参数。数据库有成百上千的参数,而我们只要调其中重要的几个,需要调整哪些参数可以根据DBA的经验,同时OtterTune也利用机器学习将参数的重要性排序,从而选出最重要的几个参数。
另外对于不同的工作负载,对应的最优参数文件也不同。如OLTP工作负载通常是很多个简单的查询(如insert,delete),而OLAP工作负载通常是几个复杂查询(通常有多个表的join)。对于OLAP和OLTP,他们需要调整的参数和最优的值都不相同。
OtterTune现在的做法是用一些系统的统计量(如读/写的字节数)来刻画工作负载,在已有数据中找到和用户工作负载最相似的一个,然后用最相似的工作负载对应的数据进行推荐。
五、深度强化学习
在OtterTune最新的进展中,我们尝试了深度强化学习的方法来进行数据库调参,因为我们发现数据库调参的过程能很好的刻画成强化学习的问题。
强化学习问题中有状态、动作,以及环境所给予的反馈。
如下图所示,整个过程是在当前状态(st)和环境的反馈(rt)下做动作(at),然后环境会产生下一状态(st+1)和反馈(rt+1),再进行下一个动作(at+1)。

数据库调参过程中,状态即是参数文件,动作即是调整某个参数的值,而反馈即是参数文件下数据库的性能。
所以我们对于当前的参数文件,调整某个参数的值,而得到新的参数文件,对这个新的参数文件做测试得到对应的数据库性能,再根据性能的好坏继续调整参数的值。
这样数据库调参的过程就被很好的刻画成强化学习的问题,而深度强化学习即是其中的状态或动作由神经网络来表示。
我们用了Deep Deterministic Policy Gradient (DDPG)算法,主要是因为DDPG能允许动作可以在连续的区间上取值。对于调参来说,动作即是调整某个参数的值,比如调整内存容量,DDPG允许我们尝试128MB到16GB的任意值,这个区间是连续的。
而很多别的算法只允许动作在离散区间上,比如只允许取几个值中的一个值。通过实现和优化DDPG,最终深度强化学习推荐出的参数文件与高斯过程回归推荐出的效果相似。但我们发现之前的高斯过程回归(GPR)更有优势,能用更少的时间和次数找到满意的参数文件。
如下图中所示,我们跑了TPC-H基准中的一条查询(Query 13),OtterTune一次次的推荐参数文件直到其达到好的效果(即对应的数据库延迟变低)。
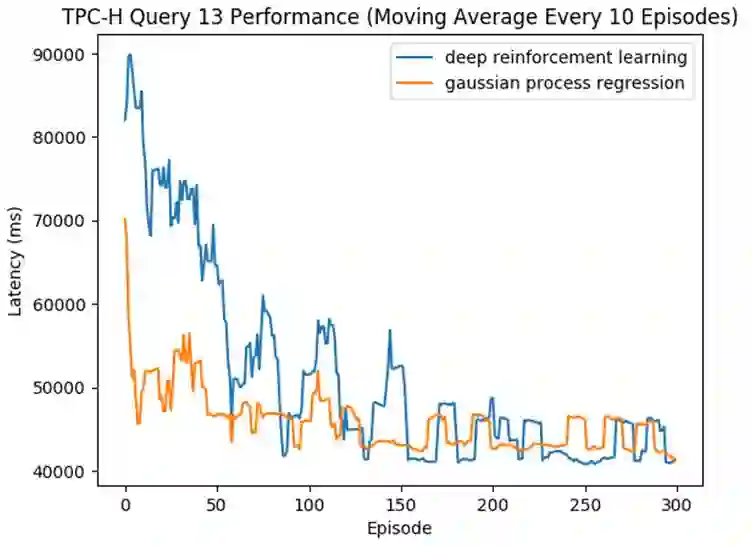
该图横坐标是推荐的次数,纵坐标是数据库的延迟,延迟越低越好。蓝线是深度强化学习,而黄线代表高斯过程回归模型。
可见两个模型最终推荐出的文件效果相似,但高斯过程回归用了更少的次数便收敛,推荐出了好的参数文件。而深度强化学习需要尝试更多的次数才能达到类似效果。
我们发现:
DDPG算法模型有一些参数也需要调整,而这些参数对效果的影响很大。调整算法模型的参数也是个费时费力的过程。这样就陷入尴尬的局面,OtterTune是用来自动调整数据库参数的工具,而OtterTune自己算法模型的参数也需要调整。相比而言,GPR的模型参数可以自动的进行调整,从而实现OtterTune真正的自动化。
GPR能用Upper Confidence Bound更好的平衡探索(exploration)和利用(exploitation),相比DDPG更加高效。 这在没有或缺少数据的情况下,GPR能用更少的次数找到好的参数文件。
DDPG是更加复杂的模型,其中还有神经网络,可解释性差。需要更多的数据和更长的时间来训练和收敛。虽然最后能达到和GPR一样的推荐效果,但往往需要更多的次数和更长的时间,意味着用户需要等更久才能得到满意的参数文件。
六、展望
对于数据库来说,有很多部分都能尝试与机器学习结合。比如预测数据库一段时间的工作负载,如通过挖掘数据库的日志来做自动预警,再到更核心的部分,如学习数据库索引,甚至帮助优化器做查询优化。
OtterTune专注的参数文件调优只是其中的一部分。由于OtterTune和数据库的交互只是一个参数文件,这使得该工具更加通用,理论上能适用于所有的数据库。
当要调参一个新的数据库时,我们只需要给OtterTune该数据库的一些参数和统计量信息即可,不需要去改动这个数据库的任何代码。
再者,OtterTune的通用框架也可以用于其他系统的调参,如我们尝试用OtterTune来调优操作系统的内核参数也取得了不错的效果。
现在的OtterTune仍有要改进的地方:
比如假定了硬件配置需要一样,而我们希望OtterTune能利用在不同的硬件配置上的数据来训练模型进行推荐。
再比如现在OtterTune每次只推荐一个文件,当有多个相同机器时,我们希望一次推荐多个文件并行的去尝试,这样能加快推荐速度。
另外还可以尝试与其他部分的机器学习方法结合,比如可以先用机器学习方法预测工作负载,再根据预测的工作负载提前调优参数文件。
用机器学习来优化系统是最近很火很前沿的一个话题,无论是在工业界还是在学术界。
全球最大数据库厂商Oracle如今的最大卖点便是autonomous database[6] ,即自适应性数据库,利用机器学习来自动优化数据库来减少DBA的干预,要知道在美国雇一个资深的DBA是多么困难的一件事。Oracle投入大量的专家和资金来做这件事便证明了它的工业价值。
学术上,一些ML和系统的大佬在前两年开了一个新的会议叫SysML[7],专注于机器学习和系统的交叉领域。更不用说越来越多的相关论文,比如卡内基梅隆大学的OtterTune,再如MIT和谷歌开发的用神经网络学习数据库的索引[8]。
最后以谷歌Jeff Dean在演讲中的话结尾:
计算机系统中充满了经验性的规则,到处是在用启发式的方法来做决定,而用机器学习来学系统的核心部分会让其变得更好更加自适应,这个领域充满着机会[9]。
[1]运维要失业了? 机器学习可自动优化你的数据库管理系统
www.sohu.com/a/146016004_465914
[2]https://github.com/cmu-db/ottertune
[3]Automatic Database Management System Tuning Through Large-scale Machine Learning. Dana Van Aken, Andrew Pavlo, Geoffrey J. Gordon, Bohan Zhang. SIGMOD 2017
[4]A Demonstration of the OtterTune Automatic Database Management System Tuning Service. Bohan Zhang, Dana Van Aken, Justin Wang, Tao Dai, Shuli Jiang, Jacky Lao, Siyuan Sheng, Andrew Pavlo, Geoffrey J. Gordon. VLDB 2018
[5]Tuning Database Configuration Parameters with iTuned. Songyun Duan, Vamsidhar Thummala, Shivnath Babu. VLDB 2009
[6]https://www.oracle.com/database/what-is-autonomous-database.html
[7]https://www.sysml.cc/
[8]The Case for Learned Index Structures. Tim Kraska, Alex Beutel, Ed H. Chi, Jeffrey Dean, Neoklis Polyzotis. SIGMOD 2018
-
[9]http://learningsys.org/nips17/assets/slides/dean-nips17.pdf

抢先掌握让智能为我所用的方法
而不是等着被智能替代
不妨来Gdevops北京站学点独家技能
↓↓点击链接了解更多详情及报名↓↓