腾讯云大数据 TBDS 在私有化场景万节点集群的实践

本次分享主要分为三个部分展开:第一部分是 Hadoop 体系下存算⼀体存在的问题;第二部分是 TBDS 存算分离架构和三层优化;第三部分是云原⽣环境下计算引擎优化和最佳实践,最后是对本次分享内容的总结。
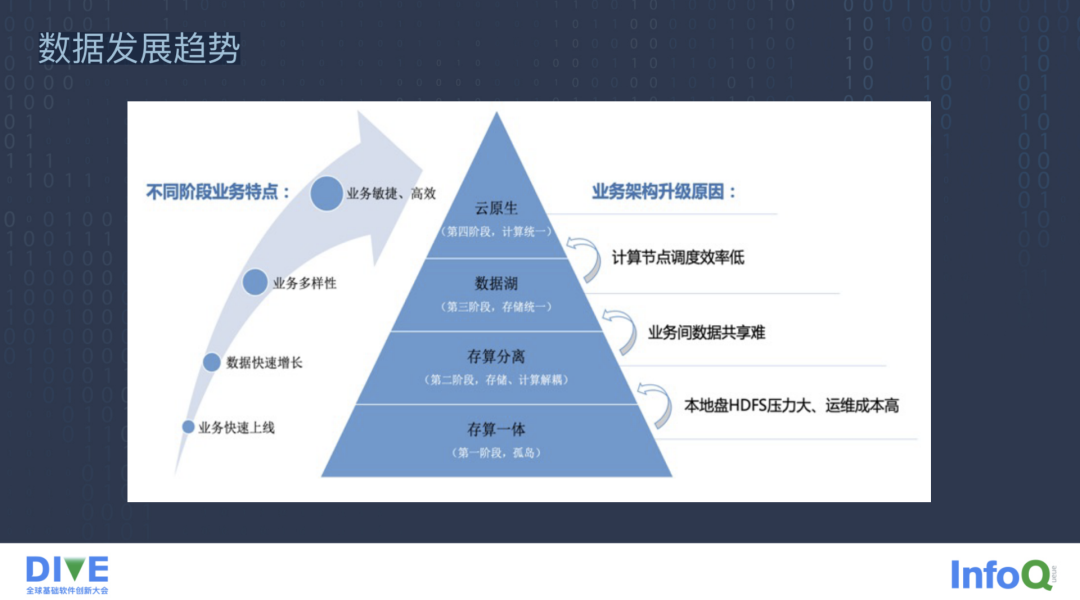
大数据发展多年以来,总体上根据业务特点主要可以分为四个阶段。
第一个阶段是以 Hadoop 体系为代表的存算一体阶段,存算一体顾名思义就是存储和计算部署在一起。Hadoop 就是 HDFS 的 DateNode 节点和 Yarn 的 NodeManager 节点部署在一起的形式。这种模式的好处是计算具有一定的数据本地性,减少了一定的网络 IO,有一定的加速作用,在集群规模较小且节点数较少的时候,每个节点存储分配到的文件相对较多,加速效果比较明显。
但是随着集群数据规模和节点的增加,本地加速的优势越来越小,由于集群节点对存储和计算的硬件配置要求都比较高,整体扩容的成本也在增加,HDFS 的 NameNode 元数据扩展性也会产生瓶颈,从而导致集群整体的规模上限也会产生瓶颈。
为了解决这个问题,进而催生了第二个阶段,即存算分离阶段。
存算分离顾名思义就是存储和计算独立分开部署,各自以分片的方式保证其自身的可扩展性。由于存储资源和计算资源对计算机硬件的配置要求不同,所以生产环境中对计算和存储的需求也在不断变化。
集群整体的机器成本,尤其是存储节点机器的成本会比存算一体阶段便宜很多,但存算分离最大的问题是计算节点会通过网络 IO 去远端存储拉取数据进行计算,所以计算速度和效率会比存算一体差很多。这个阶段的存算分离主要还只是一个噱头,或者说是一个概念,很少在大规模生产环境中使用。
第三个阶段是数据湖。数据湖解决了业务的多样性以及业务之间数据共享难的问题,比如说用户的一部分结构化数据存储在传统的 MySQL、Oracle 这类关系型数据库中,另外一部分统计的数据存储在 Hive 数仓里。
当 Hive 数仓想使用关系型数据库的数据进行 JOIN 关联查询就比较困难,这时候就需要通过 CDC 或 OGG 的方式让传统数据库中的数据实时入湖,在数据湖里用统一的表格式,比如说 Iceberg 或 Hudi 来提供数仓及上层来进行共享计算,总体上是为上层制造了一种更为融合的方式。
最后一个阶段就是云原生。云原生的目的是运用多个弹性的计算资源。,计算资源可以快速被申请和创建,但不必关心整体的调度细节以及调度过程中的容错、迁移、重建等一系列操作,这就是基于云原生的存算分离模式。像云数仓这种服务越来越火,存算分离也借助与云原生和缓存加速真正实现大规模生产实践的落地。
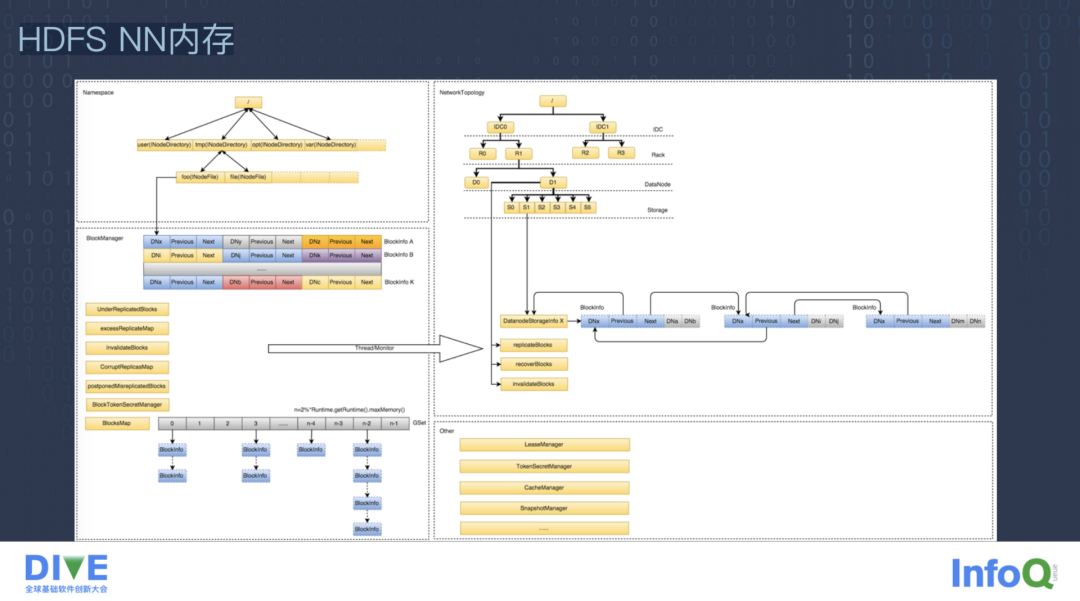
先来看一下 HDFS NameNode 的内存结构,其主要分为四个部分,左边是 Namespace 和 BlockManager,右边是网络拓扑和一些其他结构。
Namespace 维护了整个文件系统的目录结构。与 Linux 单机的文件系统类似,HDFS 文件系统的目录结构也是按照树状结构维护的,而且是一个非常巨大的树,树的叶子节点是 INodeFile 结构,这个结构里存储了文件所在 Block 块的引用。除了在内存常驻以外,部分数据也会定期 flush 到磁盘里,生成一个叫 FSImage 的文件,方便 NameNode 发生重启时从 FSImage 恢复整个 Namespace,集群中的目录和文件的总量就是整个 Namespace 目录树中包含节点的总数,这块内存也会随着集群内文件和目录个数的增加而成比例增长。
BlockManager 维护了整个文件系统中与数据块相关的信息以及数据块状态的变化,核心有两个结构,一个是 BlockInfo 数组,另外一个是 BlockMap 的链表结构。BlockInfo 维护了 Block 块的元数据信息,Block 块数据本身的信息是由 DataNode 管理的,所以 BlockInfo 需要包含实际数据到 DataNode 的管理信息。
BlockMap 是一个链式解决冲突的哈希表,可以通过 BlockId 的哈希值快速定位到 BlockInfo,这块内存也会随着集群内的文件个数以及大小的增长而成比例增长。
然后就是网络拓扑结构,网络拓扑结构维护着整个机架的拓扑以及 DataNode 的基本信息,整个机架的拓扑结构在 NameNode 的生命周期内一般不会发生变化,即使扩容到上千个节点规模的集群,用的内存也是比较小的,也比较固定,不会随着集群文件个数的增长而变化。
第四部分就是其它一些小的内存,比如说 LeaseManager 存储了读写互斥锁的同步信息,像 CacheManager 主要是支持集中式的缓存管理,实现 MemoryLocation 的速度性能提升,还有 SnapshotManager 用于管理数据的备份回滚以及防止用户误操作导致集群出现的一些问题。
当然还有 DelegationTokenSecretManager,主要管理 HDFS 之中的一些密钥访问,这些结构所使用到的内存都是比较小的,而且不会随着集群和文件个数的增长而变化,总体上来看,左边部分的内存会随着集群规模的增长而不断的增长,而且占用的内存非常大,而右边的部分占用内存比较小,且比较固定。
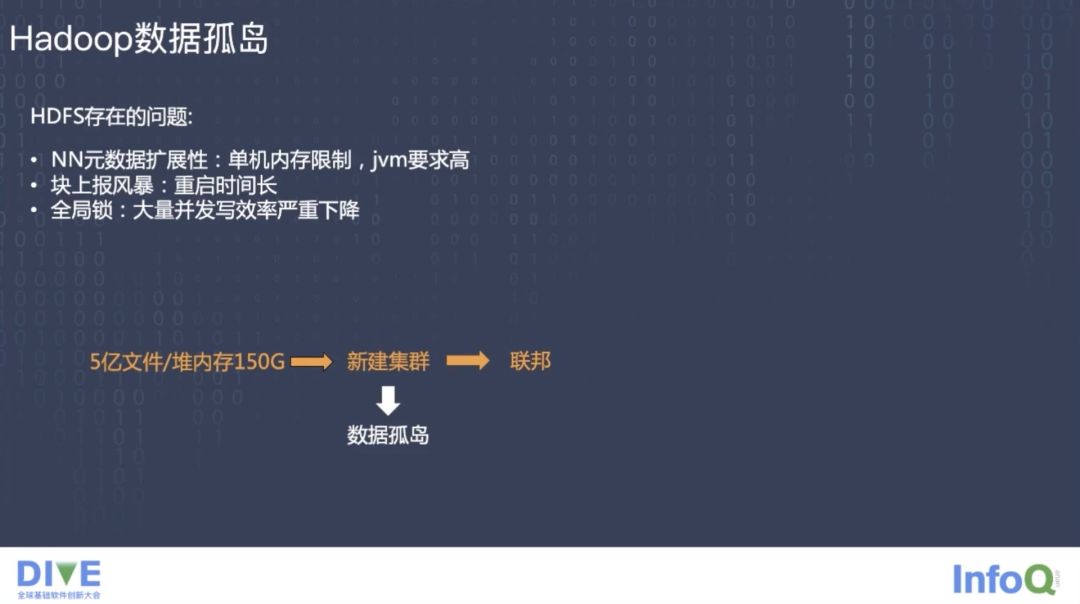
NameNode 文件系统的元数据及块信息的位置基本全部存放在内存中,所以会面临着常驻内存随着数据规模的持续增长,内存逐渐增大的问题,TBDS 在私有化客户项目中获取的经验值是大概一亿个文件 NameNode 占用 100 GB 左右的内存。
HDFS 面临三个主要的问题:
第一个是 NameNode 元数据的扩展性问题,随着数据规模和内存使用的逐步增大,对 NameNode 内存的要求也越来越高,需要定制大内存的机器,内存的大小也限制了集群的扩展性。
对于硬件,京东的 NameNode 采用了 512 GB 内存的机器,字节跳动的 NameNode 采用了 1TB 内存的机器,此外,因为 NameNode 对内存分配巨大,所以对 GC 的要求也比较高,JVM 相关的处理能力已经达到了比较高的水准,大厂可以定制 JDK 的开发,保证大内存场景下 GC 性能良好,但是一般规模的公司不具备 JDK 的维护能力,所以不具备普遍性。
像字节跳动把 NameNode 修改成 C++ 的版本,这样分配内存和释放内存都由程序自己控制,而不是用 JVM,也能达到非常不错的性能,但是这种操作也不具备普遍性,因为开发和维护 C++ 版本的 NameNode 也需要不小的投入。
第二个就是块汇报的风暴问题,HDFS 的块默认大小是 128 MB,启动几百 PB 数据量的集群时,NameNode 需要接收所有块汇报的信息,之后推出了安全模式,因此启动的时间也会随着块大小和块数量的增加而延长,有时候会达到数个小时。集群的全量块汇报和 Balance 操作也会对性能造成一定影响,根本的原因是 DataNode 需要把所有的块汇报给 NameNode。
第三个就是全局锁问题,NameNode 有一把 FILESYSTEM 的全局锁,每个元数据在请求更新时都会加这把锁,虽然是读写分开的,但是这部分流程以及对该锁持有的范围会随着并发量的增长而持续增大。同时 FILESYSTEM 内部的 FSDirectory 的 INode 树也会存在一个单独的锁,用来保护整个树以及 BlockMap 的修改。
TBDS 从私有化客户处获取的经验值是 NameNode 一旦超出了 150 G 内存,或者集群整体的文件规模数量达到 5 亿时就开始新建集群,但是新集群和旧集群的数据是不通的,集群之间就会形成数据孤岛。
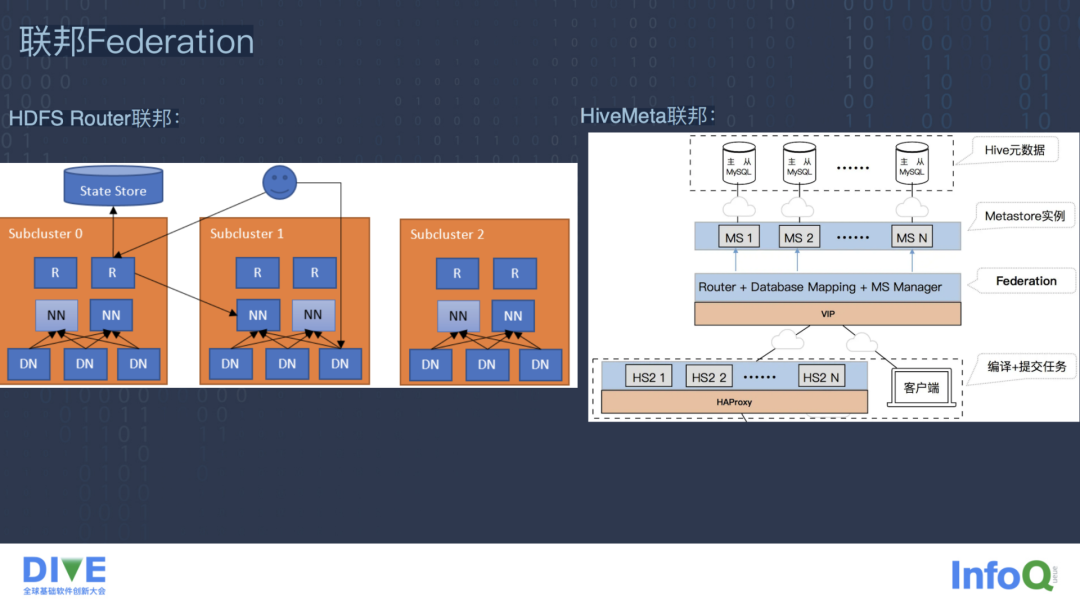
思考一下访问 HDFS 文件需要什么?需要一个 HDFS client,不管是命令行的 client 还是 FILESYSTEM 这种加 API 的 client,除了 client 还需要知道 HDFS 集群 NameNode 的 RPC 通讯 IP 和端口以及认证信息,这些信息通常会保存在 HDFS 的 core-site 配置文件里。
只需要一个 HDFS client 加上不同孤岛集群的 core-site HDFS 配置文件,就可以达到用一个 client 端访问不同的集群数据的目的,只不过访问不同的集群,每一次都要替换对应集群的配置文件,将不同集群的配置文件信息汇总合并成一个配置文件,就可以用同一个 client 和同一个配置文件访问不同的集群了。
不过这也引入了新的问题,就是不同集群的 HDFS schema Namespace 的名字不同,文件路径上看到的还是割裂的。为了解决这个问题,HDFS 社区提出了在 client 端用 ViewFs 挂载表统一管理多个 HDFS Namespace 路径的映射关系,让不同集群的文件路径和 schema 都统一成新的 ViewFs,这就是 HDFS Federation 的联邦模式。
但是这种方式是 Client Side 的模式,对 client 端的访问方式变化很大,协议由 HDFS 变成了 ViewFs,另外子集群的信息是以挂载表的方式配置在 client 端,一旦集群发生了机器的迁移变更,所有的 client 端配置都要修改。
在这种情况下,尤其是在私有化场景中,引导客户去升级和维护的成本都非常大,基于这种考虑,HDFS 社区在后来的 2.9 版本上又提出了基于 Router 的联邦模式,主要的目的是引入一个 Router 服务管理路由的挂载表,对外由 Router 提供 client 端的 HDFS 协议解析和访问,来代替 ViewFs 协议,达到了向前兼容的目的。
Router 把路由表的配置信息放在 StateStore 的分布式存储上,比如 ZK,让 Router 可以平行的无状态地扩展,Router 根据 client 请求中文件的路径到路由表中进行匹配,计算出实际要由哪个子集群处理。
其中把 client 的路径转化成子集群实际处理的路径,Router 自己会启动一个 HDFS 的 client 把这个请求转发给具体的子集群,同时有一个 ClientManager 的结构保存所有 client 的 Router 以及 Router 到具体每个子集群 NameNode 连接池的信息,保证具体子集群处理完请求的 response 之后,能够经过 Router 返回给 client。
TBDS 是基于 Router 的联邦方式,解决了 HDFS 的多集群数据孤岛问题,让集群之间的存储能够互通,当然我们也在 Router 上做了很多新的功能以及性能上的优化。
一般在 Hadoop 集群上绝大多数业务都是通过 Hive 库表的方式去访问 HDFS 存储,比如最常见的离线数仓,解决了数据存储的孤岛问题还不能让业务进行跨集群的连通访问,还要解决 Hive 库表的跨集群连通。
TBDS 是基于 HDFS Router 的思想自研了 HiveMeta 的 Router Federation 联邦,实现了跨集群 Hive 元数据的连通统一,HiveMeta Router Federation 实现了 Hive Metastore、库表大部分常见的 thrift 协议以及 SQL 语法解析,向 HiveServer2、Presto、Spark 等计算引擎提供了 HiveMeta 服务。Router 本身是根据数据库的前缀管理多个子集群 Hive Metastore 实例的路由表,路由表的信息也是配置在 ZK 里的,Router 根据请求中的数据库名查询路由表,根据前缀进行匹配,计算出它实际要路由到哪个子集群的 Hive Metastore 进行处理,同时把库名的前缀去掉并转发到具体子集群的 Hive Metastore 进行处理,这样就实现了 HiveMeta 层库表元数据的联邦统一。

我们通过 Federation 解决了数据和库表元数据的孤岛问题,让上层应用基本可以无感知底层的变化而实现跨集群的数据互通,但 Federation 也有一些问题。
第一个是它增加了数据访问的调用链路,所有的 HDFS 和 Hive Metastore 请求都要经过 Router 的代理转发。虽然 Router 本身的逻辑比后端 HDFS 和 Hive Metastore 轻量,它只实现一些 Proxy 转发逻辑,但还是增加了对系统整体稳定性和耗时的影响,尤其是在进行大量 shuffle 作业时。
当然我们也对 Router 的 HA 高可用及性能做了一些优化,我们对社区的 Router 进行压测,发现大部分 handler 时间都花在 RPC 的 response 返回阶段,而在这个阶段中,大部分时间又花在了加密操作上。因为 RPC 的 response 返回的处理都是在 handler 的资源里实现的,比较繁重且占据了大量资源,它影响了整体的 RPC 处理。我们将相关处理操作从 handler 中分离出来,放到了另外一个线程中进行异步化处理,从而使得 handler 资源能够尽早释放。
第二个是社区采用 Kerberos 认证,在高并发场景下,其加解密的操作会非常耗时,我们把 Router 的 HDFS 认证改成了 TBDS 的 SecretId 和 SecretKey 的方式,优化后整体的耗时比直连 NameNode 多了 4%。同时我们把 handler 的并行处理能力也提升了几倍,整体相比没有经过 Router 处理的时候,性能的差距基本可以持平。
联邦架构只是多了一层 Router 代理,它没有根本性的改变原来存算一体的架构,本来联邦中每一个集群的规模和节点数已经基本达到了红线,对 JVM 的要求也达到了很高的标准,HDFS 集群和 Yarn 的混布,也加大了计算节点和存储节点相互影响的风险。而且我们在客户的生产环境上也确实遇到了相关问题,如 DataNode 为了提高处理能力,抢占系统线程数过多导致 NodeManager 分配不到线程处理任务,进而出现 NodeManager OOM 的情况,这整体加大了系统的不稳定性,所以说联邦还是在逻辑上实现了扩展,并没有打破物理上独立分片扩展的瓶颈。
第三点是资源成本,联邦很容易造成新建集群中存储的都是热数据的情况,导致出现冷热集群两种状态,老集群的计算资源出现大量闲置,需要通过统一进行库的划分或者动态迁移数据来调整所有集群的整体均衡性,这样又增加了系统整体的复杂性,导致运维成本较高。
在生产环境中,不同的时间段,存储和计算的需求往往也是不同的,是弹性变化的。联邦后面的每一个物理集群节点的规模都比较大,机器硬件配置也比较高,计算或存储资源任何一个不足都需要整体扩容,导致资源成本的代价非常高。主要基于后面两点的考虑,我们开始向基于云原生存算分离的架构演化。
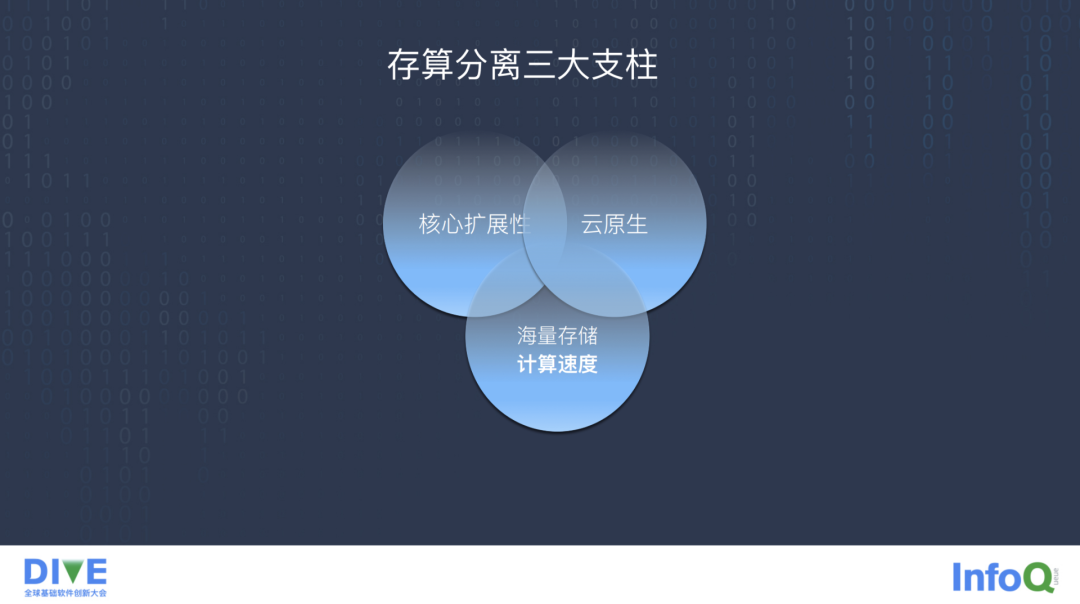
通过前面存算一体提出的问题以及存算分离的简单的介绍,我们从三个核心点设计和考虑我们的存算分离架构,主要是核心扩展性、海量存储计算速度和云原生。
核心扩展性主要指存储、元数据和调度计算的独立物理扩展性,扩展性能需要达到上万节点规模的能力;海量存储计算速度主要是为了解决存算分离引起的大量网络 IO 问题,通过缓存加速等手段可以实现数据的本地性能能力;云原生主要是指计算和调度依赖 Kubernetes 提供的云原生能力,实现弹性计算以及自动容错。
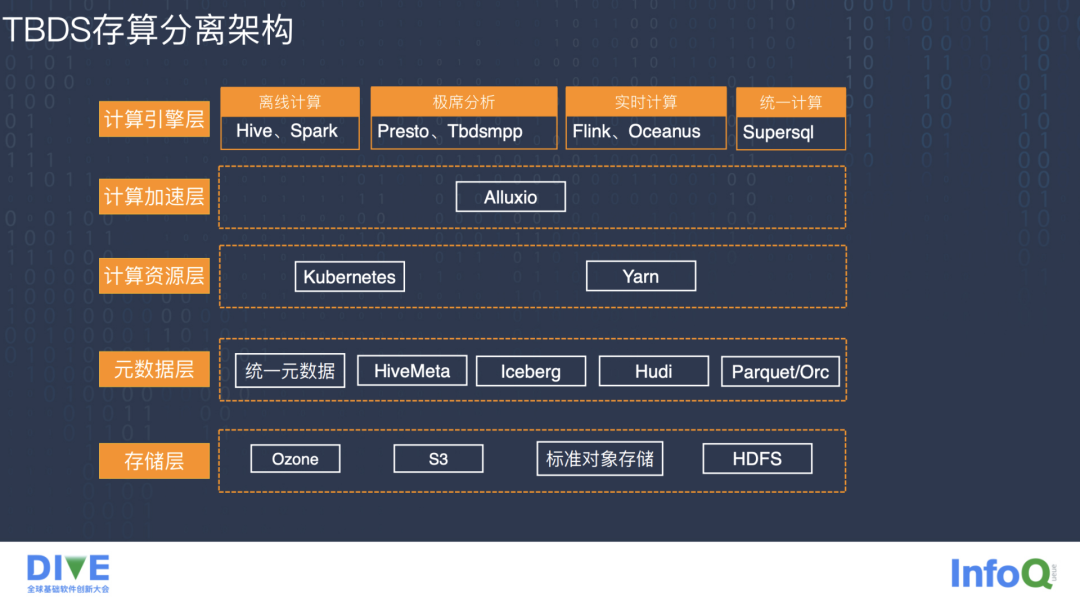
上图是 TBDS 存算分离的大致架构图,主要是存算分离底座部分去掉了应用层,像数据管理、一站式数据开发、数据治理、数据报表分析及上层工具等。我们只看核心组成,这个架构图可能和其它类似的大数据架构图不太一样,区别主要在于存储层,在存储层和计算层中间加了一个元数据层,计算层又分成了计算资源层、计算加速层和计算引擎层。
这样设计的原因是把可扩展性的核心交给了存储层,因为实现存储层的扩展性难度是最大的,所以只要存储层是可扩展的,其上面所有层理论上都是可扩展的,或者说是比较容易扩展的,其它上层的东西都可以通过分布式方案解决。
我们的存储层主推腾讯自研并贡献给 Apache 社区的 Ozone 对象存储,Ozone 在文件的元数据架构上通过拆分以及 Raft 分布式的方案解决了 HDFS NameNode 元数据中央节点无法扩展的问 题。
因为 TBDS 用于私有化场景,考虑到客户的实际情况,我们存储层也支持像亚马逊的 S3、阿里的 OSS、华为的 OBS 这种支持标准对象存储协议的存储方式,当然存储层架构治理同时也兼容了老的 HDFS 文件系统存储。在解决了存储层的扩展性问题后,元数据层再将存储层中一个个的文件组织成一个个的数据表,提供给上层的计算引擎。
应用的查询需要在不同的计算引擎上做选择,大数据领域里没有一个万能的计算引擎,不同的计算引擎擅长不同的领域,所以元数据层不是一个统一的一种表格就可以满足所有的场景,而是针对不同的场景,不同的情况,选择不同的计算引擎,甚至会使用不同元数据格式的数据。
我们的元数据层支持像 Iceberg、Hudi 这种面向数据湖的表格,也支持像 Parquet/Orc 这种传统的 Hive 数仓的表格式,当然还有一些没有列出来的,比如像 Flink 这种实时计算的动态表格式。
元数据层最常用的就是 HiveMeta 这种表格式的管理,然而在海量扩展性存储的场景下,由于 HiveMeta 本身没有元数据采集能力,并且 HiveMeta 用于存储数据的 MySQL 是以主备方式部署的,整体的扩展性和性能在高数据量级的情况下会产生瓶颈,基于以上考虑,我们自研了一个叫统一元数据的服务,统一解决元数据层的扩展性问题,它也同样支持了大部分 HiveMeta 的标准协议。
计算资源层支持 Kubernetes 的计算调度和 Yarn 的计算调度,由于 Kubernetes 与 Hadoop 生态及其配套工具还有某些计算引擎存在一些不适配的地方,我们根据不同集群的不同物化的计算引擎去 Kubernetes 和 Yarn 上面做选择。我们整体是往云原生方面发展,计算引擎也越来越多的往云原生上开发适配。计算加速层我们采用 Alluxio 作为计算引擎到存储引擎之间大量网络 IO 的缓冲纽带,Alluxio 带来的数据本地性让上层应用可以享受更快的速度。
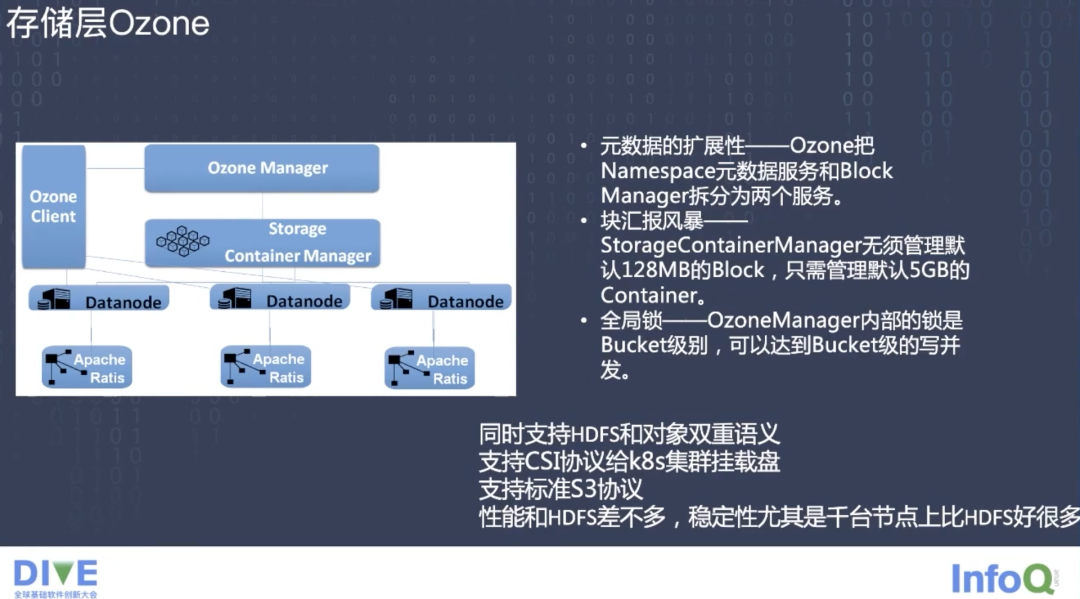
接下来逐层看一下我们目前做的设计和优化。首先对于存储层,最核心的点就是可扩展性,尤其是大规模节点环境下的可扩展性,相比较 HDFS,Ozone 把 Namespace 元数据服务和 BlockManager 拆分成了两个服务。
Ozone Manager 负责元数据服务,管理 Ozone Namespace,提供所有 Volume、Bucket 以及 Key 的新建、更新和删除操作,存储 Ozone 的元数据信息,这些元数据信息包括 Volumes、Bucket 和 Key,底层通过 Raft 协议扩展元数据的副本,实现了元数据的 HA 和无限的扩展性。
Storage Container Manager 主要负责数据块管理、节点管理以及副本的冗余管理,类似于 HDFS 中的 BlockManager 模块,它管理了 Container、Pipeline 还有 DataNode,为 Ozone Manager 提供 Block 以及 Container 相关操作的信息。这个模块同时也监听了 DataNode 发送过来的心跳信息,作为 DataNode Manager 的角色,保证和维护集群所需要的数据冗余级别。
这两个服务都可以独立部署在多台机器上,各自利用各自的机器资源,Ozone 的元数据不存储到内存中,不管是 Ozone Manager 的元数据,还是 Storage Container Manager 中的 Container 信息,都是在 RocksDB 中存储维护的,极大降低了对内存的依赖,理论上元数据都是可以无限扩展的。
Storage Container Manager 无须管理默认 128MB 的 Block 信息,它只需要管理默认 5 GB 的 Container 信息,可以极大的减少数据管理的成本,从而提升自身服务性能。
因为 Storage Container Manager 是以 Container 的方式作为块的汇报单位,汇报数量比 HDFS 大大减少了,无论是全量汇报还是增量汇报,整体都不会对 Storage Container Manager 的性能造成很大影响。DataNode 是 Ozone 的数据节点模块,它以 Container 为基本存储单元,维护每一个 Container 内部的数据映射关系,它会定时向 Storage Container Manager 发送心跳并汇报节点信息,同时管理着 Container 和 Pipeline 等信息,DataNode 也是以 Raft 协议的方式实现了一致性的扩展。
Ozone Manager 内部的锁是 Bucket 级别的,可以达到 Bucket 级别的写并发,因为 Ozone 是对象存储,对象存储的语义不存在目录和树之间的关系,因此也不需要维护全局的文件系统树,并且可以达到很高的性能吞吐。Ozone 的优势是同时支持 HDFS 和对象存储双层语义,它支持 CSI 协议让 Kubernetes 集群去挂载,也支持标准的 S3 协议。通过压测得出其整体性能和 HDFS 差不多,但稳定性要好很多,尤其是在节点数量达到千台以上规模的情况下。当然对象存储也存在天然的劣势,因为没有 HDFS Namespace 这种庞大的目录树,所以在执行 List 这种操作时会特别耗时,代价也非常高。

接下来看计算资源层,由于我们的存算分离主打的是云原生,这里主要说的是基于 Kubernetes 的计算资源层。
在扩展上,Kubernetes 可以快速弹性的支持节点的上下线,但官方表示单个 Kubernetes 集群最大节点数为五千个,虽然五千个节点已经非常多了,但对于腾讯内部的大数据集群,单租户就已经达到了数万个节点,而且私有化场景下,一些行业的头部客户未来的数据量也会逐步增大。万节点是一个越来越现实的诉求,所以五千个节点的限制对于 Kubernetes 集群的扩展性也是一个较大的瓶颈,同时 Kubernetes 的调度性能与 Yarn 有数量级的差距。
根据压测,Kubernetes 在一千个 Pod 每秒的调度情况下性能有严重下降,难以支持大规模的数据调度场景,除了调度之外,在超大规模集群的高并发场景下,apiserver、etcd、监控、日志等都会存在明显的瓶颈,这些都是需要解决的问题,因为 Kubernetes 的节点和 Pod 的状态信息都存在 etcd 里。Kubernetes 除了通过 ListAndWatch 的事件监听方式感知 Node 变化外,也会定时从所有 Node 节点查询更新事件。五千个节点的限制主要是因为 etcd 的性能限制,尤其是在 etcd 进行大量并发查询的情况下。
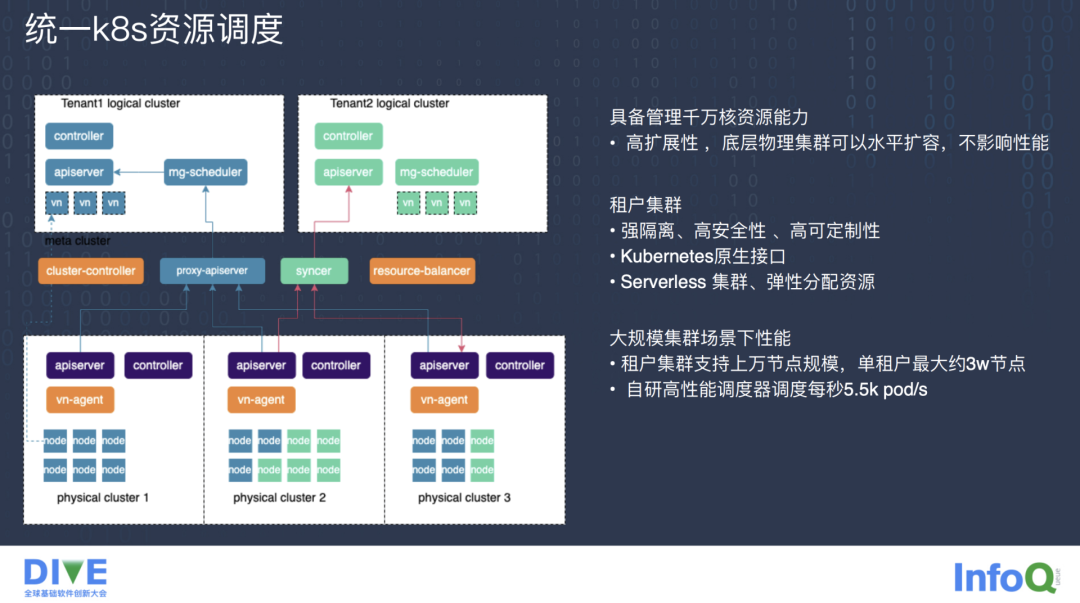
我们针对原生 Kubernetes 的节点扩展限制以及调度能力上的瓶颈自研了统一 Kubernetes 调度引擎来优化解决这个问题。首先我们有一个租户集群 logical cluster,租户集群对外相当于一个 Kubernetes,它是用户提交任务的入口,提供了和 Kubernetes 标准一样的 apiserver、controller、以及 scheduler 调度器,不过这里的调度器是我们自研的 mg-scheduler,引入了批量调度,实测比原生 Kubernetes 的调度能力快了 10 倍以上,租户集群有很多虚拟的逻辑节点,和租户集群底层管理的 Kubernetes 物理集群的节点是一对一的映射关系。
也就是说租户集群的虚拟节点总数是其所管理物理 Kubernetes 集群节点数之和,之所以叫虚拟逻辑节点,是因为租户集群的节点只同步物理集群的 Node 配置以及状态信息用来做展示,并没有责任去维护后面物理 Kubernetes 集群的 Node 健康状态等信息,Node 的健康状态等信息还是由物理 Kubernetes 集群负责维护。
更新物理 Kubernetes 集群 Node 信息的频率我们控制的很低,一般是 15 分钟一次,后面可以调整的更低。租户集群更新节点的事件会被过滤掉一大部分,只选择小部分重要事件进行变更,所以虽然租户集群管理的存储节点规模很大,但对于租户集群的压力尤其是 etcd 的压力是很小的,这也是它能维护上万节点,高性能的原因。
中间是自研调度引擎的 Meta Cluster 层,Meta 层主要对租户集群做了一些管控,比如通过 cluster-controller 模块可以创建新的租户集群,通过 syncer 模块进行信息同步,它将租户集群的虚拟 Pod 信息及 Pod 依赖的 ConfigMap、Secret、PV/PVC、Volume 等资源对象同步到物理集群。
此外 syncer 还将 Node、Pod 的状态信息从物理集群同步到租户集群,并且通过 ListAndWatch 机制把物理集群的 Node/Pod 的创建销毁事件及时上传到租户集群。
proxy-apiserver 给调度器提供了统一的 Node 视图,因为租户集群的节点可能来自于多个不同的物理 Kubernetes 集群,通过 proxy-apiserver 提供统一的 API 访问入口去访问物理集群。
最下面就是物理 Kubernetes 集群,配合我们的统一 Kubernetes 调度引擎,它具备管理千万核资源的能力,具有较高的扩展性,底层物理集群可以水平扩展,不影响性能。
租户集群有强隔离性、高安全性、高定制性的特点,同时支持原生 Kubernetes 接口,资源可以弹性扩展,支持上万节点的集群规模,腾讯内部单个租户集群最大已经有三万个节点,我们的自研调度器可以达到每秒 5500 个 Pod 的调度能力。
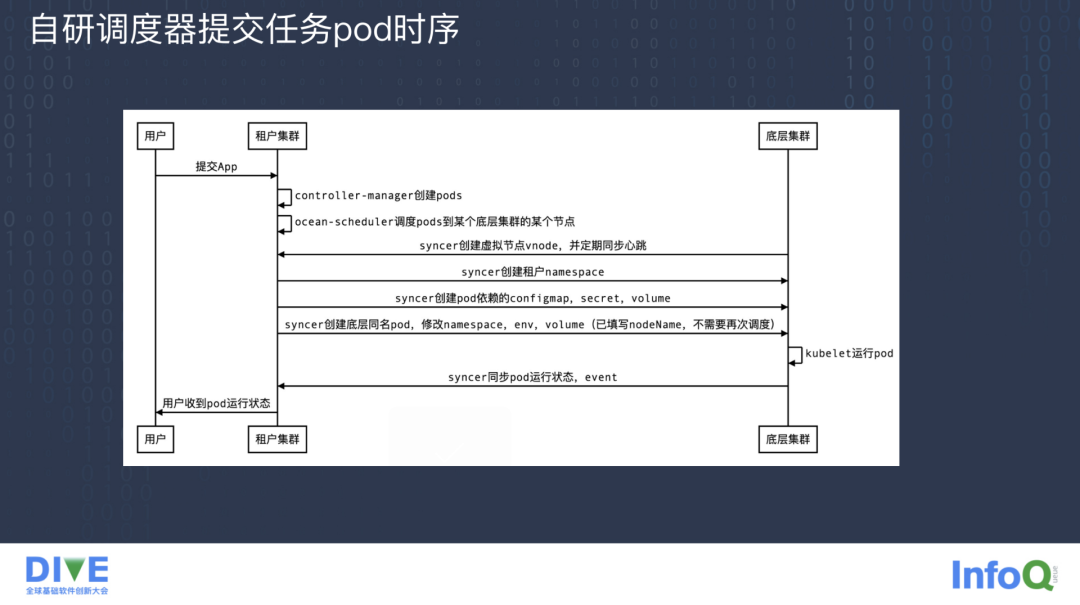
上图是经过自研调度器提交任务启动 Pod 的时序图,用户提交 Pod 创建任务到租户集群,租户集群的 controller-manager 开始创建 Pod,mg-scheduler 调度器会调度 Pod 到具体某一个底层物理 Kubernetes 集群的某个节点上,如果这个节点在租户集群上还没有被创建,syncer 模块会将这个节点以虚拟节点的形式创建出来,并且定期同步物理集群的 Node、心跳等信息到租户集群,这个时间周期可以设置的很短。
syncer 模块发现如果底层的物理集群还没有创建 Namespace,它会创建一个租户集群 Namespace,但由于可能存在多个租户集群,Namespace 可能会冲突,这里会统一给租户集群的 Namespace 在底层的物理 Kubernetes 集群映射的 Namespace 上加一个前缀,保证全球唯一,避免冲突。
接着 syncer 模块会创建 Pod 依赖的 Secret、ConfigMap、Volume 等对象并同步到底层的物理 Kubernetes 集群上,然后就可以创建底层同名的 Pod 并修改 Pod 里面的一些属性,比如说对象属性,加一些前缀保证唯一性等操作。
底层物理 Kubernetes 集群的 kubelet 就会运行这个 Pod,最终 syncer 感知到物理集群的 Pod 状态发生变化,就会把 Pod 的状态和 Event 事件同步到租户集群上,租户集群上的 client 用户就能收到这个 Pod 的状态,这就是通过自研调度器提交 Pod 运行任务的流程。

接下来就是计算加速层的优化,我们引入了 Alluxio 做计算加速。这里主要讲解一些使用场景上的优化,Alluxio 提供主动和被动两种方式获取数据,主动方式即预热的方式,比如在离线数仓场景,用户可能有很多周期性任务,比如金融系统需要每天统计账单数据,电网系统可能每天要统计电量用量的分布,这些任务周而复始,需要按天甚至按小时进行计算,我们可以在跑任务之前,主动把 Hive 表中的数据加载到 Alluxio 的 Cache 里进行计算加速。
由于周期性的任务业务逻辑可能很多,而且 Alluxio 的 Cache 空间有限,全量获取 Cache Hive 表可能导致 Alluxio 中的数据频繁进行数据淘汰,这样加速效果难以达到理想状态,而且周期性任务的表往往会按照周期性进行分区的 partition,比如按天或按小时进行分区。
我们利用 Alluxio Prefix Level 的预热能力可以提前按照表的分区级别设置前缀,让数据加载到 Alluxio 的 Cache 里,并且将数据和周期的调度时间按比例设置 TTL 过期时间,保证分区内数据可以在计算完成后迅速过期,给 Alluxio 腾出更多空间来缓存最重要的数据。
被动方式是当计算引擎需要相关文件的 Block 并且向 Alluxio 申请时,发现本地 Cache 里不存在,Alluxio 会马上从底层的 UFS 同步数据,以访问相应 Block 的内容,并且 Cache 到 Alluxio 的 Worker 节点中,这种被动的方式第一次比较耗时,但对于后续计算要重复使用的热数据,也有明显的加速效果。
另外之前提到了对象存储的 List 操作,它需要遍历,是非常耗时且代价较高的 API。List 操作是计算引擎经常用到的命令,Alluxio 也提供了元数据的 Cache 能力,我们可以把元数据 Cache 到 Alluxio 里以减小 List 操作带来的耗时和代价,提升 Metadata 的访问性能。
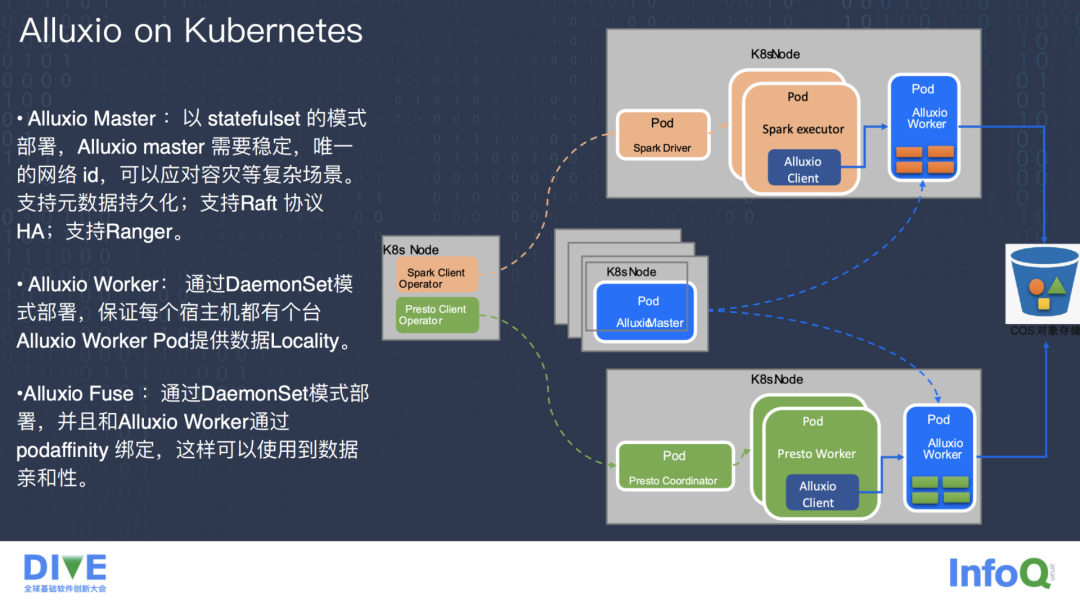
上图是 Alluxio 部署在 Kubernetes 计算层一个典型的存算分离场景。简单说就是 Alluxio Worker 部署在和执行计算的这个 Pod 节点相同的宿主机上,计算引擎如 Spark、Presto 都有 Master 和 Worker 属性的不同的 Pod,Alluxio Worker 部署在 Spark 的 Executor 或者 Presto 的 Worker 节点相同宿主机的 Pod 上,为了让 Kubernetes 集群所有的 Node 调度资源均衡。我们采用了 DaemonSet 的方式部署 Alluxio Worker 的 Pod,保证每一台宿主机节点都能提供数据的本地加速。
Alluxio Master 通过 StatefulSet 模式部署,因为 Alluxio Master 需要稳定且唯一的网络 ID 来应对容灾等复杂场景。并且 Alluxio Master 是以 Raft 的方式支持多副本的高可用 HA。
Alluxio Fuse 也可以通过 DaemonSet 方式部署,并且它可以和 Alluxio Worker 通过 PodAffinity 进行绑定,这样可以达到数据的亲和性,Fuse 主要使用在 AI 场景,它可以通过 Mount 文件到业务的方式直接读取文件,业务端就不需要感知和考虑 Alluxio 数据端的部署模式以及 Pod 的位置,当然 Alluxi 也支持 CSI 这种方式的 Mount。
下面讲解实践中计算引擎的优化,主要以 Spark 计算引擎为例。
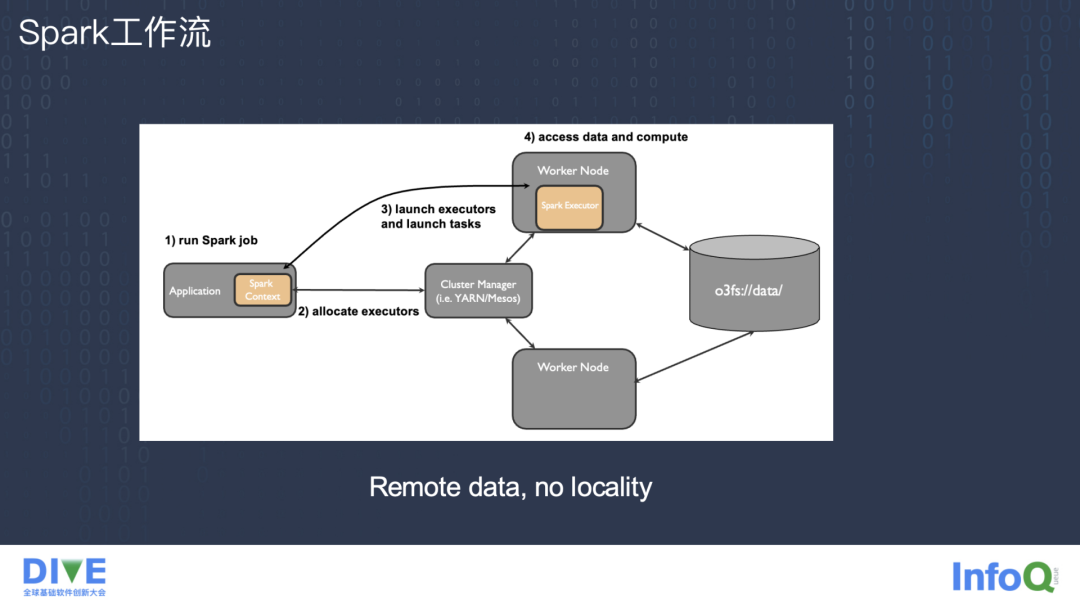
先看一下 Spark 在物理集群中常见的工作流状态。首先通过 Spark submit client 提交运行一个 Spark job 到 Yarn 或者 Mesos,接着 Yarn 或 Mesos 分配一个 Worker 节点作为 Executor 给 Spark client,Spark client 会从 Worker 节点起动 Spark Executor 并且在 Executor 里起动一个物理执行计划的 Task 任务。Spark Executor 的每一个 Task 都要从远端的 Ozone 或者 S3 这种对象存储访问数据并进行计算,这种模式的计算都是通过网络 IO 从远端访问数据,整体的网络时延和 IO 都会影响整体的计算速度。
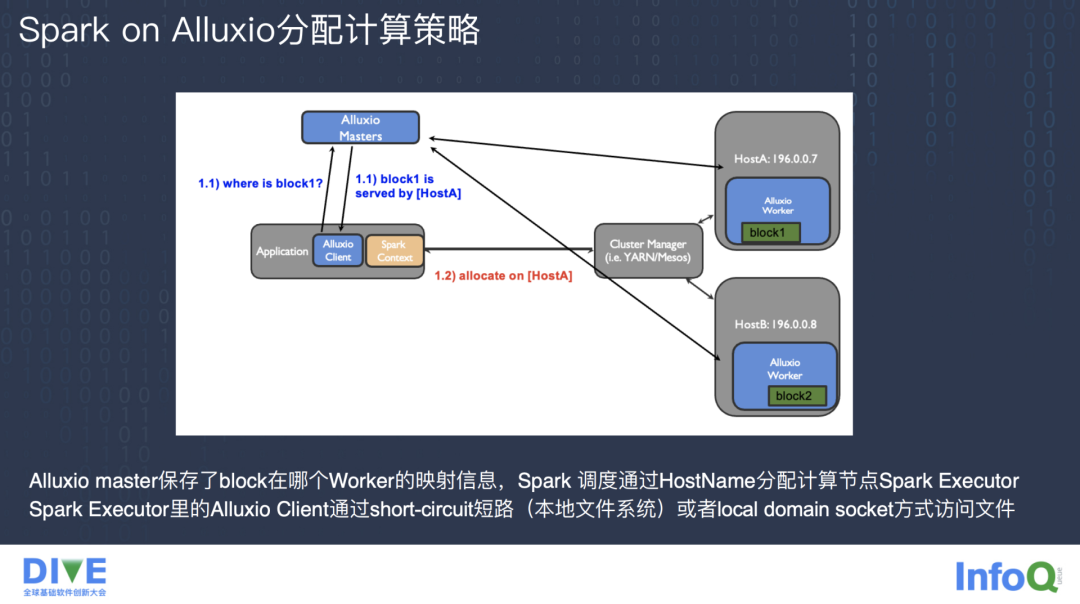
上图是在物理机上 Spark 经过 Alluxio 加速计算的流程,通常会把 Alluxio 的 Worker 节点和 Yarn 的 Worker 节点部署在一起,达到数据本地性的加速效果。相比于未经过 Alluxio 加速计算的流程,这里的 Yarn 在分配 Executor 节点时策略会有所不同。
首先 Spark client 里的 Alluxio client 会到 Alluxio 的 Master 节点查找本次计算要访问的文件的 Block 具体在那个 Alluxio Worker 节点,拿到 Alluxio Worker 节点主机的 Host 地址之后,Spark client 会带着这个 Host 地址去 Yarn 或 Mesos 上要求在这个 Host 的宿主机节点上分配 Spark Executor 节点,并且启动 Task 任务。
Spark Executor 里面的 Alluxio 通过短路读的方式或者 Local Domain Socket 的方式去访问 Worker Cache 里具体文件的 Block。这里的 Local Domain Socket 和 RPC 的 Socket 通信方式不同,RPC 的通信方式是需要对端的 IP 和端口建立 Socket fd,而 Local Domain Socket 是通过本地文件系统的文件路径去创建 Socket fd,不会经过网络协议栈。
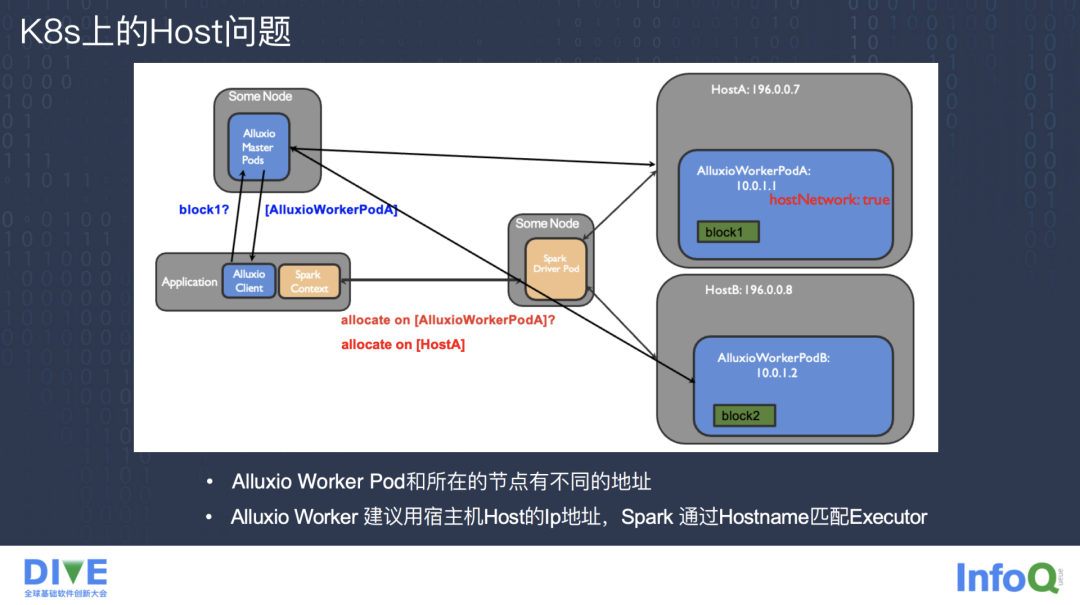
不过在物理机上经过 Alluxio 加速的模式放在 Kubernetes 上部署会有一些问题。首先 Alluxio Worker Pod 的 Host 是在 Kubernetes 集群里分配的,与所在宿主机的 Host 是不同的,这就导致无法通过 Pod 的 Host 分配 Spark Executor 到数据就近的 Pod,在实践中可以通过配置 Pod 的 hostNetwork 属性为 true,让这个 Pod 共享宿主机的 Host 来解决这个问题。

这样又引入两个新的问题,第一个是 Spark 的 Executor Pod 的 Host 和宿主机的 Host 不一样,这里同样需要让 Spark Executor 的 Pod 开启 hostNetwork 属性为 true,才可以以物理机 Host 的方式分配和 Alluxio Worker 同一物理机的节点来进行本地计算。
第二个问题是即使能让 Alluxio Worker 和 Spark Executor 分配到同一个宿主机上,但是因为 Alluxio 的 client 只能通过短路读或者 Local Domain Socket 的方式去访问,而 Pod 之间的文件系统又不互通。虽然可以通过 Volume Mount 的方式共享宿主机文件,但具体要访问的文件的路径和目录也是动态变化的,而且存储的文件相对比较大,所以 Volume Mount 的访问方式是很不稳定的。
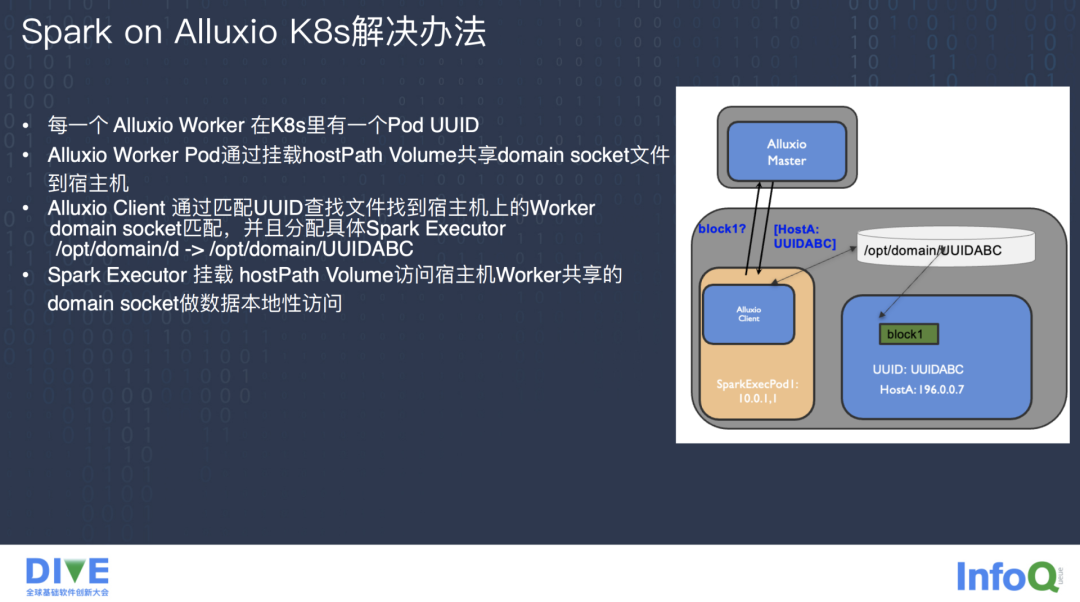
实践后得出的解决方法是让 Alluxio Worker 通过挂载 hostPath Volume 的方式共享 Domain Socket 到宿主机,比如挂载到 /opt/domain 这个路径,由于每个 Alluxio Worker 在 Kubernetes 里都有唯一的 Pod UUID,我们把 Pod 的 UUID 挂载到 /opt/domain 路径下,具体的文件就变成了 /opt/domain/UUIDA,Alluxio client 会到 Alluxio Master 询问文件的 Block 所在的 Alluxio Worker 的 Pod。
Alluxio Worker 会把自己的 Local Socket Domain 通过 Master 发 给 client,Alluxio client 就可以在宿主机上通过匹配 UUID 的方式查找到 Worker 的 Domain Socket 文件,也就是 /opt/domain/UUIDA。匹配到具体要查找的宿主机并且在这个宿主机上分配具体的 Spark Executor 并启动任务,Spark Executor 同样挂载到和 Alluxio Worker 一样的 HostPath Volume 路径,Spark Executor 里面的 Alluxio client 就可以通过 Domain Socket 的方式去访问这个路径的文件,进行本地数据计算加速。
本次分享主要分为三部分,第一部分提到了存算一体的扩展性问题及产生原因,我们可以通过增加集群的方式进行解决,但增加集群同时带来了新的数据孤岛问题,为了解决数据孤岛问题,我们又引入了联邦集群解决方案,但联邦集群存算分离的架构也依然不够完善。
所以第二部分中基于云原生的存算分离架构应运而生,这里讲到存算分离的三层架构以及如何解决存储层的扩展性问题、如何解决 Kubernetes 层的扩展性问题以及如何使用 Alluxio 进行加速计算。
最后一部分讲解了 Spark on Alluxio Kubernetes 的最佳实践与优化。
点击底部阅读原文访问 InfoQ 官网,获取更多精彩内容!
“台湾省山西刀削面”搜索过多,百度地图宕机;BOSS 直聘即将实行末位淘汰;B 站回应 HR 称核心用户是 Loser |Q 资讯
开发技能需求变了:经验不是晋升唯一要素,通晓多编程语言的时代已成过去