医疗领域知识图谱构建-关系抽取和属性抽取
前言
医疗知识图谱构建离不开大量的三元组,而三元组的获取除了先前文章介绍的IS-A上下位抽取,另一项就是关系抽取。关系抽取是信息抽取领域中的重要任务之一,目的在于抽取文本中的实体对,以及识别实体对之间的语义关系。例如"弥漫性肺泡出血易合并肺部感染"中,"弥漫性肺泡出血"与"肺部感染"都是疾病,他们之间的关系是"疾病-合并症"。存在于海量医疗文本中的知识体系网络,可以为其他NLP技术(实体链接,query 解析,问答系统,信息检索等)提供可解释性的先验知识(知识表示)和推理。
与我们认识世界一样,实体关系相当于事物与事物之间的联系,而属性,则丰富了我们对事物本身的认识。同理,医疗文本中也存在描述实体属性的信息,如:"通过用手搔抓患癣的部位如足趾间,或与患者共用鞋袜、手套、浴巾、脚盆等是手癣的主要传播途径。"中,"手癣"的"传播途径"是"用手搔抓患……"。又如"发生丙肝的主要原因是丙型肝炎病毒"中,"丙肝"的"主要原因"是"丙型肝炎病毒"。通过例子可以发现,属性名通常是一个名词短语,但是属性值可以是词,也可以是句子,属性的概念本身就具备较宽泛的灵活性,学界目前也没有一个统一的标准,所以需要在具体落地场景中根据实际情况做相应的设计。
在医疗文本数据中进行信息抽取,必须对医疗文本数据有一定的认识和分析,关系复杂,密度大,但基本无歧义,指代情况明显,由于表达相对简短,上下文信息没有固定模式,overlapping现象普遍存在,因此需要一定的医疗领域先验知识和模型结构上的巧思。
医疗知识图谱的构建不仅在于使用知识,完成数据的结构化,同时也需要赋予结构化数据在丁香园团队的搜索,问答,推荐场景的可计算能力。我们希望能构建高质量的医疗知识图谱,为各个业务场景赋能。
关系抽取方法综述
目前主流的关系抽取主要分为两种,两类方法各有利弊:
远监督标注数据下的关系分类
优:利用远监督思想得到训练数据,可大大减轻标注工作;关系抽取准确率基本在85%以上。
缺:实体识别的错误会传递到关系抽取过程中;同时,分开抽取,也没有充分的利用实体信息;负样本的选取也是决定着模型好坏。
实体关系联合抽取
优:实体和关系抽取工作同时进行,关系抽取过程会充分利用实体信息。
缺:模型复杂;基于英文公共数据集,最好模型的准确率只有64%,即只要实体识别准确率在80以上,那么远监督的准确率就会高于联合抽取模型。
当然上述结果都基于英文公共数据集,并且是非领域数据,因此接下来的将在模型总数的同时,展示各模型在中文医疗数据上的效果。
远监督模型
由于远监督模型假设实体识别是完全正确的,但实际中并非如此,因此在此给出基于2万条数据的医疗命名实体识别模型效果:F1=81%。
《Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks》
这一篇工作是在Zeng[1]基础上的扩展,将Fully Supervised 转化为Distant Supervised。Distant supervised 会产生有大量噪音或者被错误标注的数据,直接使用supervised的方法进行关系分类,效果很差。原始方法大都是基于词法、句法特征来处理, 无法自动提取特征。而且句法树等特征在句子长度边长的话,正确率很显著下降。因此文中使用Multi Instance Learning的at least one假设来解决第一个问题;在Zeng 2014 的CNN基础上修改了Pooling的方式,解决第二个问题。
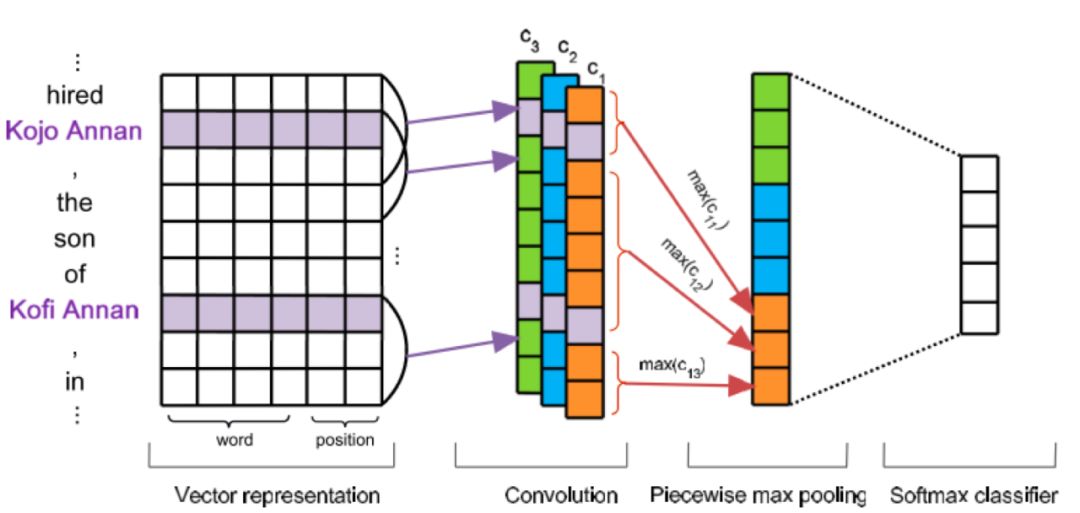
Input Layer为word embedding + position embedding,以往不同的是,Pooling层并没有直接使用全局Max Pooling, 而是局部max pooling,把一个句子按实体位置切分成三部分,卷积之后对每一段取max pooling, 这样可以得到三个值,相比传统的max-pooling 每个卷积核只能得到一个值,这样可以更加充分有效的得到句子特征信息。为了降低远监督带来的噪音问题,采用了Multi-Instance Learning。
我们使用远监督标注的医疗实体关系数据进行实验,同时,也尝试了基于PCNN的其他改进模型,如将CNN换成更适合序列文本的BiLSTM,加入注意力机制的PCNN,效果将在文末展示。
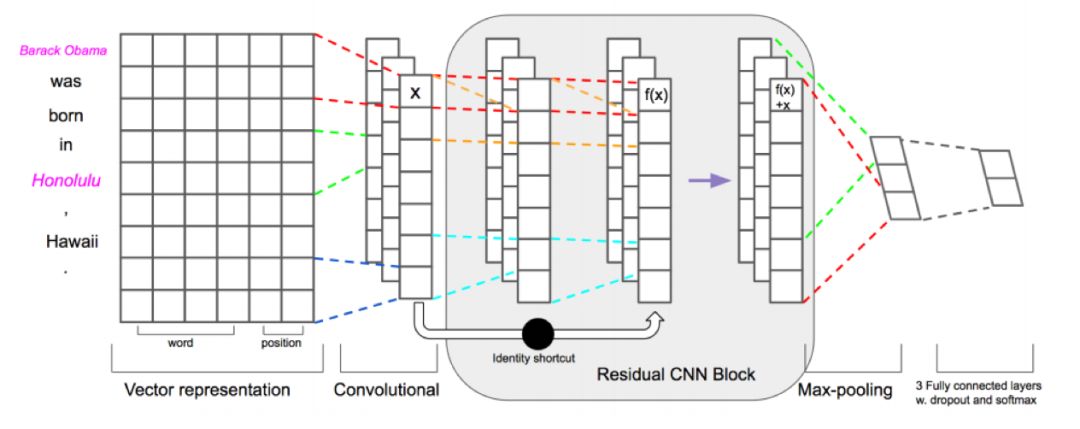
《Deep Residual Learning for Weakly-Supervised Relation Extraction》
本文使用9层ResNet作为sentence encoder, 在不使用piecewise pooling 或者attention机制的情况下,性能和PCNN+ATT 接近。
《Classifying Relations by Ranking with Convolutional Neural Networks》
在Zeng[1]的CNN基础上做的改进,最大的变化是损失函数,不再使用softmax+cross-entropy的方式,而是margin based的ranking-loss。
负样本的选择上, 并不是随机选择一个负标签,而是选择score最大的那个负标签,这样可以更好地将比较类似的两种label分开。关于NA label的特殊处理,NA表示两个entity没有任何关系,属于噪音数据,因此如果将这个噪音类别与其他有意义的类别同等看待的话,会影响模型的性能. 因此文中对NA类做了特殊处理。在train的时候,不再考虑NA这一类别, 对于NA的训练数据,直接让(1)式的第一部分为0即可。在predict的部分, 如果其他类别的score都是负数,那么就分类为NA。实验证明这个效果对整体的performance有提升。
使用Ranking loss,效果提升2%多,而且在没有使用lexical-feature以及单窗口尺寸的情况下。有提升的原因可能是使用ranking loss可以更容易区分开一些易于分错的类别,而softmax却没有这样的功能,只可以增强正确类别的概率。使用仅仅两个entity之间的words 可以在一定程度来替代position的作用,而且实现更简单。
《RESIDE: Improving Distantly-Supervised Neural Relation Extraction using Side Information》
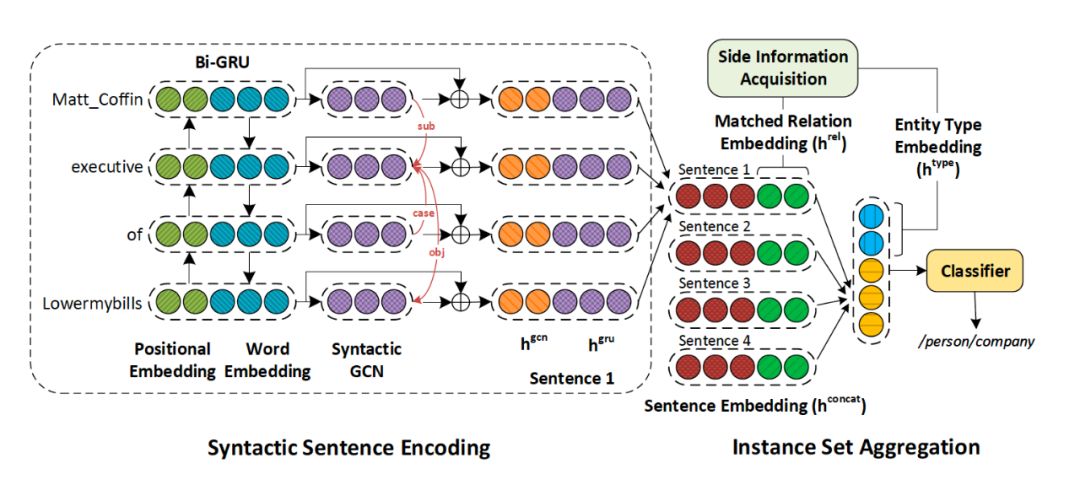
为了获取更多的图谱结构特征和图谱中的先验知识,近几年,大多研究集中于利用图神经网络解决远监督关系抽取任务。与传统神经网络结构不同,RESIDE主要应用了Graph Convolution Networks,来弥补句法结构特征,并利用已有知识图谱中边信息额外监督,来提高远程监督的可靠性,增加模型的可解释性。
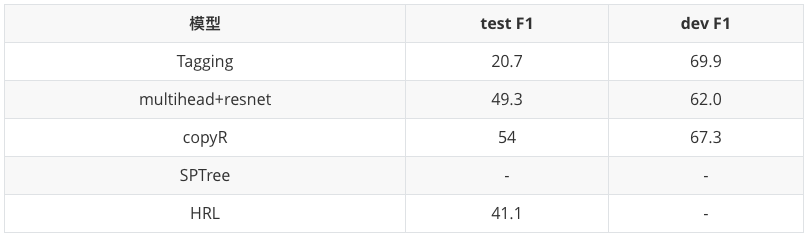
实验结果
以下为远模型在医疗文本中的关系抽取结果:
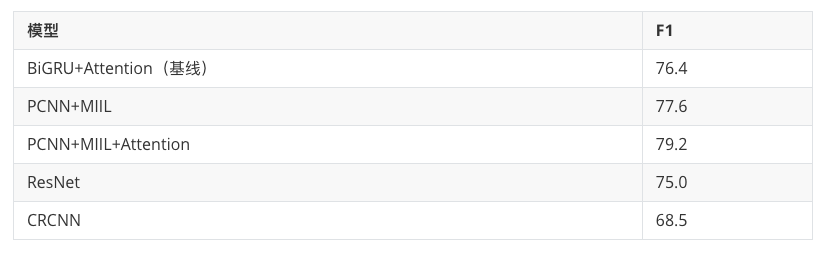
远监督模型总结
word embedding + position embedding 成为输入层的标配。Attention和多实例学习的作用明显。图神经网络兼顾了语义和句法结构。
联合抽取模型
联合抽取模型的设计目的是希望在进行命名实体识别的同时,让实体信息辅助关系抽取,从而实现两个任务一体化。对于实体间关系的端到端(联合)提取,现有的模型都是基于特征的系统。这些模型包括结构化预测[2,3]、整数线性规划[4,5]、卡片金字塔解析[6]和全球概率图形模型[7,8]。其中,结构化预测方法在几个语料的表现较好。
但每个模型的输出效果是有所区别的,有些模型对预测结果比较严格,要求实体边界,类型,以及关系类型都正确,才算预测成功;而有些模型则无需预测实体类型,只需识别实体的范围即可,因此具体到应用中,可视情况而定。
《End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures》
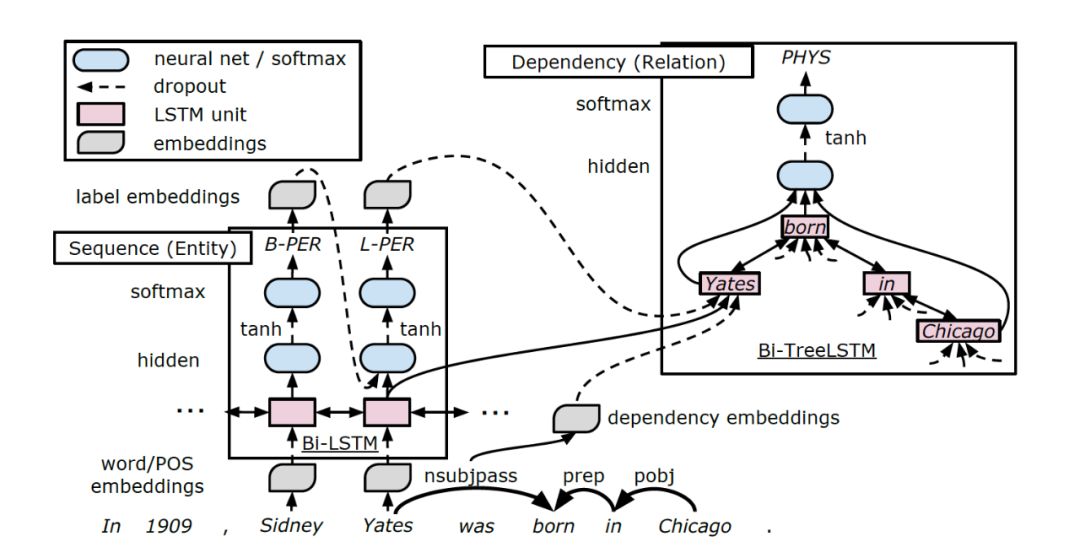
提出了一个新的端到端模型来提取实体之间的关系。模型使用双向序列RNNs(从左到右和从右到左)和双向树结构(自下而上和自上而下)LSTM-RNNs,对实体和关系进行联合建模。首先检测实体,然后使用一个递增解码的nn结构提取被检测实体之间的关系,并且使用实体和关系标签共同更新nn参数。与传统的端到端提取模型不同,模型在训练过程中还包含两个增强功能:实体预训练(预培训实体模型)和计划抽样,在一定概率内用gold标签替换(不可靠)预测标签。这些增强功能缓解了早期实体检测低性能问题。
该模型主要由三个表示层组成:字嵌入层(嵌入层)、基于字序列的LSTM-RNN层(序列层)和基于依赖子树的LSTM-RNN层(依赖层)。解码期间,在序列层上建立基于贪心思想的从左到右的实体检测,在依赖层上,利用dependency embedding和TreeLSTM中的实体对最小路径,来辅助关系分类,依赖层堆叠在序列层上,这样共享参数由实体标签和关系标签的决定。
SPTree模型的痛点之一是需要完美的分词,所以模型的识别效果缺陷主要来自于实体识别这一部分。不同于SPTree,下面介绍的模型,都应用了序列标注,解决这一问题。
《Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme》

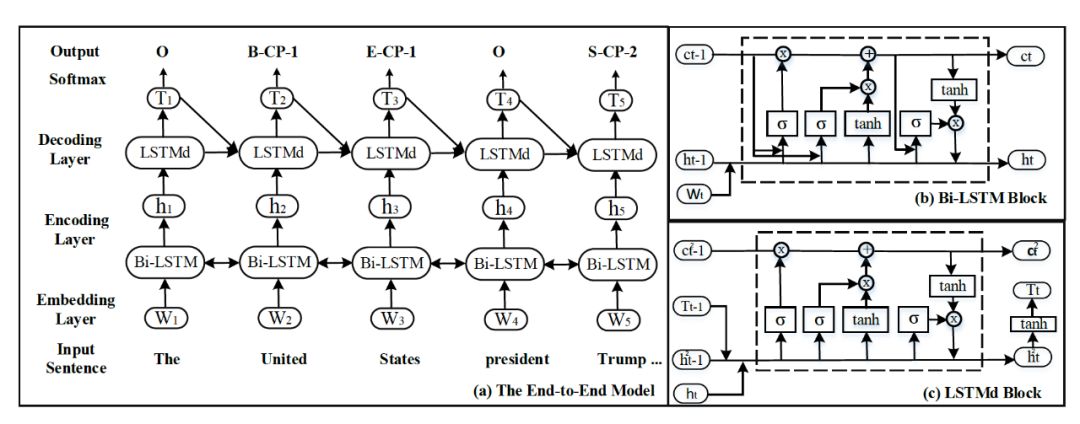
此文将实体关系联合抽取转换成一种新的标注模式,无需像以往研究一样,将实体和关系分步处理,直接对三元组建模。新的标签模式还可兼顾关系的方向性。针对新的标签模式,设计了一种新的loss bias函数。这为我们提供了一种新的思路,即复杂的模型往往不一定会有更好的效果,尤其对于工业及应用,代价更是无法预测。但是任务转换上的巧思,能让模型轻量的同时,得到好的效果。
但此模型也有待改进,第一,对于同一句话中的多个相同关系,只能通过就近原则解决;第二,没有考虑关系覆盖的情况。
《Extracting Relational Facts by an End-to-End Neural Model with Copy Mechanism》
以上模型都存在一个通病,即没有考虑到关系的overlapping问题,即一对实体之间存在多种关系,或一个实体参与多个关系,这在现实数据中是普遍存在的。如:"多发性肌炎临床表现包括对称性肌无力,可伴肌肉压痛,后期出现肌萎缩,以近端肢带肌为主。"中,"多发性肌炎"与"对称性肌无力"的关系是"疾病与症状","多发性肌炎"与"肌萎缩"的关系是"疾病与并发症"。
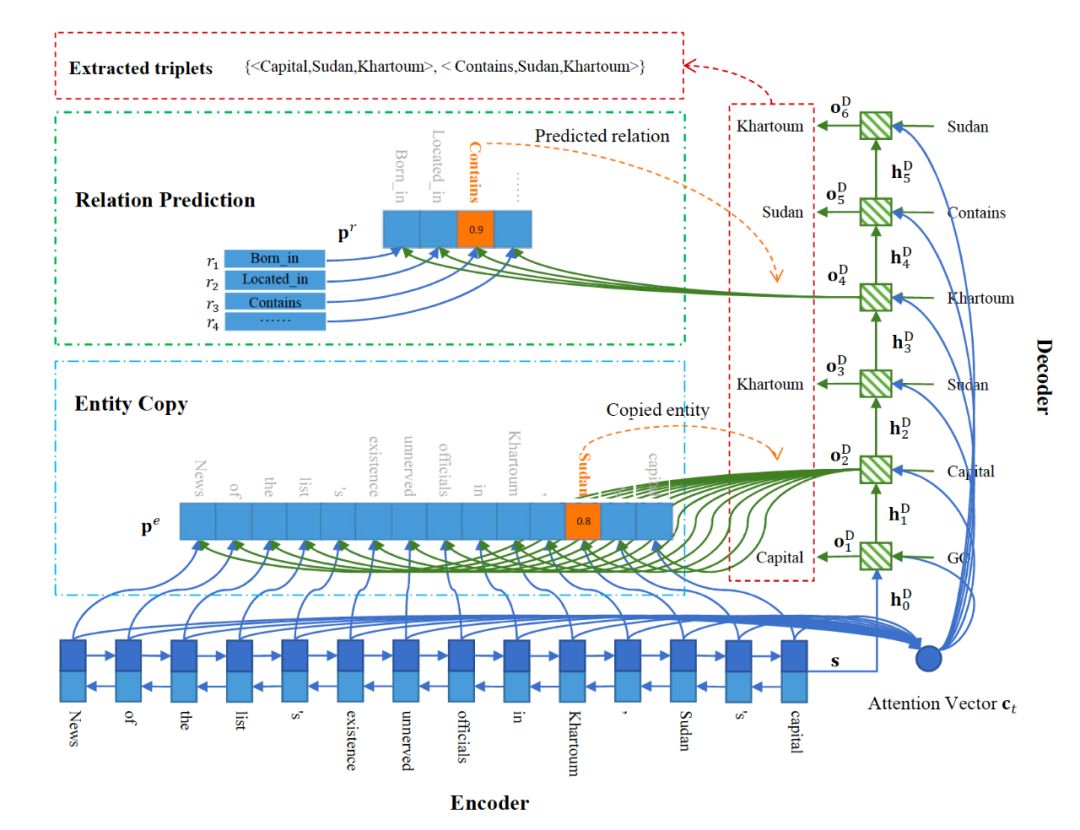
CopyR是一个Seq2seq学习框架,采用copy机制,根据三元组重叠度将句子分为三种类型,包括Normal EntityPairOverlap和SingleEntiyOverlap,其中应用多个解码器生成三个来处理重叠关系。将可变长度的句子编码成固定长度的矢量表示,然后将该矢量解码成相应的关系事实(三元组)。解码时,可以使用一个统一解码器解码所有三元组,或者使用分离的解码器解码每个三元组。实验将它们分别表示为OneDecoder模型和MultiDecoder模型。
《Adversarial training for multi-context joint entity and relation extraction》
利用AT(对抗学习)的概念作为正则化方法,使模型对输入扰动具有鲁棒性。具体来说,通过在级联单词表示的级别添加一些噪声来生成原始变体的示例。这类似于Goodfellow等人提出的概念,提高图像识别分类器的鲁棒性。通过将最坏情况扰动adv添加到最大化损失函数的原始嵌入w来生成对抗性示例:
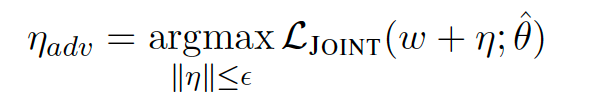
《A Hierarchical Framework for Relation Extraction with Reinforcement Learning》
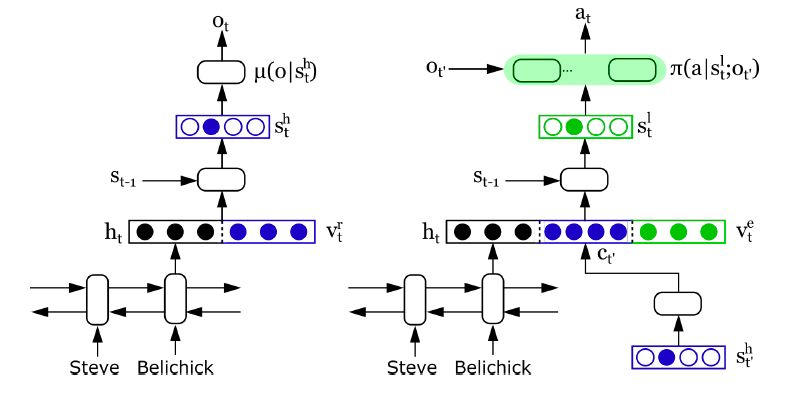
以往的模型存在两个问题:
首先,只有在所有实体都被识别之后才确定关系类型,而这两个任务之间的交互没有完全捕获。在某种意义上,这些方法是将关系与实体对对齐,因此,它们可能会引入额外的噪声,因为包含实体对的句子可能不会真正提到关系。
其次,对于一对多的问题(重叠关系),仍然缺乏联合抽取的优雅:一个实体可以参与同一句话中的多个关系,甚至一句话中的同一个实体对也与不同的关系相关联。据我们所知,CopyR是唯一一个讨论这个问题的方法,它将关系提取视为三次生成过程。然而,这种方法严重依赖于训练数据,无法提取多字实体。
于是论文提出了一种以相关实体为关系论据,处理关系提取的新范式。在这个范式中应用层次强化学习(hrl)框架来加强实体提及和关系类型之间的交互。整个提取过程被分解为两个层次的RL策略,分别用于关系检测(high-level)和实体提取(low-level),这样处理重叠关系更为可行和自然。
与其他模型不同,HRL的标注数据比较复杂,除了需要具有特定关系的实体对,还需要与当前关系无关的实体用于强化学习的reward过程。
联合抽取模型总结
模型复杂度高,时间空间代价较大。
所有模型都致力于解决一对多的问题(重叠关系),并充分利用实体信息。
就目前的数据量来说(1.8万+),效果较远监督模型有一定差距。
由于医疗文本中关系复杂多样,因此训练数据的标签分布是数据处理中的关键部分。
目前无论是哪一种关系抽取模型,我们除了在细节结构上整合各种策略,也会将BERT,和已有医疗知识图谱的表示学习模块加入到模型中,目的就是更好的抽取医疗实体关系,构建更高质量的医疗知识图谱。
属性抽取
实际上,属性抽取较之关系抽取的难点在于,除了要识别实体的属性名还要识别实体的属性值,而属性值结构也是不确定的,因此大多研究都是基于规则进行抽取,面向的也是网页,query,表格数据[9,10,11]。但是这种方法在医疗领域数据上有一定的弊端,因为医疗知识图谱不同于常识性知识图谱,它对于信息的质量有着很高的要求,对信息噪音的容错性也较低。
当然也有研究使用了一些机器学习模型对文本中的属性名进行序列标注,但这种方法的局限在于,实体属性实际上是非常丰富的,但模型除了需要标注数据,也无法cover多种多样的属性。
《ReNoun-Fact Extraction for Nominal Attributes》
通常假定事实是用动词短语表示的,因此很难为基于名词的关系提取事实[4]。ReNoun主要用于提取长尾型名词属性,首先从文本和查询流中提取一个大型但不完善的本体。然后使用一组小的高精度抽取器,利用属性的文本表达特性来获得一个训练集,然后通过远程监督从训练集中归纳出一组更大的抽取模式。最后,用基于三元组模式频率和属性之间的语义相似度来计算事实的分数。

《MetaPAD-Meta Pattern Discovery from Massive Text Corpora》

以往研究采用了一种基于依赖分析的模式发现方法,如ReNoun。但是,解析结果会丢失模式中实体周围丰富的上下文,而且对于大规模的语料库来说,这个过程代价很高[12,13,14]。本文提出一种新颖的类型化文本模式结构,称为元模式,在一定的语境下扩展到一个频繁、信息丰富、精确的子序列模式:MetaPAD,它使用三种技术从海量语料库中发现元模式:(1)开发了一种上下文感知的分割方法,通过学习模式质量评估函数来仔细确定模式的边界,避免了代价高昂的依赖性分析,并生成了高质量的模式。(2)从多个方面识别和分组同义元模式,包括它们的类型、上下文和提取;(3)检查每个模式组提取的实例中实体的类型分布,并寻找适当的类型级别,以使发现的模式精确。实验证明,该框架能够有效地从海量语料库的不同类型中发现高质量的类型文本模式,并有助于信息提取。
MetaPAD不是处理每个单独的句子,而是利用大量句子,其中冗余模式用于表示大规模实例的属性或关系。首先,MetaPAD使用有效的序列模式挖掘生成元模式候选,学习候选模式的质量评估函数,特征选择具有丰富的域独立上下文特征:频率,信息性。然后挖掘质量元模式通过评估引导的上下文感知分割。其次,MetaPAD将同义元模式的分组过程制定为学习任务,并整合多个方面的特征(包括实体类型,数据类型,模式上下文和提取的实例)。第三,MetaPAD检查每个元模式组中的实体类型分布,并寻找模式最合适的类型级别。包括自上而下和自下而上两种方案,这些方案遍历类型本体,以确保模式的准确性。
因此我们利用MetaPAD,采用了一种集成方法:
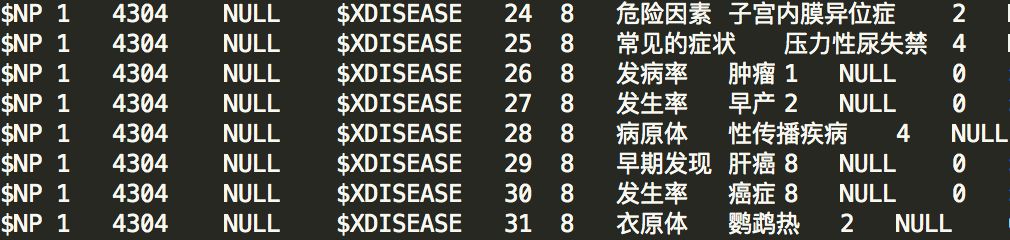
首先利用NER,名词短语抽取,词典,jiba对文本进行精准的分词,统计动词列表和停用词列表,并标注每个词的类型,如"Disease","NP"等,利用MetaPAD对海量数据进行pattern抽取,并统计pattern频次,通过TrueIE[15],筛选出描述实体属性的高质量语句pattern,并将其中的"NP"抽出,作为候选属性词。
然后,将所有候选属性词生成词典,重新对刚才的语料进行分词,并将所有属性词标记类型为"Attribute",进行第二次pattern抽取,只取与"Attribute"类型词有关的pattern,筛除其中的文本,作为属性值。对于属性值为句子的属性,直接截取相关语句作为答案。
实际上,MetaPAD不只可以用在属性抽取任务上,也可发现更多的术语表达,模版,统计信息等,工业价值比较高。

结语
本文主要介绍了关系抽取和属性抽取的以往研究,以及中文医疗数据在这些模型的效果和我们的一些改进做法。医疗信息抽取是图谱构建的重要环节,如何获取高质量的数据,是我们的目标。在当前工作的基础上,我们还有很多后续工作,如:在考虑到overlapping的同时,如何简化联合抽取模型的结构,降低模型的训练时间;如何利用"杂乱无章"的实体,关系,属性信息构建concept层级架构,用于搜索推荐;以及信息抽取技术在搜索实时应用上的运用。
参考文献
[1] Relation Classification via Convolutional Deep Neural Network.
[2] Incremental joint extraction of entity mentions and relations.
[3] Modeling joint entity and relation extraction with table representation.
[4] Global Inference for Entity and Relation Identification via a Linear Programming..
[5] Joint inference for fine-grained opinion extraction.
[6] Joint entity and relation extraction using card-pyramid parsing.
[7] Jointly identifying entities and extracting relations in encyclopedia text via a graphical model approach.
[8] Joint inference of entities, relations, and coreference.
[9] Weakly-Supervised Acquisition of Open-Domain Classes and Class Attributes from Web Documents and Query Logs.
[10] Attribute extraction and scoring-a probabilistic approach.
[11] Automatic Discovery of Attribute Synonyms Using Query Logs and Table Corpora.
[12] ReVerb:Identifying Relations for Open Information Extraction.
[13] Open information extraction from the web.
[14] Toward an architecture for never-ending language learning.
[15] TruePIE: Discovering Reliable Patterns in Pattern-Based Information Extraction.
招聘信息
丁香园大数据NLP团队招聘各类算法人才,Base杭州。NLP团队的使命是利用NLP(自然语言处理)、Knowledge Graph(知识图谱)、Deep Learning(深度学习)等技术,处理丁香园海量医学文本数据,打通电商、在线问诊、健康知识、社区讨论等各个场景数据,构建医学知识图谱,搭建通用NLP服务。团队关注NLP前沿技术,也注重落地实现,包括但不仅限于知识图谱、短文本理解、语义搜索、可解释推荐、智能问答等。加入我们,让健康更多,让疾病更少!
欢迎各位朋友推荐或自荐至 kanfang@dxy.cn
本文转载自公众号丁香园大数据,作者丁香园大数据NLP
推荐阅读
大幅减少GPU显存占用:可逆残差网络(The Reversible Residual Network)
AINLP-DBC GPU 云服务器租用平台建立,价格足够便宜
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。




