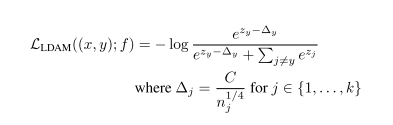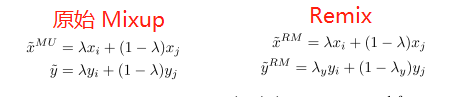加入极市专业CV交流群,与 1 0000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 , 回复 加群, 立刻申请入群~
就在明天 极市平台将独家直播由山东大学主办的“ 可视计算 ”学术专题报告。国内外的知名学术专家,会就各自领域的 基础理论、应用前景与前沿技术 等方面进行专题报告。 请大家锁定直播时间7月17日(星期五)—7月19日(星期日) 这里 ,在 极市平台 后台回复“ 61 ”,即可获取直播链接 。
来源|汤凯华@知乎,https://zhuanlan.zhihu.com/p/158638078
本文主要整理了长尾(不均衡)分布下图片分类问题的近年(2019-2020)研究,如有遗漏,欢迎提醒
。
目前我将这些研究分为三类,根据我个人的偏好依次分为:
3)迁移学习(transfer learning)相关
据我了解,目前在长尾图片分类任务上取得最优结果的两篇论文Decoupling和BBN都是采取了对重采样(re-sampling)技术的改进,并且他们同时发现了一个相似的规律,我觉得对长尾分布乃至任意不均衡分布下识别任务的研究都有着重要的启发(我会在下面详细介绍),所以我个人最看好这类方法。其次,我相对而言也比较喜欢纯粹的重加权(re-weighting)相关的拓展研究,通过对loss的改进来解决长尾/不均衡分布问题,我喜欢这类研究的原因是,他们(大部分)实现简单,往往只需几行代码修改下loss,就可以取得非常有竞争力的结果,因为简单所以很容易运用到一些复杂的任务中。而我个人
目前 比较不看好的方向,其实反而是各种迁移模型,虽然他们的理念非常好,从头部常见类中学习通用知识,然后迁移到尾部少样本类别中。但是这类方法,往往会需要设计额外的非常复杂的模块,我认为这其实是把简单问题复杂化。简化问题的过程通常是在接近问题本质,可过度复杂的方案则更多的是利用人为的知识去更好的过拟合特定数据。不过我目前的偏好也并非绝对,也许未来就有人可以设计出简单有效的迁移模型。下面我就对这三类方法所涉及的近年文章一一做简单的介绍。
重采样(re-sampling)相关
1. Decoupling Representation and Classifier for Long-Tailed Recognition, ICLR 2020
链接:https://arxiv.org/abs/1910.09217
代码:https://github.com/facebookresearch/classifier-balancing
这篇文章应该是目前长尾图片分类领域的SOTA了。
该文章和下面的BBN共同发现了一个长尾分类研究的经验性规律:
对任何不均衡分类数据集地再平衡本质都应该只是对分类器地再均衡,而不应该用类别的分布改变特征学习时图片特征的分布,或者说图片特征的分布和类别标注的分布,本质上是不耦合的。(当然,这是我自己的总结,原文没这段,也没任何证明hhhhh)
基于这个规律,Decoupling和BBN提出了两种不同的解决方案,又因为Decoupling的方案更简单,实验更丰富,所以我这里优先介绍Decoupling方法。
Decoupling将长尾分类模型的学习分为了两步。第一步,先不作任何再均衡,而是直接像传统的分类一样,利用原始数据学习一个分类模型(包含特征提取的backbone + 一个全连接分类器)。第二步,将第一步学习的模型中的特征提取backbone的参数固定(不再学习),然后单独接上一个分类器(可以是不同于第一步的分类器),对分类器进行class-balanced sampling学习。此外,作者还发现全连接分类器的weight的norm和对应类别的样本数正相关,也就是说样本数越多的类,weight的模更大,这也就导致最终分类时大类的分数(logits)更高(对头部类的过拟合)。所以第二步的分类器为归一化分类器,文章中有两种较好的设计:1)
Decoupling的核心在于图片特征的分布和类别分布其实不耦合,所以学习backbone的特征提取时不应该用类别的分布去重采样(re-sampling),而应该直接利用原始的数据分布。
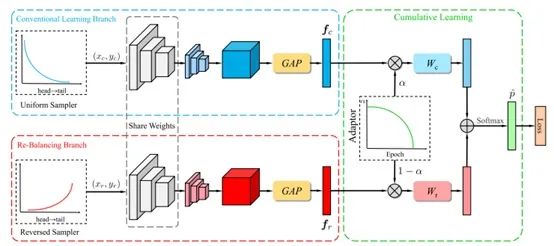
2. BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition,CVPR 2020
链接:https://arxiv.org/abs/1912.02413
代码:https://github.com/Megvii-Nanjing/BBN
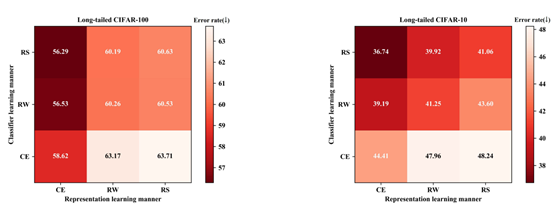
BBN的核心idea和Decoupling其实是一样的。正因为两个人同时发现了同样的规律,更证明了这个规律的通用性和可靠性。关于上文的规律,BBN做了更详细的分析:
这个图说明,长尾分类的最佳组合来自于:利用Cross-Entropy Loss和原始数据学出来的backbone + 利用Re-sampling学出来的分类器。
和Decoupling的区别在于,BBN将模型两步的学习步骤合并至一个双分支模型。该模型的双分支共享参数,一个分支利用原始数据学习,另一个分支利用重采样学习,然后对这两个分支进行动态加权(
3. Dynamic Curriculum Learning for Imbalanced Data Classification,ICCV 2019
链接:https://arxiv.org/abs/1901.06783
课程学习(Curriculum Learning)是一种模拟人类学习过程的训练策略,旨在从简到难。先用简单的样本学习出一个比较好的初始模型,再学习复杂样本,从而达到一个更优的解。这篇文章的详细分析可以看知乎文章https://zhuanlan.zhihu.com/p/74166778
根据原文的总结,该框架包括两个level的课程学习方案:1)Sampling Scheduler:调整训练集的数据分布,将采样数据集的样本分布从原先的不平衡调整到后期的平衡状态;2)Loss Scheduler:调整两个Loss(分类Loss和度量学习Loss)的权重,从一开始倾向于拉大不同类目之间特征的距离(度量学习Loss),到后期倾向于对特征做分类(分类Loss)。
重加权(re-weighting)相关
4. Class-Balanced Loss Based on Effective Number of Samples,CVPR 2019
链接:https://arxiv.org/abs/1901.05555
代码:https://github.com/richardaecn/class-balanced-loss
这篇文章的核心理念在于,随着样本数量的增加,每个样本带来的收益是显著递减的。所以作者通过理论推导,得到了一个更优的重加权权重的设计,从而取得更好的长尾分类效果。实现上,该方法在Cross-Entropy Loss中对图片根据所属类给予
5. Learning Imbalanced Datasets with Label-Distribution-Aware Margin Loss,NIPS 2019
链接:https://arxiv.org/abs/1906.07413
代码:https://github.com/kaidic/LDAM-DRW
这篇文章首先设计了一个如下的非典型的重加权loss。其中C是常数,
其次,该文章设计了一个两步的训练方法。第一步只利用LDAM loss训练,第二步利用LDAM loss再额外加上传统的re-weighting权重
6. Rethinking Class-Balanced Methods for Long-Tailed Visual Recognition from a Domain Adaptation Perspective, CVPR 2020
链接:https://arxiv.org/abs/2003.10780
这篇文章对loss的加权分为两项:其一,用上面Class-Balanced Loss Based on Effective Number of Samples的weight作为
而条件权重的学习,则需要再利用Meta-Learning去内部迭代,优化其在一个balanced开发集上的结果。总的来说,idea挺好,但实现上是个偏复杂的方法。由于Meta-Learning的内部迭代,训练也将更费时间费显存。
7. Remix: Rebalanced Mixup,
Arxiv Preprint 2020
链接:https://arxiv.org/abs/2007.03943
Mixup是一个这两年常用的数据增强方法,简单来说就是对两个sample的input image和one-hot label做线性插值,得到一个新数据。实现起来看似简单,但是却非常有效,因为他自带一个很强的约束,就是样本之间的差异变化是线性的,从而优化了特征学习和分类边界。
而Remix其实就是将类别插值的时候,往少样本类的方向偏移了一点,给了小样本更大的
迁移学习(transfer learning)相关
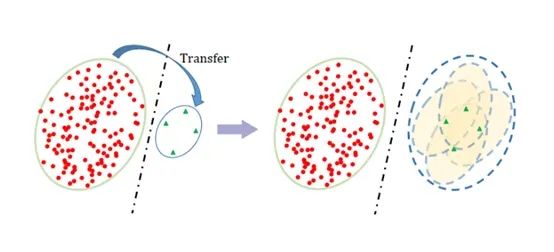
8. Deep Representation Learning on Long-tailed Data: A Learnable Embedding Augmentation Perspective,CVPR 2020
链接:https://arxiv.org/abs/2002.10826
详细分析可以看作者知乎原文(https://zhuanlan.zhihu.com/p/112248291)。简单来说,长尾分布中因为尾部样本缺乏,无法支撑一个较好的分类边界,这篇工作在尾部的样本周围创造了一些虚拟样本,形成一个特征区域而非原先的特征点,即特征云(feature cloud)。而如何从特征点生成特征云,则利用的头部数据的分布。图例如下:
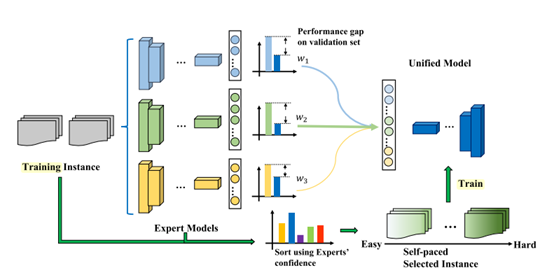
9. Learning From Multiple Experts: Self-paced Knowledge Distillation for Long-tailed Classification,ECCV 2020
链接:https://arxiv.org/abs/2001.01536
暂且归为迁移学习类。作者发现在一个长尾分布的数据集中,如果我们取一个更均衡的子集来训练,其结果反而比利用完整的数据集效果更好。所以原文利用多个子集来训练更均衡的专家模型来指导一个unified学生模型。
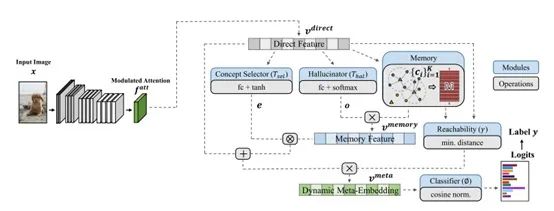
10. Large-Scale Long-Tailed Recognition in an Open World,CVPR 2019
链接:https://arxiv.org/abs/1904.05160
代码:https://github.com/zhmiao/OpenLongTailRecognition-OLTR
该方法学习一组动态的元向量(dynamic meta-embedding)来将头部的视觉信息知识迁移给尾部类别使用。这组动态元向量之所以可以迁移视觉知识,因为他不仅结合了直接的视觉特征,同时也利用了一组关联的记忆特征(memory feature)。这组记忆特征允许尾部类别通过相似度利用相关的头部信息。
其他
此外最近刚看到一个有意思的paper:Rethinking the Value of Labels for Improving Class-Imbalanced Learning, Arxiv Preprint 2020,就是关于如何利用半监督和自监督来解决类别不均衡的问题,因为既然数据的标注难免会遇到类别不均衡的问题,那么如果不利用或少利用类别信息,是否可以解决长尾/不均衡分布问题呢?有兴趣的同学可以去看下原文(https://arxiv.org/abs/2006.07529),我还没细看。
因为图片级别的数据易于生成或收集,baseline模型也简单,目前主要的长尾分布研究都集中在图片分类领域。不过随着去年Facebook发布的LVIS(Large Vocabulary Instance Segmentation)数据集(https://arxiv.org/abs/1908.03195),越来越多的人也开始关注起了Instance级别的长尾分布分布问题(物体检测和实例分割),我会在下一节更新这方面的工作。
添加极市小助手微信
(ID : cv-mart) ,备注:
研究方向-姓名-学校/公司-城市 (如:目标检测-小极-北大-深圳),即可申请加入
极市技术交流群
,更有
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、 干货资讯汇总、行业技术交流 ,
一起来让思想之光照的更远吧~
△长按添加极市小助手
△长按关注极市平台,获取 最新CV干货
觉得有用麻烦给个在看啦~