这门华东6所名校同步开课的系列课程,上线机器之心知识站
城市综合治理、自动驾驶、视频理解、遥感影像解译……这些最热门的人工智能应用,都离不开计算机视觉技术。
如何成为面向未来的计算机视觉和人工智能创新人才?
4月12日起,《通用视觉框架OpenMMLab》系列课程上线机器之心知识站,点击「阅读原文」即可进入知识站一起学习。
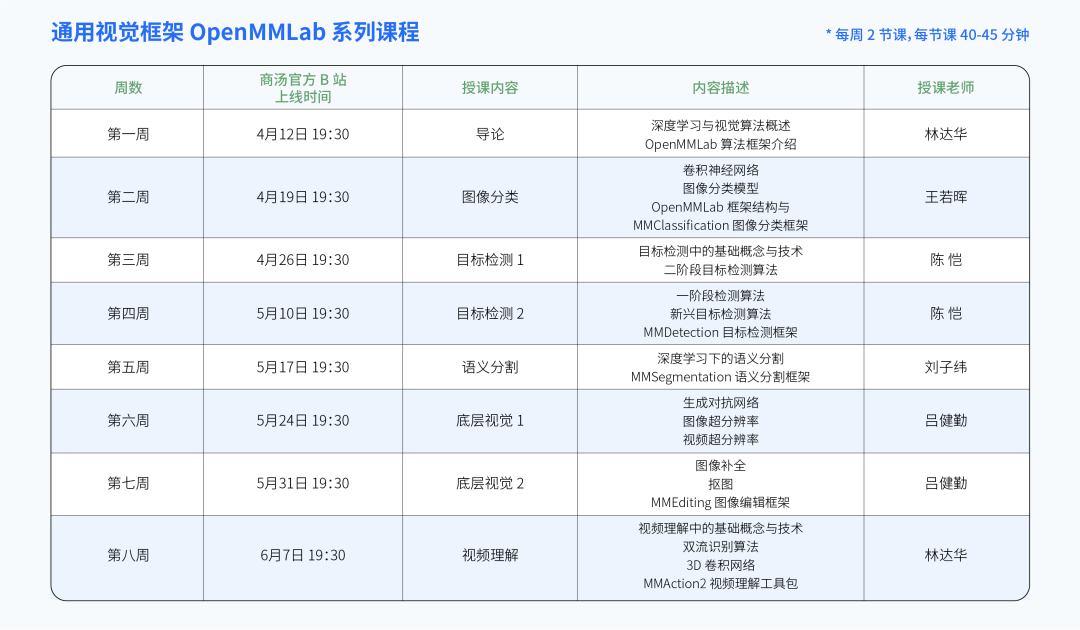
-
图像分类:对图像中的物体目标分类出其所属类别的标签,如人、楼房、街道、车辆等。 -
目标检测:从图像中将指定的目标进行提取,是很多计算机视觉任务的基础。 -
语义分割:针对每个像素进行类别预测,并对整个图像按照类别进行分割,划分道路、车辆、植物等区域。 -
底层视觉:包括超分,抠图,修复等多项底层视觉任务。 -
视频理解:实现针对视频的动作识别,时序动作检测,时空动作检测等任务。

登录查看更多
相关内容

Arxiv
3+阅读 · 2017年8月3日




相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2017年8月3日