简单12招让Hive运行快一点,再快一点

摘要:Hive可以让你在Hadoop上使用SQL,但是在分布系统上的SQL的调优是不同的。这里有12个技巧能够帮助你。 Hive并不是一个关系型数据库,但它假装是大部分情况中的一个。它有表格,运行SQL,并且支持JDBC和ODBC。 这个启 …
Hive可以让你在Hadoop上使用SQL,但是在分布系统上的SQL的调优是不同的。这里有12个技巧能够帮助你。
Hive并不是一个关系型数据库,但它假装是大部分情况中的一个。它有表格,运行SQL,并且支持JDBC和ODBC。
这个启示有利及不利的消息:Hive不运行查询数据库方式。这是一个很长的故事,但是我在工作周花了80多个小时亲自调整Hive。不用说,我不必再头疼了。因此,为了您的利益,这里有一些建议,让你的Hive项目比我的运行的快一点。
1、不要使用MapReduce
你是否相信Tez,Spark或者Impala,但是不相信MapReduce。它是缓慢的,它比Hive还要慢。如果你在Hortonwork的分布,你可以在脚本的顶部输入 set hive.execution.engine=tez
在子句中使用Impala.希望当你的impala不再合适的时候设置 hive.execution.engine=spark
2、不要在SQL字符串配对
注意,尤其是在Hive,如果你在本该是子句的地方配对字符串,会产生一个交叉的产品警告。如果你有一个几秒内运行的查询,与需要几分钟才能配对的 字符串。你*好选择使用多个工具,允许你添加搜索Hadoop。查看Elasticsearch’s Hiveintegration or Lucidwork’s integration for Solr。或者,哪里有Cloudera Search. RDBMSes 非常善于做这个,但是Hive就很差了。

Apache Hive拟人画
3、不要加入一个子查询
你*好创建一个临时列表,然后加入临时表不询问Hive如何智能的处理子查询。也就是说不要这么做。

而是要这么样做

在这一点上,它真的不应该在Hive的进化上如此之快,但是它通常是这样的。
4、使用Parquet或者ORC,但是不要把它们转化成运动
这就是说,相对用Parquet或者ORC,例如,TEXTFILE。然而,如果你有文本数据进来,并且促进它变的更结构化,转换到目标表。你不能从文本文件加载数据到一个ORC,所以做初始加载到文本。
如果你创建其他的表,你*终会运行不到你的分析。在那里做ORCing,因为转换到ORC或者Parquet需要时间,并且不值得进行你的ETL过程的第一步。如果你有简单的平面文件进来,并且不做任何调整。然后你被加载到一个临时表,并且选择创建一个ORC或者Parquet。我不嫉妒你因为它真的很慢。
5、尝试把矢量化打开或者关闭
增加
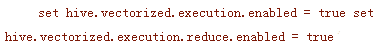
在你的脚本的顶端。尝试让它们开或关,因为矢量化在Hive的新版本中似乎有一些问题。
6、不要用结构加入
我不得不承认我原本的大脑的SQL语法依然是SQL-92时代,所以我无论如何不倾向于使用结构。但是如果你做一些像对复合PKS子句超重复的事 情,结构是方便的。不幸的是,Hive隔断了它们——尤其是在子句上,当然,在较小的数据集并没有这么做,也没有产生任何错误的时间。在绝对禁区,你得到 一个有趣的向量误差。这个限制是没有记录任何我所知道的地方。把这个看成是一个有序的方式来了解你的执行引擎的内部结构!
7、检查容器的尺寸
你可能需要为Impala或者Tez增加你容器的尺寸。此外,”建议”尺寸可能不适用于您的系统,如果你有较大的节点尺寸。你可能要确保你的YARN队列和一般的YARN记忆是恰当的。你可能还想把它钉在一个东西上,这个东西不是所有人都使用的默认队列。
8、启动统计
Hive的确有点愚蠢的东西加入,除非数据启动起来。你可能还想在Impala使用查询提示。
9、考虑Mapjoin优化
如果你对查询做了解释,你可能会发现*近Hive的版本足够聪明到去自动应用优化的。但是你需要去调整他们。
10、如果可以,把*大的表放在*后
11、区分你的朋友……额……
如果你在许多子句的地方有一个项目,如一个日期(但是并不是一个理想的范围)或者重复的位置,您可能有您的区分键!分区的基本意思是”分裂成为它自 己的目录,”这意味着不是在寻找一个大的文件,Hive查看一个文件,因为你用你的join/where从句让你只看location=’NC’,这是你 的一个小数据集。此外,与列值不同,您可以在负载数据报表中推分区。但是,请记住,HDFS不喜欢小的文档。
12、使用哈希表列的比较
如果你在每个查询中比较相同的10个字段,考虑使用()对比总结。这些有时是非常有用的,你可能会把它们放在一个输出表中。注意Hive0.12是低分辨率的,但是更好的可以使用的值在0.13。

媒体合作请联系:
邮箱:xiangxiaoqing@stormorai.com