UC 伯克利大学计算机科学博士胡戎航(Ronghang Hu)的博士论文新鲜出炉,内容涉及视觉与语言推理的结构化模型。
![]()
视觉 - 语言任务(如基于图像回答问题或按照自然语言指令在视觉环境中导航)需要对图像和文本两种模态的数据进行联合建模和推理。视觉和语言联合推理方面已经取得了很大进步,但通常使用的是在更大的数据集和更多计算资源帮助下训练的神经方法。
视觉 - 语言任务的解决是否只是堆参数堆数据那么简单?如果不是,如何构建更好的推理模型,既能提高数据效率又具备不错的泛化性能呢?UC 伯克利胡戎航的博士论文就是关于这个主题:
![]()
论文链接:https://www2.eecs.berkeley.edu/Pubs/TechRpts/2020/EECS-2020-50.pdf
这篇论文通过视觉 - 语言推理的结构化模型为上述问题提供了答案,该模型考虑了人类语言、视觉场景、智能体技能中的模式和规律。
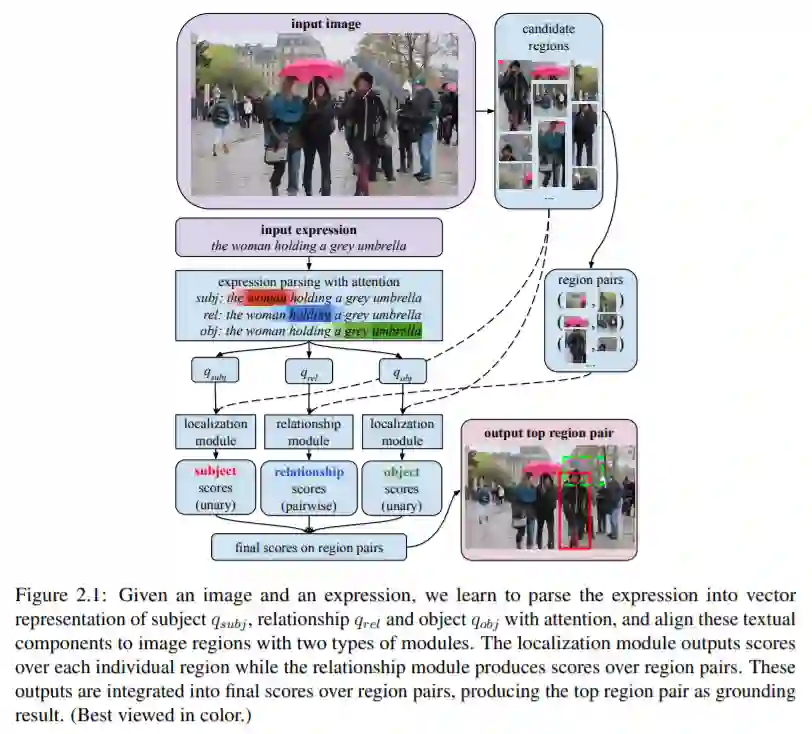
这篇论文从指示表达定位(referring expression grounding)任务开始,使用 Compositional Modular Network (CMN) 来考虑这些表达中的组合结构,进而显著提高准确率和泛化性。
具体而言,该论文提出使用联合方法显式地对指示表达及其定位的组合语言结构建模,同时也支持对任意语言的解释。这里提出的 CMN 网络是一种端到端训练模型,可以联合学习语言表征和图像区域定位,如图 2.1 所示。
![]()
视觉问答(VQA)需要同时理解图像和文本。这种理解通常取决于组合推理( compositional reasoning),如定位一个场景中的多个对象,检查其属性或将其相互比较。尽管传统的深度网络在 VQA 任务中的性能不错,但是表明其能够进行显式组合推理的证据有限。针对这一问题,该论文提出了端到端模块网络(N2NMN),该模型能够直接基于文本输入预测新型模块化网络架构,并将其应用于图像,来解决问答任务。该方法学习将语言解析为语言结构,再将其组合成合适的布局。
第四章中,研究者扩展了关于模块推理的工作,提出了堆栈神经模块网络(SNMN)。该模型使用显式的模块化推理过程,它可以通过反向传播进行完全可微的训练,而无需对推理步骤进行专家监督。与现有的模块化方法相比,该方法提高准确率和可解释性。
此外,该模型还可以进行扩展,在一个模型中无缝处理视觉问答 (VQA) 和指示表达定位。这通过下图所示的一般程序完成相关任务之间的知识共享:
![]()
除了模块推理,研究者还提出了使用语言条件图网络(LCGN)构造视觉场景的语境感知表示,以进行关系推理。该模型是基于场景中的视觉实体构建的图网络,并通过实体之间消息传递的多次迭代来收集关系信息。LCGN 通过对图中的边进行加权,动态地确定每一轮从哪些对象收集信息,并通过图发送消息以传播适量的关系信息。其关键思想是根据输入文本的特定语境关系来调整消息传递。
![]()
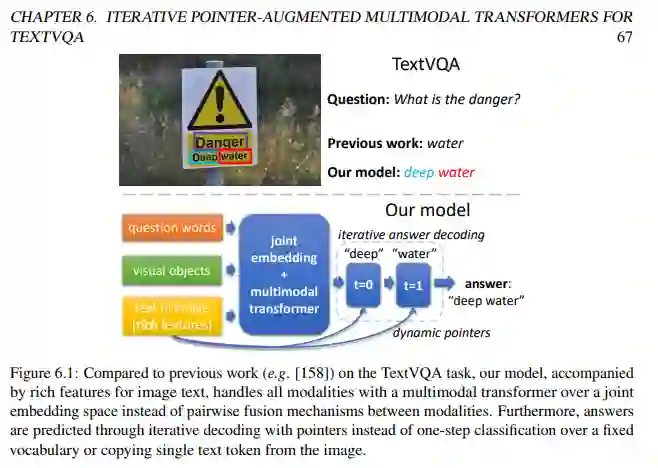
在第六章中,该研究使用迭代式指针增强多模态 Transformer,来解决从图像中读取文本并回答问题的任务(即 TextVQA 任务)。
对于 TextVQA 任务,该研究提出新型 Multimodal Multi-Copy Mesh (M4C)。该模型基于 transformer 架构,并通过动态指针进行迭代式答案解码,如图 6.1 所示:
![]()
针对导航指令跟随任务,该研究提出了 Speaker-Follower 模型,其中 Speaker 模型和 Follower 模型相互补充。
该研究把导航指令跟随任务视为一个轨迹搜索问题,智能体需要根据指令找到环境中的最佳轨迹,从起始位置导航到目标位置。Speaker-Follower 模型包括一个指令理解模块(follower),将指令映射到动作序列;一个指令生成模块(speaker),将动作序列映射到指令(图 7.1),这两个模块均通过标准的序列到序列架构实现。speaker 模块学习为视觉路线提供文本指令,follower 模块则根据提供的文本指令执行路线(预测导航动作)。
![]()
![]()
![]()
![]()
胡戎航是 Facebook 人工智能研究院 (FAIR) 的研究科学家,研究兴趣包括视觉与语言推理、视觉感知。他于 2020 年在 Trevor Darrell 教授和 Kate Saenko 教授的指导下获得 UC Berkeley 的计算机科学博士学位。
Amazon SageMaker实战教程(视频回顾)
Amazon SageMaker 是一项完全托管的服务,可以帮助机器学习开发者和数据科学家快速构建、训练和部署模型。Amazon SageMaker 完全消除了机器学习过程中各个步骤的繁重工作,让开发高质量模型变得更加轻松。
10月15日-10月22日,机器之心联合AWS举办3次线上分享,全程回顾如下,复制链接到浏览器即可观看。
另外,我们准备了Amazon SageMaker 1000元服务抵扣券,帮助开发者体验各项功能。点击阅读原文,即可领取。
![]()
第一讲:Amazon SageMaker Studio详解
主要介绍相关组件,如studio、autopilot等,并通过在线演示展示这些核心组件对AI模型开发效率的提升。
-
视频回顾地址:
https://app6ca5octe2206.h5.xiaoeknow.com/v1/course/alive/l_5f715443e4b005221d8ea8e3
第二讲:使用Amazon SageMaker 构建一个情感分析「机器人」
主要介绍情感分析任务背景、进行基于Bert的情感分析模型训练、利用AWS数字资产盘活解决方案进行基于容器的模型部署。
第三讲:DGL图神经网络及其在Amazon SageMaker上的实践
主要介绍图神经网络、DGL在图神经网络中的作用、图神经网络和DGL在欺诈检测中的应用和使用Amazon SageMaker部署和管理图神经网络模型的实时推断。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com