数据挖掘巨擘俞士纶:真实数据源不止一个,学习不仅要有深度还要有广度

深挖洞,广积粮!
作者 | Camel
排版 | 唐里


-
首先,定义并获取相关的有用数据源,也即找到对你的问题有用的数据。 -
其次,设计一种模型来将异质数据源信息融合起来。 -
最后,基于模型整体的需求从各种数据源中深度地去挖掘信息。

首先是在同一个实体上有不同类型信息的学习。这种类型的广度学习包括 Multi-view Learning、Multi-source Learning、Multi-model Learning 等。
其次是在不同的但类型相似的实体上信息的学习。这包括 Transfer Learning。
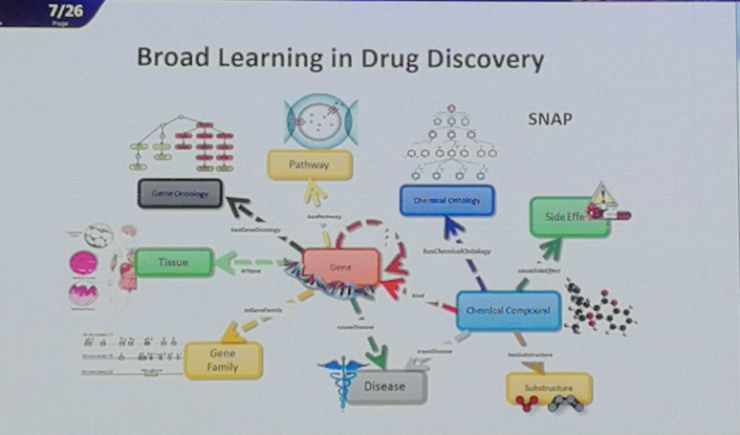
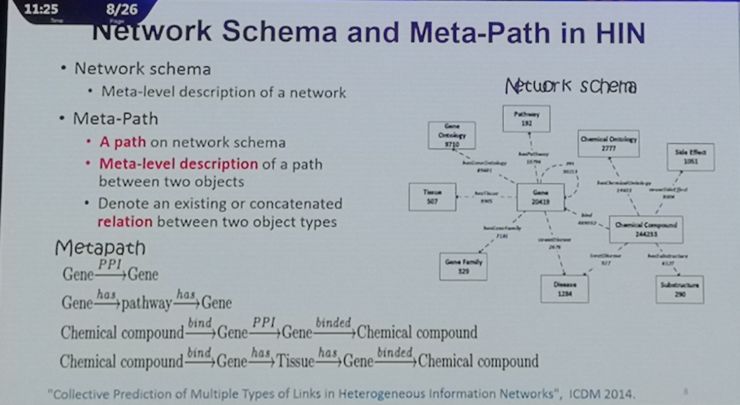
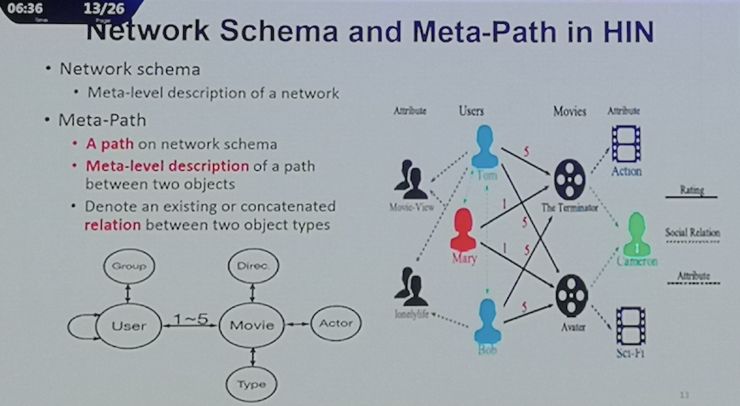
另外是在有复杂网络类型关系的不同类型实体信息的学习。这包括基于融合的异质信息网络(HIN)。




点击“阅读原文”进入 AI 研习社
登录查看更多
相关内容

俞士纶,美国伊利诺伊大学芝加哥分校(UIC)特聘主任教授、美国计算机学会(ACM)及美国电气电子工程师学会(IEEE)院士(Fellow),清华大学特聘教授。他曾于美国IBM Watson研究中心工作多年,创建了世界知名的数据挖掘及数据管理部,是IBM公司拥有专利最多的人之一。作为国际数据库和数据挖掘等领域的先驱之一,作为国际数据挖掘和数据管理领域的顶尖学者,曾担任多个著名国际期刊主编、副主编以及多个顶级国际学术会议的程序委员会主席和委员,在国际著名学术期刊与重要国际学术会议(如SIGKDD、SIGMOD,WWW、AAAI等)上发表论文970余篇,专利300余项,在谷歌学术上的H-index高达138。自1981-2018年Philip S. Yu的研究成果有1094项,2018年全球计算机科学和电子领域排名第九,华人排名第二。Philip S. Yu的主要研究兴趣包括数据挖掘、隐私保护发布和挖掘、数据流、数据库系统、互联网应用和技术、多媒体系统、并行和分布式处理以及性能建模。
专知会员服务
49+阅读 · 2019年11月15日
Arxiv
78+阅读 · 2019年11月10日



相关VIP内容
专知会员服务
49+阅读 · 2019年11月15日
相关资讯
相关论文
Arxiv
78+阅读 · 2019年11月10日