歪比歪比,歪比巴卜,神经网络也该用上加密“通话”了

《Key-Nets: Optical Transformation Convolutional Networks for Privacy Preserving Vision Sensors》
这篇论文为设计保护隐私的深度学习应用提供了一种范式。

动机

方法
2.1 视觉变换网络
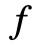 ,
需要满足五个充分条件,分别是
,
需要满足五个充分条件,分别是
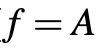 ,我们就可以通过
,我们就可以通过
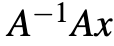 将原始采集到的图像恢复出来;
将原始采集到的图像恢复出来;
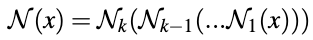
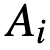 ,输入图像的加密因子为
,输入图像的加密因子为
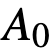 (模拟传感器的光学加密),加密后的图像为
(模拟传感器的光学加密),加密后的图像为
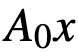 ,则卷积神经网络变为:
,则卷积神经网络变为:
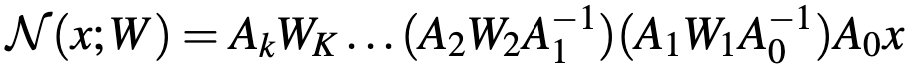
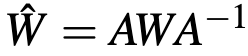 表示某一层的权重加密结果,加密因子
表示某一层的权重加密结果,加密因子
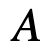 及其逆
及其逆
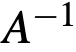 存在,这满足了上面的条件1和2。根据条件4,我们假设存在一个非线性激活函数
存在,这满足了上面的条件1和2。根据条件4,我们假设存在一个非线性激活函数
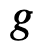 满足非线性交换律,
满足非线性交换律,
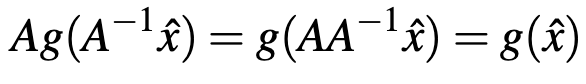
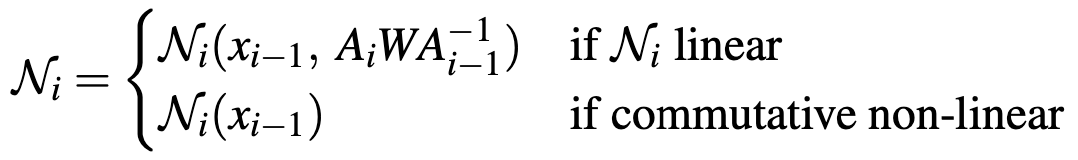 即可,对于非线性激活层,由于条件3的存在,无需作出任何修改,网络示意图如下:
即可,对于非线性激活层,由于条件3的存在,无需作出任何修改,网络示意图如下:
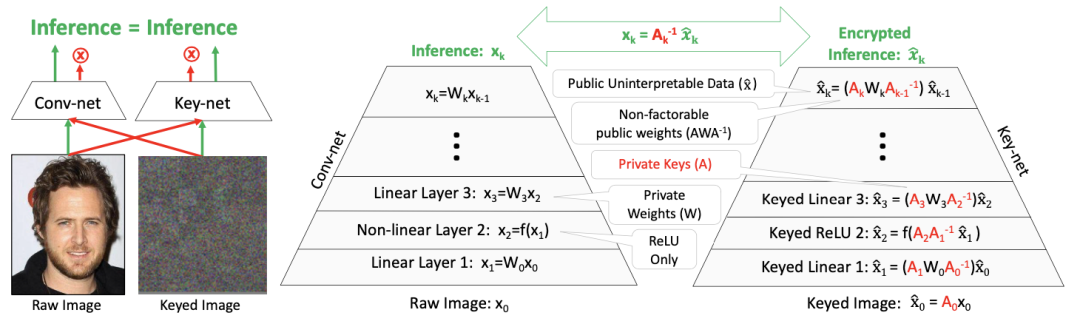
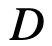 和一系列置换矩阵的凸组合构成:
和一系列置换矩阵的凸组合构成:
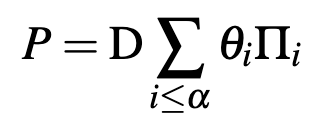
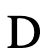 可以将干扰噪声通过仿射变换
可以将干扰噪声通过仿射变换
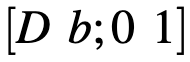 施加到图像上,而置换矩阵
施加到图像上,而置换矩阵
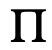 是一个随机方阵,它的每行和每列都正好有一个元素为1,其他元素为0,它可以对图像执行像素级的随机组合和几何退化操作。由于构造的特殊性,广义随机矩阵恰好满足上面提出的五个充分条件。
的随机程度逐渐加大,图像像素值的随机组合效果也越明显,从上到下表示对角矩阵
的干扰噪声对图像的影响,两种效应共同作用,使得右下角生成的图像是人类无法理解的。
是一个随机方阵,它的每行和每列都正好有一个元素为1,其他元素为0,它可以对图像执行像素级的随机组合和几何退化操作。由于构造的特殊性,广义随机矩阵恰好满足上面提出的五个充分条件。
的随机程度逐渐加大,图像像素值的随机组合效果也越明显,从上到下表示对角矩阵
的干扰噪声对图像的影响,两种效应共同作用,使得右下角生成的图像是人类无法理解的。
 2.2 视觉传感器
2.2 视觉传感器
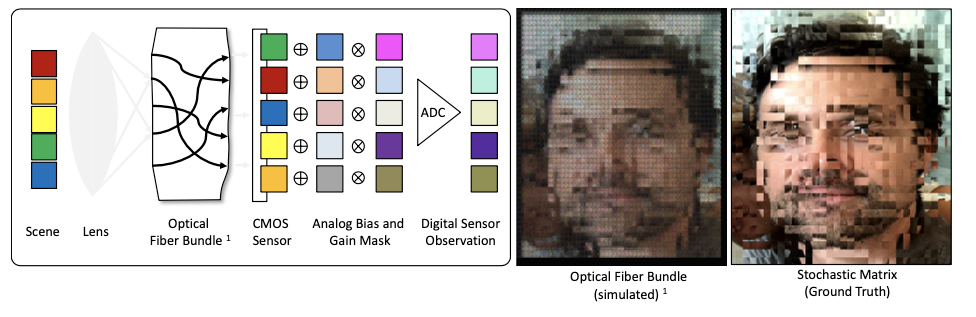
实验
3.1 keynet必要性实验
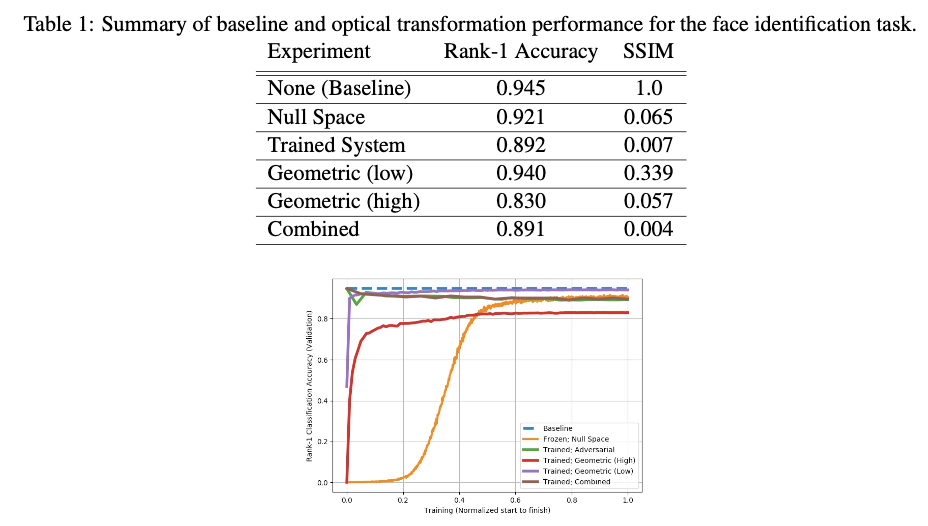

3.2 keynet性能实验
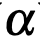 的函数,实验结果如下表所示
的函数,实验结果如下表所示

总结
在10月1日头条留言区留言,谈一谈你对这两本书的看法或有关的学习、竞赛等经历。
AI 科技评论将会在留言区选出15名读者,送出《阿里云天池大赛赛题解析——机器学习篇》10本,《集成学习:基础与算法》5本,每人最多获得其中一本。
活动规则:
1. 在留言区留言,留言点赞最高的前 15 位读者将获得赠书,活动结束后,中奖读者将按照点赞排名由高到低的顺序优先挑选两本书中的其中一本,获得赠书的读者请添加AI科技评论官方微信(aitechreview)。
2. 留言内容会有筛选,例如“选我上去”等内容将不会被筛选,亦不会中奖。
3. 本活动时间为2020年10月1日 - 2020年10月8日(23:00),活动推送内仅允许中奖一次。
AI科技评论现建立摸鱼划水群,供大家闲聊一些学术以及非学术问题(禁广告、禁敏感话题,群满请加微信aitechreview)

点击阅读原文,直达NeurIPS小组~
登录查看更多
相关内容

专知会员服务
10+阅读 · 2019年10月30日
Arxiv
0+阅读 · 2020年12月3日
Arxiv
0+阅读 · 2020年12月1日



相关VIP内容
专知会员服务
10+阅读 · 2019年10月30日
相关资讯