丛京生院士深度解读可定制计算的设计自动化:自动将代码转换成电路描述,解决开发人员最大难题

新智元报道
【新智元导读】中国工程院、美国工程院双院院士丛京生教授在2020年北京召开的亚太地区设计自动化会议(ASP-DAC)上发表了关于可定制计算的演讲,指出可定制计算现在已经在各类公有、私有云上大面积铺开,并已经做出了像Merlin编译器, HeteroCL, HeteroHalide等一系列的重大进展。「新智元急聘主笔、编辑、运营经理、客户经理,添加HR微信(Dr-wly)了解详情。」


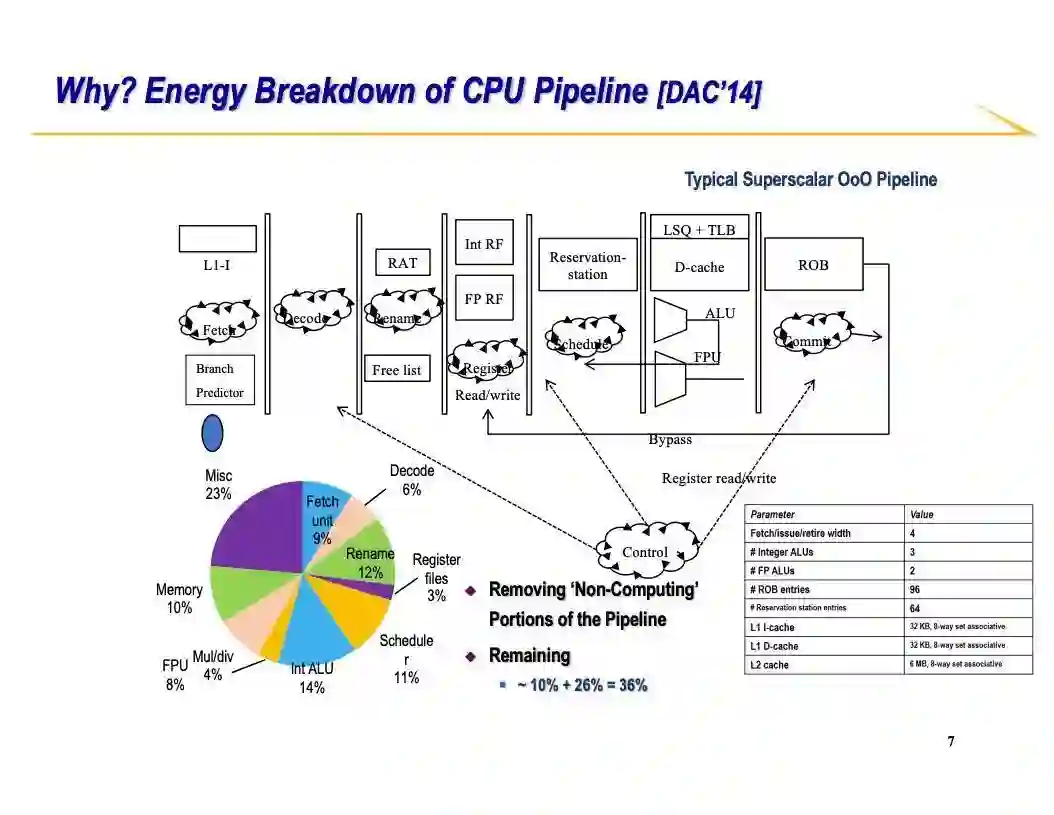
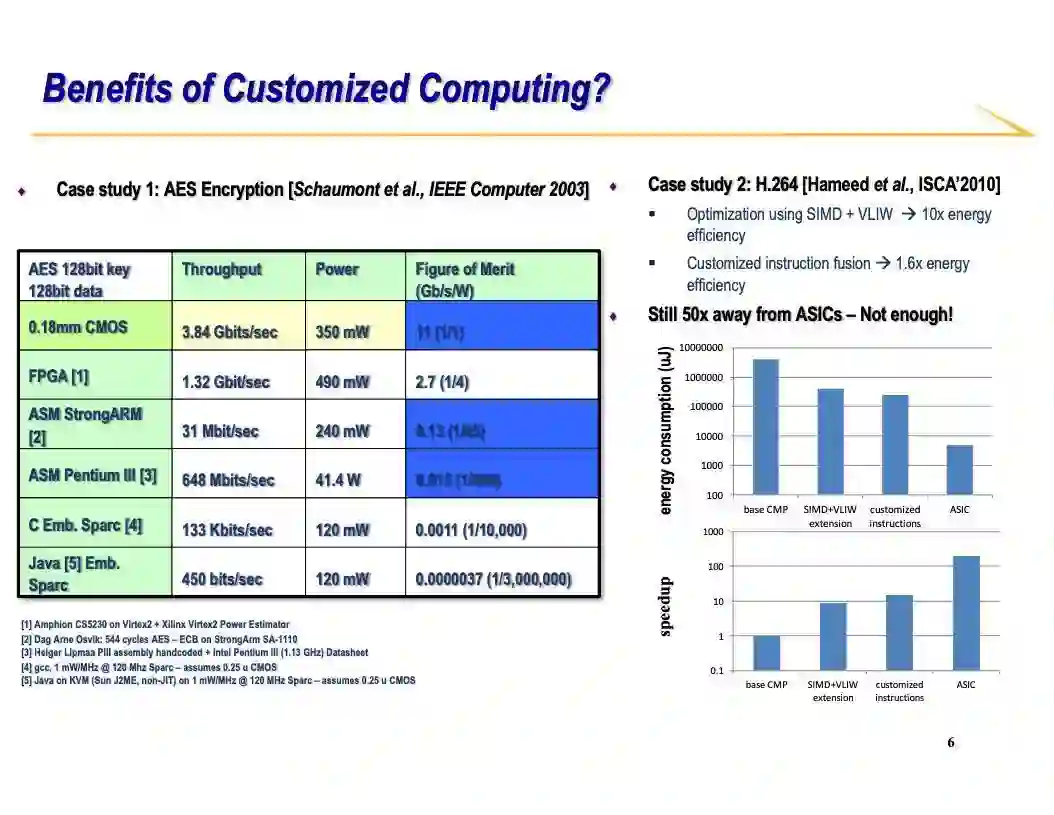 有些同学可能会比较好奇说:等一会,我在计算机原理课上学过CPU的架构。为什么CPU的性能这么差,差到甚至成百上千倍?实际上原因通过下图看来非常简单明了。你们可以想一想CPU是怎么进行加法操作的。第一件事是从缓存或者内存里拿到这个指令放进处理器流水线。这个过程就已经有9%的能量消耗了。接着指令需要被解码从而CPU才知道这条指令到底要做什么事情,这里又有6%的能耗。因为现代处理器可以支持乱序执行,这样指令很有可能要被重命名来解决一些冲突的问题,这又导致12%的能耗。接下来从寄存器堆拿数据又产生3%。现在万事俱备就等着做加法了,等待数据会有11%的能耗。最终实际的计算部分只占了14%能耗,而剩下的杂事又产生23%能耗。在以上CPU的一系列操作中实际上只有做加法这一步是你关心的。然而,为了得到正确的加法结果一条加法指令需要走一个非常复杂的计算流水线。这就是为什么CPU不高效的原因。
有些同学可能会比较好奇说:等一会,我在计算机原理课上学过CPU的架构。为什么CPU的性能这么差,差到甚至成百上千倍?实际上原因通过下图看来非常简单明了。你们可以想一想CPU是怎么进行加法操作的。第一件事是从缓存或者内存里拿到这个指令放进处理器流水线。这个过程就已经有9%的能量消耗了。接着指令需要被解码从而CPU才知道这条指令到底要做什么事情,这里又有6%的能耗。因为现代处理器可以支持乱序执行,这样指令很有可能要被重命名来解决一些冲突的问题,这又导致12%的能耗。接下来从寄存器堆拿数据又产生3%。现在万事俱备就等着做加法了,等待数据会有11%的能耗。最终实际的计算部分只占了14%能耗,而剩下的杂事又产生23%能耗。在以上CPU的一系列操作中实际上只有做加法这一步是你关心的。然而,为了得到正确的加法结果一条加法指令需要走一个非常复杂的计算流水线。这就是为什么CPU不高效的原因。

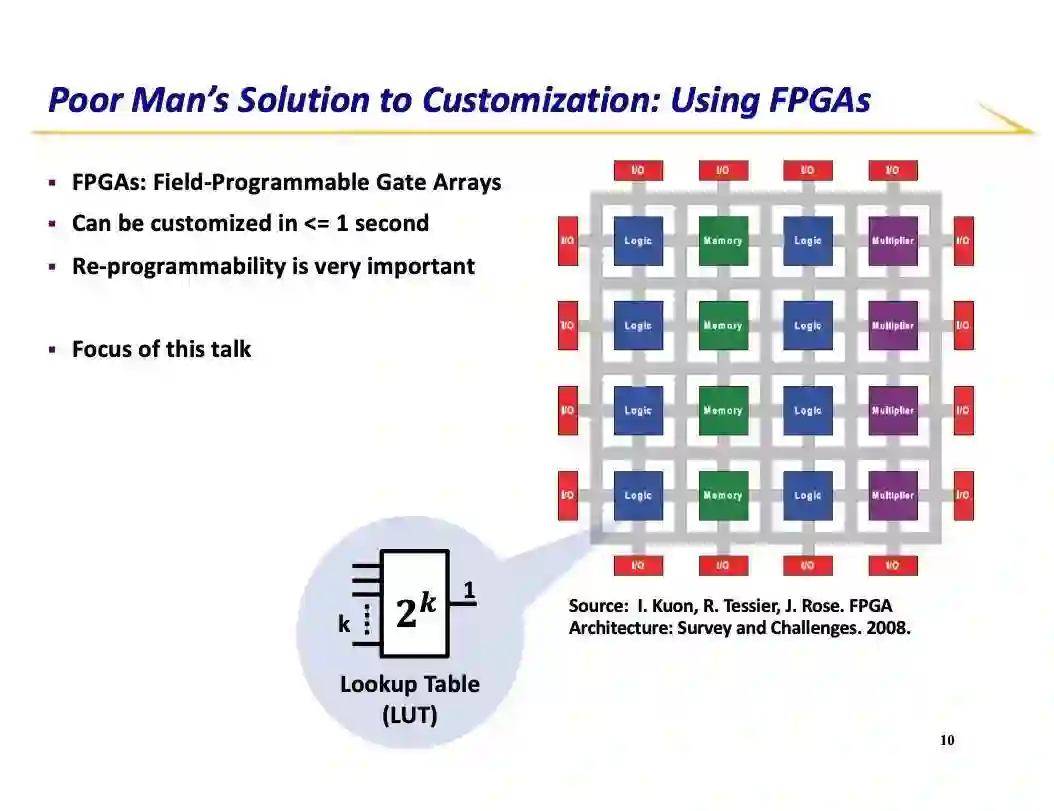

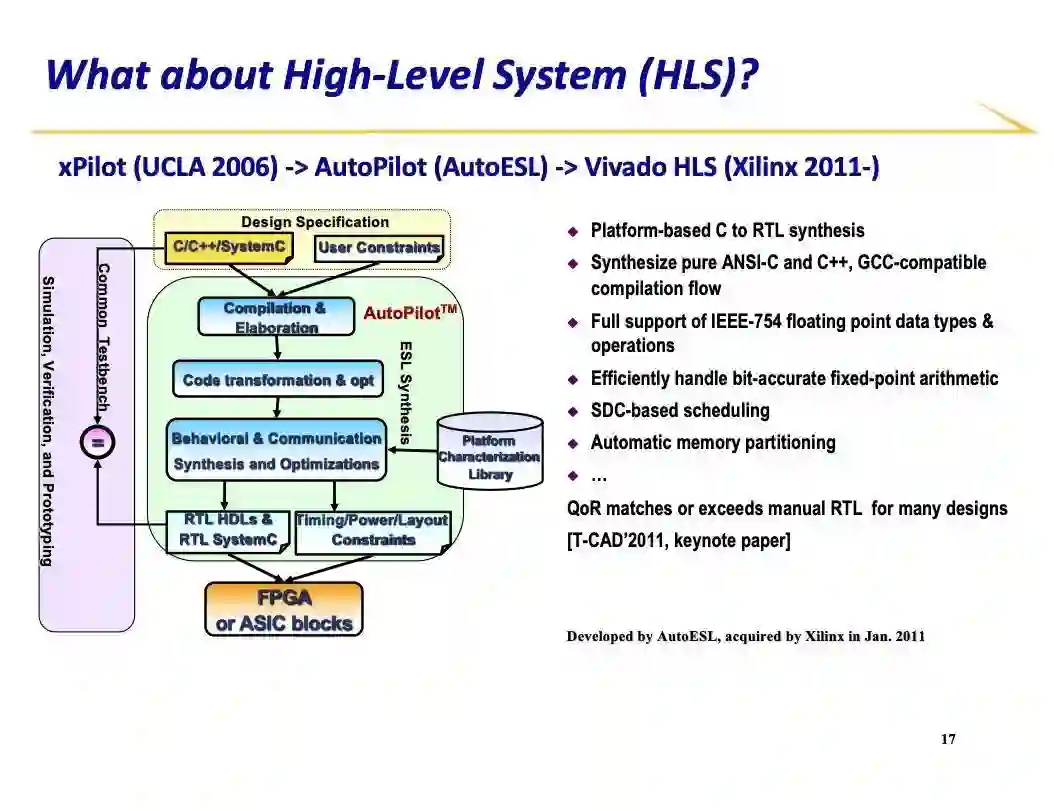



登录查看更多
相关内容

ASP-DAC:Asia and South Pacific Design Automation Conference。
Explanation:亚洲及南太平洋设计自动化会议。
Publisher:ACM/IEEE。
SIT: http://dblp.uni-trier.de/db/conf/aspdac
Arxiv
4+阅读 · 2019年4月15日


相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2019年4月15日