GAN能生成3D图像啦!朱俊彦团队公布最新研究成果
晓查 发自 凹非寺
量子位 出品 | 公众号 QbitAI
GAN现在可以合成3D图像了!
最近,MIT计算机科学与AI实验室的朱俊彦团队,发表了一篇论文《Visual Object Networks: Image Generation with Disentangled 3D Representation》,描述了一种用GAN生成3D图片的方法。
这篇文章被近期在蒙特利尔举办的NeurIPS 2018大会收录。

文中所描述的方法的强大之处在于:它不仅生成的图像逼真,甚至还可以改变物体的形状、材质和视角。这是以往生成2D图像的方法无法做到的。
图片效果碾压对手
研究人员把这种技术称为可视化物体网络(VON)。用它生成的汽车是这样的:

而用另一种称为WGAN-GP的方法生成的汽车则是这样的:

VON生成的图片上还有汽车纹理和表面反光,二者的差距已经非常明显。但这仅仅是主观感受,如何量化表示生成图像与真实图像的差距呢?
为了评估图像生成模型,研究人员计算了生成图像和真实图像之间的Fréchet初始距离(FID),这是一种与人类感知高度相关的标度。
每组图像都被送到由ImageNet训练的初始网络中,并且使用来自最后一个完全连接层之前的层的特征(features)来计算FID。
最终结果显示,VON始终优于2D生成模型,具有最小的FID值。
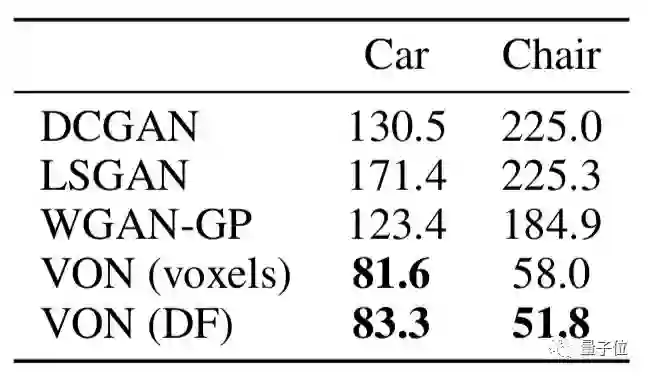
其次,研究人员还从VON和其他模型(DCGAN、LSGAN和WGAN-GP)中采集200组生成图像,并将每组图片放在Amazon MTurk的5个主题上显示。要求测试者在每组中选择更真实的结果。
其中,74%~85%的测试者回答偏好VON生成结果。
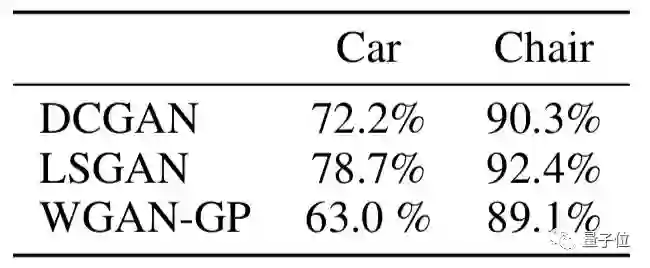
△在和其他三种方法对比时,测试者更偏好VON的比例
【在和其他三种方法对比时,测试者更偏好VON的比例】
作者表示,相比对手在性能表现上的增长,表明模型在学习3D经验后,有助于合成更逼真的图像。
举一反三的GAN
VON不仅能生成3D图片,甚至还能修改图形,想怎么变就怎么变。
它能在3个独立维度上拆分3D物体的元素。给出一个3D图片,只要改变物体的视角、形状、材质这些参数,就能获得你想要的图形。

对相同类型、相同视角的物体,如果给出两种不同形状、材质的图片,它还能从中“线性插入”图片,有下图中渐变的效果:

给合成的3D图形输入一张真实图片,它甚至还能根据这个物体的材质“推理”出类似图片,实现“基于样品的材质转换”。

数据集和网络模型
研究人员使用ShapeNet来训练模型学习3D形状,ShapeNet是一个拥有55种物体形状的大型数据集。论文中只使用了椅子和汽车2个分类,分别包含6777和3513个CAD模型。
至于2D图形数据集,研究人员使用了Pix3D,并从谷歌搜索中爬取了图片。
研究人员使用的网络模型主要分成以下3个部分:

1)形状网络。对于形状生成,采用3D-GAN的架构。
2)材质网络。对于纹理生成,使用ResNet编码器,并将纹理代码连接到编码器中的中间层。
3)可区分的投影模块。假设相机与物体中心的固定距离为2米,焦距为50毫米(等效35毫米胶片)。渲染草图的分辨率为128×128,沿着每个摄像机光线均匀地采样128个点。并假设没有面内旋转,即图像在水平面中没有倾斜。
资源
论文地址:
http://papers.nips.cc/paper/7297-visual-object-networks-image-generation-with-disentangled-3d-representations.pdf
完整的数据集和测试结果将放在MIT网站上:
http://von.csail.mit.edu
代码将公布在GitHub上:
https://github.com/junyanz/VON
— 完 —
年度评选申请

加入社群
量子位AI社群开始招募啦,欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“交流群”,获取入群方式;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进专业群请在量子位公众号(QbitAI)对话界面回复关键字“专业群”,获取入群方式。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态





