【机器学习吃掉算法】谷歌用ML模型替代数据库组件,或彻底改变数据系统开发

新智元报道
来源:arXiv
作者:费欣欣
【新智元导读】本周,谷歌团队在arXiv上传了一篇论文,探讨用机器学习取代数据库索引,引发了大量的关注和讨论。作者还概述了如何使用这一思想来替换数据库系统的其他组件和操作,包括排序和连接。如果成功,数据系统的开发方式将会彻底改变。

“如果这项研究取得更多的成果,将来有一天我们很可能回过头看然后说,索引是最先倒下的,接着是其他的数据库组件(排序算法、查询优化、连接),它们都逐渐被神经网络取代。”纽约州立大学布法罗分校的计算机科学和工程教授Murat Demirbas这样说。
文章描述了一个非常有前景且十分有趣的方向,题目读来也颇有小说的感觉——“The Case for Learned Index Structures”。
这篇论文旨在证明“机器学习模型有潜力大幅超越当前最先进的数据库索引,提供好很多的性能”。
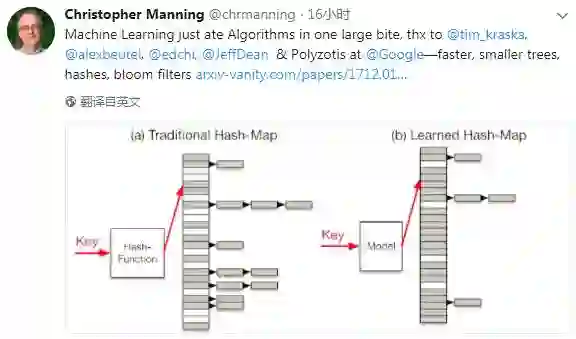
斯坦福大学Chirs Manning教授发表Twitter,评论称谷歌团队这篇论文用机器学习替代传统算法,而且“一口吃掉一大块”
索引(Index),就是一种对数据库表中一列或多列的值进行排序的结构,使用索引可以快速访问数据库表中的特定信息。数据库的索引好比图书的目录,目录能让你在看书时不把整本书看完就快速找到需要的信息,索引也能让数据库程序迅速地找到表中的数据,而不必将整个数据库扫描完。
但是,数据库在应用索引时,对数据本身并不了解,数据相当于一个黑盒,而不了解数据的分布,造成了很大的浪费。
举例来说,如果键的范围在0到500m之间,比起用哈希,直接把键当索引速度可能更快。如果知道了数据的累积分布函数(CDF),“CDF*键*记录大小”可能约等于要查找的记录的位置,这一点也适用于其他数据分布的情况。
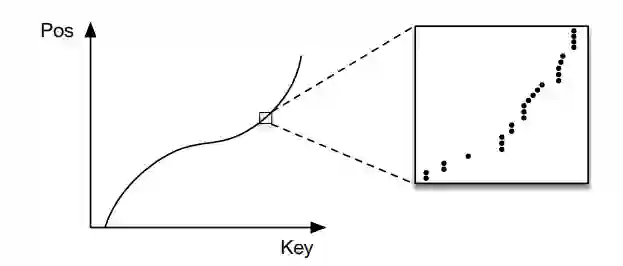
数据的累积分布函数(CDF)可以作为索引
作者在论文中表示,精确了解数据分布,可以大幅优化当前数据库系统使用的几乎所有索引结构。
但是,精确了解数据分布,数据库就成了“白盒”,失去了可重用性。这样一来就需要检查数据,每次都从头开始设计索引。
于是,谷歌研究人员想到了机器学习方法,并使用其中最强的一种——神经网络,去学习数据分布,并用学到的知识预测数据的分布。
这样一种折中的方法,让数据索引变得“data-aware”,由此获得性能的提升。
他们将神经网络应用于三种索引类型:B树,用于处理范围查询;哈希映射(Hash-map),用于点查找查询;以及Bloom-filter,用于设置包含检查。下面着重介绍一下作者如何用神经网络替代B树。
B树提供了一种有效的分层索引。从概念上讲,B-tree将一个键映射到一个页面。因此,我们可以用一个模型,也进行键的位置映射,而对于错误范围,我们可以做一个二进制搜索(或扩展环搜索)的变体来定位页面。
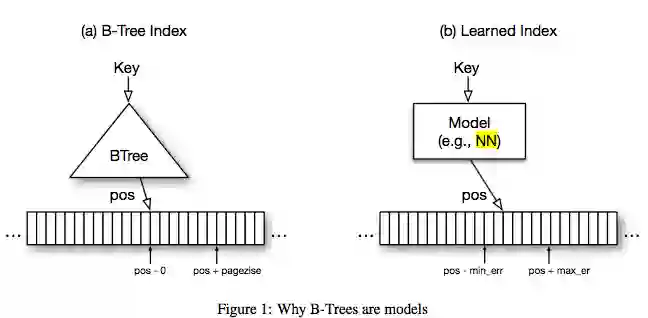
要知道min_error和max-error,就用拥有的数据来训练模型。数据是静态的,神经网络进行预测,然后从这些错误中学习。即使简单的逻辑回归也可以用于简单的分布。
在测试时,作者将机器学习索引与B树进行比较,他们使用了3个真实世界数据集,其中网络日志数据集(Weblogs)对索引而言极具挑战性,包含了200多万个日志条目,是很多年的大学网站的请求,而且每个请求都有单一的时间戳,数据中含有非常复杂的时间模式,包括课程安排、周末、假期、午餐休息、部门活动、学期休息,这些都是非常难以学习的。
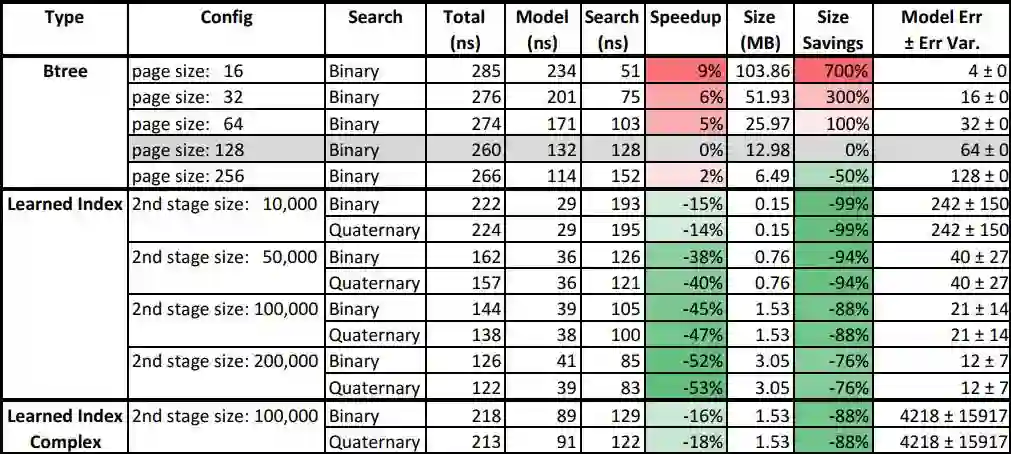
从上图可见,对于网络日志数据,机器学习索引带来的速度提升最高达到了53%,对应的体积也有76%的缩小,相比之下误差范围稍有加大。
用机器学习模型替换B树的好处是:
索引结构更小:更少的主内存或L1缓存
查找速度更快:因为索引变小了
更强的并行性(TPU),而不是B-树中的分层if语句
这里有一个关键点,那就是用计算换内存,计算越来越便宜,CPU-SIMD/GPU/TPU的功能越来越强大,作者甚至指出,“运行神经网络的高昂成本在未来可以忽略不计——谷歌TPU能够在一个周期内最高完成上万次神经网络运算。有人声称,到2025年CPU的性能将提高1000倍,基于摩尔定律的CPU在本质上将不复存在。利用神经网络取代分支重索引结构,数据库可以从这些硬件的发展趋势中受益。”
论文还介绍了几个策略来提高机器学习索引的性能,包括使用递归模型索引、分层模型和混合模型。机器学习方法都带来了能效提升,具体的评估结果请参考论文。
需要指出,作者并不认为机器学习索引结构可以完全替代传统索引。“我们论述了一种建立索引的新方法,它完善了现有的研究,并且为该领域数十年的研究开辟了一个新方向。”
作者还概述了如何使用这一思想来替换数据库系统的其他组件和操作,包括排序和连接。如果成功,数据系统的开发方式将会彻底改变。

索引就是模型:B-Tree-Index可以被看作一个将键(key)映射到排序数组中记录位置的模型,哈希索引可以被看作将键映射到未分类数组中记录位置的模型,而BitMap-Index可以被看作查看数据记录是否存在的模型。
在这篇探索性研究论文中,我们从这个前提出发,假设所有现有的索引结构都可以用其他类型的模型来代替,包括深度学习模型,也即文中所谓的“机器学习索引”(learned indexes)。
本文关键思想是,一个模型可以学习排序顺序或查找键的结构,并使用这个信号来有效预测记录的位置或记录是否存在。我们从理论上分析了在哪些条件下机器学习索引的性能优于传统索引结构,描述了设计机器学习索引的主要挑战。
我们在几个真实世界的数据集上做了测试,初步结果表明,通过使用神经网络,我们在速度上能比缓存优化的B树快70%,同时内存节省了一个数量级。更重要的是,我们相信用机器学习模型取代数据管理系统核心组件的想法,对未来的系统设计有着深远的影响,这项工作仅仅展现了未来无限可能的一瞥。
论文地址:https://arxiv.org/pdf/1712.01208v1.pdf



