让图片动起来,特朗普和蒙娜丽莎深情合唱《Unravel》

来源:Jack Cui




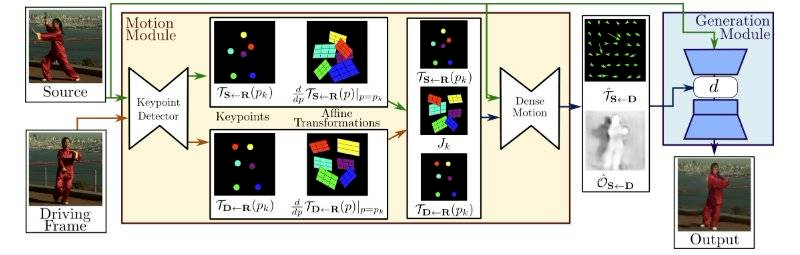

python -m pip install -r requirements.txt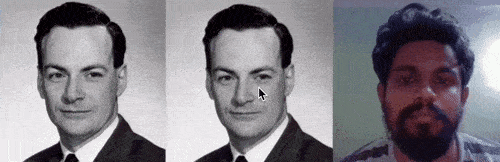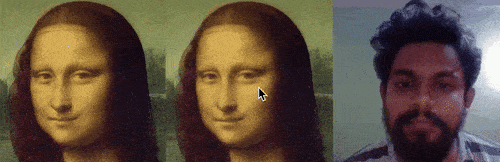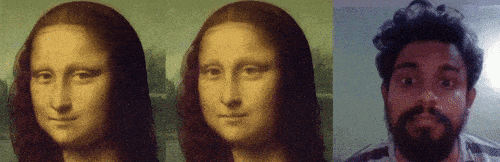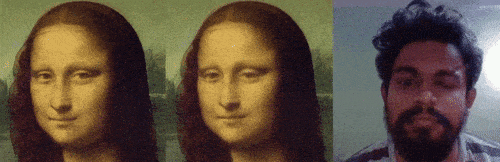
import subprocessimport osfrom PIL import Imagedef video2mp3(file_name):"""将视频转为音频:param file_name: 传入视频文件的路径:return:"""outfile_name = file_name.split('.')[0] + '.mp3'cmd = 'ffmpeg -i ' + file_name + ' -f mp3 ' + outfile_namesubprocess.call(cmd, shell=True)def video_add_mp3(file_name, mp3_file):"""视频添加音频:param file_name: 传入视频文件的路径:param mp3_file: 传入音频文件的路径:return:"""outfile_name = file_name.split('.')[0] + '-f.mp4'subprocess.call('ffmpeg -i ' + file_name+ ' -i ' + mp3_file + ' -strict -2 -f mp4 '+ outfile_name, shell=True)
import imageioimport torchfrom tqdm import tqdmfrom animate import normalize_kpfrom demo import load_checkpointsimport numpy as npimport matplotlib.pyplot as pltimport matplotlib.animation as animationfrom skimage import img_as_ubytefrom skimage.transform import resizeimport cv2import osimport argparseimport subprocessimport osfrom PIL import Imagedef video2mp3(file_name):"""将视频转为音频:param file_name: 传入视频文件的路径:return:"""outfile_name = file_name.split('.')[0] + '.mp3'cmd = 'ffmpeg -i ' + file_name + ' -f mp3 ' + outfile_nameprint(cmd)subprocess.call(cmd, shell=True)def video_add_mp3(file_name, mp3_file):"""视频添加音频:param file_name: 传入视频文件的路径:param mp3_file: 传入音频文件的路径:return:"""outfile_name = file_name.split('.')[0] + '-f.mp4'subprocess.call('ffmpeg -i ' + file_name+ ' -i ' + mp3_file + ' -strict -2 -f mp4 '+ outfile_name, shell=True)ap = argparse.ArgumentParser()ap.add_argument("-i", "--input_image", required=True,help="Path to image to animate")ap.add_argument("-c", "--checkpoint", required=True,help="Path to checkpoint")ap.add_argument("-v","--input_video", required=False, help="Path to video input")args = vars(ap.parse_args())print("[INFO] loading source image and checkpoint...")source_path = args['input_image']checkpoint_path = args['checkpoint']if args['input_video']:video_path = args['input_video']else:video_path = Nonesource_image = imageio.imread(source_path)source_image = resize(source_image,(256,256))[..., :3]generator, kp_detector = load_checkpoints(config_path='config/vox-256.yaml', checkpoint_path=checkpoint_path)if not os.path.exists('output'):os.mkdir('output')relative=Trueadapt_movement_scale=Truecpu=Falseif video_path:cap = cv2.VideoCapture(video_path)print("[INFO] Loading video from the given path")else:cap = cv2.VideoCapture(0)print("[INFO] Initializing front camera...")fps = cap.get(cv2.CAP_PROP_FPS)size = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))video2mp3(file_name = video_path)fourcc = cv2.VideoWriter_fourcc('M','P','E','G')#out1 = cv2.VideoWriter('output/test.avi', fourcc, fps, (256*3 , 256), True)out1 = cv2.VideoWriter('output/test.mp4', fourcc, fps, size, True)cv2_source = cv2.cvtColor(source_image.astype('float32'),cv2.COLOR_BGR2RGB)with torch.no_grad() :predictions = []source = torch.tensor(source_image[np.newaxis].astype(np.float32)).permute(0, 3, 1, 2)if not cpu:source = source.cuda()kp_source = kp_detector(source)count = 0while(True):ret, frame = cap.read()frame = cv2.flip(frame,1)if ret == True:if not video_path:x = 143y = 87w = 322h = 322frame = frame[y:y+h,x:x+w]frame1 = resize(frame,(256,256))[..., :3]if count == 0:source_image1 = frame1source1 = torch.tensor(source_image1[np.newaxis].astype(np.float32)).permute(0, 3, 1, 2)kp_driving_initial = kp_detector(source1)frame_test = torch.tensor(frame1[np.newaxis].astype(np.float32)).permute(0, 3, 1, 2)driving_frame = frame_testif not cpu:driving_frame = driving_frame.cuda()kp_driving = kp_detector(driving_frame)kp_norm = normalize_kp(kp_source=kp_source,kp_driving=kp_driving,kp_driving_initial=kp_driving_initial,use_relative_movement=relative,use_relative_jacobian=relative,adapt_movement_scale=adapt_movement_scale)out = generator(source, kp_source=kp_source, kp_driving=kp_norm)predictions.append(np.transpose(out['prediction'].data.cpu().numpy(), [0, 2, 3, 1])[0])im = np.transpose(out['prediction'].data.cpu().numpy(), [0, 2, 3, 1])[0]im = cv2.cvtColor(im,cv2.COLOR_RGB2BGR)#joinedFrame = np.concatenate((cv2_source,im,frame1),axis=1)#joinedFrame = np.concatenate((cv2_source,im,frame1),axis=1)#cv2.imshow('Test',joinedFrame)#out1.write(img_as_ubyte(joinedFrame))out1.write(img_as_ubyte(im))count += 1# if cv2.waitKey(20) & 0xFF == ord('q'):# breakelse:breakcap.release()out1.release()cv2.destroyAllWindows()video_add_mp3(file_name='output/test.mp4', mp3_file=video_path.split('.')[0] + '.mp3')
python image_animation.py -i path_to_input_file -c path_to_checkpoint -v path_to_video_filepython image_animation.py -i Inputs/trump2.png -c checkpoints/vox-cpk.pth.tar -v 1.mp4


登录查看更多
相关内容

专知会员服务
13+阅读 · 2020年3月12日
Arxiv
8+阅读 · 2018年3月29日



相关VIP内容
专知会员服务
13+阅读 · 2020年3月12日
相关资讯