fast.ai发布针对编程者的深度学习教程
编者按:今年年初,fast.ai的创始人、数据科学家Jeremy Howard推出了2018版的“针对编程者的深度学习课程”——Practical Deep Learning For Coders, Part 1。这场免费的课程可以教大家如何搭建最前沿的模型、了解深度学习的基础知识。昨天,fast.ai发布了课程的第二部分“Cutting Edge Deep Learning for Coders”。以下是论智对课程的大致介绍。
5月7日,fast.ai发布了2018版的Cutting Edge Deep Learning for Coders的第二部分,这是fast.ai免费深度学习课程中的一部分。如同本课程的第一部分一样,参与者只需要有高中数学基础和一年的编程经验即可,其余的部分我们会交给你。这一课程包括了许多新元素,比如NLP分类领域最新的成果(20%都比现有的方法更好),并且教你如何复制最近ImageNet和CIFAR10的最佳性能。其中主要用到的库是PyTorch和fastai。
每节课程配有两小时左右的视频,以及交互式Jupyter Notebook和fast.ai论坛上详细的讨论。课程涵盖了许多话题,包括用SSD和YOLOv3进行多目标检测、如何阅读学术论文、如何定制一个预训练模型、进行复杂的数据增强(左边变量、像素分类等等)、NLP迁移学习、用新的fast.ai文本库处理大型语料库、进行并研究对比试验、目前NLP分类的先进成果、多模型学习、多任务学习、双向LSTM带有seq2seq的注意力、神经翻译、定制ResNet架构、GANs、WGAN和CycleGAN、数据分类、超分辨率、用u-net进行图像分割。

Lesson 8
第8课是本课程第一部分的回顾,并介绍了第二部分的重点:先进研究。在这里,我们介绍了如何阅读论文,以及在搭建自己的深度学习架构时都要什么。即使你之前从未读过一篇学术论文,我们也会从头开始教你,避免你被各种符号或写作风格迷惑。另外,在这节课中,我们将会深入了解fastai和PyTorch库中的源代码:我们会教你如何快速浏览并搭建易懂的代码。另外我们还会展示如何运用Python的调试器帮助你了解目前的情况以及修复bug。
本课的主要话题是目标检测,即让模型在每个目标对象周围画上边界框,并正确标注。你可能会很惊讶,我们竟可以用从来没被训练过的、从ImageNet分类器上的迁移学习来做图像检测!其中有两个主要任务:对目标物体定位,同时给它们分类。我们要用一个模型同时完成这两个任务。这种多任务学习总体上比给每个人物都设计不同的模型效率更高。为了利用与训练模型创建自定义网络,我们将使用fastai的灵活定制的head architecture。
Lesson 9
在这节课中,我们关注的重点从单一物体转向了多个物体检测。结果表明这种改变让问题的难度增加。事实上,大多学生觉得这是整个课程中最具挑战性的部分。并不是因为某一部分非常复杂,而是因为组成部分实在太多了。所以这个任务真的很考验你对各种基础概念的理解。不过不要担心,你可以时不时地回看之前的课程,逐渐就会对整个任务有所把握。
我们的关注重点是Single Shot Multibox Detector(SSD),同时还附带相应的YOLOv3检测器。这些都是处理多目标检测任务的方法,通过结合多物体的损失,使用损失函数。他们同样还使用定制化的网络,利用CNN中不同图层的不同接受域。我们同样要讨论,如何在独立变量也需要增强的情况下进行数据增强。最后,我们讨论一个简单但强大的技巧,称作焦点损失,用于得到该领域的最新成果。
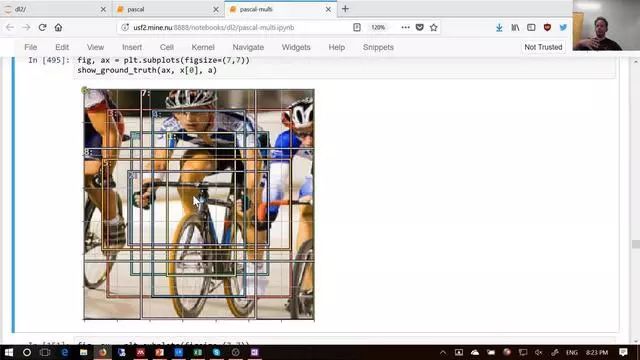
anchor box示例,这是多目标检测的关键
Lesson 10
大致回顾下关于目标检测之所学,在第10课我们会转向NLP,从介绍新的fast.ai文本库开始。fast.ai文本库是torchtext的替代品,在很多情况下,它比后者更快且更灵活。这节课可能与第一部分的第4课有些重合,但是本节课会教你如何用NLP中的迁移学习产生更加精确的结果。
迁移学习在计算机视觉领域做出了许多革命性的成果,但是直到现在却没有在NLP领域有重要的应用(在某种程度上可以说是被忽略了)。在这节课上,我们会展示如何预训练一个全语言的模型,能超越此前基于简单词向量的方法。我们将把这一语言模型看作是文本分类的最新成果。

如何完成并理解对比试验
Lesson 11
本节课上,我们会学习将法语翻译成英语!为了达到这一目标,我们将学习如何在LSTM中添加注意力,以创建一个seq2seq的模型。但是在做之前,我们需要了解RNN的一些基础知识,因为了解这些对课程的其他部分非常重要。
seq2seq模型的输入和输出都是序列,并且长度不同。翻译是seq2seq的一个典型任务。因为每个翻译过来的词语可以对应源句子中一个或多个不同位置的词语,我们利用一个注意力机制来确定每个步骤应该关注哪些词语。我们同样学习其他的技巧来改进seq2seq的结果,包括teacher forcing和双向模型。
课程结尾,我们讨论了DeVISE论文,其中展示了如何用同样的模型将文本和图像连接起来。
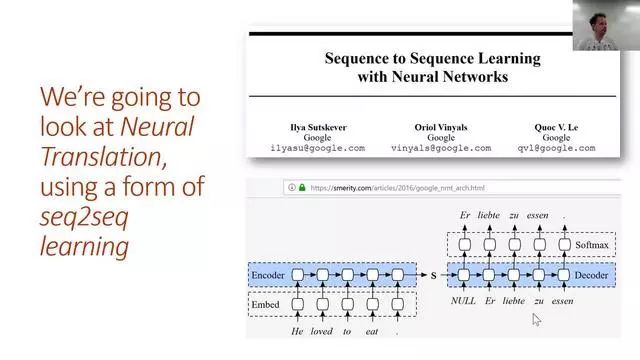
简单的seq2seq模型
Lesson 12
在本节课一开始,我们就用YOLOv3探究DarkNet的架构,它还可以帮助我们更好地理解搭建ResNet架构时的各种细节和选择。在这里我们讨论的基本方法是赢得过DAWNBench竞赛的方法。
然后我们会学习生成对抗网络(GANs)。事实上这是另一种形式的损失函数。GANs有一个生成网络和判别网络,生成模型的目的就是生成现实度极高的输出。我们会重点讨论Wasserstein GAN,因为这个更好训练,同时对大量超参数的稳定性更好。

CycleGAN模型
Lesson 13
这节课我们会讲到CycleGAN,它是GANs领域的突破性思想,可以凭空生成并无训练过的图像。我们可以用它将马变成斑马。也许目前你不需要这种应用,但是它的基本思想可以转移到很多有价值的应用中。我们其中一位学生正用它创作新形式的视觉艺术。
但是生成模型也会对社会造成伤害。所以我们也要花些时间讨论数据的规范。这个话题需要在整个课程中被关注,但是由于时间关系不能列出所有细节,希望我们能讲出其中重要的问题。
在课程结尾,我们会研究风格迁移问题,这个技术能将图像改变成自己喜欢的风格。这种方法需要我们优化像素(而不是权重),所以是优化问题的一个有趣方面。

偏差是目前数据规范中一个重要问题
Lesson 14
在最后一节课中,我们会深入研究超分辨率,这种神奇的技术能让我们基于卷积神经网络,将图片的分辨率恢复得非常高。在这一过程中,我们正研究一些能更快、更可靠的训练卷积网络的方法。
最后,我们要讲的是图像分割,尤其是利用U-net架构,这种技术赢得了多次Kaggle竞赛,并在行业内广泛使用。图像分割模型能让我们精准分辨图像的每个位置,精确至像素级别。
课程地址:http://course.fast.ai/part2.html
第一部分课程地址:http://course.fast.ai/index.html







