10万元奖金“智源工业检测赛”激战正酣!高分Baseline合辑带你入门智能制造

百年德企博世放出真实独家生产场景脱敏数据,邀你为工业 4.0 制造练就 AI 大脑。
比赛地址:

Baseline 概览
Baseline 详情
pinlan 版
根据题意,作者将题目定义为二分类问题;
-
先建立 valid_4 模型,再建立 valid_11 模型,建模流程相同。
样本越多,效果越好;
官方验证集未包含全部子家族以及产品类型,在提取训练集时是否删去官方验证集未包含的子家族;
对于 validation_predict_4 而言,提取训练数据应包含产品实例前三步检测数据,这里进行了数据筛选,剔除了前三部已经检测出问题的产品。
针对产品实例 Product_ID 构造统计特征:最值,均值;
对类别特征进行编码;
构思一些具有背景意义的特征;
工业数据一般暗含很多规则,一些 EDA 可以帮助发现规则,有助于分数提升。
正负样本极不平衡;
主要在于不平衡样本的处理,如使用采样,is_unbalance 参数;
模型方面小数据集分类问题 Catboost 可能更具有优势。
F1 需要设置阈值,阈值对结果影响很大,概率、排序或者搜索算法等都可以;
F1 不单考虑某一类样本的准确性,需要正负样本预测准确性都高。
训练样本构造以及筛选方式,十分重要;
-
特征工程。
2. 数据提取与探索性分析
import numpy as np
import pandas as pd
import gc
import os
import math
import lightgbm as lgb
from sklearn.metrics import f1_score,accuracy_score,roc_auc_score
from sklearn.model_selection import StratifiedKFold,KFold,train_test_split
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
color = sns.color_palette()
sns.set_style("whitegrid")
import warnings
warnings.filterwarnings('ignore')
path='./INSPEC_train/'
test_path='./INSPEC_validation/'
filename=os.listdir('./INSPEC_train/')
data_cols = ['Product_ID', 'TYPE_NUMBER', 'PRODUCTGROUP_NAME', 'ID_F_PHASE','PHASE_RESULT_STATE', 'PHASE_NAME', 'ID_F_PHASE_S',
'RESULT_STRING','RESULT_VALUE', 'PARAMETER_RESULT_STATE', 'LOWER_LIMIT', 'UPPER_LIMIT','AXIS', 'SIDE', 'ID_F_PARAMETER_S']2.1 数据提取
def get_data(path, data_cols, file_dir, num):
process = pd.read_excel(path+file_dir, sheet_name='Process_Table')
phase = pd.read_excel(path+file_dir, sheet_name='Phase_Table')
parameters = pd.read_excel(path+file_dir, sheet_name='Parameters_Table')
del parameters['ID_F_PHASE_S'];gc.collect()
df = process.merge(phase, on = 'ID_F_PROCESS', how = 'left')
df = df.merge(parameters, on = 'ID_F_PHASE', how = 'left')
df.rename(columns={'ID_F_PROCESS':'Product_ID','PROCESS_RESULT_STATE':'label'}, inplace=True)
df = df[data_cols+['label']]
bad_id = df[(df['ID_F_PHASE_S'] < num)&(df['PHASE_RESULT_STATE'] == 2)]['Product_ID'].unique()
df = df[~df['Product_ID'].isin(bad_id)]
df = df[df['ID_F_PHASE_S'] < num].reset_index(drop=True)
del process, phase, parameters;gc.collect()
return df
def get_train4(path, data_cols, filename):try:
train_4 = pd.read_csv('train_4.csv')
except:
train_4 = pd.DataFrame()
for dir_file in tqdm(filename):
temp_df = get_data(path, data_cols, dir_file, 3)
train_4 = train_4.append(temp_df)
train_4 = train_4.reset_index(drop=True)
train_4.to_csv('train_4.csv', index=False)
return train_4
3)其他描述性类别特征。
train_4 = get_train4(path, data_cols, filename)
train_4.head()
train_4.describe()
plt.rcParams['font.sans-serif']=['SimHei']
train_4.drop_duplicates(subset=['Product_ID'])['label'].value_counts().plot.pie(autopct='%1.1f%%',title = '正负样本比例')
<matplotlib.axes._subplots.AxesSubplot at 0x2375cb20f98>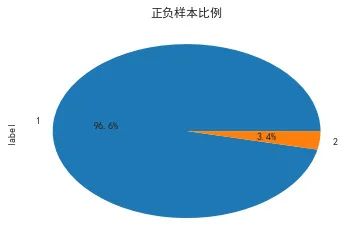
train_4.nunique().plot.bar(title='类别个数')
<matplotlib.axes._subplots.AxesSubplot at 0x2375cbbfb70>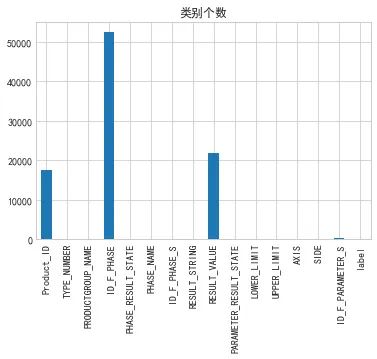
(train_4.isnull().sum()/len(train_4)).plot.bar(title='缺失值比例')
<matplotlib.axes._subplots.AxesSubplot at 0x2375cc6b9b0>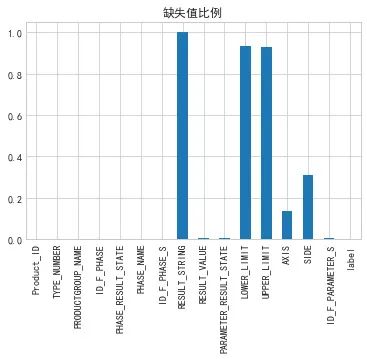
train_4.groupby('label')['ID_F_PARAMETER_S'].agg(['min', 'max', 'median','mean', 'std']) 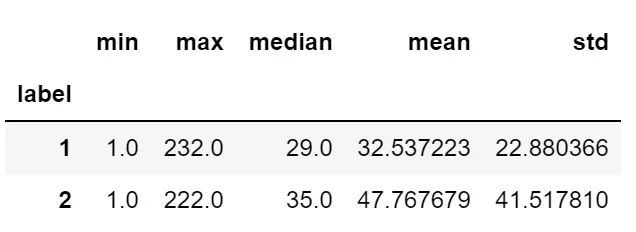
train_4.groupby(['label'])['RESULT_VALUE'].describe()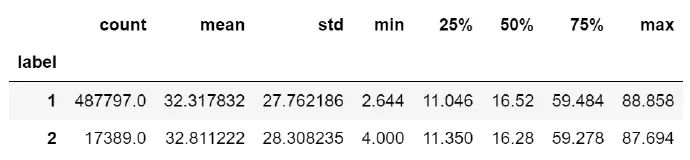
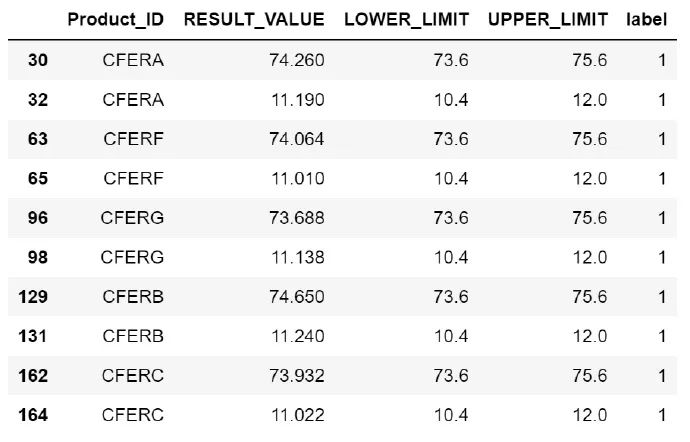
temp = train_4[['Product_ID','RESULT_VALUE', 'LOWER_LIMIT', 'UPPER_LIMIT','label']].dropna()
temp.head(10)
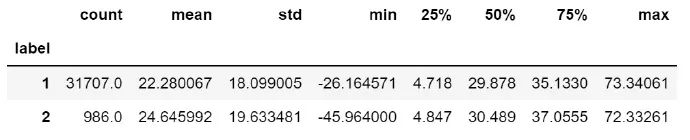
temp['差值'] = temp['RESULT_VALUE'] - temp['LOWER_LIMIT'] / (temp['UPPER_LIMIT'] - temp['LOWER_LIMIT'])
temp.groupby('label')['差值'].describe()
代码分析
import numpy as np
import pandas as pd
import gc
import os
import math
import lightgbm as lgb
from sklearn.metrics import f1_score,accuracy_score,roc_auc_score
from sklearn.model_selection import StratifiedKFold,KFold,train_test_split
path='./INSPEC_train/'
test_path='./INSPEC_validation/'
filename=os.listdir('./INSPEC_train/')
data_cols = ['Product_ID', 'TYPE_NUMBER', 'PRODUCTGROUP_NAME', 'ID_F_PHASE','PHASE_RESULT_STATE', 'PHASE_NAME', 'ID_F_PHASE_S',
'RESULT_STRING','RESULT_VALUE', 'PARAMETER_RESULT_STATE', 'LOWER_LIMIT', 'UPPER_LIMIT','AXIS', 'SIDE', 'ID_F_PARAMETER_S']
valid4 建模
#提取训练数据def get_data(path, data_cols, file_dir, num):
process = pd.read_excel(path+file_dir, sheet_name='Process_Table')
phase = pd.read_excel(path+file_dir, sheet_name='Phase_Table')
parameters = pd.read_excel(path+file_dir, sheet_name='Parameters_Table')
del parameters['ID_F_PHASE_S'];gc.collect()
df = process.merge(phase, on = 'ID_F_PROCESS', how = 'left')
df = df.merge(parameters, on = 'ID_F_PHASE', how = 'left')
df.rename(columns={'ID_F_PROCESS':'Product_ID','PROCESS_RESULT_STATE':'label'}, inplace=True)
df = df[data_cols+['label']]
bad_id = df[(df['ID_F_PHASE_S'] < num)&(df['PHASE_RESULT_STATE'] == 2)]['Product_ID'].unique()
df = df[~df['Product_ID'].isin(bad_id)]
df = df[df['ID_F_PHASE_S'] < num].reset_index(drop=True)
del process, phase, parameters;gc.collect()
return df
#合并数据def get_train4(path, data_cols, filename):try:
train_4 = pd.read_csv('train_4.csv')
except:
train_4 = pd.DataFrame()
for dir_file in tqdm(filename):
temp_df = get_data(path, data_cols, dir_file, 3)
train_4 = train_4.append(temp_df)
train_4 = train_4.reset_index(drop=True)
train_4.to_csv('train_4.csv', index=False)
return train_4
#构造统计特征def make_feature(data,aggs,name,data_id):
agg_df = data.groupby(data_id).agg(aggs)
agg_df.columns = agg_df.columns = ['_'.join(col).strip()+name for col in agg_df.columns.values]
agg_df.reset_index(drop=False, inplace=True)
return agg_df
#产品实例统计特征def get_4_fe(data,cate_cols):
dd_cols = ['PHASE_RESULT_STATE', 'RESULT_STRING','PARAMETER_RESULT_STATE']
data.drop(columns=dd_cols, inplace=True)
data['ID_F_PHASE_S'] = data['ID_F_PHASE_S'].astype('int8')
df = data[['Product_ID', 'label'] + cate_cols].drop_duplicates()
aggs = {}
for i in ['RESULT_VALUE']:
aggs[i] = ['min', 'max', 'mean', 'std', 'median']
for i in ['PHASE_NAME', 'AXIS']:
aggs[i] = ['nunique']
aggs['ID_F_PARAMETER_S'] = ['max', 'std', 'mean', 'median', 'count']
temp = make_feature(data, aggs, "_product", 'Product_ID')
df = df.merge(temp, on = 'Product_ID', how='left')
return df
#根据数值检测结果上下限构造统计def get_limit_4(data,df):
temp = data[['Product_ID','RESULT_VALUE', 'LOWER_LIMIT', 'UPPER_LIMIT']].dropna()
temp['差值'] = temp['RESULT_VALUE'] - temp['LOWER_LIMIT'] / (temp['UPPER_LIMIT'] - temp['LOWER_LIMIT'])
aggs = {}
aggs['差值'] = ['min', 'max', 'mean']
temp_df = make_feature(temp, aggs, "_limit", 'Product_ID')
df = df.merge(temp_df, on = 'Product_ID', how='left')
return df
#目标编码def get_target_mean_4(df, cate_cols):for i in cate_cols:
df[f'{i}_label_mean'] = df.groupby(i)['label'].transform('mean')
return df
#建模数据def get_training_data(df, name):
train_4 = df[~df['label'].isnull()].reset_index(drop=True)
test_4 = df[df['label'].isnull()].reset_index(drop=True)
col = [i for i in train_4.columns if i notin ['Product_ID', 'label']]
X_train = train_4[col]
y_train = (train_4['label']-1).astype(int)
X_test = test_4[col]
sub = test_4[['Product_ID']].copy()
print('{} train shape {} and test shape {}'.format(name, X_train.shape, X_test.shape))
return X_train, y_train, X_test, sub
1. 提取数据
train_4 = get_train4(path, data_cols, filename)
test_4 = pd.read_csv(test_path + 'validation_predict_4.csv')
train_4 = train_4[train_4['PRODUCTGROUP_NAME'].isin(test_4['PRODUCTGROUP_NAME'].unique())]
data_4 = train_4.append(test_4).reset_index(drop=True)
data_4.loc[data_4['AXIS'] == -9.223372036854776e+18, 'AXIS'] = np.nan
print('val_4 train sample {} and test sample {}'.format(train_4['Product_ID'].nunique(), test_4['Product_ID'].nunique()))
val_4 train sample 16441 and test sample 3721
2. 特征工程
cate_cols = ['TYPE_NUMBER', 'PRODUCTGROUP_NAME']
df4 = get_4_fe(data_4,cate_cols)
df4 = get_limit_4(data_4,df4)
df4 = get_target_mean_4(df4,cate_cols)
df4['TYPE_NUMBER'] = df4['TYPE_NUMBER'].astype('category')
df4['PRODUCTGROUP_NAME'] = df4['PRODUCTGROUP_NAME'].astype('category')
#构建标签
X_train, y_train, X_test, sub1 = get_training_data(df4, 'val_4')
val_4 train shape (16441, 19) and test shape (3721, 19)
3. 模型训练
lgb 自定义评测 f1 评测:
def lgb_f1_score(y_hat, data):
y_true = data.get_label()
y_hat = np.round(y_hat)
return'f1', f1_score(y_true, y_hat), True五折划分数据,lgb 参数设置:
K = 5
seed = 2020
skf = StratifiedKFold(n_splits=K, shuffle=True, random_state=seed)
lgb_params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'None',
'num_leaves': 63,
'subsample': 0.8,
'colsample_bytree': 0.8,
'learning_rate': 0.05,
'lambda_l2':2,
'nthread': -1,
'silent': True
}
f1_scores = []
oof = np.zeros(len(X_train))
predictions = np.zeros(len(X_test))
feature_importance_df = pd.DataFrame()
for i, (train_index, val_index) in enumerate(skf.split(X_train,y_train)):
print("fold{}".format(i))
X_tr, X_val = X_train.iloc[train_index], X_train.iloc[val_index]
y_tr, y_val = y_train.iloc[train_index], y_train.iloc[val_index]
lgb_train = lgb.Dataset(X_tr,y_tr)
lgb_val = lgb.Dataset(X_val,y_val)
num_round = 3000
clf = lgb.train(lgb_params, lgb_train, num_round, valid_sets = [lgb_train, lgb_val], feval=lgb_f1_score,
categorical_feature=['TYPE_NUMBER', 'PRODUCTGROUP_NAME'],
verbose_eval=100, early_stopping_rounds = 100)
oof[val_index] = clf.predict(X_val, num_iteration=clf.best_iteration)
pred = clf.predict(X_val, num_iteration=clf.best_iteration)
sc = f1_score(y_val, np.round(pred))
f1_scores.append(sc)
print(f'fold{i} f1 score = ',sc)
print('best iteration = ',clf.best_iteration)
fold_importance_df = pd.DataFrame()
fold_importance_df["Feature"] = clf.feature_name()
fold_importance_df["importance"] = clf.feature_importance()
fold_importance_df["fold"] = i + 1
feature_importance_df = pd.concat([feature_importance_df, fold_importance_df], axis=0)
predictions += clf.predict(X_test, num_iteration=clf.best_iteration) / skf.n_splits
print('val_4 训练f1均值: {},波动: {}.'.format(np.mean(f1_scores), np.std(f1_scores)))
print('val_4 macro F1 score: ',f1_score(y_train, np.round(oof),average='macro'))
4. 特征重要性
plt.figure(figsize=(12,8))
sns.barplot(y='Feature', x='importance',data=feature_importance_df)
plt.title('val_4特征重要性')
Text (0.5,1,'val_4特征重要性')
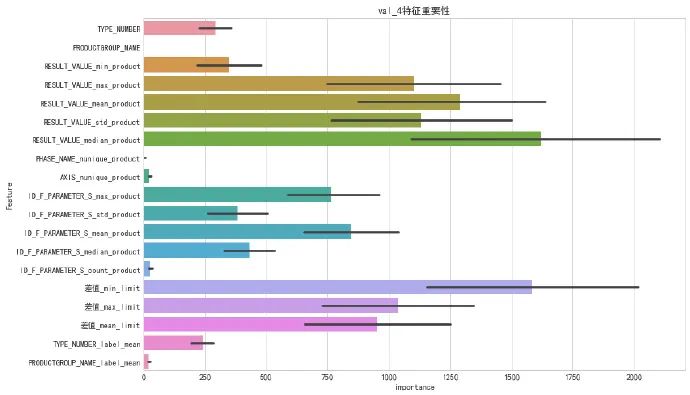
5. 生成 val4 结果
sub1['label'] = predictions
sub1['label'] = sub1['label'].rank()
sub1['label'] = (sub1['label']>=sub1.shape[0] * 0.93).astype(int)
sub1['label'] = (sub1['label'] + 1).astype(int)
sub1.rename(columns={'Product_ID':'id'}, inplace=True)
print('val_4正负样本比例:\n', sub1['label'].value_counts())
val_4 正负样本比例:
1 3460
2 261
Name: label, dtype: int64
这里结合数据和结果发现规则:结果中发现一个产品实例只有三条检测记录的正常样本居多,直接全部赋值 1,大概有百分位提升,但更换数据集后效果未知。
rule = test_4['Product_ID'].value_counts()
rule = rule[rule==3].index.values
sub1.loc[sub1['id'].isin(rule), 'label'] = 1
print('val_4正负样本比例:\n', sub1['label'].value_counts())
val_4 正负样本比例:
1 3609
2 112
Name: label, dtype: int64
valid11 建模
#合并数据def get_train11(path, data_cols, filename):try:
train_11 = pd.read_csv('train_11.csv')
except:
train_11 = pd.DataFrame()
for dir_file in tqdm(filename):
temp_df = get_data(path, data_cols, dir_file, 10)
train_11 = train_11.append(temp_df)
train_11 = train_11.reset_index(drop=True)
train_11.to_csv('train_11.csv', index=False)
return train_11
#产品实例统计特征def get_11_fe(data_11, cate_cols):
dd_cols = ['PHASE_RESULT_STATE', 'PARAMETER_RESULT_STATE']
data_11.drop(columns=dd_cols, inplace=True)
data_11['ID_F_PHASE_S'] = data_11['ID_F_PHASE_S'].astype('int8')
df = data_11[['Product_ID', 'label'] + cate_cols].drop_duplicates()
aggs = {}
for i in ['RESULT_VALUE']:
aggs[i] = ['min', 'max', 'mean', 'std', 'median']
for i in ['PHASE_NAME', 'AXIS', 'SIDE', 'RESULT_STRING']:
aggs[i] = ['nunique']
aggs['ID_F_PARAMETER_S'] = ['max', 'std', 'mean', 'count']
temp = make_feature(data_11, aggs, "_product", 'Product_ID')
df = df.merge(temp, on = 'Product_ID', how='left')
return df
#根据数值检测检测上下限构造统计def get_limit_11(data,df):
temp = data[['Product_ID','RESULT_VALUE', 'LOWER_LIMIT', 'UPPER_LIMIT']].dropna()
temp['差值'] = temp['RESULT_VALUE'] - temp['LOWER_LIMIT'] / (temp['UPPER_LIMIT'] - temp['LOWER_LIMIT'])
aggs = {}
aggs['差值'] = ['min', 'max', 'mean']
temp_df = make_feature(temp, aggs, "_limit", 'Product_ID')
df = df.merge(temp_df, on = 'Product_ID', how='left')
return df
#类别特征def get_cate_11(data, df, cate_cols):
df['TYPE_NUMBER'] = df['TYPE_NUMBER'].astype('category')
df['PRODUCTGROUP_NAME'] = df['PRODUCTGROUP_NAME'].astype('category')
temp = pd.pivot_table(data=data, index='Product_ID',values='RESULT_VALUE',columns='SIDE',aggfunc='min').reset_index()
df = df.merge(temp, on = 'Product_ID', how='left')
temp = pd.pivot_table(data=data, index='Product_ID',values='RESULT_VALUE',columns='AXIS',aggfunc='min').reset_index()
df = df.merge(temp, on = 'Product_ID', how='left')
temp = pd.pivot_table(data=data, index='Product_ID',values='RESULT_VALUE',columns='RESULT_STRING',aggfunc='count').reset_index()
df = df.merge(temp, on = 'Product_ID', how='left')
for i in cate_cols:
df[f'{i}_label_mean'] = df.groupby(i)['label'].transform('mean')
return df
1. 提取数据
train_11 = get_train11(path, data_cols, filename)
test_11 = pd.read_csv(test_path + 'validation_predict_11.csv')
train_11 = train_11[train_11['PRODUCTGROUP_NAME'].isin(test_11['PRODUCTGROUP_NAME'].unique())]
data_11 = train_11.append(test_11).reset_index(drop=True)
data_11.loc[data_11['AXIS'] == -9.223372036854776e+18, 'AXIS'] = np.nan
print('val_11 train sample {} and test sample {}'.format(train_11['Product_ID'].nunique(), test_11['Product_ID'].nunique()))
val_11 train sample 13051 and test sample 3784
2. 特征工程
cate_cols = ['TYPE_NUMBER', 'PRODUCTGROUP_NAME']
df11 = get_11_fe(data_11, cate_cols)
df11 = get_limit_11(data_11, df11)
df11 = get_cate_11(data_11, df11, cate_cols)
# 构建标签
X_train, y_train, X_test, sub2 = get_training_data(df11, 'val_11')
val_11 train shape (13051, 36) and test shape (3784, 36)
3. 模型训练
五折划分数据,lgb 参数设置:
K = 5
seed = 2020
skf = StratifiedKFold(n_splits=K, shuffle=True, random_state=seed)
lgb_params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'None',
'num_leaves': 32,
# 'is_unbalance': True,'subsample': 0.9,
'colsample_bytree': 0.9,
'learning_rate': 0.05,
'lambda_l2':1,
# 'min_data_in_leaf':10,'nthread': -1,
'silent': True
}
f1_score2 = []
oof = np.zeros(len(X_train))
predictions2 = np.zeros(len(X_test))
feature_importance_df = pd.DataFrame()
for i, (train_index, val_index) in enumerate(skf.split(X_train,y_train)):
print("fold_{}".format(i))
X_tr, X_val = X_train.iloc[train_index], X_train.iloc[val_index]
y_tr, y_val = y_train.iloc[train_index], y_train.iloc[val_index]
lgb_train = lgb.Dataset(X_tr,y_tr)
lgb_val = lgb.Dataset(X_val,y_val)
num_round = 3000
clf = lgb.train(lgb_params, lgb_train, num_round, valid_sets = [lgb_train, lgb_val], feval=lgb_f1_score,
categorical_feature=['TYPE_NUMBER', 'PRODUCTGROUP_NAME'],
verbose_eval=100, early_stopping_rounds = 100)
oof[val_index] = clf.predict(X_val, num_iteration=clf.best_iteration)
pred = clf.predict(X_val, num_iteration=clf.best_iteration)
sc = f1_score(y_val, np.round(pred))
f1_score2.append(sc)
print(f'fold{i} f1 score = ',sc)
print('best iteration = ',clf.best_iteration)
fold_importance_df = pd.DataFrame()
fold_importance_df["Feature"] = clf.feature_name()
fold_importance_df["importance"] = clf.feature_importance()
fold_importance_df["fold"] = i + 1
feature_importance_df = pd.concat([feature_importance_df, fold_importance_df], axis=0)
predictions2 += clf.predict(X_test, num_iteration=clf.best_iteration) / skf.n_splits
print('val_11训练f1均值:{},波动:{}.'.format(np.mean(f1_score2), np.std(f1_score2)))
print('val_11 macro F1 score: ',f1_score(y_train, np.round(oof),average='macro'))4. 特征重要性
plt.figure(figsize=(12,8))
sns.barplot(y='Feature', x='importance',data=feature_importance_df)
plt.title('val_11特征重要性')
Text (0.5,1,'val_11特征重要性')
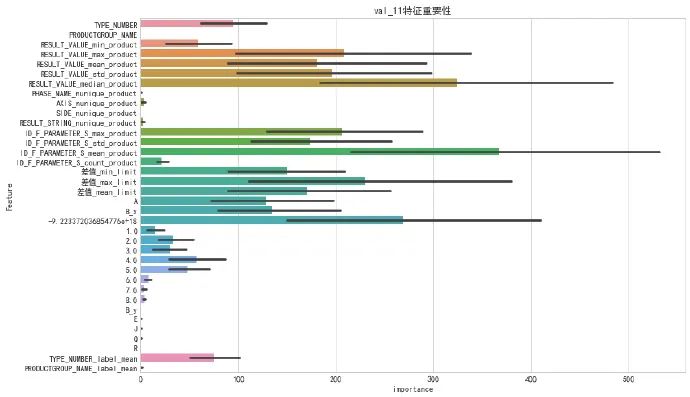
5. 生成 val_11 结果
sub2['label'] = predictions2
sub2['label'] = sub2['label'].rank()
sub2['label'] = (sub2['label']>=sub2.shape[0] * 0.97).astype(int)
sub2['label'] = (sub2['label'] + 1).astype(int)
sub2.rename(columns={'Product_ID':'id'}, inplace=True)
print('正负样本比例:\n', sub2['label'].value_counts())
正负样本比例:
1 3703
2 81
Name: label, dtype: int64
生成提交文件
sub = sub1.append(sub2)
print('正负样本比例:\n', sub['label'].value_counts())
sub.to_csv(f'sub_val4_{np.round(np.mean(f1_scores),3)}_val11_{np.round(np.mean(f1_score2),3)}.csv', index=False)
正负样本比例:
1 7312
2 193
Name: label, dtype: int64
sub.head()

由于文章篇幅限制,其他选手 Baseline 请扫码查看。

▲ bestIteration版

▲ sijinabc版

▲ hh_neuq版
参赛方式
点击阅读原文链接或扫描下图中的二维码直达赛事页面,注册网站-下载数据,即可参赛。

INSPEC 工业检测大数据
智源联合博世发布了 INSPEC 工业检测大数据,该数据集包括某系列产品近年来的质量检测相关数据,其中主要为每个产品质量检测环节各个步骤记录的相关参数,每个步骤都标注检测判定结果,整体数据量在 3w 条左右。相比于类似数据集,本比赛数据具有显著优势和特点。
首先,该数据集来自世界顶尖制造企业真实的工厂生产数据,已经过脱敏处理,尽量还原现实环境中产品检测的工序和流程。其次,INSPEC 工业检测大数据详细记录了检测环节生成的具体产品参数,涵盖产品子家族 ID、实例 ID、检测环节 ID、检测环节结果、检测规格和数值等。丰富的数据维度一方面增强了比赛的难度,另一方面有助于选手打造更加鲁棒的模型。
智源算法大赛
2019 年 9 月,智源人工智能算法大赛正式启动。本次比赛由北京智源人工智能研究院主办,清华大学、北京大学、中科院计算所、旷视、知乎、博世、爱数智慧、国家天文台、晶泰等协办,总奖金超过 100 万元,旨在以全球领先的科研数据集与算法竞赛为平台,选拔培育人工智能创新人才。
研究院副院长刘江也表示:“我们希望不拘一格来支持人工智能真正的标志性突破,即使是本科生,如果真的是好苗子,我们也一定支持。”而人工智能大赛就是发现有潜力的年轻学者的重要途径。
本次智源人工智能算法大赛有两个重要的目的,一是通过发布数据集和数据竞赛的方式,推动基础研究的进展。特别是可以让计算机领域的学者参与到其它学科的基础科学研究中。二是可以通过比赛筛选、锻炼相关领域的人才。智源算法大赛已发布全部的 10 个数据集,目前仍有 5 个比赛(奖金 50 万)尚未结束。
正在角逐的比赛
智源小分子化合物性质预测挑战赛
https://www.biendata.com/competition/molecule/
智源杯天文数据算法挑战赛
https://www.biendata.com/competition/astrodata2019/
智源-INSPEC 工业大数据质量预测赛
https://www.biendata.com/competition/bosch/
智源-MagicSpeechNet 家庭场景中文语音数据集挑战赛
https://www.biendata.com/competition/magicdata/
https://www.biendata.com/competition/jet/
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。




