Python网络爬虫与信息抽取笔记06 爬虫实战2
【导读】我们在上一节的内容中已经为大家对爬虫实践进行讨论,这一节将继续实践剩下的例子。本文内容讨论了实战爬虫的两个例子:网络图片的爬取和存储以及IP地址归属地的自动查询。话不多说,让我们一起学习这些内容吧。
Python网络爬虫与信息抽取笔记01 课程框架和Python IDE工具
Python网络爬虫与信息抽取笔记02 requests库入门
视频网址:
https://www.bilibili.com/video/av9784617?from=search&seid=240663710546169136
http://www.icourse163.org/course/BIT-1001870001?tid=1001962001
Python网络爬虫与信息抽取06 爬虫实战2
1.网络图片的爬取和存储
先讨论网络图片的爬取与存储

我们要先明白网络图片链接的格式是什么样子的

比如我们将爬取这个网址
http://image.nationalgeographic.com.cn/2017/0211/20170211061910157.jpg

先用指令爬取网址
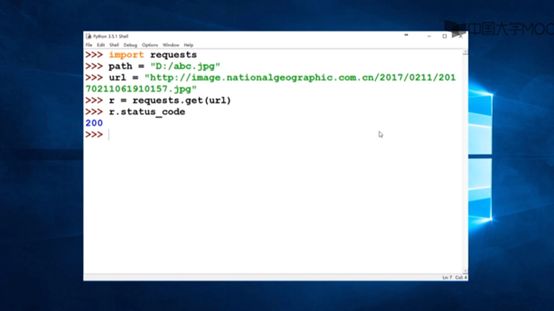
因为图片是二进制网址,所以使用r.content
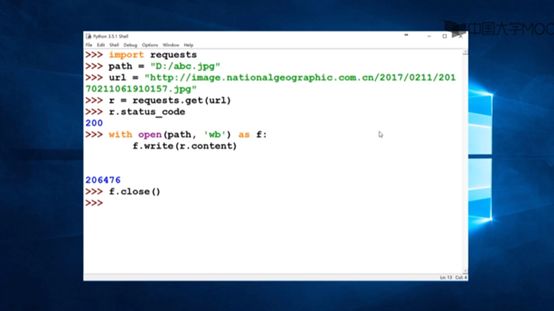
图片就会保存在D://abc.jpg中
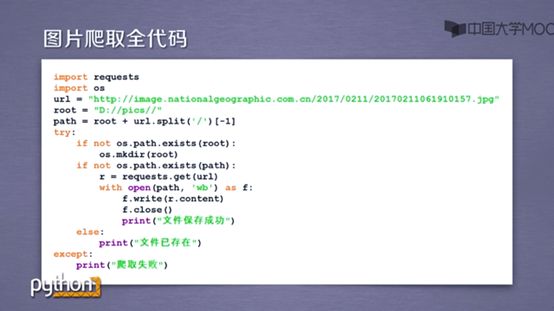
图片爬取的全代码如下
2.IP地址归属地的自动查询
接下来试一试IP地址归属地的自动查询

我们可以在www.ip138.com这个网址进行查询
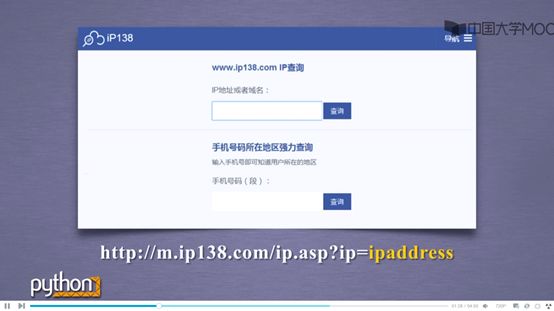
如果想用爬虫的形式爬取的话,就是如下网址
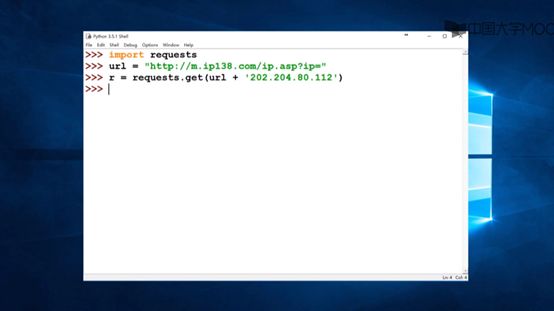
将网址填入爬虫指令
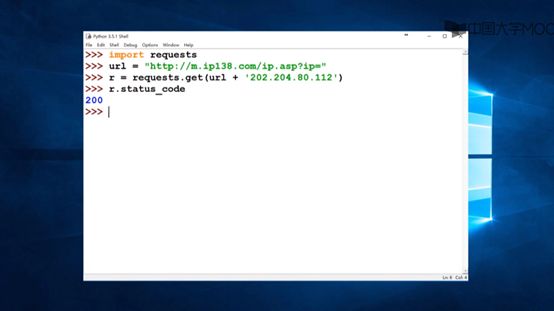
发现返回码为200,说明爬取成功
然后看服务器响应字符串的倒数500个字符
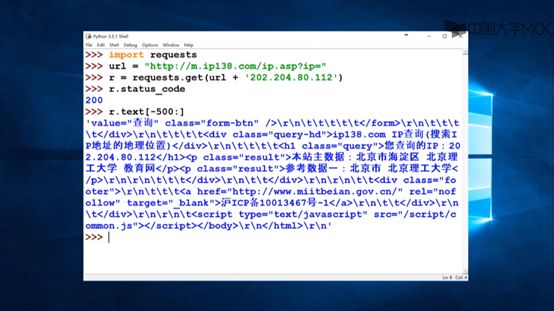
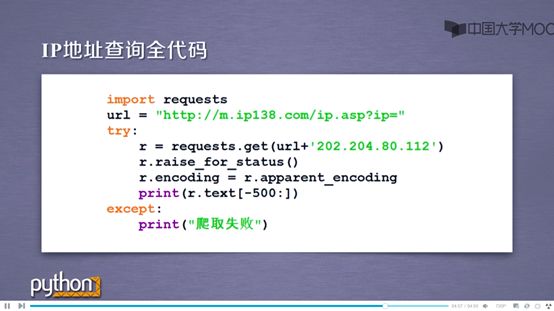
IP地址查询的全代码如下
目前我们已经会爬取网址进行简单的任务了,从下节开始我们介绍Beautiful Soup库
参考链接:
http://www.icourse163.org/course/BIT-1001870001?tid=1001962001
更多教程资料请访问:人工智能知识资料全集
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知