线下活动 × 深圳 | 大咖云集!第11届国际博士生论坛报名开启

国际博士生论坛(International Doctoral Forum)是由清华大学和香港中文大学于 2006 年联合发起的一项学术交流活动,至今已有 12 年的历史。2014 年起西北工业大学参与承办。论坛由清华大学、香港中文大学、西北工业大学轮流承办,旨在推进北京、香港、深圳、西安各高校相关领域的老师和学生的交流与合作。
论坛主题涵盖多媒体(Multimedia)、自然语言处理(Natural Language Processing)、互联网数据挖掘(Web Mining)、网络及大数据(Networking and Big Data)、人工智能(Artificial Intelligence)等多个领域,并邀请来自相关领域学术界、产业界的学者、专家亲临指导、作特邀报告等。论坛期间还会召开圆桌会议交流、学术思想秀等专题活动,促进与会的老师和同学们的交流和合作。
博士生论坛为同学们搭建了学习交流的平台,聘请清华大学、香港中文大学、西北工业大学相关专业领域的领导、老师担任指导委员会,由同学们亲自策划和组织,包括议题确定、论文投稿和审稿、大会报告邀请、论坛日程安排、优秀论文评审、本地组织等各个方面,有效锻炼了与会同学们各方面的能力。借助论坛搭建的平台,不少参加往届博士生论坛的同学业已成长为在相关领域有较大影响力的优秀青年学者。
论坛自 2006 年首次举办以来,今年已是第十一届。历届论坛的举办地分别为北京(2006 年、2008 年、2010 年、2015 年),香港(2007 年、2009 年、2016 年),深圳香港联合(2011 年),西安(2014 年、2017 年)。历届论坛获得了来自各高校老师和同学们的积极支持和参与,也取得了良好的效果。以论坛为契机,相关领域的老师和同学们深入交流和相互讨论学习,并达成了诸多合作,取得了较好的效果。论坛的影响力也在不断扩大,获得了来自中国大陆、香港、台湾、澳门、乃至海外诸多院校的支持与参与。
今年的国际博士生论坛于 12 月 6 日-7 日在深圳举行,由清华大学深圳研究生院具体承办,将举行为期 2 天的学术研讨和交流活动。论坛主题为:Multimedia、Intelligent Speech Interaction、Web Mining、Networking and Big Data。论坛首日包括开幕式(Opening Ceremony)、并安排 4 个特邀报告(Invited Talk)、科技园高科技企业参观(UBTech and Tencent Binhai Mansion);论坛第二天安排 3 个特邀报告(Invited talk)、1 个特殊议题专题报告(Special Session: Dialogue with AI Companies)、10 组口头分论坛报告(Oral Sessions)、晚宴及颁奖仪式(Banquet and Best Paper Award Ceremony)等。
论坛特邀报告讲者包括:佐治亚理工李锦辉教授,香港中文大学邢国良、周博磊教授,西北工业大学谢磊教授,清华大学刘知远、贾珈、袁春教授。特殊议题专题报告安排人工智能相关企业介绍最新的研究成果,并和大家进行交流,讲者包括好未来人工智能实验室(TAL AI Lab)杨嵩、深圳壹秘科技陈文明、深圳声希科技刘鹏飞。
参加论坛的学生总人数为 60-70 人,参加论坛的老师人数为 10 人左右。
欢迎大家报名参加论坛开幕式、特邀报告以及特殊议题环节。
论坛开幕式:12 月 6 日,9:00-9:45
第一组特邀报告:12 月 6 日,9:45-12:15(包括特邀报告 1-4)
第二组特邀报告:12 月 7 日,8:30-10:00(包括特邀报告 5-7)
Dialogue with AI Companies特殊议题报告:12 月 7 日,10:30-12:00(包括特殊议题报告 1-3)
时间 2018 年 12 月 6 日,9:45-10:45
地点 清华大学深圳研究生院,CII 一楼多功能厅

佐治亚理工李锦辉教授
Chin-Hui Lee is a professor at School of Electrical and Computer Engineering, Georgia Institute of Technology. Before joining academia in 2001, he had accumulated 20 years of industrial experience ending in Bell Laboratories, Murray Hill, as a Distinguished Member of Technical Staff and Director of the Dialogue Systems Research Department. Dr. Lee is a Fellow of the IEEE and a Fellow of ISCA. He has published over 500 papers and 30 patents, with more than 42,000 citations and an h-index of 80 on Google Scholar. He received numerous awards, including the Bell Labs President's Gold Award in 1998. He won the SPS's 2006 Technical Achievement Award for “Exceptional Contributions to the Field of Automatic Speech Recognition”. In 2012 he gave an ICASSP plenary talk on the future of automatic speech recognition. In the same year he was awarded the ISCA Medal in scientific achievement for “pioneering and seminal contributions to the principles and practice of automatic speech and speaker recognition”.
报告题目 Knowledge-rich Speech Processing: Beyond Current Deep Learning
Deep neural networks (DNNs) are becoming ubiquitous in designing speech processing algorithms. However, the robustness issues that have hindered a wide-spread deployment of speech technologies for decades still have not been fully resolved. In this talk, we first discuss capabilities and limitations of deep learning technologies. Next, we illustrate three knowledge-rich techniques, namely: (1) automatic speech attribute transcription (ASAT) integrating acoustic phonetic knowledge into speech processing and computer assisted pronunciation training (CAPT), (2) Bayesian DNNs leveraging upon speaker information for adaptation and system combination, and (3) DNN-based speech pre-processing, demonstrating better acoustics leads to more accurate speech recognition. Finally, we argue that domain knowledge in speech, language and acoustics is heavily needed beyond current blackbox deep learning in order to formulate sustainable whitebox solutions to further advance speech technologies.
时间 2018 年 12 月 6 日,10:45-11:15
地点 清华大学深圳研究生院,CII 一楼多功能厅

清华大学刘知远教授
Zhiyuan Liu is an associate professor at the Department of Computer Science and Technology, Tsinghua University. He received his Ph.D. degree in Computer Science from Tsinghua in 2011. His research interests include representation learning, knowledge graphs and social computation, and has published more than 60 papers in top-tier conferences and journals of AI and NLP including ACL, IJCAI and AAAI, cited by more than 3500 according to Google Scholar.
报告题目 Knowledge-Guided Natural Language Processing
Recent years have witnessed the advances of deep learning techniques in various areas of NLP. However, as a typical data-driven approach, deep learning suffers from the issue of poor interpretability. A potential solution is to incorporate large-scale symbol-based knowledge graphs into deep learning. In this talk, I will present recent works on knowledge-guided deep learning methods for NLP.
时间 2018 年 12 月 6 日,11:15-11:45
地点 清华大学深圳研究生院,CII 一楼多功能厅

香港中文大学邢国良教授
Guoliang Xing is currently a Professor in the Department of Information Engineering, the Chinese University of Hong Kong. Previously, he was a faculty member at Michigan State University, U.S. His research interests include Embedded AI, Edge/Fog Computing, Cyber-Physical Systems, Internet of Things (IoT), security, and wireless networking. He received the B.S. and M.S degrees from Xi’an Jiao Tong University, China, in 1998 and 2001, the D.Sc. degree from Washington University in St. Louis, in 2006. He is an NSF CAREER Award recipient in 2010. He received two Best Paper Awards and five Best Paper Nominations at several first-tier conferences including ICNP and IPSN. Several mobile health technologies developed in his lab won Best App Awards at the MobiCom conference and were successfully transferred to the industry. He received the Withrow Distinguished Faculty Award from Michigan State University in 2014. He serves as the General Chair for IPSN 2016 and TPC Co-Chair for IPSN 2017.
报告题目 Edge AI for Data-Intensive Internet of Things
Internet of Things (IoT) represent a broad class of systems which interact with the physical world by tightly integrating sensing, communication, and compute with physical objects. Many IoT applications are data-intensive and mission-critical in nature, which generate significant amount of data that must be processed within stringent time constraints. It’s estimated that 0.75 GB of data can be produced by an autonomous vehicle each second. The existing Cloud computing paradigm is inadequate for such applications due to significant or unpredictable delay and concerns on data privacy.
In this talk, I will present our recent work on Edge AI, which aims to address the challenges of data-intensive IoT by intelligently distributing compute, storage, control and networking along the continuum from Cloud to Things. First, I will present ORBIT, a system for programming Edge systems and partitioning compute tasks among network tiers to minimize the system power consumption while meeting application deadlines. ORBIT has been employed in several systems for seismic sensing, vision-based tracking, and multi-camera 3D reconstruction. Second, I will briefly describe several systems we developed for mobile health, smart cities, volcano and aquatic monitoring, which integrate domain-specific physical models with AI algorithms. We have conducted several large-scale field deployments for these systems, including installing a seismic sensor network at two live volcanoes in Ecuador and Chile.
时间 2018 年 12 月 6 日,11:45-12:15
地点 清华大学深圳研究生院,CII 一楼多功能厅

清华大学贾珈教授
Jia Jia is a tenured associate professor in Department of Computer Science and Technology, Tsinghua University. Her main research interest is affective computing and human computer speech interaction. She has been awarded ACM Multimedia Grand Challenge Prize (2012), Scientific Progress Prizes from the National Ministry of Education as the First Person-in-charge (2016), IJCAI Early Career Spotlight (2018), ACM Multimedia Best Demo Award (2018) and ACM SIGMM Emerging Leaders (2018). She has authored about 70 papers in leading conferences and journals including T-KDE, T-MM, T-MC, T-ASLP, T-AC, ACM Multimedia, AAAI, IJCAI, WWW etc. She also has wide research collaborations with Tencent, SOGOU, Huawei, Siemens, MSRA, Bosch, etc.
报告题目 Mental Health Computing via Harvesting Social Media Data
Psychological stress and depression are threatening people’s health. It is non-trivial to detect stress or depression timely for proactive care. With the popularity of social media, people are used to sharing their daily activities and interacting with friends on social media platforms, making it feasible to leverage online social media data for stress and depression detection. In this talk, we will systematically introduce our work on stress and depression detection employing large-scale benchmark datasets from real-world social media platforms, including 1) stress-related and depression-related textual, visual and social attributes from various aspects, 2) novel hybrid models for binary stress detection, stress event and subject detection, and cross-domain depression detection, and finally 3) several intriguing phenomena indicating the special online behaviors of stressed as well as depressed people. We would also like to demonstrate our developed mental health care applications at the end of this talk.
时间 2018 年 12 月 7 日,8:30-9:00
地点 清华大学深圳研究生院,CII 一楼多功能厅

西北工业大学谢磊教授
Lei Xie is currently a Professor in the School of Computer Science, Northwestern Polytechnical University, Xian, China. From 2001 to 2002, he was with the Department of Electronics and Information Processing, Vrije Universiteit Brussel (VUB), Brussels, Belgium, as a Visiting Scientist. From 2004 to 2006, he worked in the Center for Media Technology (RCMT), City University of Hong Kong. From 2006 to 2007, he worked in the Human-Computer Communications Laboratory (HCCL), The Chinese University of Hong Kong. His current research interests include audio, speech and language processing, multimedia and human-computer interaction. He is currently an associate editor of IEEE/ACM Trans. on Audio, Speech and Language Processing. He has published more than 140 papers in major journals and proceedings, such as IEEE TASLP, IEEE TMM, Signal Processing, Pattern Recognition, ACM Multimedia, ACL, INTERSPEECH and ICASSP.
报告题目 Meeting the New Challenges in Speech Processing: Some NPU-ASLP Approaches
Speech has become a popular human-machine interface due to fast development of deep learning, big data and super-computing. We can see many applications in smartphones, TVs, robots and smart speakers. However, for further wide deployments of speech interfaces, there are still many challenges we have to face, such as noise interferences, inter- and intra-speaker variations, speaking styles and low-resource scenarios. In this talk, I will introduce several approaches, recently developed in the Audio, Speech and Language Processing Group, Northwestern Polytechnical University (NPU-ASLP) team, to meet these challenges in speech recognition, speech enhancement and speech synthesis.
时间 2018 年 12 月 7 日,9:00-9:30
地点 清华大学深圳研究生院,CII 一楼多功能厅

香港中文大学周博磊教授
Bolei Zhou is an Assistant Professor with the Information Engineering Department at the Chinese University of Hong Kong. He received his PhD in computer science at Massachusetts Institute of Technology (MIT). His research is in computer vision and machine learning, focusing on visual scene understanding and interpretable deep learning. He received the Facebook Fellowship, Microsoft Research Fellowship, MIT Greater China Fellowship, and his research was featured in media outlets such as TechCrunch, Quartz, and MIT News.
报告题目 Deep Visual Scene Understanding
Deep learning has made great progress in computer vision, achieving human-level object recognition. However, visual scene understanding, which aims at interpreting objects and their spatial relations in complex scene context, remains challenging. In this talk I will first introduce the recent progress of deep learning for visual scene understanding. From the 10-million image dataset Places to the pixel-level annotated dataset ADE20K, I will show the power of data and its synergy with interpretable deep neural networks for better scene recognition and parsing. Then I will talk about the trend of visual recognition from supervised learning towards more active learning scenario. Applications including city-scale perception and spatial navigation will be discussed.
时间 2018 年 12 月 7 日,9:30-10:00
地点 清华大学深圳研究生院,CII 一楼多功能厅

清华大学袁春教授
Chun Yuan is currently an Associate Professor with the Division of Information Science and Technology at Graduate school at Shenzhen, Tsinghua University. He received his M.S. and Ph.D. degrees from the Department of Computer Science and Technology, Tsinghua University, Beijing, China, in 1999 and 2002, respectively. He once worked at the INRIA-Rocquencourt, Paris, France, as a Post-doc research fellow from 2003 to 2004. In 2002, he worked at Microsoft Research Asia, Beijing, China, as an intern. His research interests include computer vision, machine learning and multimedia technologies. He is now the executive vice director of “Tsinghua-CUHK Joint Research Center for Media Sciences, Technologies and Systems”.
报告题目 Event Level Video Captioning based on Attentional RNN
Video understanding is a hotspot and challenge subject featured by jointly knowledge of natural language processing (NLP) and computer vision. More and more commercial application of online multimedia content requires better automatic understanding of video events. Unlike image captioning, video captioning faces more obstacles. First, video is complex data form to get and utilize feature, comparing to image. The temporal change makes sufficient information and different methods have their own shortages in mining temporal information. Second, in the task of captioning, the generation of sentence is required to extract dynamic information from videos. While some methods deal well with short ant monotone actions, mining with longer and more complex actions is next goal. Third, some new tasks like captioning multiple events, call for new algorithm to get event-level processing. When generating sentences, correctly generate words like “continue” or “another” is one manifestation of good exploit context information.
时间 2018 年 12 月 7 日,10:30-11:00
地点 清华大学深圳研究生院,CII 一楼多功能厅

声希科技(SpeechX)CTO 刘鹏飞博士
Dr. Pengfei Liu received his B.E. and M.E. degrees from The East China Normal University and the Ph.D. degree from The Chinese University of Hong Kong. His research areas are natural language processing and deep learning, particularly on sentiment analysis and dialog systems. He developed the SEEMGO system which ranked 5th in the task of aspect-based sentiment analysis at SemEval-2014, and received the Technology Progress Award in JD Dialog Challenge in 2018. Dr. Liu previously worked at SAP Labs China in Shanghai, The Chinese University of Hong Kong, and Wisers AI lab in Hong Kong, where he led a team to conduct research on deep learning-based sentiment analysis. He is currently the CTO of SpeechX.
报告题目 Developing a Personalized Emotional Conversational Agent for Learning Spoken English
The spoken English skill is critical but challenging for non-native learners in China due to lack of enough practice, while improving spoken English is in large demand among learners of different ages. This talk presents our ongoing project at SpeechX on developing a personalized emotional conversational agent which aims to provide a virtual partner for language learners to practice their spoken English. Such an agent is personalized based on each learner’s English level and interests, and meanwhile gives appropriate responses according to the learner’s emotions. Developing the agent involves a lot of research challenges such as consistency and personalization in dialog systems, multimodal emotion recognition, expressive speech synthesis and so on. In this talk, we will briefly introduce our work responding to these challenges, present a preliminary proof-of-concept prototype and discuss future research perspectives.
时间 2018 年 12 月 7 日,11:00-11:30
地点 清华大学深圳研究生院,CII 一楼多功能厅

深圳壹秘科技(eMeet)CEO 陈文明
陈文明,深圳壹秘科技有限公司创始人,中欧国际工商学院 EMBA。在音视频、智能语音、智能家居、物联网领域工作 18 年;曾于 TCL 就职 10 余年,历任研发总经理、产品总经理、电声事业部总经理、创新事业部总经理;2016 年 8 月创立深圳壹秘科技有限公司。
报告题目 专业商务智能语音的应用及挑战
深圳壹秘科技有限公司成立于 2016 年,专注移动办公产品创新及智能服务。研发的人工智能会议服务系统,基于智能语音前端阵列算法技术、自然语言处理技术、网络通讯技术,服务于全球移动办公及智能会议市场。报告将以壹秘产品及服务的应用场景及市场潜力作为切入点,分享深圳壹秘科技有限公司争做智能语音单项技术应用冠军的心路历程,进而从前端语音处理的技术瓶颈、后端语言处理技术的挑战机遇两方面阐述专业商务智能语音的应用和挑战。
时间 2018 年 12 月 7 日,11:30-12:00
地点 清华大学深圳研究生院,CII 一楼多功能厅

好未来AILAB语音技术负责人杨嵩
杨嵩,历任思必驰高级语音工程师、苏州驰声研发主管、好未来 AILAB 语音技术负责人。研究方向为语音识别、语音评测。一直致力于中高考英语口语机器评分,在线教育课堂质量自动化评估等方面工作,在该领域拥有多项专利。2014 年获中国人工智能学会颁发的“吴文俊人工智能科学技术奖进步奖”。
报告题目 AI在教育领域落地的探索
好未来教育集团以“科技推动教育进步”作为自己的使命,深入发掘AI技术和教育场景的结合点。针对教学资源不均衡,优质师资不足的现状,大力发展各个场景的“AI 老师”;针对学生能力发展不平衡,推广个性化教学。此外为教育的各个环节引入不同的AI评测技术;在线下课堂教学中提供智慧教室的解决方案,让教室拥有眼睛(摄像头),耳朵(麦克风),大脑(云)及其他器官(答题器,iPad),引入音视频量化教学过程,评价课堂的教学质量;在线上课堂通过识别和分析课堂内容,评价师生间的交互状况,抽取相关特征对师生进行匹配,提高教学效率。好未来以 AI 技术为引擎,持续探索未来教育的新模式。
长按识别二维码,马上报名!
▼

深圳市南山区丽水路 2279 号,清华大学深圳研究生院 CII 一楼多功能厅(国际会议中心)
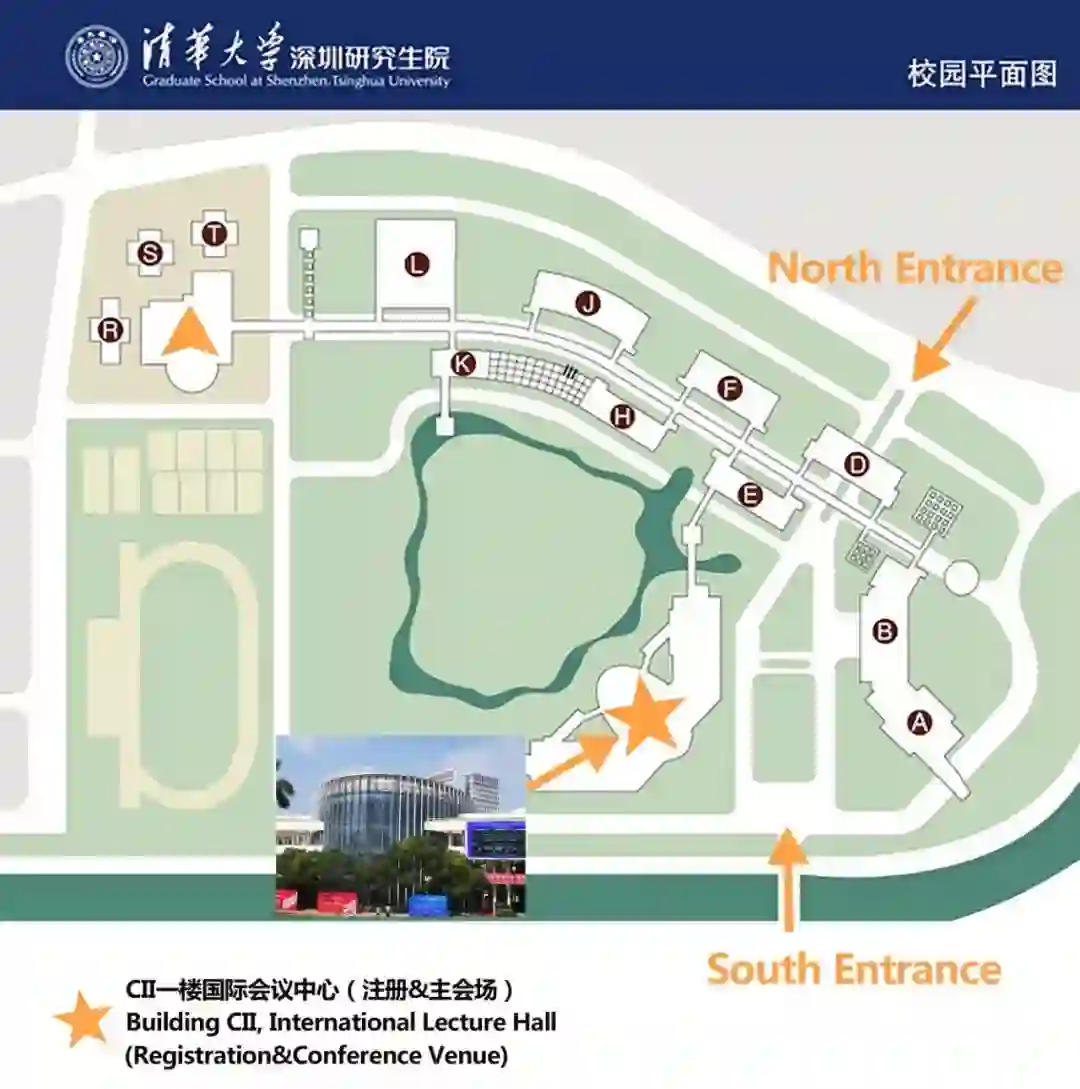




🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 立刻报名





