Uber开源JVM Profiler,用以跟踪分布式Java虚拟机

6 月下旬,Uber 开源了一个分布式性能分析器,名为 JVM Profiler。Uber 搭建这一工具的目的是解决他们在使用 Apache Spark 框架过程中的资源配置问题。Apache Spark 是一个非常流行的框架,主要用于处理大型数据流问题,这正是 Uber 所需要的。JVM Profiler 是为 Spark 而建的,但它也可以被应用于任何基于 JVM 的服务或应用。
Uber 的需求是在运行在数以千计的机器上的成千上万应用的海量进程中操作相关性矩阵。在 Uber 的分布式环境下,同一台服务器中会运行很多 Spark 应用,而每个应用都有数千个执行器。他们现有的工具只能监控服务器级别的矩阵,而无法对单一应用进行监控。他们需要一个解决方案,使得对每个进程都可以收集其相关性矩阵,并对每个应用进行跨进程的相关性分析。
JVM Profiler 有三个主要特性,可以简化对性能和资源使用状况矩阵的收集,然后将收集到的信息发布给其他系统(如 Apache Kafka)用以进一步分析。
Java Agent:可以以分布式的形式在 JVM 进程上收集矩阵。
高级性能分析能力:可跟踪任意方法和参数,而无需对代码进行任何修改。可以识别 Spark 应用中耗时较长的方法调用,并检测 HDFS 文件路径中的热文件。
数据分析报告:可以通过 Kafka topic 和 Apache Hive 更快地进行数据分析。
JVM Profiler 的设计很简单,但扩展性很强。用户可以自行添加其他的 profiler 实现,以收集更多的矩阵。这样,用户便可以添加自己的矩阵发布报告。
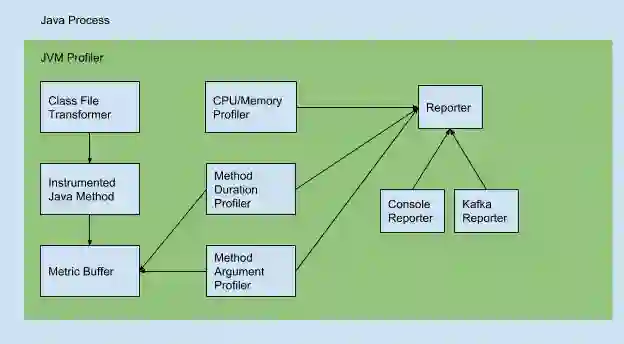
Uber 关于 JVM Profiler 的博客 中还包含了有关如何添加自定义报告器的内容,并介绍了如何使用此报告器来跟踪用户自己的应用。
Uber 在其最大的 Spark 应用之一上使用了 JVM Profiler,并发现这样可以在每个执行器上节约 2GB 的内存的分配——由原先的 7GB 降到了 5GB。仅在这个应用上,JVM Profiler 就可以为 Uber 节约 2TB 的内存。
JVM Profiler 的 GitHub 项目地址为:https://github.com/uber-common/jvm-profiler。欢迎大家下载学习!
公司业务的增长往往是带来技术挑战的第一步,大量的数据让人慢慢难以招架,很多公司选择搭建自己的大数据处理平台,或者向新的数据平台 / 框架迁移,无论在技术选型、搭建、系统迁移还是优化方面,都会遇到或多或少的困扰和问题,在这方面富有经验的技术团队是怎么克服的?
Pravega(Dell EMC 流平台与实时分析)、Apache Kafka、DStream3(百度新一代流式计算系统)等实践请点击「阅读原文」查收。
大会9 折报名中,立减 680 元。有任何问题欢迎咨询票务经理 Hanna,电话:010-84782011,微信:qcon-0410。





