手把手教你用 R 语言分析歌词

本文为雷锋字幕组编译的技术博客,原标题 Lyric Analysis with NLP & Machine Learning with R,作者为 Debbie Liske。
翻译 | 刘朋 Noddleslee 程思婕 余杭 整理 | 凡江
基于 R 语言对 Prince 的音乐的歌词研究:用文本挖掘和探索性数据分析(EDA)来了解这位艺术家的生涯。
这是由三部分组成的系列辅导教程的第一部分,在这个系列里,你将会使用 R 语言对传奇艺术家 Prince 的歌词通过各种分析任务进行实例研究。这三个教程覆盖以下内容。
第一部分:文本挖掘和探索性数据分析
第二部分:情感分析和自然语言处理的主题模型
第三部分:基于机器学习的预测分析
介绍
音乐的歌词经常会代表着一个艺术家的观点,但是流行歌曲揭示的是社会大众所想听到的东西。歌词分析不是一件容易的工作,因为它的结构通常和散文有着很大的区别,它需要谨慎的假设和特定的分析技巧选择。音乐的歌词渗透到我们的生活以及无所不在地细微地影响着我们的思想。预测性歌词的概念正在兴起,同时作为研究论文和毕业论文的主题变得越来越流行。这个案例分析会涉及这个新兴学科的几个部分而已。
Prince: 艺术家
为了庆祝 Prince 留下的令人激动的和多样化的作品,你将在他的歌词中探索偶尔清晰却时常隐晦的信息。然而,你不必喜欢 Prince 的音乐进而欣赏他对全球对许多流派发展的影响。《滚石》杂志将 Prince 列为一直以来的第 18 位最优秀的作曲家,仅次于鲍勃 · 迪伦 (Bob Dylan)、约翰 · 列侬 (John Lennon)、保罗 · 西蒙 (Paul Simon)、乔尼 · 米歇尔 (Joni Mitchell) 和史提夫 · 旺德 (Stevie Wonder) 等人。随着预测 “热门歌曲” 接近现实的可能性,歌词分析正在慢慢地进入数据科学界。
“Prince 是一个着魔于音乐的人 – 一个狂野的多产作曲家,也是吉他,键盘和鼓的演奏家,同时也是骤停打击乐,摇滚,R&B 和流行音乐的大师。虽然他的音乐和大众流派背道而驰。” – 乔治. 帕雷莱斯(纽约时报)
在本教程中,该系列的第一部分,你将会使用整洁文本框架在一组歌词上使用文本挖掘技术。整洁数据集有一种特定的结构,其中每个变量是一列,每个观察是一行,每个观察单元是一个表。在清理和调整数据集之后,在观察 Prince 歌词的不同方面的同时,你将会创建描述性的统计和探索性的可视化。
前提
本系列的第一部分需要有着对整洁数据的基本理解 – 特别是像用于数据转换的 dplyr,可视化的 ggplot2 以及来自于 magrittr 管道操作的 %>% 等几个包。每个教程会描述你可以用于分析的工具,但是并不是每一步的细节。你将会注意到一些步骤是通常结合使用 %>% 操作符。由于这是一个案例学习,重要的是记住你所做的推论都只是观察性的;因此,相关性并不意味着因果关系。
提示:关于你使用的工具的背景,Garrett Grolemund 和 Hadley Wickham 的《基于 R 语言的数据科学》,和 Julia Silge 和 David Robinson 的《基于 R 语言的文本挖掘》是两个很好的资源。
第 2 和第 3 部分
在其中一个教程中,第二部分,你将会了解涵盖情感分析和主题模型来捕捉 Prince 的音乐中的所有情绪和主题以及它们在社会方面的应用。你将会使用一个情感词汇,评估二元的和分类的情绪,画出随着时间的发展趋势,查看 n-grams 模型和单词的关联。你还将使用自然语言处理和聚类技术,比如潜在狄利克雷分配(DLA)和 K 近邻,对歌词中的主题进行梳理。
在另一个教程中,第三部分,你将会使用你的探索性结果来预测一首歌曲的发布时间,更有趣的是,预测一首歌是否会基于它的歌词登入 Billboard 排行榜。你将会使用机器学习工具,比如决策树(rPart 和 C50),K 近邻(class)和朴素贝叶斯(e1071)来产生可接受文本的分类器。
所有这三部分都将会使用相同的数据集,即 Prince 的歌词,发布年份,BillBoard 位置。 这次研究的技术也可以应用于其他类型的文本。事实上,标准散文的结果更容易解释,因为歌词一般常常是用间接的信息和细微的差别来设计的。
总之,歌词分析有很多方法。这些教程覆盖了下面图表中高亮红色的部分。注意的是这个图表是一个非常模糊的图片的简单的高级表示,并不代表图片本身。事实上,建模和机器学习的很多方面都是模糊的,并不一定适合下面展示的单一框。所以,在看图片时带上 3D 眼镜可能会更有意义!

目标
除了学习和实践新技能,这个教程旨在阐述歌词分析概念的基本问题。最近的研究表明 “歌词智力” 在流行音乐中正在走下坡路。一些研究甚至表明在排名第一的热门歌曲中,使用的词汇与美国三年级学生的阅读水平是一致的。是否可以使用文本挖掘、自然语言处理、机器学习或其他的数据科学方法来对这样的主题进行深入了解? 是否可以根据一首歌曲的被接受程度来确定对社会具有吸引力的主题? 是否可以预测是否一首歌曲会做的很好仅仅依赖于歌词分析? 在第一个教程中,作为探索性的练习,你将会检查 Prince 音乐的歌词复杂程度。
问题
在深入之前,思考一下你正在试图发现什么,还有感兴趣的问题是什么。首先你将会对数据集进行分析,它看起来什么样子的?有多少歌曲?歌词是什么样的结构? 需要做多少清理和争论?事实是什么?频率这个词是什么以及它为什么重要?从技术的角度,你想要理解并为情感分析、自然语言处理以及机器学习模型准备数据。
“音乐一直以来都是一个和大众交流的有效方式,歌词在这其中扮演着重要的角色。然而,对歌词在社会福祉中扮演的角色的研究机会却被大大的低估了 -- 帕特里夏 · 福克斯 · 兰瑟姆”
数据
为文本挖掘获得数据的流行办法是使用 rvest 包来从网上搜取内容。我能够从不同的网站上搜取 BillBoard 信息和 Prince 歌词,并把他们加入到歌曲的标题中。因为不一致的标题命名约定,导致了一些争论。然后我做了一个主观的决定,去除了不是原版的所有歌曲,即混音,扩展版本,俱乐部混音,重制等等。为了避免重复,我还删除了收录了他热门歌曲的历史合集的专辑。我做了一些小清理,并保存结果为可以用于本教程的 csv 文件。
由于第一部分专注于文本挖掘,我没有在这里提供代码,但是如果你愿意的话,数据集是可以在这里下载。
导入类库

读取数据
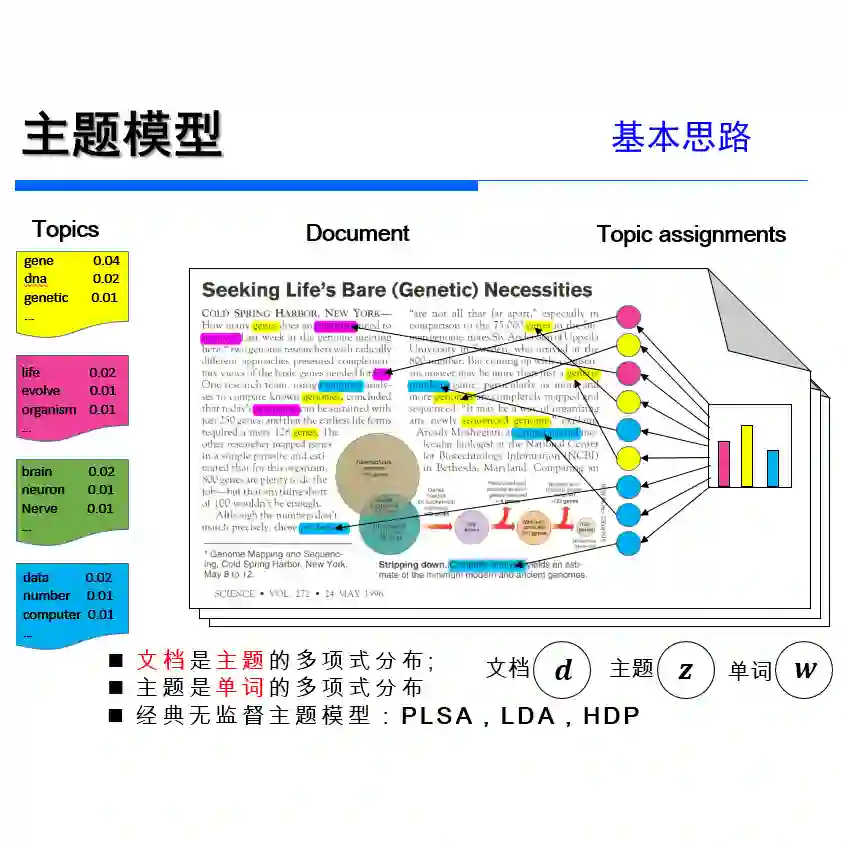
从 csv 文件中有几种方式读入数据,我倾向于使用 read.csv() 加载数据框架,即歌词、发布年份、Billboard 排名位置。需要注意的是,默认情况下,R 语言把所有的字符串转换成因子。这可能会导致下游问题,但是你可以通过设置 stringAsFactor 参数为 FALSE 来解决这个问题。

你可以使用 names() 函数来看数据框架中的列。

因为我创建了这个文件,我知道 X 是行数,text 是实际的歌词。其他必需的项包括 song, year, peak(代表它在 Billboard 中的位置), US Pop 和 US R.B 代表着在美国(流行音乐和 R&B 排名)峰值图位置,所以保存好这些,删去其他的项。
使用原始的数据集来做这件事 prince_orig,然后使用 %>% 管道操作传入 select()。这样的方式你能够从左到右的读取代码。
另外,注意的是,select() 允许你一次重新命名所有的列。因此将文本设置成歌词然后用_代替. 重命名 US 列项。然后存储为 Prince,之后再整个教程中你都将会用到。Dplyr 提供了一个函数叫 glimpse() 会使你在转置视图中更容易地查看数据。
第一个显而易见的问题是有多少个观察和列项?

使用 dim() 函数,你将看到结果是 7 个列项和 824 个观察,每个观察都是一首歌。如我所说。多产啊!
请看其中一首歌的 lyrics 项,你可以了解一下它们的结构。

这里有很多机会来清理它们,让我们开始吧。
数据调整
基本的清理
有很多不同的方法使你来清理数据。其中一个选择是使用 tm 文本挖掘包把数据框架转换成语料库和文本术语表,然后使用 tm_map() 函数做清理。但是本教程目前将专注基础,使用 gsub 和 apply() 函数来做脏工作。
首先,通过使用 gsub() 创建一个小函数来处理大部分场景以避免那些烦人的收缩,然后再所有歌词上应用该函数。
你还将注意到特殊字符弄脏了文本。你可以用 gsub() 函数和简单的正则化表达式来去除它们。 请注意,在这步骤之前,扩充收缩是非常重要的!

为了一致性,使用 tolower() 函数来把所有的内容都转换成小写格式。

检查歌词,现在它们展示了原始文本之上一个很好的、更简洁的版本。

在文本挖掘中调整数据的另一个普遍的步骤是词干,或者叫拆分单词为它们的词根含义。这是可以在以后讨论的话题,现在,看一下 Prince 的数据框架。
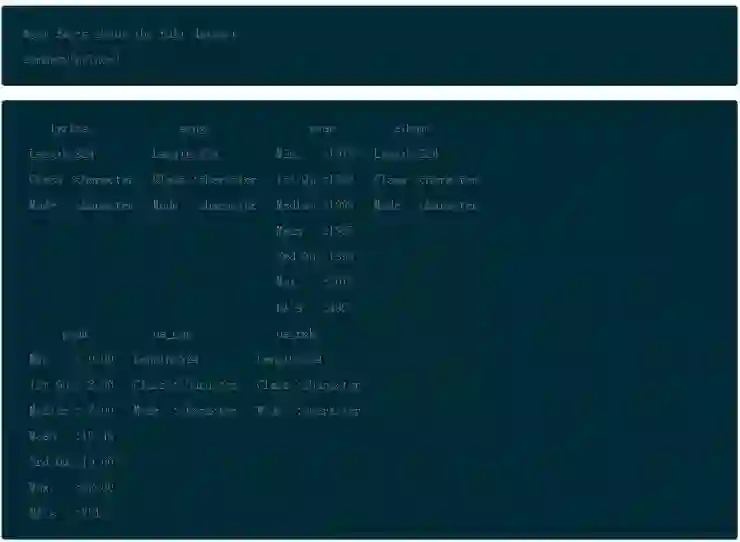
如你看到的,有 37 年的歌曲,而排名最低的歌曲是在 88 的位置。你也可以看到对于 year 和 peak 项有很多 NAs。因为你将要做不同类型的分析,在 Prince 数据框架中保留完整的数据集,仅在需要的时候进行筛选。
加入一些新的项
因为你的一个目标问题是寻找跨越时间的歌曲趋势,并且数据集包含着个人发行年份,你可以创建存储桶来以十年划分年份。使用 dplyr 的 mutate() 函数来创建新的 decade 项。创建存储桶的一个办法是采用 ifelse() 和 %in% 操作符来根据年份过滤歌曲转换成十年。然后存储结果到 Prince(实际是增加了一个新的项)
你可以对 chart_level 做同样的事,它代表着一首歌是否进入了前 10 名,前 100 名或者没有上榜。它们是互相排斥的,所以前 100 并不包含前 10。

另外,创建一个叫做 charted 的二值项表明一首歌是否入围 Billboard 榜单。使用 write.csv() 来保存为了以后的教程中使用。
描述性的统计
为了个性化图表,我喜欢创建一个唯一的颜色列来保持视觉的一致性。Web 上有很多可以通过下面所展示的十六进制码来获得不同的颜色的地方。如果你有对于图表有这样的喜好,你也可以在需要的时候通过使用 ggplot() 创建自己的主题。
在开始进行文本挖掘之前,先从基本的角度看看你的数据在歌曲级别的位置。现在是一个很好的时机来了解一下 Prince 每十年发行的数量。提醒一下,他于 1978 年开始自己的职业生涯并一直持续到 2015 年(在上面总结的数据中可见)。但是因为我们现在关注的是趋势,而且数据集上在 year 项有很多空白值,你将想要在第一张图表中过滤掉所有的发行年为 NAs 的数据。
歌曲统计
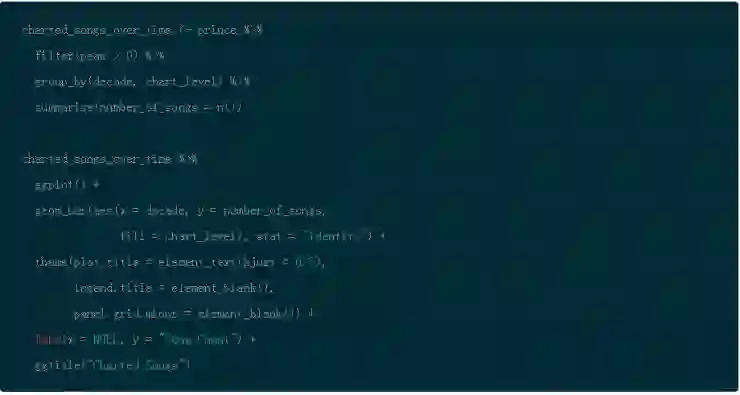
通过使用 dplyr 的 filter(),group_by() 以及 summarise() 函数,你能够按照 decade 来分组,然后计算出歌曲的数量。函数 n() 是多个聚合函数之一,也是对于在分组数据上使用 summarise() 有用的。然后使用 ggplot() 和 geom_bar() 创建条形图然后将分类填充到条形图中。
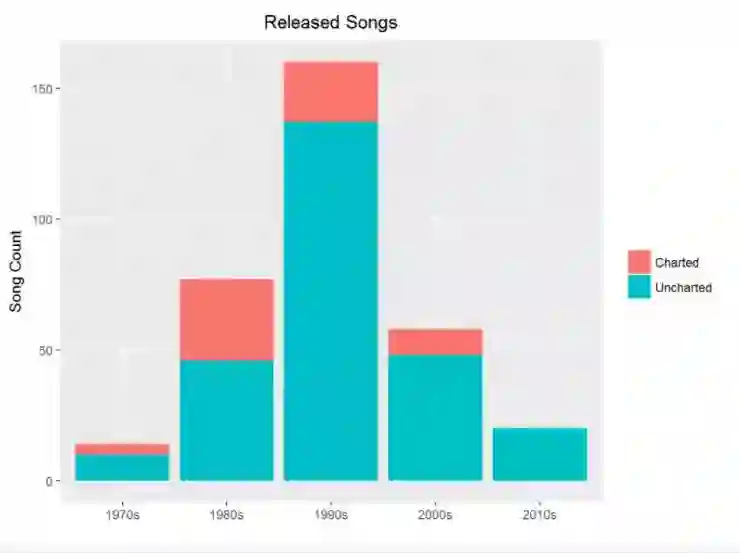
这清楚地展示了 20 世纪 90 年代是他最活跃的十年。
现在创建一个类似的图表叫 chart_level。
记得对 decade 和 chart_level 使用 group_by() 函数,你将会看到趋势。
在这个图表中,你仅需要看一下表上的歌曲,使用 peak > 0 来过滤掉其他的东西。将 group_by 对象导入到 summarise() 然后使用 n() 来统计歌曲的数量。当你把它存到一个变量中便可以导入到 ggplot() 来绘制一个简单的条形图。
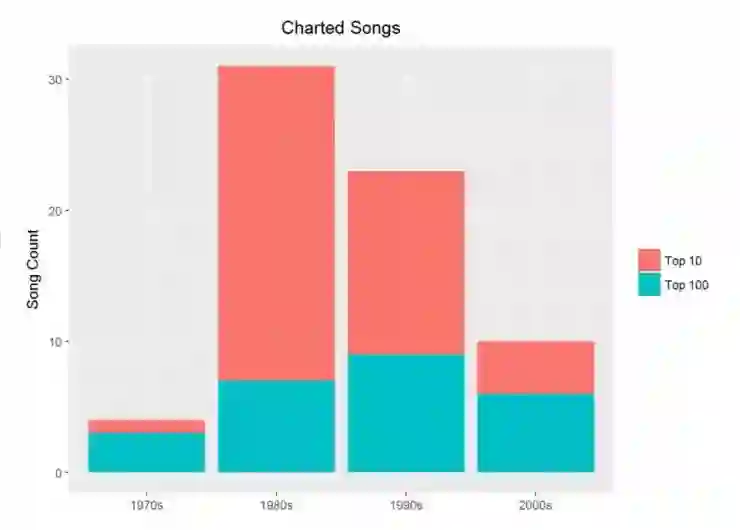
洞见
注意到所有 Prince 的上排行表的歌曲,大部分都是前 10 名。但是更有趣的是在他创作新歌最多产的十年是 90 年代,但是更多上排行表的是在 80 年代。为什么会发生这样的事儿?请在看文本挖掘部分的时候记住这个问题。
为了使用完整数据集来分析歌词,你可以删除参考图表级别和发布年份来获得更大量的歌曲去挖掘。
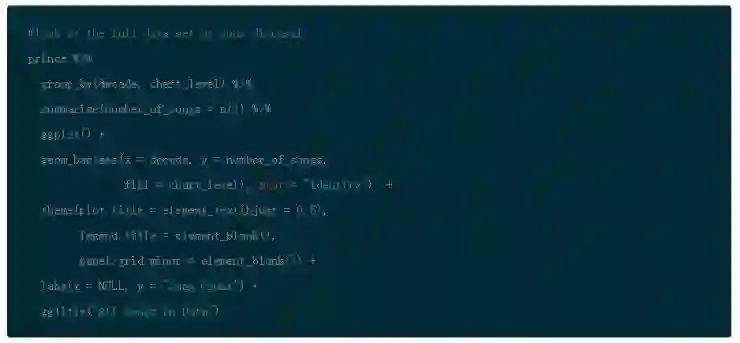
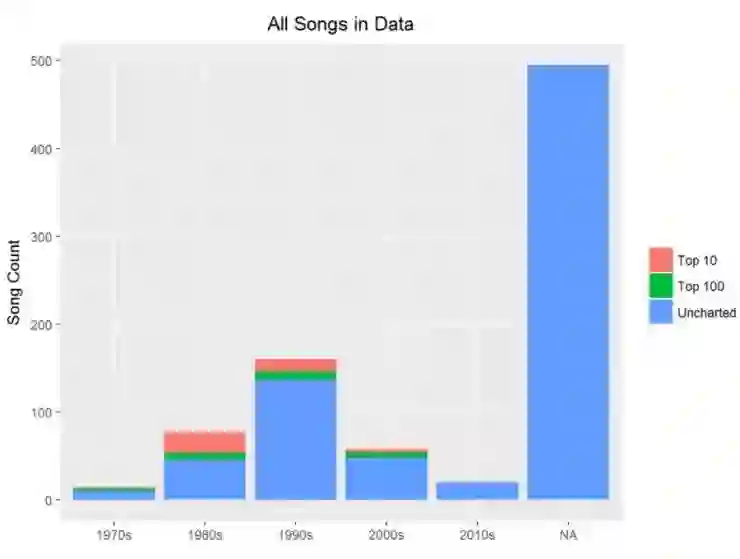
如你看到的,Prince 写过成百上千首在数据中没有发布日期的歌曲。对于情感分析和探索性分析来说,你可以使用所有的数据,但是对于随时间的变化趋势,你仅有一个更小的处理集合。这没问题,仅仅知道就好了。
第一的歌曲
对于那些 Prince 狂热的粉丝来说,下面是一个快速浏览排行榜第一的歌曲(请注意,你可以用来自于 knitr 包的 kable() 和来自于 kableExtra 包的 kable_styling() 以及来自于 formattable 包的 color_tile() 来创建一个更规范的 HTML 输出)

文本挖掘
文本挖掘也可以被认为文本分析。目标是发掘可能未知的或者被隐藏在字面意思之下的相关信息。自然语言处理是一种用于挖掘文本的方法。它试图通过标记、聚类、提取实体和单词关系来解释书面语言的模糊性,并使用算法来明确主题和量化主观信息。首先你将打破词汇复杂性的概念。
词汇复杂性在不同上下文环境中可能意味着不同东西,但是现在,假设它可以被这些测量的组合所描述。
单词频率:每首歌单词的数量
单词长度:文本中每个单词的平均长度
词汇多样性:在文本中不单词的数量(歌曲词汇)
词汇密度:不同单词的数量除以所有单词总数(字词重叠)
整洁文本的格式
分析之前,你需要把歌词分解为一个个单词,然后开始深入挖掘。这个过程叫做标记化。
数据格式和标记化
请记住有不同的方法和数据格式可以用做文本挖掘。
语料库:用 tm 文本挖掘包来创建的文档的集合
文档 - 词矩阵:一个列出在语料库出现的所有单词的矩阵,其中文档是行,单词是列。
整洁文本:每行都有一个令牌的表。在本例中,令牌即一个单词(或者是在第二部分讨论的 n-gram)。标记化是一个将歌词拆分为令牌的过程。本教程将用 tidytext 的 unnest_tokens() 函数来完成。详细信息,请查阅 tidytext 文档。
但是在你开始令牌化任何东西之前,清理数据还有一个步骤。很多歌词在转录的时候会包括像 “重复合唱” 或者 “桥牌”“诗歌” 等这样的标签。还有很多不希望的单词会弄脏结果。有了之前的分析,我选择一些可以摆脱的方法。
下面是需要手动删除的多余单词的列表。

要取消标记,使用己加载的 tidytext 类库。你可以开始利用 dplyr 的强大功能同时一起加入几个步骤。
在文本整洁框架中,你既需要将文本分解成单独的标记又需要把文本转换成一个整洁的数据结构。使用 tidytext 的 unnest_tokens() 函数来做这个。Unnest_token() 需要至少两个参数:列输出名将被在文档取消后创建(本例中的 word), 列输入保存当前文本(歌词)
你可以使用 prince 数据集,并导入 unnest_tokens() 函数,然后删除停止单词。停止单词是什么?你很了解它们。它们是对结果没有增加任何意义的很普通的单词。有不同的列表可供选择,但是你可以使用 tidytext 包的 stop_words 函数。
使用 sample() 展示一个这些停止单词的随机列表,使用 head() 限制在 15 个单词。
因此,在你将歌词标记为单词之后,使用 dplyr 的 anti_join() 函数删除停止单词。接下来,使用 dplyr 的 filter() 函数和 %in% 操作符来删除之前定义的不想要的单词。然后使用 distinct() 来去掉重复的单词。最后,你可以删除所有少于 4 个字符的单词。这是另一个主观决定,但是在歌词中,很多感叹词比如 “是, 嘿”,然后把结果存到 prince_words_filtered。
注意:为了之后的参考,prince_words_filtered 是 Prince 数据的整洁文本版本: 没有了停止单词,没有不想要的单词,没有 1-3 个字符的单词。你会在一部分而并不是所有的分析中使用它们。

注意的是 stop_words 有一个 word 列,有一个叫做 word 的新列是被 unnest_tokens() 函数所创建的,所以 anti_join() 自动加入到 word 列
你可以检查你的新的整洁数据的结构的类别和维度。

Prince_words_filtered 是一个有着 36916 个单词(不是唯一的单词)和 10 个列的数据。这有一个快照 (我只选择一个单词,并将它限制在 10 首歌之中然后使用 select() 按顺序打印感兴趣项,再次使用 knitr 来格式化)。这里向你展示了标记化,未总结的,整洁的数据结构。
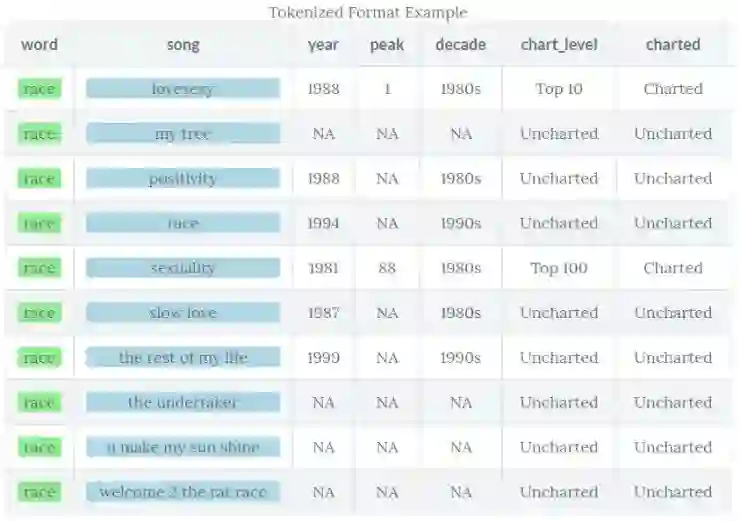
你能看到每行包含各自的能够在每首歌中重复出现的单词。
词汇频率
音乐中的个性化词频占有非常重要的一席之地,无论是常见词汇还是罕见词汇。这两方面都会影响整首歌的流行度。流行歌曲的作者都想知道的一个问题是词频和打榜歌曲是否有关联性。所以现在你需要利用简洁的数据做更深一步的探究,以得到每首歌的词汇统计。
为了测试 Prince 歌词的格式,可以根据歌曲名称和公告牌是否上榜分组,建立直方图来展示词频的分布。利用源 Prince 歌词得到一个真实的词频计数。再一次利用 group_by() 和 summarise() 函数计数。随后使用 dplyr 和 arrange() 排序。首先,看一下词频最高的歌曲,再使用 ggplot() 的直方图展示。

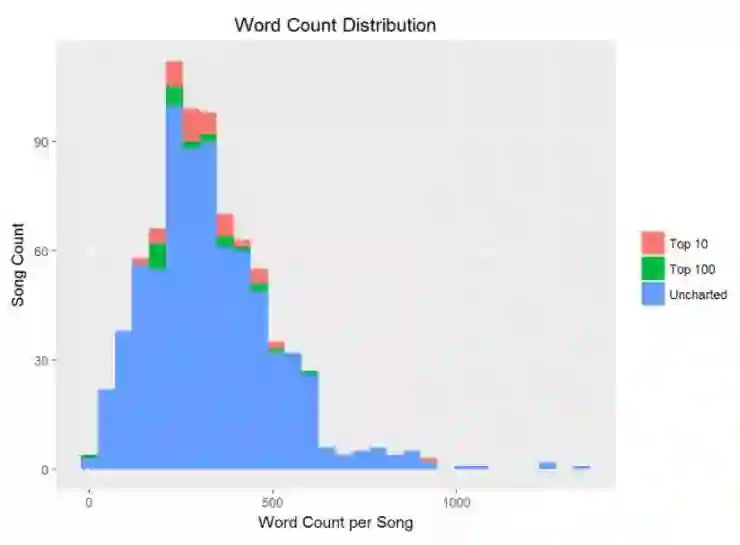
注意到上图是右偏的。考虑到歌词转录的性质,我怀疑是歌词输入的错误。所以,出自好奇,我观察打榜前十名且超过 800 个单词的歌曲。
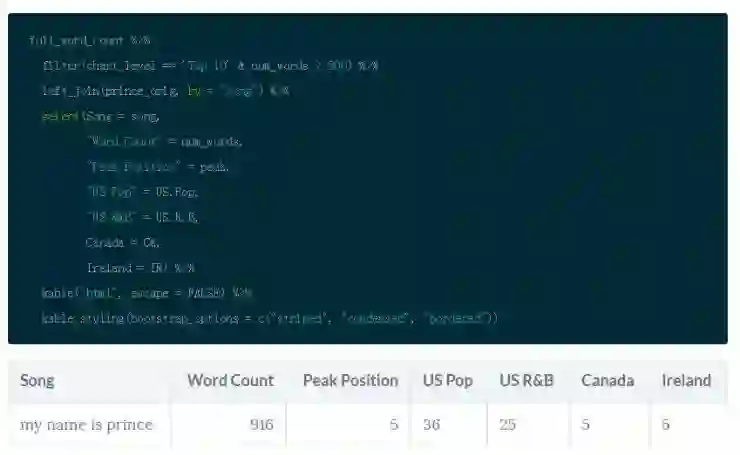
我做了一点研究后发现这首歌曲有一段嘉宾表演的说唱。这就说得通了!记住,这份数据包含流行歌曲和 R&B 全球榜单,所以歌曲类型和地理因素可以影响你的假设。注意到这首歌曲在美国流行音乐榜的排名要远低于其它国家,比如在加拿大榜单其位列第五名。在心里记住这件事。
挑战:如果你想要亲自动手进行音乐分析,你可能需要查看 The Million Song Dataset,它拥有超过 50000 名表演者的 50 个特征(例如:节奏, 响度, 舞蹈表现力等等)。将音乐特征融入到歌词有利于做非常全面的分析。
词汇榜首
为了粗略估计全部歌词集中最频繁使用的词汇,你可以在你干净的、过滤过的数据集使用 count() 和 top_n() 两个函数,得到前 n 名频繁使用的词汇。
然后根据计数结果,利用 reorder() 函数对词汇再度排名,使用 dplyr 的 mutate() 函数生成有序的 word 变量。这方便使用 ggplot() 进行更友好的展示。
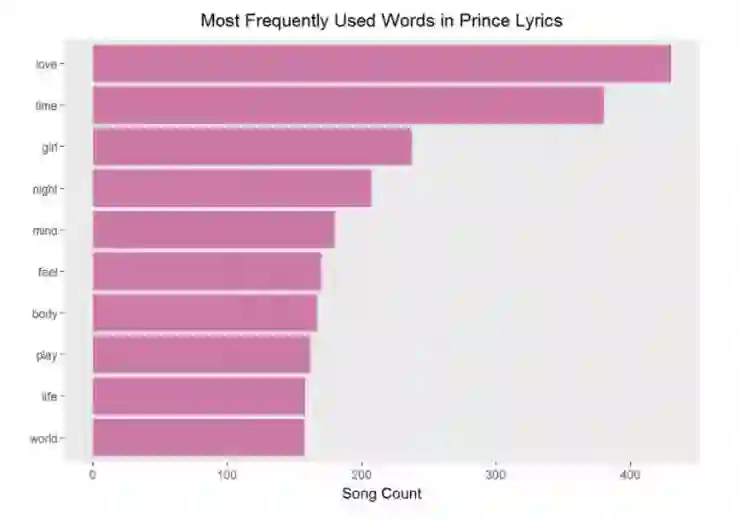
在最为流行的音乐中,爱是最为常见的主题。仅凭借这些最常用的词汇我不会做任何假设,但是你可以从中窥探艺术家的洞察力,当然不是全貌。在移步进行更深层次的调查之前,花一些时间获得一些视觉上的享受吧!
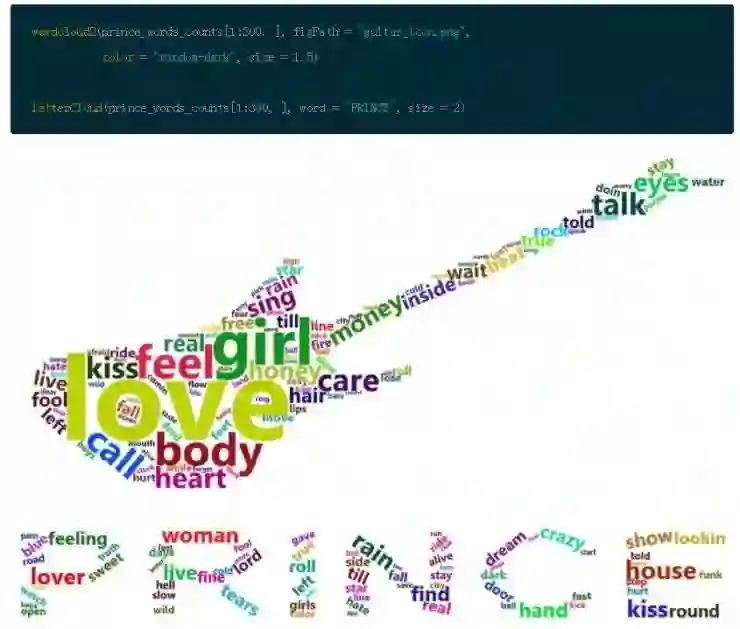
词云
词云在很多人中受到负面评价,如果你不谨慎地使用词云,那么在某些时候他们就会超出文本框。然而从本质上来说,我们都是视觉动物,能够以洞察力从这些可视化图中获得真正有意义的信息。看一些 Sandy McKe 的实例,并谨慎地使用词云图。
但是现在,使用一个新的、名为 wordcloud2 的包做一些酷的事情。这个包提供关于词云生成 HTML 控件的创造性的集合。你可以围绕一个单词观察其在文本的频率。(这个包在 rMarkdown 平台上面更新速率非常缓慢,并且对使用的浏览器有非常多的限制条件。希望它会有所提升。)

想获得更多乐趣的话,你可以加入一点数据美感。
流行词汇
截至目前我们已经观察所有歌曲中的流行词汇。如果你根据打榜名次分组后会发生什么?在上榜歌曲和未上榜歌曲中是否存在更流行的词汇?这些被认为是社会中流行的词汇。
注意到下图代码中使用 slice(seq_len(n)) 的作用是为了获得 chart_level 不同类别的前几名。它的作用和 top_n() 是不同的,并且如果你在图形中使用刻面的话,这是更加方便的选择。(需要谨记这类技巧有不同方法)你可以使用 row_number() 函数来确保在图形中你可以按照正确顺序呈现单词)。ggplot() 默认设置是按照字母排序,并且实际操作中排序要优先于画图。
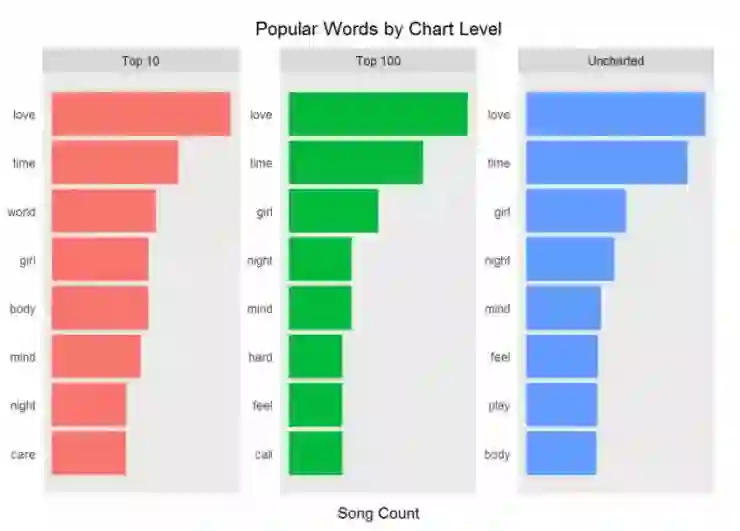
你现在从上面得到的见解是什么?
好吧,不同打榜歌曲中流行词汇是如此接近。这对于我们想通过歌词来预测一首歌是否成功打榜不是件好事。但是你仅仅了解到文本挖掘,自然语言和预测模型中的皮毛知识。
永不过时的词汇
音乐中一些词汇是永不过时的。永不过时的词汇超越了时间,能够吸引一大批听众。如果你按照每十年划分你的数据,这些词汇会上榜。使用过滤,分组和聚合获得 Prince 歌词每十年的流行词汇,观察什么词汇属于永不过时的,哪些是一闪即逝的。你可以使用 ggplot() 中的 facet_wrap() 绘制每十年的数据。
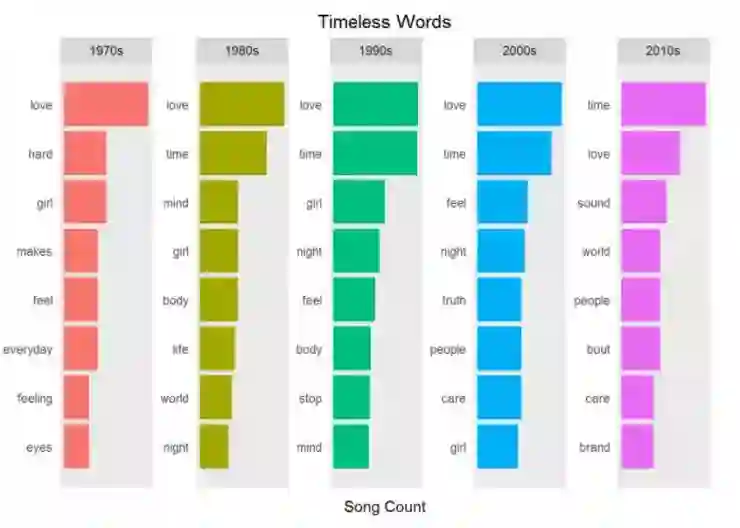
显而易见:爱,时间和女孩是历久弥新的词汇。但是识别流行词汇到底多容易呢?一个世纪就会轮换流行词汇是否为事实?能否简单认为上述的词汇在歌曲中是高度重复的呢?词频是否是识别歌曲主题的依据呢?这种分析歌词的方法是否适用于其它文本挖掘的任务呢,例如分析州政府的演讲?
词汇长度
对歌曲作者来说,词汇长度是一个有趣的话题。词汇越长,越难押韵和形成一种模式。下面的词汇长度的直方图展示正如你所期待的,仅有少数词汇的长度是非常长的。
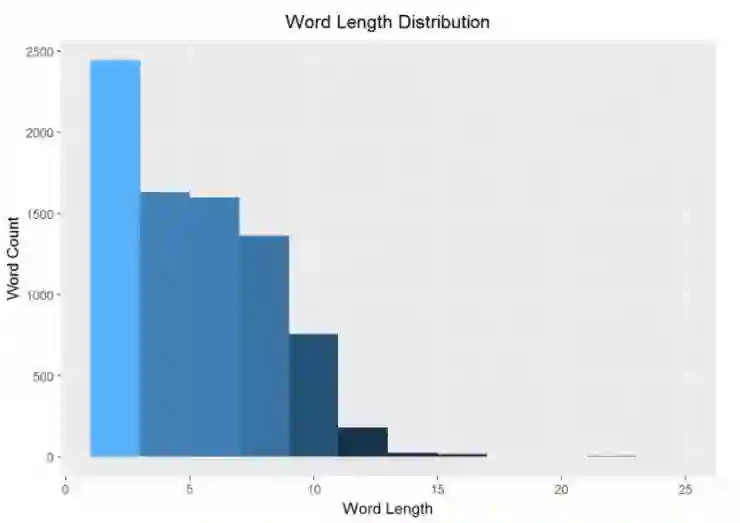
这些疯狂的长词汇是哪些呢?我想这需要一个非常有趣的词云图!这是基于词的长度而非词频。显示如下:
词汇多样性
一个文本包含的词汇越多,其词汇多样性就越高。宋的词汇表呈现的是一首歌曲中有多少独特的词汇。可以用一个简单的图显示过去平均一首歌中有多少词汇是独一无二的。
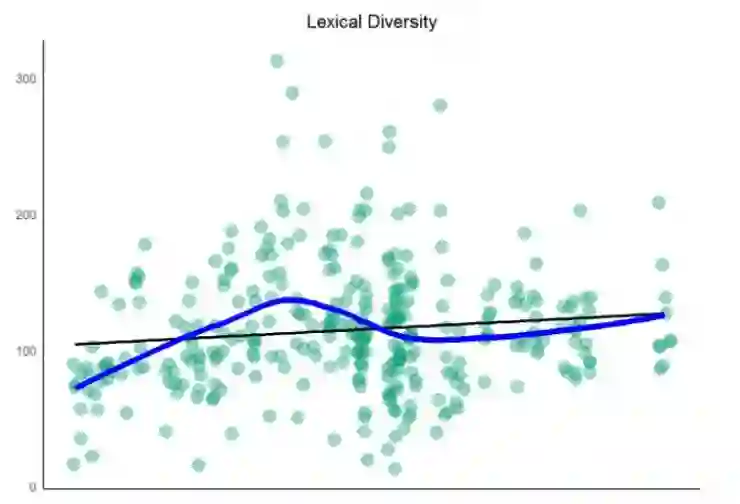
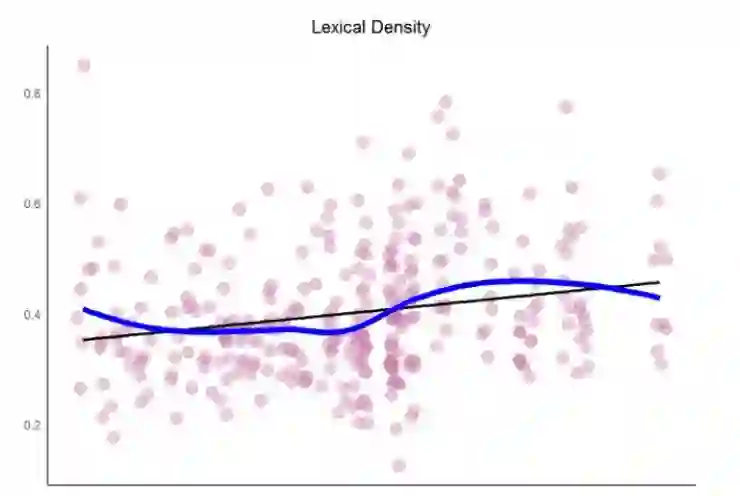
这说明什么呢?过去的数十年间,Prince 的歌词多样性具有一点轻微向上的趋势。这和打榜成功有多少相关呢?很难说,画出密度图和打榜历史再做更近一步的分析吧!
词汇密度
回忆本教程,词汇多样性等于独特词汇除以文章词汇的长度。这是词汇重复性的一个指标,词汇重复是歌曲作者的一个关键工具。词汇密度提升,重复性降低。(注意:这不同于顺序重复,那是歌曲作者的另一个技巧)
观察过去几年间 Prince 的词汇密度。考虑密度的话,最好保留所有词,包括停词。所以从原始的数据集和未经过滤的词汇开始。根据歌曲和年份分组,用 n_distinct() 和 n() 计算密度,把结果用 geom_smooth() 传给 ggplot() 。此外用 stat_smooth() 的 lm 模型做一个线性平滑模型。
为比较趋势,可以可视化打榜历史数据(例如:打榜成功的歌曲)和比较其多样性和密度。使用 gridExtra 的 grid.arrange() 函数并排地绘图。
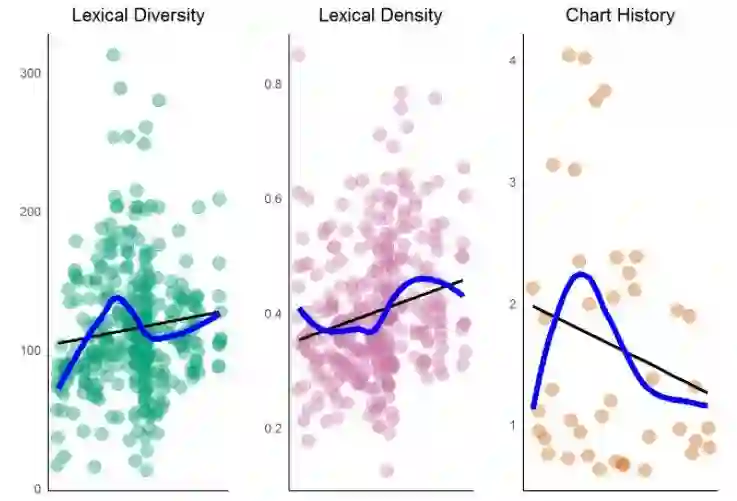
你可以观察到过去几年间,Prince 的词汇多样性和密度呈轻微上升趋势。怎样比较这个趋势和所有流行歌曲的关系呢?有研究显示打榜歌曲的词汇多样性和密度呈下降趋势,暗示重复性有所提升(例如:词汇更多,说得更少)。这个趋势和 Prince 的歌曲不同。另一个研究证明所有流行歌曲,多样性(独特词汇)在过去年间呈现上升趋势,这和 Prince 歌曲正相关。这可能是因为过去榜单排名试图丰富类型多样性。类型是数据的关键部分,但是这个变量在我们的数据集并不存在。这是否是因为榜单历史对流行歌曲的影响力日益衰微,对 R&B/Rap 的影响力日益加深?
挑战:我希望你能考虑这些结果,甚至鼓励你寻找不同数据集,并且自己动手练习。记住:相关性不同于因果关系。
TF-IDF
目前为止在整个数据集中使用的方法并没有强调如何量化文档中不同词汇在整个文档集中的重要性。你已经查看词频,并且移除停词,但这可能还不是最复杂的方法。
进入 TF-IDF。TF 代表词频。IDF 代表逆向文件频率,它赋予经常使用的词汇低权重,同时给文本中罕见词汇更多权重。当你联合 TF 和 IDF 时,一个词汇的重要性调整为它在使用过程中的罕见程度。TF-IDF 背后的假设是文本中更频繁使用的词汇应赋予更高的权重,除非它出现在很多文档中。公式总结如下:
• 词频 (TF):一个单词在文档中出现次数
• 文件频率 (DF):包含单词的文档数量
• 逆向文件频率 (IDF) =1/DF
• TF-IDF = TF * IDF
因此对于在集合中仅见于少数文档的任何单词,IDF 是非常高的。你可以通过 tidytext 中的 bind_tf_idf() 函数来使用这个方法,以便检查每个打榜名次分类中最重要的词汇。这个函数用 TF*IDF 的乘积来计算和联合 TF 与 IDF。它用经过过滤的数据集作为输入,每一行是一篇文件(歌曲)中的一个表示(词汇)。你会在新的一列看到结果。
所以,利用你原始的 Prince 的数据框和经过过滤的标记词,并且消除不受欢迎的词汇,但是保留停词。然后使用 bind_tf_idf() 运行公式并且建立新的列。
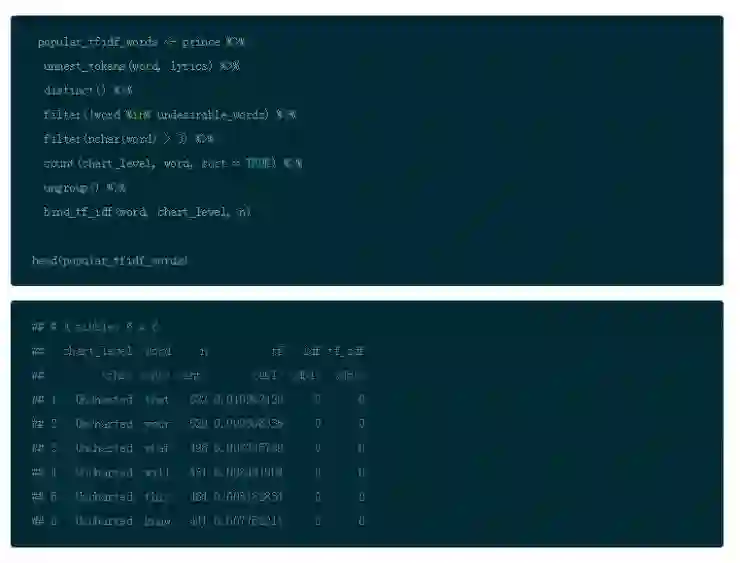
现在如你所见,对于最最常见的单词,IDF and TF-IDF 都是 0.(更科学地说,IDF 的表现形式是自然对数 ln(1),所以那些词汇的 IDF 以及 TF-IDF 的值是 0.)把你的结果作为参数传递给 arrange() 然后以降序的方式展示 tf-idf。通过增加这些步骤,你会以一种不同的视角观察 Prince 的歌词。
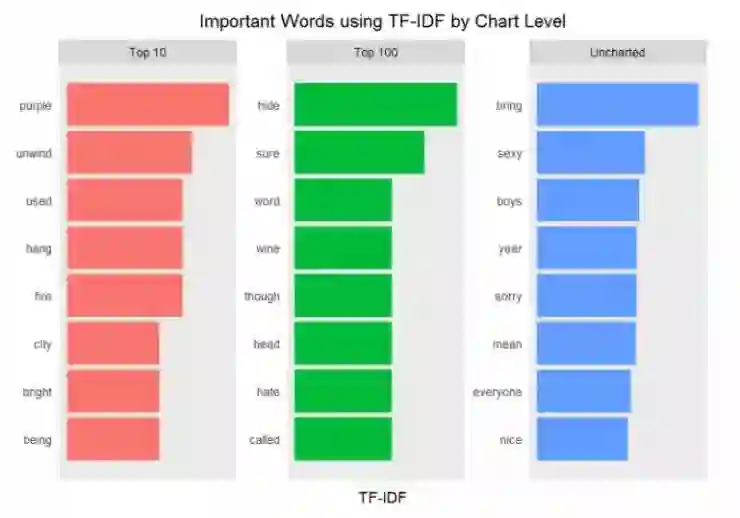
使用 TF-IDF 为观察潜在的重要词汇提供一种不同的视角。当然,解释是完全主观性的。注意到其中的模式了吗?
接下来,观察随时间变化的 TF-IDF。
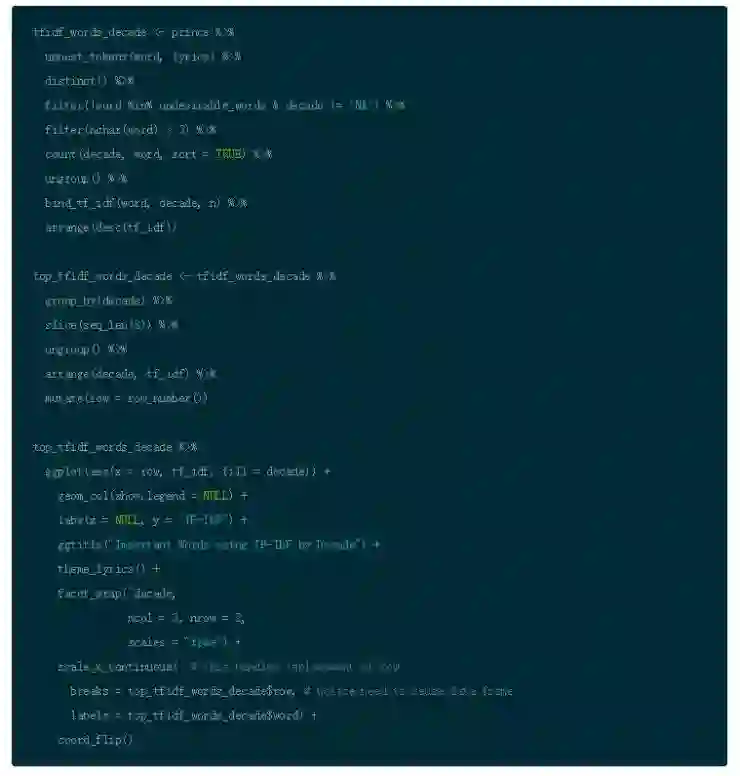

现在你看待这个问题已经有了更深层次的见解。‘永不过时’的词汇不再流行。仅仅利用每组一些词汇就能观察到新出现的主题是否可行呢?你将会在第二个教程学习这方面的知识以达到新的高度(第二部分:自然语言处理的情感分析和主题模型)
这个方法的词云图以全新的视角显 Prince 中的歌词的重要词汇,事情变的越来越有趣。


总结
在这个案例中,首先你以最基础的角度快速观察真实数据。然后进行一些处理:例如数据清洗和删除不提供信息的词汇,并开始歌曲的探索分析。
接下来,你通过把歌词转换词的表示以便于观察歌词复杂性的方法,更加深入地钻研文本挖掘。分析结果为接下来的情感分析和主题建模提供关键视角。
最后,你通过 TF-IDF 分析得到在文本中词汇背后的信息,并收获一些有趣的结论。你或许认为这是一个识别音乐主题的好方法,但此时你仅仅只是一知半解。第二部分强调运用无监督的 LDA 方法。在数据科学的各个层面,有很多方法可以获得内在的见解。在此案例的第二部分和第三部分,你将会学习到更多观点
希望你和我一样迫不及待想继续接下来的探索分析旅程:情感分析,话题建模和预测见解。
谢谢你的阅读,期待接下来教程能继续同行。
博客原址 https://www.datacamp.com/community/tutorials/R-nlp-machine-learning
更多文章,关注 AI 研习社,添加雷锋字幕组微信号(leiphonefansub)为好友
备注「我要加入」,To be an AI Volunteer !

NLP 工程师入门实践班
三大模块,五大应用,知识点全覆盖;
海外博士讲师,丰富项目分享经验;
理论 + 实践,带你实战典型行业应用;
专业答疑社群,结交志同道合伙伴。
▼▼▼

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
一文详解如何用 R 语言绘制热图
▼▼▼