Pick 一下?Python 机器学习实用技巧
我们 Pick 了一些用 Python 进行机器学习实践的基本技巧。
我是一名计算机科学与技术专业的学生。我怎么才能入门机器学习/深度学习/人工智能?
入门机器学习从来不是一件简单的事。除了成熟的 MOOC,网络上还有海量的免费资源,这里列举了一些曾经对我有帮助的资源:
从 YouTube 上的一些精彩的视频开始入门。读一些优秀的教材或文章。例如,你读过《终极算法: 机器学习和人工智能如何重塑世界(https://www.goodreads.com/book/show/24612233-the-master-algorithm)》吗?并且我敢保证,你会深深的爱上这本书里有关机器学习的精彩页面(http://www.r2d3.us/visual-intro-to-machine-learning-part-1/)。
首先要明确区分相关术语——机器学习、人工智能、深度学习、数据科学、计算机视觉、机器人。阅读或聆听专家的讲座。观看 Brandon Rohrer 的精彩视频,他是一位很有影响力的数据科学家, 这些视频(https://www.youtube.com/watch?v=Ura_ioOcpQI)清晰的讲述了数据科学相关概念的定义和区别。
清楚知道自己学习想要达到的目标。然后,学习Coursera的课程,或者一些来自华盛顿大学的课程(https://www.coursera.org/specializations/machine-learning),也是不错的选择。
关注一些优秀的博客: KDnuggets,Mark Meloon的博客,是关于数据科学的,Brandon Rohrer 的博客,Open AI 的博客,主要是关于他们的研究的。
如果你对在线 mooc 课程充满热情,不妨看看这篇文章(https://towardsdatascience.com/how-to-choose-effective-moocs-for-machine-learning-and-data-science-8681700ed83f)的指导。

复仇者联盟3:无限战争
主演:小罗伯特·唐尼 / 克里斯·海姆斯沃斯 / 马克·鲁法洛
最重要的是,培养一种感觉。加入一些好的社交论坛, 但是要抵制住诱惑,不要去关注那些耸人听闻的标题和新闻内容。 做你自己的阅读,了解它是什么,它不是什么,它可能去哪里,它会有什么样的可能性。 然后坐下来思考如何将机器学习或者将数据科学原理应用到日常工作中。 建立一个简单的回归模型来预测下一顿午餐的成本,或者从电力公司那里下载你的用电数据,然后在 Excel 中做一个简单的时间序列图来发现一些用电规律。 在您完全沉迷于机器学习之后,可以看看这个视频。
对于机器学习/人工智能,Python是一款优秀的语言吗?
除非你是一个研究复杂算法的纯理论证明的博士研究员,否则你将主要使用现有的机器学习算法,并将它们应用于解决新问题。这就需要你懂得如何编程。
关于“最优秀的数据科学语言”有很多争论。当争论激烈的时候,停下来读读这篇有见地的文章,了解你的想法,看看你的选择。或者,看看 KDnuggets 的文章。目前,大家普遍认为,从开发到部署及维护,Python可以帮助开发人员更有效率。与 Java、C 和 C++ 相比,Python 的语法更简单,更高级。 它拥有充满活力的社区,开源文化,数以百计高质量的机器学习程序库,以及来自行业巨头的鼎力支持(例如:谷歌,Dropbox,Airbnb 等)。这篇文章会关注PythonIt应用于机器学习上的相关基本技巧。
需要了解及掌握的基础程序库
为使机器学习实践效率更高,你需要掌握一些 Python 核心库。这些库简单介绍如下。
Numpy
Numerical Python 的缩写,NumPy 是采用 Python 进行科学计算和数据分析所必须的基本程序库。几乎所有的高级工具都是基于 Numpy 构建的,例如 Pandas 和 scikit-learn。 TensorFlow 使用 Numpy 数组作为基础构件模块,基于此,为深度学习任务构建了 Tensor 对象和 graphflow 。很多 Numpy 操作都是用 C 实现的,这使它运行更快。对数据科学和现代机器学习任务来说,这是一个宝贵的优势。

Pandas
这是 Python 科学计算领域进行通用数据分析方面最流行的库。Pandas 基于 Numpy 数组构建,因此保留了计算速度快的特性,并且提供了很多数据工程领域的功能,包括:
可以读/写多种不同的数据格式;
选择数据子集;
跨行列计算;
查找并填充缺失的数据;
将操作应用到数据中的独立组 ;
将数据重组成不同的形式;
合并多个数据集;
高级的时序功能;
通过 Matplotlib 和 Seaborn 实现可视化;
Matplotlib 与 Seaborn
数据可视化和善于用数据表达是每一位数据科学家应有的基本技能,这些技能可以有效传达从分析中获得的信息。这对于掌握并精通机器学习是非常重要的,在你的机器学习工作流(ML Pipeline)中也是如此。在决定应用特定的 ML 算法之前,您需要对数据集进行探索性分析。
Matplotlib 是应用最广泛的 2 维可视化库,它拥有令人眼花缭乱的数组命令和接口,能够从数据生成高质量的图表。这里有一个非常详细和内容丰富的文章(https://realpython.com/python-matplotlib-guide/),可以帮你入门 Matplotlib 。
Seaborn 是另一个非常棒的专注于统计绘图的可视化库。机器学习从业者是值得学习的。在 Matplotlib 基础之上,Seaborn 提供 API (具备绘图样式和颜色默认的灵活选择),针对常见的统计绘图类型它定义简单的高级函数,针对 Pandas 库可以无缝对接。这里有一份适合初学者的很棒的 Seaborn 教程(https://www.datacamp.com/community/tutorials/seaborn-python-tutorial)。
Seaborn plots 的例子
Scikit-learn
Scikit-learn 是必备的最重要的常见 Python 的机器学习包。它支持多种分类、回归和聚类算法,包括支持向量机、随机森林、梯度提升、k-means 和 DBSCAN 。Scikit-learn 可与 NumPy 库 SciPy 库交互操作。它通过一致界面提供一系列的监督和非监督算法。Scikit-learn 库致力于实现一定程度的健壮性和支持生产实践中的使用。这意味着要深入关注例如易于使用,代码质量,协作,文档和性能等问题。可以看看这篇关于Scikit-learn使用的机器学习词汇的简单介绍。这里是另一篇文章,演示了使用 Scikit-learn 的简单机器学习管道方法(http://scikit-learn.org/stable/tutorial/basic/tutorial.html)。
这里有另一篇使用Scikit-learn演示简单的机器学习方法的文章。
https://towardsdatascience.com/machine-learning-with-python-easy-and-robust-method-to-fit-nonlinear-data-19e8a1ddbd49
Scikit-learn 背后的闪光点
针对机器学习初学者和经验丰富的专业人士,Scikit-learn 是非常容易上手的包。然而,即使是非常有经验的 ML 从业人员也可能没有意识到这个包背后所有的的闪光点,它们可以显着提升效率。我试图展示 scikit-learn 中少为人知的方法/接口。
管道:它可以将多个 estimators 封装成一个。处理数据过程中通常有一系列固定步骤所以它非常有用,例如特征选择、规范化和分类。这里有份教程供深入了解。

后来的我们
主演:井柏然 / 周冬雨 / 田壮壮
网格搜索:超参数不是在 estimators 直接学习到的参数。在 scikit-learn 中它们作为参数传递给估计类的构造函数。搜索超参数空间以便获得最好交叉验证分数是可行且被推荐的做法。当构建 estimators 时待估的任何参数都可以用这种方式优化。访问下面的链接获取更多信息:
http://scikit-learn.org/stable/modules/pipeline.html
验证曲线:每个 estimator 都有其优缺点。泛化误差可依据偏差,方差和噪音分解。estimators 的偏差是不同训练集的平均误差。estimators 的方差表示其对改变训练集有多敏感。噪音是数据的一个属性。绘制单个超参数在训练集和验证集的分数,以确定某些超参数估计量是过拟合还是欠拟合的做法是非常有用的。Scikit-learn 内置方法请移步于此。
分类数据的独热编码:它是一种非常常见的数据预处理任务,用于将输入的分类特征转换为分类或预测任务中使用的二进制编码(例如:掺有数指和文本特征的逻辑回归)。Scikit-learn 提供强大而简单的方法实现上述过程。它直接在 Pandas 数据框或 Numpy 数组上操作,因此便于用户为这些转换编写任何特殊的 map/apply 函数。
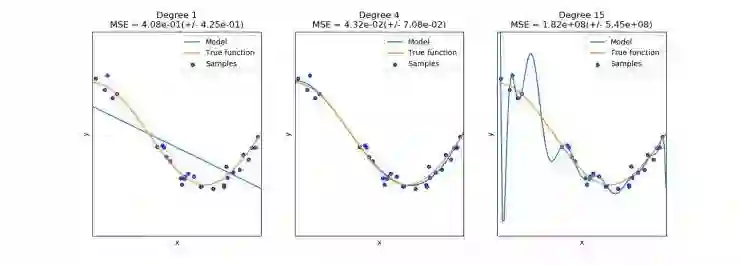
多项式特征生成:对于不尽其数的回归建模任务,在输入数据中考虑非线性特征来增加模型的复杂性是有用的。一个简单且常用的方法是使用多项式特征,可得到特征的高阶和交互项。Scikit-learn 有现成的函数,可根据给定的特征集和用户选择的最高多项式的程度生成高阶的交叉项。
数据集生成器:Scikit-learn 包含各种随机样本生成器,可用于构建给定大小和复杂度的人工数据集。它具有分类,聚类,回归,矩阵分解和多种测试的函数。
实践交互式机器学习
在 2014 年 Jupyter 项目于脱胎于 IPython 项目,并迅速演变为支持所有主流编程语言的交互式数据科学和科学计算的笔记本。毫无疑问,它在帮助数据科学家快速测试,为他/她的想法创建原型,展示成果给同行和开源社区等方面带来巨大影响。
然而,只有当用户能够交互式地控制模型参数并实时看到效果(几乎)的时侯,学习和测试数据才变得真正浸润其中。Jupyter 中大多数呈现都是静态的
但是你需要更多控制,你想通过简单的滑动鼠标而不是通过编写 for 循环改变变量。该怎么办?你可以使用 IPython 的插件。
插件是重要的 python 组件,它通过浏览器有所体现,通常作为一个前端 (HTML/JavaScript) 呈现通道控件,如滑块、文本框等。
本文我演示使用简单插件完成基础的曲线拟合练习。后续文章将进一步扩展到交互式及其学习技术领域。
深度学习框架
本文介绍使用 Python 探索机器学习奇妙世界的重要技巧。但它不包括 TensorFlow,Keras 或 PyTorch 等深度学习框架,因为它们每一个都需要深入讨论。您可以在这里阅读一些关于上述主题的非常棒的文章,但稍后我们可能会对这些惊艳的框架进行专门讨论。
7 great articles on TensorFlow (Datascience Central)
https://www.datasciencecentral.com/profiles/blogs/9-great-articles-about-tensorflow
Datacamp tutorial on neural nets and Keras example
https://www.datacamp.com/community/tutorials/deep-learning-python
AnalyticsVidhya tutorial on PyTorch
https://www.analyticsvidhya.com/blog/2018/02/pytorch-tutorial/
总结
文章不可能覆盖机器学习主题的全部内容(即使是一小部分)。但是,希望这篇文章能激发你的兴趣,也为你提供 Python 生态系统中已存在一些强大框架的明确指针,确保开始你的机器学习之旅。
博客原址:
https://heartbeat.fritz.ai/some-essential-hacks-and-tricks-for-machine-learning-with-python-5478bc6593f2
近期热文
广告、商业合作
请添加微信:guodongwe1991
(备注:商务合作)



