在 12 月 20 日举行的「WAVE SUMMIT+ 2020 深度学习开发者峰会」上,飞桨平台交出了一份非常亮眼的年终成绩单。
2020 年,是不平凡的一年:这一年,人工智能全面进入落地期,与各行业深度融合,也更加深刻地改变了人类社会。
数以千万计的开发者,正扮演着越来越重要的角色。像百度飞桨这样的产业级深度学习平台,也为产业智能化贡献着更多的力量。
本届峰会,百度飞桨带来八大全新发布与升级,
有支持前沿技术探索和应用的生物计算平台 PaddleHelix 螺旋桨,开发更加便捷的飞桨开源框架 2.0 RC 版,端云协同的 AI 集成开发环境 BML CodeLab,支持更强大分布式训练的业界首个通用异构参数服务器架构,开源算法库增至 200+,飞桨企业版 EasyDL 智能数据服务升级,飞桨硬件生态路线图以及携手全球开发者开启「大航海」计划。可见飞桨技术与生态发展的步调越来越快
。
飞桨是一个开源的平台,既受益于开源,也反过来促进了开源社区的发展。在谈到开源开放的重要性时,百度 CTO 王海峰表示,「开源开放对人类社会过去几百年科学和技术的发展起到非常重要的作用,让我们可以更快追踪到最新的技术进展,并将改进意见以及创新思想迅速进行反馈,形成一个正循环,进一步推动科技的创新迭代。当下,中国开源力量正在影响全球的科技创新。同时,在以深度学习为代表的人工智能发展浪潮中,产业界已经成为驱动开源开放的重要力量。而成熟的开源开放技术生态与开放平台,也正在推动社会各界加快融合发展。」
![]()
关于飞桨,王海峰分享了几个重要的数字:从今年 5 月份的「WAVE SUMMIT 2020」深度学习开发者峰会到现在,飞桨平台的开发者数量实现了大幅度的增长,达到了 265 万。基于 34 万多个模型,飞桨平台已经服务了超过 10 万家企业。
这是在飞桨平台与开发者的共同努力下,短短半年内取得的卓越成绩,且它的未来更加可期。
接下来,让我们打开百度飞桨这份 2020 年度成绩单。
人工智能是新一轮科技革命和产业变革的重要驱动力量,飞桨在这场时代变革中成为了承载体。作为 AI 开发的基础设施,飞桨和人工智能一起在向更多的行业、地域和领域发挥着价值。在人工智能技术和生物计算领域的结合上,百度已经做出了一系列尝试和探索。
在本次的 Wave Summit + 峰会上,百度正式发布了生物计算平台「PaddleHelix 螺旋桨」。这个人工智能和生物计算领域结合的平台,是飞桨的一次「跨界」。
![]()
该平台先期将开源螺旋桨生物计算开源工具集,提供包括 RNA 二级结构预测、大规模的分子预训练、DTI 药物靶点亲和力预测以及 ADMET 成药性预测等在内的新药研发和疫苗设计环节的核心能力,帮助生物信息学、计算机交叉学科背景的学习者、研究者和合作伙伴,更便利地构建 AI 算法模型。
编程一致、动静统一:飞桨开源框架迎来 2.0RC 版本
作为国内开源最早、技术领先、功能完备的产业级深度学习平台,飞桨一直在进行迅速地迭代。在本次的 Wave Summit + 峰会上,百度深度学习技术平台部高级总监马艳军宣布:
飞桨开源框架 2.0RC 版本正式发布
。
![]()
经过两年的研发,新版本能够给开发者带来「编程一致、动静统一」的全新开发体验。这一体验的实现,离不开飞桨在以下几个方向的重要创新和升级。
目前深度学习框架主要有声明式编程和命令式编程两种方式,对应静态图和动态图两种编程范式。静态图模式能够对整体性做编译优化,更有利于性能的提升,而动态图则非常便于用户对程序进行调试。
为了兼顾两种编程范式的优势,飞桨 2.0RC 将
默认的开发模式正式升级为动态图模式
。开发者可以随时查看变量的输入、输出,方便快捷地调试程序,还可以使用 Python 原生的控制流(如:if,for 等)灵活组网。
然而,动态图的模型在使用 C++ 部署时会面临巨大的挑战。对此,新版飞桨提供了
完备的动转静支持
,在 Python 语法支持覆盖度上达到领先水平。在动态图编程调试的过程中,开发者仅需添加一个小小的装饰器,就可以无缝平滑地自动转静态图训练部署。同时,2.0RC 版本的飞桨还做到了模型存储和加载的接口统一,保证动转静之后保存的模型文件能够被纯动态图加载和使用。
如果说深度学习框架是开发者们在 AI 海洋中乘风破浪的动力引擎,那么 API 就是这个引擎的控制面板上的按钮,是深度学习框架威力发挥的直接入口。飞桨开源框架 2.0RC 版本升级了整个 API 体系,使其更加简洁、系统,还能向前兼容。
整体来看,新版飞桨包含 19 大类 API,功能上也进行了全面增强,尤其是分布式训练相关的 API。常用的通信策略和启动方式等操作,以及原先分散在各处的分布式优化策略相关的 API 被统一归纳到 paddle.distributed.fleet 之下,形成了 Fleet API。这样的话,开发者只需要通过这些接口去做简单的配置,就能做分布式训练。此外,新版飞桨还新增了 200 多个 API,提升了整体开发体验。
在开发过程中,开发者往往需要以一种更加简单、快捷的方式应用 API,完成数据增强、建立数据流水线等可以标准化的工作流程。针对这个需求,新版飞桨提供了更适合低代码编程的高层 API,允许开发者用 10 行代码编写完成训练部分的程序。而且,这些高层 API 和基础 API 可以灵活地交叉使用,让开发者在简捷开发与精细化调优之间自由定制,改变了很多开源框架高层 API 和基础 API 割裂的局面。
说到这里,很多开发者可能会问,这个新的 API 体系迁移成本高不高?马艳军在会场强调,「我们是完全向前兼容的」。此外,飞桨还提供了专门的迁移工具和新旧版本的 API 对照表,以降低开发者的迁移成本。
飞桨 2.0RC「编程一致,动静统一」的编程体验对深度概率编程、量子机器学习开发等前沿技术研究也有巨大的支撑作用。
此次大会上,清华大学计算机系教授、深度学习技术及应用国家工程实验室副主任朱军介绍了
珠算
深度概率编程与百度飞桨的合作,依托飞桨框架成熟的底层功能和动静统一的开发体验,更好地支持深度概率编程工具开发和前沿技术探索。
在设计上,珠算底层复用了飞桨框架的核心能力,实现了动态图编程。它还基于飞桨的全新 API 体系实现了进一步的丰富和扩展,增加了 BayesianNet、StochasticTensor 等特色组件,丰富了底层概率库,让开发者能够轻松地完成深度生成模型建模、变分推断、蒙特卡洛采样等应用,有力支持了深度概率编程领域的研究与探索。
在
量子机器学习开发
方面,飞桨框架新增了对复数计算方面的支持,成倍地提升了复数运算的效率,基础复数运算速度最高可提升 22.3 倍。此外,飞桨还优化了复数 Tensor 运算的写法,简化了使用量桨开发模型的代码实现规模,助力量桨进一步提升了性能和易用性。
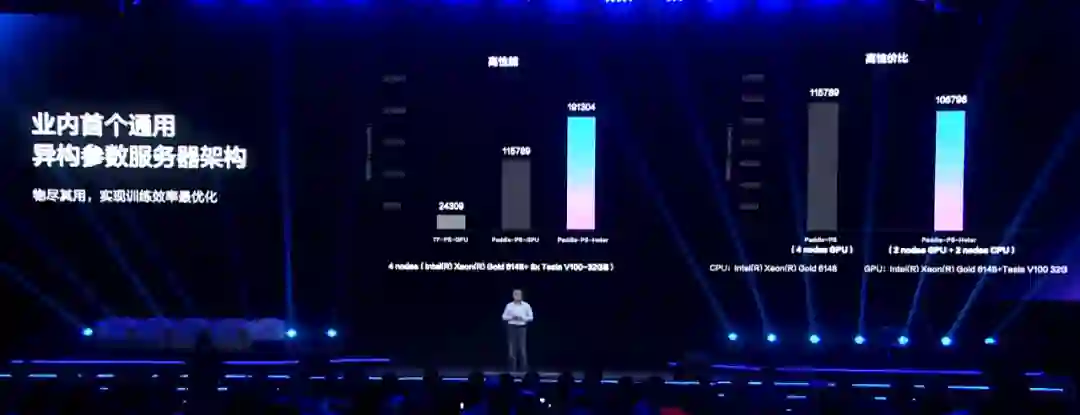
伴随着 2.0RC 版本的发布,飞桨还宣布了大规模分布式训练的升级,正式推出
业内首个通用异构参数服务器架构
。
在搜索推荐领域,模型通常具有大规模稀疏特征,训练时是一个 IO 密集型任务。这种任务适合用 CPU 搭建的参数服务器架构来完成。但为了追求更好的效果,开发者通常需要在推荐模型中增加越来越多的复杂网络结构,使得训练算力成为瓶颈。
算力不够,加 GPU 行不行?首先,传统服务器架构往往要求硬件类型一致,无法加入算力较强的 GPU 等硬件。其次,GPU 等硬件不擅长 IO 密集型任务,因此我们也不能用 GPU 完全取代原来的硬件。
在这种背景下,飞桨推出了首个异构服务器训练架构,实现了异构硬件的自由混布,能够实现数据的独立存取传输,大幅提高了数据吞吐量。此外,它还通过流水线机制提高了训练速度,通过多种通信策略提高了带宽的利用率。
测试结果表明,
在相同的硬件条件下,飞桨的异构参数服务器架构比单纯的非异构参数服务器架构性能提升了 65% 以上
。
![]()
开源算法库的升级也是新版飞桨的一个重大更新。新版飞桨官方支持的算法从 140 +个扩充到 200 + 个,涉及各个领域,而且都升级到了动态图实现。
![]()
除了以上发布的全新内容外,飞桨企业版还迎来了两大新特性的发布。
很多 AI 开发者都遇到过「想做模型训练,本地机器资源不够用」、「租云服务器好贵,机型少不稳定」等问题。基于开发者的痛点,百度飞桨企业版推出了全新的端云协同 AI 集成开发环境——BML CodeLab。
![]()
BML CodeLab 在基于 JupyterLab 优秀功能的基础上,引入了微软 Monaco Editor-VSCode 的编码体验,支持任何编程语言的代码补全、用法提示、多光标等 IDE 功能,实现了 50 多个体验优化项。
为了达到开箱即用的效果,BML CodeLab 集成了许多高性能的 AI 工具组件,比如高性能单机引擎,相比开源 Pandas/Sklearn 加速性能平均高 6 倍以上;还有飞桨文心 (ERINE)NLP 开发套件,将数据标注、算力投入、开发时长等成本大幅降低。
另一个非常有特色的功能是端云协同。BML CodeLab 可通过云端仓库把本地的代码、数据、模型上传到云端,在大数据量和大计算量的情况下,将本地任务无缝扩展到云端。
随后,百度 AI 平台研发部总监忻舟介绍了智能数据服务 EasyData 的升级。
在智能数据标注方面,EasyData 通过核心算法、算法流程、硬件的升级,将智能标注的时长平均减少了 74%,在物体检测和图像分割上的准确率分别提升了 6.4 和 3.2 个点。
EasyData 的多人标注功能能够解决数据分发、标注结构审核等问题,将数据集和标签管理进行了拆分,让开发者更加灵活地使用数据。
第三个新特性是高级智能清洗,可自动过滤无人脸、无人体的数据,广泛应用于安全生产、视频监控等场景。
此外,飞桨的生态建设离不开广大的生态伙伴。为了加快生态建设,飞桨在 5 月份发布了硬件生态圈共建计划。在半年之后的今天,马艳军宣布:
飞桨硬件生态路线图正式发布
。
![]()
从图中可以看出,整个飞桨已经与 20 家硬件企业达成合作,目前正在适配和已经完成适配的芯片和 IP 的型号已经有 29 种,并且在国产硬件的支持方面遥遥领先,加速了国产 AI 产业链适配升级。
产业共进、人才共育、开源共建:AI 大咖共话未来发展
开源以来,飞桨一直秉持开源开放、技术创新,产学研用通力融合,从产业应用、人才培养、开源社区三个维度全面推进生态繁荣,助力产业智能化升级。在本次的 Wave Summit + 大会中,多位大咖围绕「产业共进」、「人才共育」、「开源共建」探讨了深度学习的未来发展问题。
在「产业共进」环节,宁德时代智能制造部部长张伟和昆仑数智科技有限公司人工智能与物联网技术总监卫乾分享了应用经验,并与其他十个项目一起获得了「飞桨产业应用创新奖」。
在「人才共育」环节,百度研究院大数据实验室和商业智能实验室主任窦德景主持了一场圆桌论坛,邀请北京大学信息科学技术学院教授黄铁军、北京航空航天大学计算机学院教授王蕴红、中国人民大学信息学院院长文继荣分享他们在 AI 人才培养方面的经验和见解。深度学习领域颇受欢迎的「精灵宝可梦大师」李宏毅作为首批入驻 AI Studio 的名师,也加入现场连线与大家分享了如何「如何高效掌握深度学习」这一话题。
在「开源共建」环节的圆桌论坛上,百度飞桨总架构师于佃海邀请了复旦大学计算机科学技术学院教授邱锡鹏、北京大学信息科学与技术学院前沿计算研究中心助理教授董豪、PreAngel 合伙人李卓桓、Zilliz 创始人兼首席执行官星爵等人共同探讨了 AI 开源项目的创建与维护经验。
![]()
如何打造一个成功的 AI 开源项目?嘉宾们认为,首先要保证实现「生态」和「技术」两个闭环,做开源项目和创业十分相似,找到一个好的「选题」是重中之重,而项目成员的多样性,能够促使项目后期去探索无限的可能性,此外还需要一群优质的、多元化的开发贡献者。
开源开放的飞桨促进了 AI 产学研社区的发展壮大。其实,这不仅是我们的主观感受,还体现在飞桨平台的一些数据中。在大会上,百度集团副总裁吴甜为我们解读了其中的一些数据。
在产业方面,飞桨平台上的应用品类明显增加,非互联网 IT 行业占比从 53.4% 增长至 67.9%;在社区方面,全国开发者 AI 热情升温,过去一年增速 TOP5 城市分别是佛山、东莞、重庆、福州和天津;在教学方面,越来越多的高校老师开始关注 AI 课程,非计算机专业高校教师占比从 2019 年的 35% 增长到 2020 年的 45%。
当然,AI 社区的持续壮大离不开人才培养。而在这方面,基于在产品、技术、生态各个方面的积累,飞桨已经准备就续,准备全面开启大航海计划。
大航海计划包括领航、启航和护航三个部分,领航计划面向核心开发者群体,践行开源布局理念,永当 AI 时代的先行者,领航前行。护航计划面向产业界,通过企业培训、技术咨询、技术服务等方式护航企业智能化转型,启航计划面向人才培养,通过校企合作、产教融合开启 AI 人才培养的新篇章。在本次峰会上,飞桨正式发布了启航计划,预计在未来三年投入总价值 5 亿元的资金与资源,支持全国 500 所高校,联合培养 50 万关键 AI 人才。
在峰会上,百度、LF AI&DATA 基金会、深度学习技术及应用国家工程实验室也联合为 97 位飞桨社区核心开发者颁发了「PPDE 飞桨开发者技术专家」证书,作为对开源开放工作的鼓励与支持。
百度副总裁徐菁现场为AI濒危物种保护项目、AI 文物保护项目、AI 沙漠栽树机器人项目三支团队颁发了 2020 年度 AI 公益合作项目证书并授予星辰计划基金。
![]()
左上:王爱华、吴甜为产业应用奖获奖项目颁奖、右上:徐菁颁发星辰计划基金;左下 & 右下:张伟民、朱军为飞桨技术开发者技术专家颁发证书
时隔半年,人们再次见证了百度飞桨在开源开放之路上的巨大进步。驱动这种核心力量的正是每一位飞桨平台的开发者,265 万飞桨开发者的每一步,都将推动中国人工智能领域走向全新的方向。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com