盘一盘 Python 系列 3 - SciPy

本文是 Python 系列的第五篇
科学计算之 SciPy
数据结构之 Pandas
基本可视化之 Matplotlib
统计可视化之 Seaborn
交互可视化之 Bokeh
炫酷可视化之 PyEcharts
机器学习之 Sklearn
深度学习之 TensorFlow
深度学习之 Keras
深度学习之 PyTorch
深度学习之 MXnet
SciPy 是 Python 里处理科学计算 (scientific computing) 的包,使用它遇到问题可访问它的官网 (https://www.scipy.org/). 去找答案。 在使用 scipy 之前,需要引进它,语法如下:
import scipy这样你就可以用 scipy 里面所有的内置方法 (build-in methods) 了,比如插值、积分和优化。
numpy.interpolatenumpy.integratenumpy.optimize
但是每次写 scipy 字数有点多,通常我们给 scipy 起个别名 sp,用以下语法,这样所有出现 scipy 的地方都可以用 sp 替代。
import scipy as spSciPy 是建立 NumPy 基础上的,很多关于线性代数的矩阵运算在 NumPy 都能做,因此就不重复在这里讲了。此外在〖数组计算之 NumPy (下)〗也说过,数组计算比矩阵计算更通用,
本章换一种写法,我们专门针对科学计算中三个具体问题来介绍 SciPy,它们就是
插值 (interpolation)
积分 (integration)
优化 (optimization)
对于以上每一个知识点我都会介绍一个
简单例子来明晰 SciPy 里各种函数的用法
和金融相关的实际例子
计算远期利率:在零息曲线中插值折现因子
计算期权价格:将期望写成积分并数值求解
配置资产权重:优化「风险平价」模型权重
给定一组 (xi, yi),其中 i = 1, 2, ..., n,而且 xi 是有序的,称为「标准点」。插值就是对于任何新点 xnew,计算出对应的 ynew。换句话来说,插值就是在标准点之间建立分段函数 (piecewise function),把它们连起来。这样给定任意连续 x 值,带入函数就能计算出任意连续 y 值。
在 SciPy 中有个专门的函数 scipy.interpolate 是用来插值的,首先引进它并记为 spi。
import scipy.interpolate as spi用 scipy.interpolate 来插值函数 sin(x) + 0.5x。
首先定义 x 和函数 f(x):
x = np.linspace(-2 * np.pi, 2 * np.pi, 11)f = lambda x: np.sin(x) + 0.5 * xf(x)
array([-3.14159265, -1.56221761, -1.29717034, -1.84442231,
-1.57937505, 0. , 1.57937505, 1.84442231,
1.29717034, 1.56221761, 3.14159265])接下来介绍 scipy.interpolate 里面两大杀器:splrep 和 splev。两个函数名称都是以 spl 开头,全称 spline (样条),可以理解这两个函数都和样条有关。不同的是,两个函数名称以 rep 和 ev 结尾,它们的意思分别是:
rep:representation 的缩写,那么 splrep 其实生成的是一个「表示样条的对象」
ev:evaluation 的缩写,那么 splev 其实用于「在样条上估值」
splrep 和 splev 像是组合拳 (one two punch)
前者将 x, y 和插值方式转换成「样条对象」tck
后者利用它在 xnew 上生成 ynew
一图胜千言:

接下来仔细分析一下 tck。
tck = spi.splrep( x, f(x), k=1 )tck

tck 就是样条对象,以元组形式返回,tck 这名字看起来很奇怪,实际指的是元组 (t, c, k) 里的三元素:
t - vector of knots (节点)
c - spline cofficients (系数)
k - degree of spline (阶数)
对照上图,tck 确实一个元组,包含两个 array 和一个标量 1,其中
第一个 array 是节点,即标准点,注意到一开始 x 只有 11 个,但现在是 13 个,首尾都往外补了一个和首尾一样的 x
第二个 array 是系数,注意它就是 y 在尾部补了两个 0
标量 1 是阶数,因为在调用 splrep 时就把 k 设成 1
注:前两个 array 我只是发现这个规律,但解释不清楚为什么这样。它和 matlab 里面的 spline() 的产出不太一样,希望懂的读者可以留言区解释一下。
虽然解释不清楚前两个 array,那就把 tck 当成是个黑匣子 (black-box) 直接用了。比如可用 PPoly.from_spline 来查看每个分段函数的系数。
pp = spi.PPoly.from_spline(tck)pp.c.T
array([[ 1.25682673, -3.14159265],
[ 1.25682673, -3.14159265],
[ 0.21091791, -1.56221761],
[-0.43548928, -1.29717034],
[ 0.21091791, -1.84442231],
[ 1.25682673, -1.57937505],
[ 1.25682673, 0. ],
[ 0.21091791, 1.57937505],
[-0.43548928, 1.84442231],
[ 0.21091791, 1.29717034],
[ 1.25682673, 1.56221761],
[ 1.25682673, 3.14159265]])tck 的系数数组里有 13 个元素,而上面数组大小是 (12, 2),12 表示 12 段,2 表示每段线性函数由 2 个系数确定。
把 x 和 tck 丢进 splev 函数,我们可以插出在 x 点对应的值 iy。
iy = spi.splev( x, tck )iy
array([-3.14159265, -1.56221761, -1.29717034, -1.84442231,
-1.57937505, 0. , 1.57937505, 1.84442231,
1.29717034, 1.56221761, 3.14159265])用 Matplotlib 来可视化插值的 iy 和原函数 f(x) 发现 iy 都在 f(x) 上。Matplotlib 是之后的课题,现在读者可忽略其细节。


除了可视化,我们还可以用具体的数值结果来评估插值的效果:
np.allclose(f(x), iy)np.sum((f(x) - iy) ** 2) / len(x)
True
0.0第一行 allclose 的结果都是 True 证明插值和原函数值完全吻合,第二行就是均方误差 (mean square error, MSE),0.0 也说明同样结果。
上面其实做的是在「标准点 x」上插值,那得到的结果当然等于「标准点 y」了。这种插值确实意义不大,但举这个例子只想让大家
明晰 splrep 和 splev 是怎么运作的
如何可视化插出来的值和原函数的值
如何用 allclose 来衡量插值和原函数值之间的差异
一旦弄明白了这些基础,接下来就可以秒懂更实际的例子了。
上面在「标准点 x」上插值有点作弊,现在我们在 50 个「非标准点 xd」上线性插值得到 iyd。
xd = np.linspace( 1.0, 3.0, 50 )iyd = spi.splev( xd, tck )print( xd, '\n\n', iyd )

密密麻麻的数字啥都看不出来,可视化一下把。


这插得是个什么鬼?红色插值点在第二段和深青色原函数差别也太远了吧 (MSE 也显示有差异)。
np.sum((f(xd) - iyd) ** 2) / len(xd)0.011206417290260647问题出在哪儿呢?当「标准点 x」不密集时 (只有 11 个),分段线性函数来拟合 sin(x) + 0.5x 函数当然不会太好啦。那我们试试分段三次样条函数 (k = 3)。
tck = spi.splrep( x, f(x), k=3 )iyd = spi.splev( xd, tck )
可视化一下并计算 MSE 看看

np.sum((f(xd) - iyd) ** 2) / len(xd)1.6073247177220542e-05视觉效果好多了!误差小多了!
用 scipy.interpolate 来插值折现因子来计算远期利率。
在金融市场中,每个货币都有自己相对应的折现曲线,简单来说,就是在「标准日期」上一组折现因子 (discount factor) 或零息利率 (zero rate)。

那么在「非标准日期」上折现因子或零息利率怎么求呢?插值!
本小节的知识点内容来之〖弄懂金融十大话题 (上)〗。
这里面说的插值是分段 (piecewise) 插值!对于线性插值,不是说一条直线拟合上表的 9 个点,这样也是不可能做到的。但是分段线性插值就可以完美解决这个问题,因为 9 个点,有 8 段,每一段首尾两个点,可以连一条直线,全部点之间连起来不就是分段线性插值吗?三种最常见的插值方法
分段常函数
分段线性函数
分段三次样条函数
首先给出数学符号。给定 N 数据点 (xi, fi), i = 1, 2, …, N,其中 x1 < x2 < ... < xN 。我们希望找到一个函数 f(x) 来拟合这 N 个数据点,对于分段函数,因为有 N 个数据点,需要 N -1 段函数。
分段常 (piecewise constant) 函数
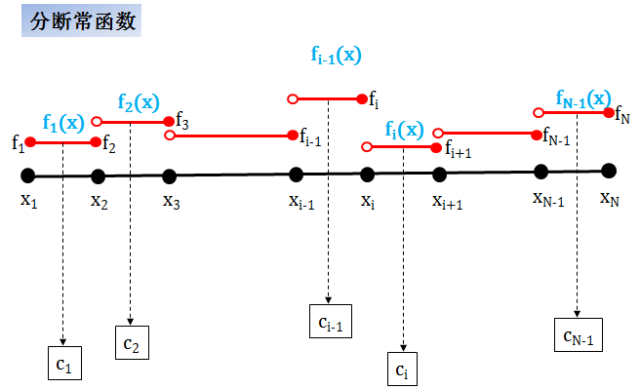
在这种情况,每一段函数都是一个常数,这种插值方法
优点是简单
缺点是在数据点上不连续,更不可导
适用于在某些模型的参数 (比如 Heston 模型中的均值回归率和波动率的波动率) 上插值 (模型参数通常只用常数和分段常函数,但后者比前者能更好的拟合市场数据,因为它有更多自由度)。
不适用于曲线和波动率插值
分段常函数不连续,通常称作 C-1 函数。
分段线性 (piecewise linear) 函数
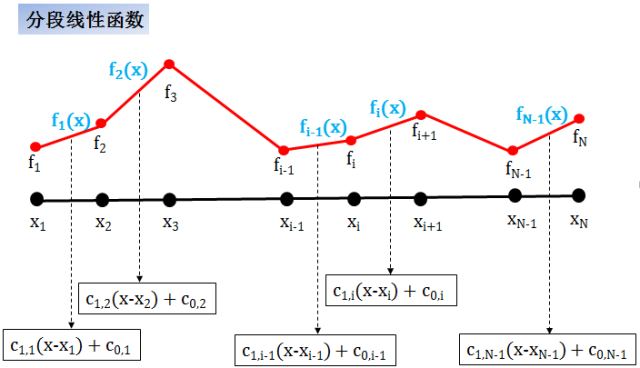
在这种情况,每一段函数都是一个线性函数,这种插值方法
优点是简单,在数据点上连续,而且形状保持性很好 (插出的值只和它相邻两个数据点有关,别的数据怎么动都不影响它的插值)
缺点是在数据点上不可导
适用于曲线和波动率插值
不适用于在 Hull-White 模型下的曲线插值 (Hull-White 模型需要对曲线求二阶导)
分段线性函数连续但是不可导,通常称作 C0 函数。
分段三次样条 (piecewise cubic spline) 函数
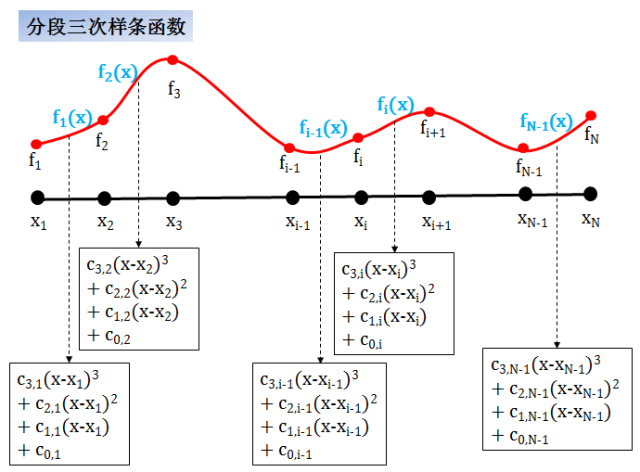
在这种情况,每一段函数都是一个三次多项式函数,这种插值方法
优点是在数据点上可导甚至可导三次 (非常平滑)
缺点是有些复杂,而且形状保持性不好 (插出的值和整个数据点有关,别的数据动以下都会影响它的插值)
适用于曲线的插值
分段三次样条函数连续而且二阶可导,通常称作 C2 函数。
对上面曲线插值有一个概念后,首先用 pandas 读取数据。Pandas 是下帖内容,你就先把它当成一个可以用字符串来索引或切片的二维数据结构。
import pandas as pdcurve = pd.read_excel('CNY zero curve.xlsx')curve

该曲线用于估值日 2019-04-01,上图第一个点的日期是 2019-04-03,通常称为即期日,往后的日期分别是从即期日开始往后推 1W, 1M, 2M, 3M, 6M, 9M, 1Y 和 2Y 得到的。
用 Matplotlib 来可视化折现因子和零息利率。


这里用了双 y 轴来区分折现因子和零息利率,左边是折现因子,右边是零息利率,其实通过观察 y 轴的数值也可以区分出来两者。
现在实际问题是要计算从起始日 2019-08-05 到终止日 2019-11-05 的 3M 远期利率,根据其公式 (不推导):

要计算远期利率,核心问题就是计算 2019-08-05 和 2019-11-05 两天的折现因子。为了简化,我们把这两天之间的年限差近似定为 0.25 ≈ 3个月/12个月。具体步骤如下:
计算曲线上「标准日期」到「估值日」之间的天数差
计算「起始日」和「终止日」到「估值日」之间的天数差
插出「起始日」和「终止日」上的折现因子 (四种方法)
将折现因子带入公式计算远期利率
第一步:计算曲线上「标准日期」到「估值日」之间的天数差
today = pd.Timestamp('2019-04-01')daydiff = curve['Date'] - todaydaydiff
0 2 days
1 9 days
2 32 days
3 63 days
4 93 days
5 185 days
6 277 days
7 368 days
8 733 days
Name: Date, dtype: timedelta64[ns]上面结果不是数值型变量 (还带个 days),用 .dt.days.values 得到相应的 numpy 数组。
d = daydiff.dt.days.valuesd
array([ 2, 9, 32, 63, 93,
185, 277, 368, 733], dtype=int64)第二步:计算「起始日」和「终止日」到「估值日」之间的天数差
import datetimestart = datetime.datetime.strptime('2019-08-05','%Y-%m-%d')end = datetime.datetime.strptime('2019-11-05','%Y-%m-%d')d_s = (start - today).daysd_e = (end- today).daysprint( d_s, d_e )
126 218需要引进 datetime 这个库将字符型日期转成真正的 date 格式。
第三步:插出「起始日」和「终止日」上的折现因子,有多种方法,不同数据商对不同曲线也有不同的设置,常见的四种有:
在折现因子上线性插值
在折现因子上三次样条插值
在 ln(折现因子) 上线性插值
在零息曲线上线性插值,再计算折现因子
tck = spi.splrep( d, curve['Discount Factor'], k=1 )DF_s = spi.splev( d_s, tck )DF_e = spi.splev( d_e, tck )print( DF_s, DF_e )
0.9909485166188177 0.9828538249018102splrep 里面 k 设为 1 表示线性插值。
tck = spi.splrep( d, curve['Discount Factor'], k=3 )DF_s = spi.splev( d_s, tck )DF_e = spi.splev( d_e, tck )print( DF_s, DF_e )
0.9909572012597055 0.9827493083500931splrep 里面 k 设为 3 表示三次样条插值。
tck = spi.splrep( d, np.log(curve['Discount Factor']), k=1 )DF_s = np.exp(spi.splev( d_s, tck ))DF_e = np.exp(spi.splev( d_e, tck ))print( DF_s, DF_e )
0.9909402218834239 0.9828472942639631把 ln(DF) 放入 splrep 中,插出来也是 ln 形式,要最终得到折现因子,还需要用 exp 函数还原。
tck = spi.splrep( d, curve['Zero Rate (%)'], k=1 )r_s = spi.splev( d_s, tck )r_e = spi.splev( d_e, tck )DF_s = np.exp(-d_s/365 * r_s/100)DF_e = np.exp(-d_e/365 * r_e/100)print( DF_s, DF_e )
0.9921606726777862 0.9843810241053533插出来的零息利率,需要用以下公式计算出折现因子
DF = exp( -d/365 × r/100)
d 除以 365 转换成年限,r 除以 100 是因为 r 单位是 %。
第四步:将折现因子带入公式计算远期利率
F = 0.25*(DF_s/DF_e - 1) * 100第三步中四种方法计算出来的远期利率 (%) 为
DF 上线性插值 - 2.059%
折DF 上三次样条插值 - 2.088%
ln(DF) 上线性插值 - 2.059%
Rate 上线性插值 - 1.976%
四个远期利率差别都不大,业界使用较多的是第 3 和 4 种。
在 SciPy 中有个专门的函数 scipy.integrate 是用来做数值积分的,首先引进它并记为 sci。
import scipy.integrate as sci用 scipy.integrate 来对函数 sin(x) + 0.5x 求积分。
首先定义被积函数 f(x):
f = lambda x: np.sin(x) + 0.5 * x假设我们想从 x= 0.5 到 9.5 对 f(x) 求积分,可以手推出

在 scipy.integrate 里还有些数值积分的函数:
fixed_quad:fixed Gaussian quadrature (定点高斯积分)
quad:adaptive quadrature (自适应积分)
romberg:Romberg integration (龙贝格积分)
trapz:用 trapezoidal 法则
simps:用 Simpson’s 法则
前三个函数 fixed_quad, quad, romberg 的参数是被积函数、下界和上界。代码如下:
sci.fixed_quad(f, a, b)[0]sci.quad(f, a, b)[0]sci.romberg(f, a, b)
24.366995967084602
24.374754718086752
24.374754718086713对后两个函数 trapz 和 simps,首先在上下界之间取 n 个点 xi,再求出对应的函数值 f(xi),再把当参数 f(xi) 和 xi 传到函数中。代码如下:
xi = np.linspace(a, b, 100)sci.trapz( f(xi), xi )sci.simps( f(xi), xi )
24.373463386819818
24.37474011548407和解析解 24.37475471808675 比较,quad 的结果最精确。一般当被积函数不规则时 (某段函数值激增),quad (自适应积分) 的结果也是最好。
用 scipy.integrate 来以数值积分的形式给欧式期权定价。
注:本节主要将数值积分的用途,因此金融模型上的很多设置我们都用最简单的,比如常数型的模型参数等等。
股票类的Black-Scholes (BS) 模型下的 SDE 是描述股票价格 (stock price) 的走势:

其中
S(t) = 股票价格
r = 瞬时无风险利率
σ = S(t)的瞬时波动率
B(t) = 布朗运动
欧式看涨期权 (call option) 在 BS 模型下的解析解 (closed-form solution) 如下:

编写一个程序计算 call 的解析解很容易:

这里需要引入 scipy.stats 下的 norm 库,使用里面 cdf 函数来计算正态分布的累积分布概率。
假设股价 S0 = 100,行权价格 K = 95,利率为 5%,期限为 1 年,波动率为 10%,带入写好的 bscall 函数来计算期权的价值。
(S0, K, r, T, sigma) = (100, 95, 0.05, 1, 0.1)bscall( S0, K, r, T, sigma )
10.405284289598569大概记注上面的期权值 10.4053。假设我们推导能力不强或者对于更复杂的期权没有解析解,只要知道 ST 的分布,我们可以试着把「期望值」写成「积分」形式,再用 x = lnST 做个转换,最终可推出下式:

为了求数值积分,我们需要知道 x 是如何分布,也就是推出 x 的密度分布函数 fX(x),推导如下 (不是本帖的重点,如无兴趣可跳过下框内容):
给定 S 的随机微分方程,首先用伊藤公式推出 lnS 的随机微分方程

在 0 到 T 两边求积分,整理得到 ST 的解。

其中 z 是标准正态分布变量 z ~ N(0, 1)。
用之前的变量转化 x = lnST 得到 x 的解。

显然 x 是个正态分布,均值为 lnS0 +(rT - 0.5σ2T),方差是 σ2T。用 NPDF 代表正态分布 (Normal) 的密度分布函数 (PDF),可把 call 的价值写成积分形式,其中
被积函数是「支付函数」和「正态分布密度分布函数 」的乘积
下界和上界分别是 lnK 和 +∞
最终表达式如下:

跟着「被积函数」的表达式敲代码
mu = np.log(S0) +(r*T-0.5*sigma**2*T)v = sigma*np.sqrt(T)f = lambda x: np.exp(-r*T) * (np.exp(x)-K) * norm.pdf(x,mu,v)
定义上界和下界
(lb, ub) = (np.log(K), 7)注意上界不要定义成 +∞。稍微分析下 x = lnST,当 ST= e7 ≈ 1097 对于 S0 = 100 已经很大了,因此上界设为 7 比较合理。
看看三个数值积分的结果如何。
sci.quad(f, lb, ub)[0]xi = np.linspace(lb, ub, 1000)sci.trapz( f(xi), xi )sci.simps( f(xi), xi )
10.405284289598615
10.405170993379011
10.405287100064612结果和之前的解析解 10.4053 都相当接近。
用数值积分来求解欧式期权的确有点多此一举 (ovekill),但很多复杂的产品是没有解析解的,除了用数值解的「偏微分方法有限差分法」和「蒙特卡洛法」,数值积分也是一种选择。
在 SciPy 中有个专门的函数 scipy.optimize 是用来优化的,首先引进它并记为 spo。
import scipy.optimize as spo优化问题可分为无约束优化 (unconstrained optimization) 和有约束优化 (constrained optimization),我们用简单例子来介绍前者,用金融例子来介绍后者。
用 scipy.optimize 来求出函数
sin(x) + 0.05x2 + sin(y) + 0.05y2
的最小值。
首先定义函数
f = lambda x,y: np.sin(x) + 0.05 * x**2 + np.sin(y) + 0.05 * y**2接着可视化函数


不难看出该函数有多个局部最小值 (local minimum) 和一个全局最小值 (global minimum)。我们目标是求后者,主要步骤如下:
在 (x-y) 定义域上选点,求出函数值 f(x, y),找出最小值对应的 x* 和 y*
用 x* 和 y* 当初始值,求出函数全局最小值
第一步:用蛮力找函数最小值以及对应的参数
之所以用「蛮力」一词,是因为接下来要用到 brute 函数,而 bruteforce 就是蛮力的意思。首先定义函数 fo (其实就是上面的 f),只不过 brute 函数要求用一个元组把若干参数集合起来。此外我们添加一个 print() 语句,为了检查中间产出。

将 x 和 y 在 -10 到 10 以步长为 5 来切片 (回顾切片是前闭后开的,因此切片完得到的是 -10, -5, 0, 5,而不包括 10 这个点)
output = Truerranges = ((-10, 10, 5), (-10, 10, 5))spo.brute(fo, rranges, finish=None)

从上面结果可看出,函数在 (0, 0) 是取最小值 0。真是最小值吗?我也不知道,但是以 5 为步长是不是太粗糙了些,接下来用 0.1 为步长。这时把 output 设为 False 是因为不想看到打印的内容。
output = Falserranges = ((-10, 10, 0.1), (-10, 10, 0.1))opt1 = spo.brute(fo, rranges, finish=None)opt1
array([-1.4, -1.4])fo(opt1)-1.7748994599769203当步长变小,我们能在更细的网格上计算函数值,这是函数在 (-1.4, -1.4) 取最小值 -1.7749,明显比函数在 (0, 0) 上的值 0 要小。
第二步:把参数当初始值,求函数全局最小值
如果网格足够密,上面 -1.7749 大概率是全局最小值而 (-1.4, -1.4) 是对应的最优解;如果网格不是足够密,那么以 (-1.4, -1.4) 当初始值,也能很大概率找到全局最小值。
用 fmin 函数,将刚才 opt1 传进去,并设定 x 和 f 的终止条件 xtol 和 ftol,和最多迭代次数 maxiter 和最多运行函数次数 maxfun。
output = Trueopt2 = spo.fmin( fo, opt1, xtol=0.001, ftol=0.001,maxiter=15, maxfun=20 )opt2

此时最优解为 (-1.42702972, -1.42876755),而对应的函数值为
output = Falsefo(opt2)
-1.7757246992239009比刚才函数在 (-1.4, -1.4) 取的最小值 -1.7749 又小了一些。
好的初始值对求函数的最优解影响比较大。假设我们无脑的用 (2, 2) 当初始值,看看会发生什么。
output = Falseopt3 = spo.fmin(fo, (2, 2), maxiter=250)opt3
Optimization terminated successfully.
Current function value: 0.015826
Iterations: 46
Function evaluations: 86
array([4.2710728 , 4.27106945])求得函数在 (4.2710728, 4.2710728) 取的最小值 0.015826,是不是错的太离谱了。
用 scipy.optimize 来用「风险平价」模型为资产配置最优权重。
本小节的知识点内容来自〖资产配置〗。
投资组合的资产配置是个很重要的课题,投资者为了最大化回报或最小化风险,可以给各种资产配置不同的权重。本节我们看一个很流行的资产配置方法 - 风险平价 (Risk Parity, RP)。但首先我们先来看看它的通用版本,风险预算 (Risk Budgeting, RB)。
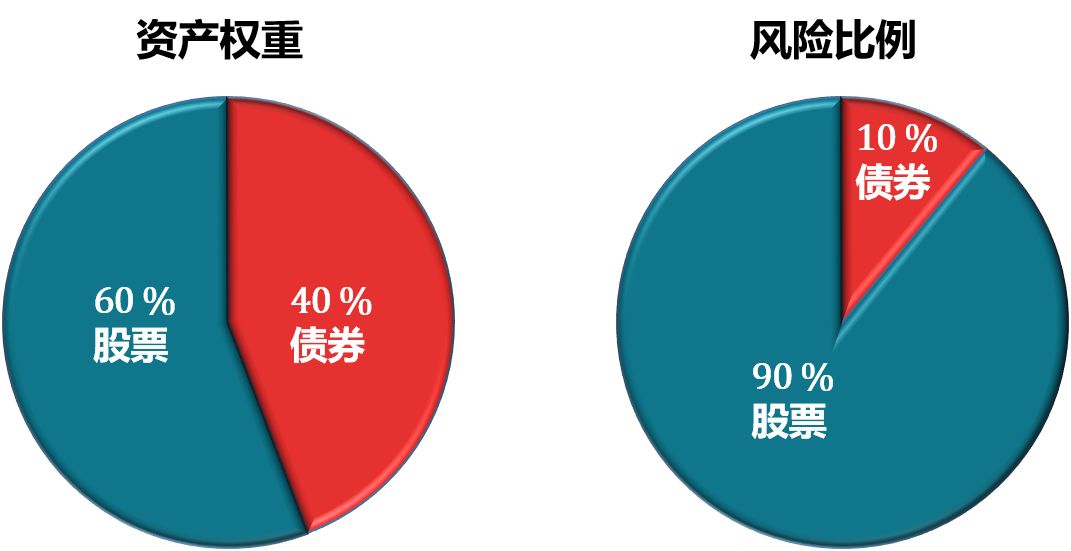
传统的 FW 模型把 60% 分给股票而 40% 分给债券,但是这样的一个投资组合 90% 的风险都来自股票只有 10% 的风险来自债券。那么这个组合更容易出现股票尾部风险 (tail risk)。一个风险更均衡的投资组合应该选择配置更多债券 (比如 75%) 和更少股票 (比如 25%),如下图所示。
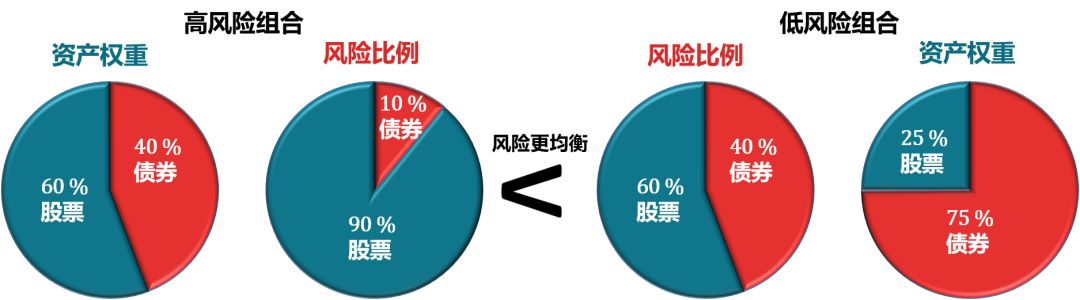
RB 模型的思路就是通过分配风险 (上图的风险比例) 来影响权重 (上图的资产权重),通常是给风险低的资产 (如债券) 高风险配额,而风险高的资产 (如股票) 低风险配额。
接下来我们看看 RB 模型的数学公式吧,首先回顾组合风险
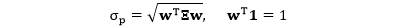
对于第 i 个资产,其边际风险贡献 (Marginal Risk Contribution, MRC) 是该资产权重 wi 的微小变化对组合风险 σp 所带来的影响。用数学公式表示就是对 σp 求 wi 的偏导数。
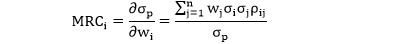
第 i 个资产的总体风险贡献 (Total Risk Contribution, TRC) 是其 MRC 乘以其权重,顾名思义,这个总体贡献一方面来自 MRC,一方面来自权重,数学表达式为:
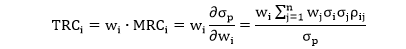
根据 TRCi 的定义,即第 i 个资产对总体风险的贡献,可推出它们总和应该等于组合风险 sp,从数学上也可证实此关系
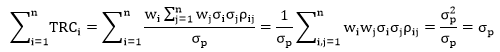
上式两边同时除以 σp,并定义风险预算 si 为 TRCi 的占比,可得 sT1 = 1
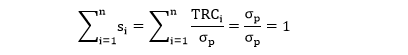
由上式看出 si 也类似于权重,只不过是风险上的权重,而 wi 是资产上的权重。下面给出 si 和 wi 之间的关系
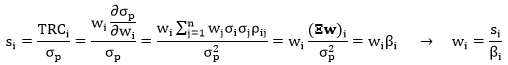
在 RB 模型中,股票权重等于风险预算除以贝塔,因此,RB 模型依赖于贝塔的预测质量。归一化之后的权重等于

事先将一组风险预算分配好,例如 s = [20%, 30%, 50%],再数值解下面序列二次规划 (Sequential Quadratic Programming, SQP) 问题可以得到 RB 模型下的最佳权重
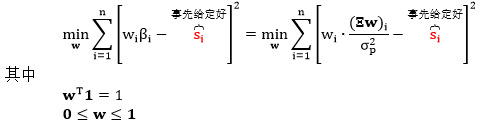
风险平价 (RP) 就是等量的风险预算,即为投资组合中的所有资产分配相等的风险。
类比 RB,RP 给每个风险配额 si 的分配 1/n 的权重,这时组合权重为
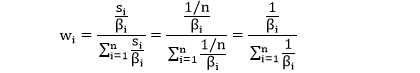
同样可得到 RP 模型下的优化问题 (用 1/n 替代 si )
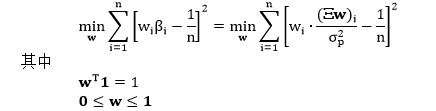
这是一个有约束 (constrainted) 的优化问题,我们可用 scipy.optimize 里的 minimize 函数来求解 RP 的权重。首先来定义 risk_parity 函数:

该函数的两个参数 sigma 和 rho 是 n 个资产的波动率向量 (一维数组) 和相关系数矩阵 (二维数组),其中
obj 就是用 numpy 把上面目标函数用「匿名函数」的形式表示出来
限制条件有两种形式,等式 (eq) 和不等式 (ineq),分别用 dict 的形式表达,而限制条件的表达式也用「匿名函数」来表示
最后在 minimize 函数设定好目标函数、初始值、算法、限制条件和终止条件,得到一个 dict 类的结果 w。
先分析简单的股票和债券两个资产组合:
股票的预期超额回报为 10%,波动率为 20%
债券的预期超额回报为 5%,波动率为 10%
它们相关系数为 -10%
mu = np.array([0.1, 0.05])sigma = np.array([0.2, 0.1])rho = np.array([[1, -0.1], [-0.1, 1]])
运行 risk_partiy 函数
result = risk_parity( sigma, rho )result
fun: 3.26901989274624e-15
jac: array([-1.86742928e-07, 1.55459627e-07])
message: 'Optimization terminated successfully.'
nfev: 22
nit: 5
njev: 5
status: 0
success: True
x: array([0.33333332, 0.66666668])result 是一个字典:
'fun' 对应的是目标函数在最优解下的值,非常小接近于零证明找到了最优值。
'nfev' 对应的 22 表示目标函数被运行了 22 次
如果只关注最优权重,只需看 ‘x’
result.xarray([0.33333332, 0.66666668])股票和债券的最优权重为 w* =[33.33%, 66.66%]
接着分析股票、债券和信贷三个资产组合:
股票的预期超额回报为 10%,波动率为 20%
债券的预期超额回报为 5%,波动率为 10%
信贷的预期超额回报为 10%,波动率为 15%
股票与债券、股票与信贷、债券与信贷的相关系数为 -10%, 30%, -30%
mu = np.array([0.1, 0.05, 0.1])sigma = np.array([0.2, 0.1, 0.15])rho = np.array([[1, -0.1, 0.3], [-0.1, 1, -0.3], [0.3, -0.3, 1]])
运行 risk_partiy 函数
result = risk_parity( sigma, rho )result.x
array([0.19117648, 0.5147059 , 0.29411762])股票、债券和信贷的最优权重为 w* = [19.12%, 51.47%, 29.41%]
本帖只讨论用 SciPy 可以实现的三个应用
用 scipy.interpolate 来插值 (interpolation)
用 scipy.integrate 来积分 (integration)
用 scipy.optimize 来优化 (optimization)
学完此贴后,至少你可以解决以下具体金融问题 (training set 
在折现曲线上插出折现因子和零息利率
数值积分求解期权价值
优化出风险平价模型的权重
举一反三一下,你还可以解决新的金融问题 (test set 
在波动平面上插出波动率
数值积分求解而二维金融衍生品价值
优化出各种资产配置模型的权重 (加各种约束)
你可以的!
下篇讨论内容最丰富的 Pandas。Buckle Up and Stay Tuned!
按二维码关注王的机器
迟早精通机学金工量投