CCL 2020闭幕,数万人见证2020年中国NLP全貌剪影

特邀报告
论文收录&最佳论文奖
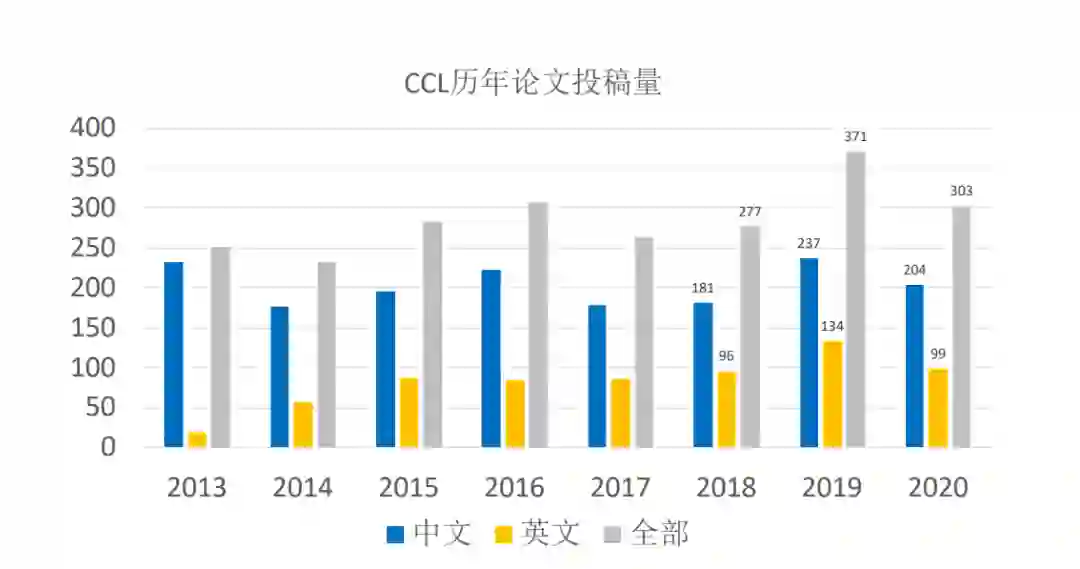
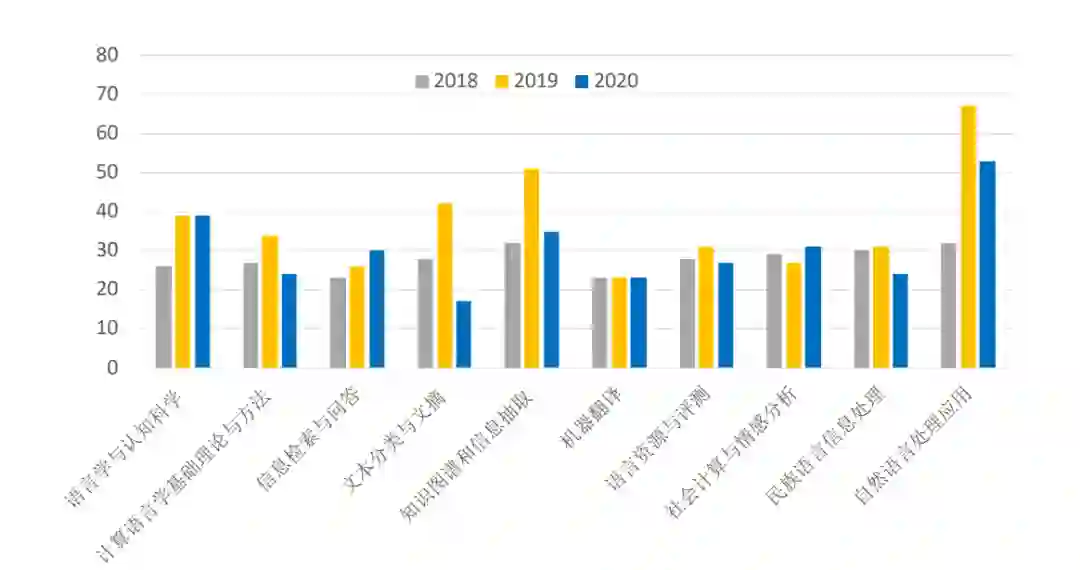
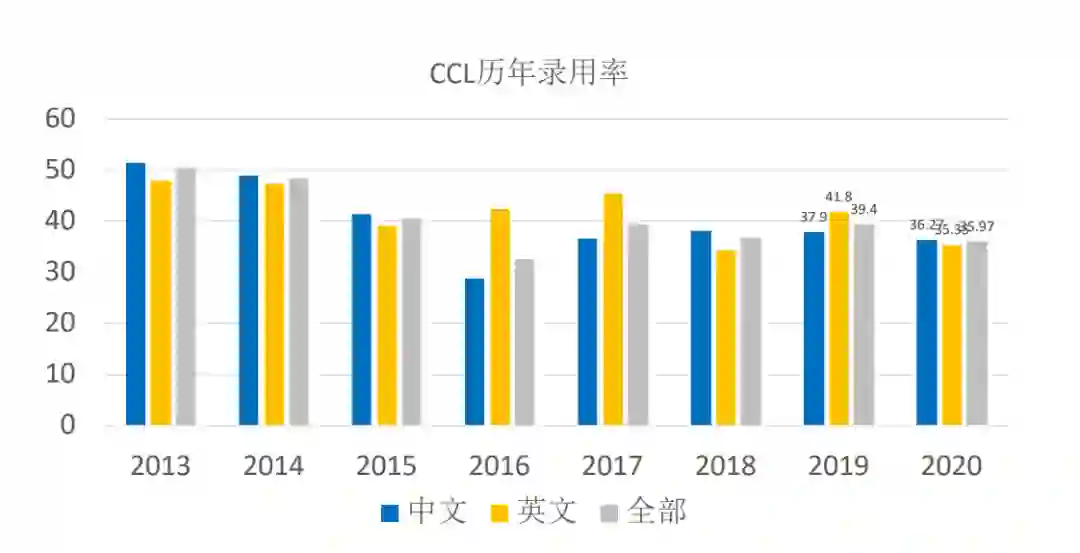






多种形式,聚焦NLP研究方方面面


点击阅读原文,直达NeurIPS小组~
登录查看更多
相关内容

刘群,华为诺亚方舟实验室语音语义首席科学家,负责语音和自然语言处理研究,研究方向主要是自然语言理解、语言模型、机器翻译、问答、对话等。他的研究成果包括汉语词语切分和词性标注系统、基于句法的统计机器翻译方法、篇章机器翻译、机器翻译评价方法等。刘群承担或参与过多项中国、爱尔兰和欧盟大型科研项目,在国际会议和期刊发表论文 300 余篇,被引用 10000 多次,培养国内外博士硕士毕业生 50 多人,获得过 Google Research Award、ACL Best Long Paper、钱伟长中文信息处理科学技术奖一等奖、国家科技进步二等奖等奖项。他曾任爱尔兰都柏林城市大学教授、爱尔兰 ADAPT 中心自然语言处理主题负责人、中国科学院计算技术研究所研究员、自然语言处理研究组负责人,分别在中国科学技术大学、中科院计算所、北京大学获得计算机学士、硕士和博士学位。
Arxiv
0+阅读 · 2021年1月27日
Arxiv
10+阅读 · 2019年9月15日





相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2021年1月27日
Arxiv
10+阅读 · 2019年9月15日