Graphcore AI芯片:更多分析
大约四个月前,基于Graphcore CTO Simon Knowles的演讲,我和大家讨论了一下它们的IPU,“解密又一个xPU:Graphcore的IPU”。10月底,Simon Knowles又在UC Berkeley做了一个演讲(点击文末阅读原文查看),介绍了IPU的更多细节和Benchmark的结果。
•••
前情回顾
如果你没看过之前的文章,也不打算再翻,这里对Graphcore IPU的特点做个简单的摘要:
1. 同时支持Training和Inference
2. 采用同构多核(many-core)架构,超过1000个独立的处理器
3. 支持all-to-all的核间通信,采用Bulk Synchronous Parallel的同步计算模型
4. 采用大量片上SRAM,不需要外部DRAM
这次Simon Knowles在Berkeley的讲演干货不少,又给出了一些新的细节,之前不太清楚的地方越来越清晰。另外,Simon Knowles的讲演包含了不少思考,建议大家自己看看。下面我们就针对几个比较有意思的地方做些分析(大部分图片是从视频中截取,不太清晰,请见谅)。
•••
整体布局和性能
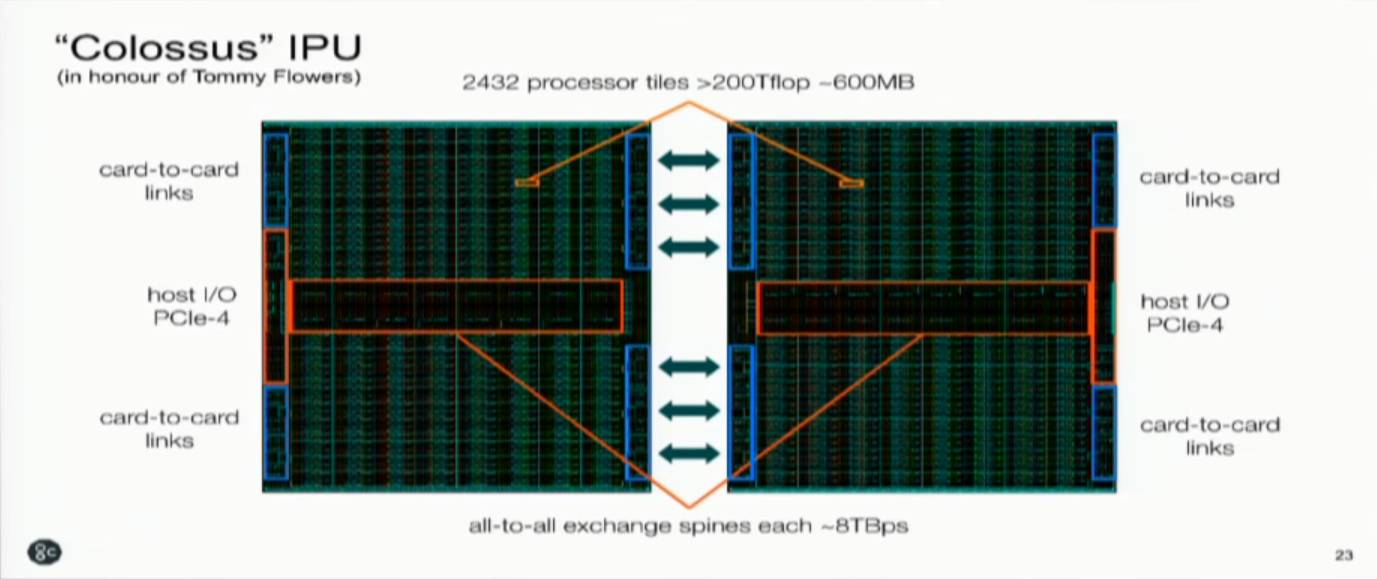
首先我们看看IPU的布局。Graphcore的第一代产品是以两颗芯片一组的PCIe板卡的形式出现,因此上图展示了整个板卡的情况。由于不使用片外的存储,芯片对外的接口只有host I/O PCIe-4和card-to-card links,以及片间的高速互连。片间互连对板卡的整体性能非常重要,不知道目前是只支持两颗芯片还是能够支持更多颗芯片的配置。
整个板卡可以提供超过200Tflop的总的处理能力。按Simon Knowles的说法,他们还没有确定峰值处理能力是多少。两颗芯片一共有2432个processor tile,其中有少量的冗余。每个Arithmetic Core如下图所示。
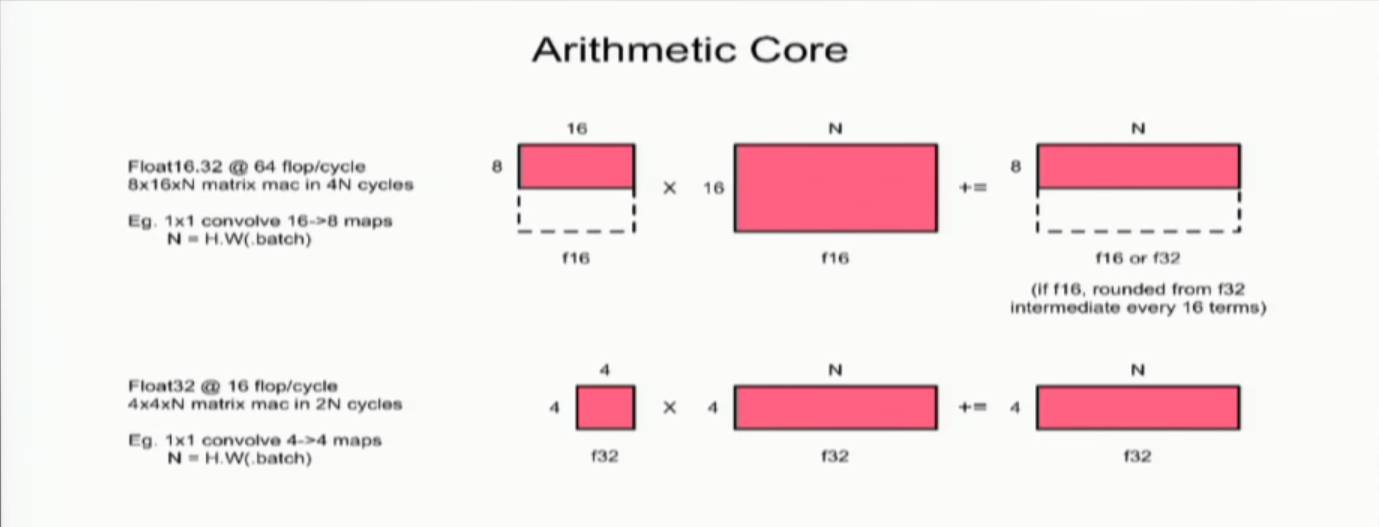
如果每个Arithmetic Core 每个Cycle可以做64flop的FP16运算,则2432个(假设都是用来做运算的),每个Cycle可以做64x2432=155648 flops。如果总的处理能力是200T以上,可以推测芯片的工作频率大约是1.3GHz左右。不过讲演中并没有透露具体的时钟频率,也没有提供功耗效率的信息。
不过我们还是可以简单和Google的TPU2对比一下,TPU2一块板卡4颗芯片,总共180Tflop(FP16乘法,FP32加法)的处理能力,这个数据大家差距不大。但IPU的一个最大特点就是使用大量的片上SRAM。这次我们看到了确切的数据,两颗芯片一共大约600MB的SRAM!确实非常惊人。
将神经网络的weight和activition都放在片上的SRAM中,肯定可以提供比片外memory高得多的带宽和功耗效率。但在同时发布的Blog,“PRELIMINARY IPU BENCHMARKS”中,有这样一段话,“ For example, the best performance reported on a 300W GPU accelerator (the same power budget as a C2 accelerator) is approximately 580 images per second.”是否可以认为Graphcore的加速卡的整体功耗也是大约300W呢?如果是这样,那么C2的功耗效率大约是:200T/300W < 1Tops/W的。显然这个数值并没有做到之前他们承诺的“- it improves performance by 10x to 100x compared with other AI accelerators”(可以看看隔壁,Groq把AI芯片的性能推向新高)。也许我看到的信息不太准确,各位如果有更准确的信息也请指教。另外,指标是一方面,最终的效果还是得看实际产品。
芯片内部的处理器和存储应该是分布排列的,芯片中部有很大一块面积留给了处理器核间的互连(all-to-all exchange spines)。Simon Knowles在讲演中强调了“time determinism”,即在芯片内部所有的操作的时间是确定的,这可以大大简化编译器优化的难度。在问答阶段他还提到,all-to-all exchange采用了一个“fishbone”的架构,而不是“grid”的形式,就是为了比较容易实现代码广播(同一份代码给不同的processor处理)的时间确定性。后面我们还会看看时间确定性在任务调度中的重要性。
此外,还有一个小点,就是在IPU中专门设计了硬件的随机数生成机制,可以满足更多的算法需求。

T.S.:
Graphcore IPU的硬件架构信息越来越清晰,确实有很多有趣的细节。能够公布这些信息,也说明IPU芯片的完成度已经相当高了。按照Simon Knowles所说,预计明年Q1能够提供给早期客户。
•••
计算模型

Graphcore对“图计算”也有自己的一套模型。其中Codelet是最小单位的函数。这个也没太多可说的,值得一提的是他们的on-chip exchange机制。

这里的关键字还是“time determinism”,也就是说在经过了同步之后,所有的exchange都发生在确定的时间,而complier是“知道”这个时间的。所以compiler可以很好的对核间的通信进行调度。这里,Simon Knowles强调了一个重要的前提,就是“graph”的“static nature”。换句话说,IPU处理的graph应该是静态的,这样才能保证时间的确定性。
另外,在上图中还可以看出,IPU有两套指令集,分别控制运算和通信。这个机制也和IPU的运算和通信分离的调度方法(Bulk Synchronous Parallel,后面还会进一步分析)是相符合的。
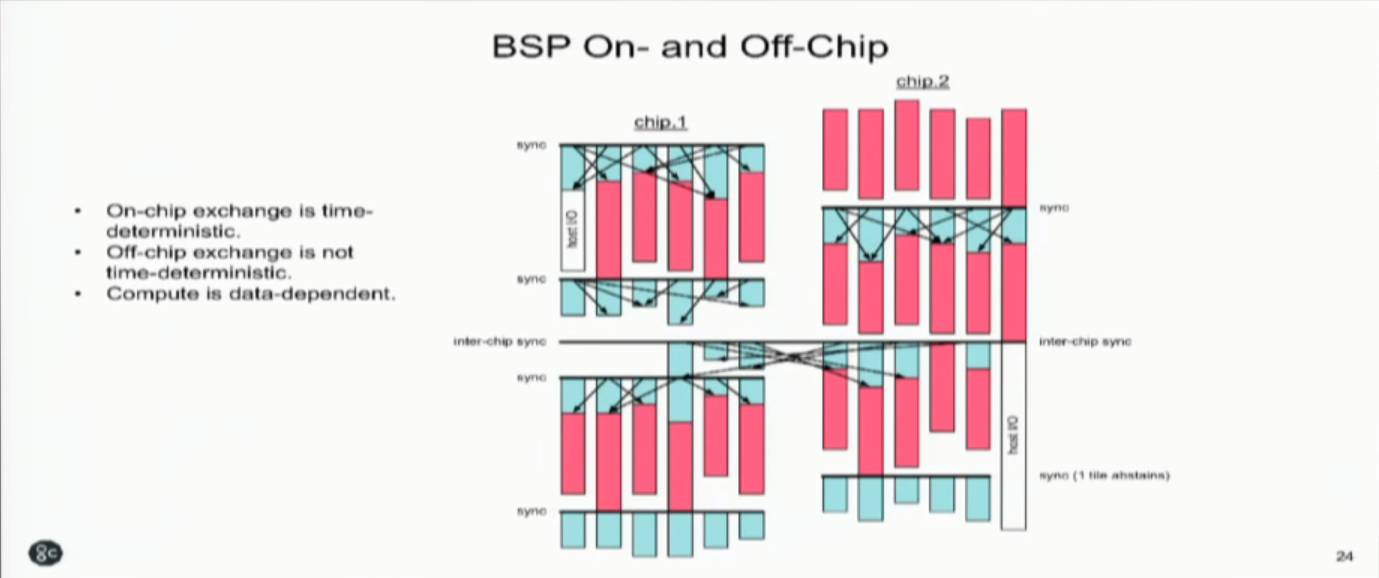
最后,两颗芯片之间是无法保证时间确定性的。所以就有了跨芯片任务的同步机制(如下图)。总结一下就是下图中的三句话:1. 片上通信是时间确定的;2. 片间通信不是时间确定的;3. 计算(调度)是依赖于数据的。
T.S.:
总的来说,IPU考虑的编程模式是一个确定性模型,要求计算和通信发生在确定的时间。这样可以大大降低硬件和compiler设计的难度。目前的神经网络Computation Graph在部署的时候绝大多数是静态的,因此问题不大。未来如果神经网络算法上有新的变化,比如更多的出现动态图的情况,可能就得重新考虑这个问题了。
•••
Bulk Synchronous Parallel
在之前的讲演里(参考解密又一个xPU:Graphcore的IPU),我们已经比较详细的看到了对BSP(Bulk Synchronous Parallel)的说明。它的基本操作可以分为三个:1) 本地计算阶段, 每个处理器只对存储本地内存中的数据进行本地计算。2) 全局通信阶段, 对任何非本地数据进行操作,包括核间数据的交换。3) 栅栏同步阶段, 等待所有通信行为的结束。这和IPU的 “运算和通信的串行执行”的特点是一致的,也和IPU的多核/local memory架构很一致。
而这次,我们看到了实际运行的例子。
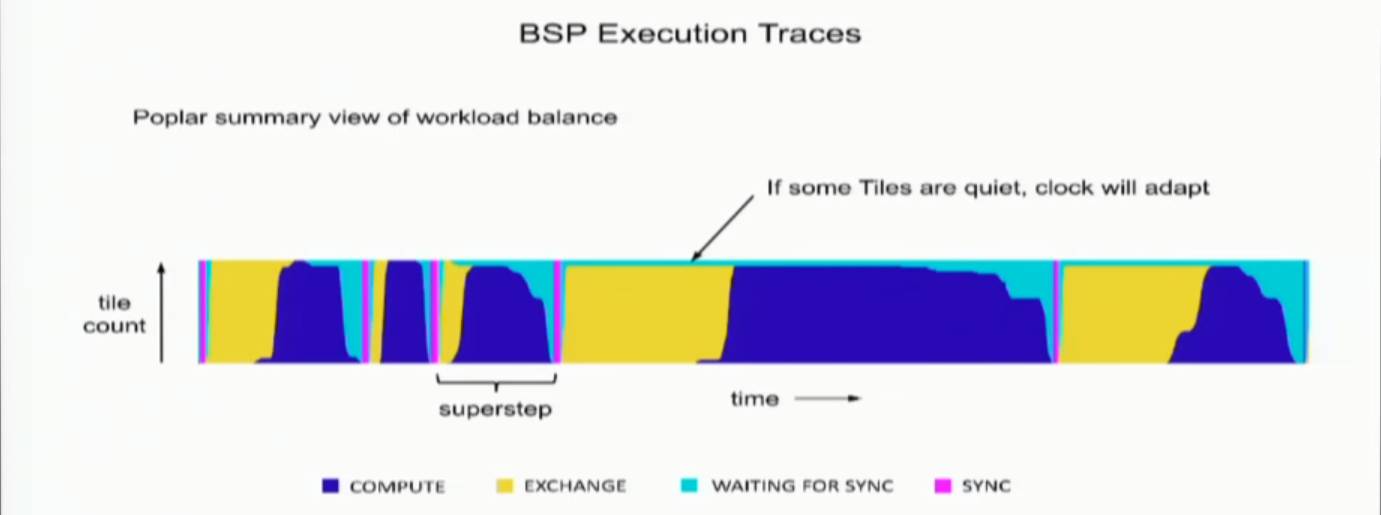
上图是一个实际运行的trace结果,可以很清楚的看到BSP执行的各个阶段是如何一拍一拍的进行的,包括同步点。下图就是一个完整的运行ResNet-50的时间序列,也很清楚,基本上可以看到IPU的运算和通信基本能够充满整个运行时间,也应该实现了他们所谓的最大限度利用能量和时间的说法。
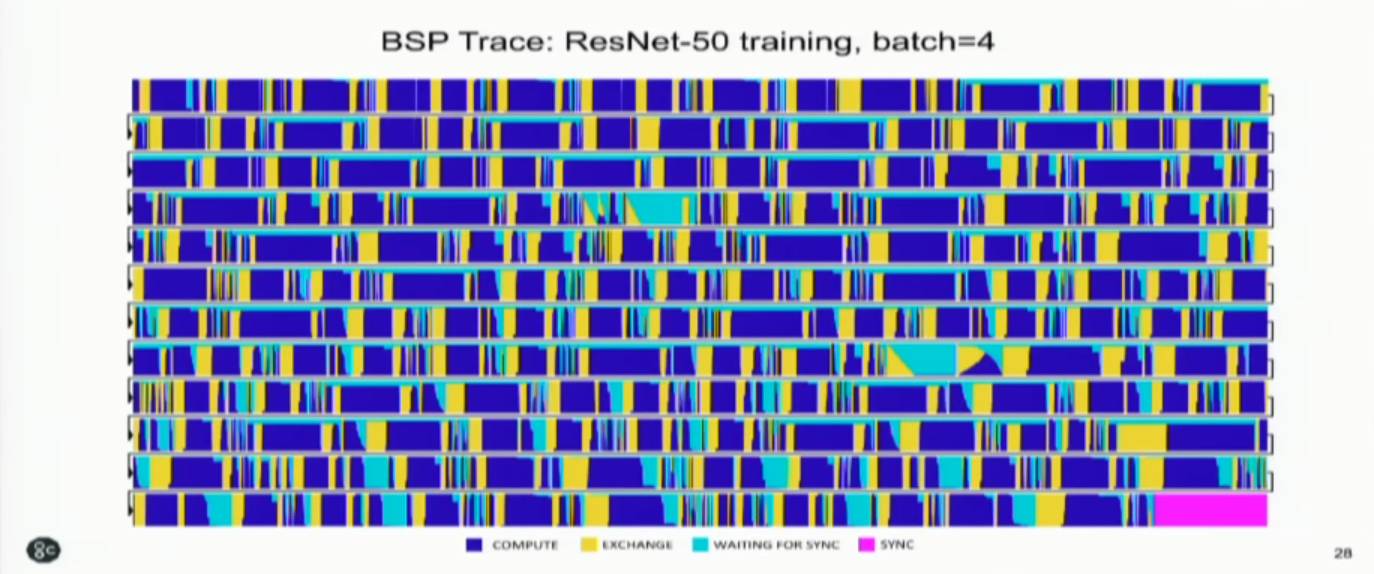
实际上,这次展示的几个例子和Graphcore网站上给出的Benchmark所用的例子是一致的。大家如果感兴趣,也可以去网站上看看他们的Benchmark。比较有意思的是他们用了很多百度“DeepBench”的测试(参考“给DNN处理器跑个分 - 设计篇”)。
T.S.:
IPU的运算和通信调度,采用的也是一个比较简单的方法。之前也讨论过为什么采用“运算和通信串行执行”的策略。这些设计都很大程度上简化了硬件和软件工具的难度,而同时也符合神经网络加速应用的特点,值得借鉴的。
•••
题外话
最后是一点题外话,Simon Knowles在开始就提到,目前Graphcore有70多名员工。在7月份的时候,好像是50人左右。这个增速基本反映了目前AI芯片领域的快速成长。不过从另一个方面来看,当他们明年第一季度开始推产品的时候,估计会需要更多的Field Engineer。AI芯片的竞争,除了要有好的架构(需求,算法到架构优化的能力),高效的实现(芯片前后端设计能力),好用的工具(工具链开发能力),未来还要比拼对客户的服务能力。

题图来自网络,版权归原作者所有
通过DARPA项目看看芯片世界的“远方”- 自动化工具和开源硬件