轻量型网络:MoGA简介
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
作者:Happy https://zhuanlan.zhihu.com/p/76909380 来源:知乎,已获作者授权转载,禁止二次转载。
该文是小米AI Lab公开于预印版的一篇关于手机端GPU推理的NAS方法。
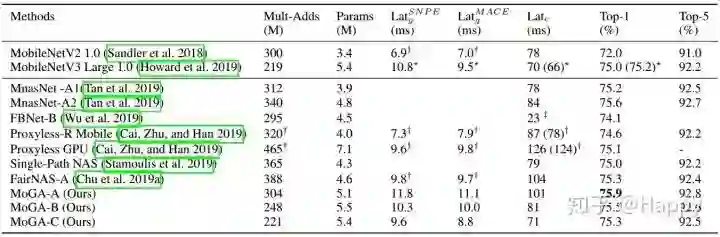
MobileNet在手机端神经网络应用中留下了浓重的一笔。MobileNetV3的提出,进一步表明了NAS在网络架构设计中的优越性。然而,已有手机端网络主要集中于CPU延迟,而非GPU。事实上,在工业应用中GPU端模型具有更高的应用潜力(现在手机大部分都支持GPU)。为填补该空白,小米AI Lab的研究院提出首个手机GPU导向NAS以促进实际应用。更进一步,它的终极目标是:在有限资源下,设计出具有更高性能、更低延迟的手机端架构。最终,作者搜索到一类优于MobileNetV3的架构(相似延迟约束),比如MoGA-A取得了75.9%top-1精度,MoGA-B取得了75.5%精度且仅比MobileNetV3在GPU端慢0.5ms,而MoGA-C以更高精度(75.3%),更快速度优于MobileNetV3(75.2%).
Background
MobileNet在手机端网络架构设计方面留下了浓重的一笔,其也是近来NAS搜索的一个baseline。然而,现有NAS方法大多以“低CPU延迟”作为主要优化目标。但实际上,“低GPU延迟”在实际手机端应用更具优势(现有主流手机基本都支持GPU),因而很有必要将NAS优化目标从“低CPU延迟”向“低GPU延迟”迁移。
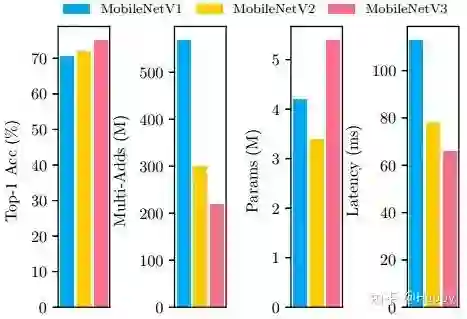
鉴于此,小米AI Lab的研究员以此作为出发点,并将其搜索网络命名为"Mobile GPU-Aware Neural Architecture Search,(MoGA)"。同时,它以模型精度、延迟以及参数量作为总体优化目标,很重要的一点是模型参数量应具有足够大以促进性能的提升,参数量提升并不一致于延迟增加。比如下图中MobileNet系列的相关对比。
Method
Mobile GPU Awareness
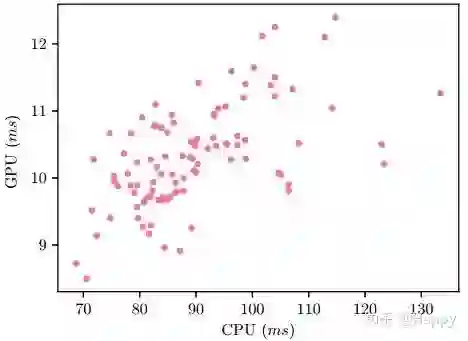
近期的NAS方法更多着重于手机CU端,对手机GPU端的关注极少。在实际应用,轻量型神经网络主要部署到手机GPU,DSP以及NPU上,CPU则是最后不得已之下的选择。为进一步说明CPU延迟与GPU延迟之间的关联性,作者随机评估了100个模型在CPU与GPU端的延迟对比(见下图)。从中可以看出:两者并无明显的线性关系。因此,特定平台的架构搜索更有必要性。
Problem Formulation
大多数NAS将分类问题定义:

小米AI Lab的研究员将其重定义为多目标优化问题,将上述优化问题重定义为:
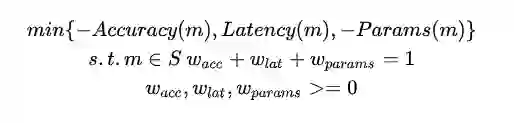
搜索空间
该搜索空间基于Inverted Bottleneck模块设计,采用逐层搜索方案,同时具有与MobileNetV3-Large同等的层与激活函数。对每一层从以下三个维度进行搜索:
卷积核尺寸:(3, 5, 7);
逆残差模块中的扩展比例:(3, 6);
是否引入SE模块。
Latency Prediction
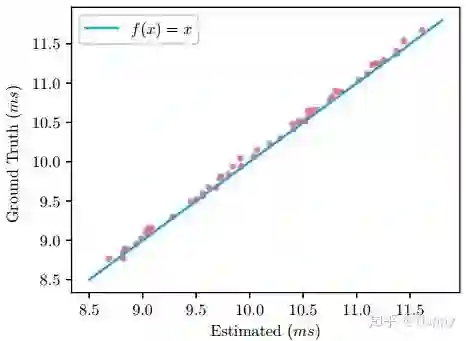
由于该搜索空间中每个模块均具有固定的输入,因而可以采用统计延迟方式制作查找表。然后将延迟采用逐层累计方式得到模型的延迟耗时。GPU实际延迟与预测耗时对比见下图,误差不大于0.0571ms.
Pipeline
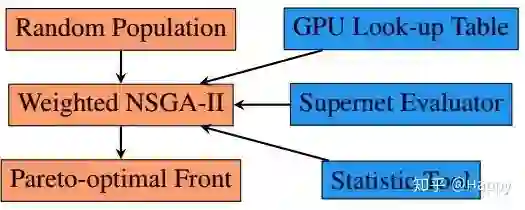
下图给出了该NAS方案的整体流程图。感兴趣者可以查阅原文得到更为详细的描述。
Experiments
实验部分简单的列举几个关键性的图。为对比模型的性能,作者采用了SNPE,MACE以及TFLite作为评估框架。
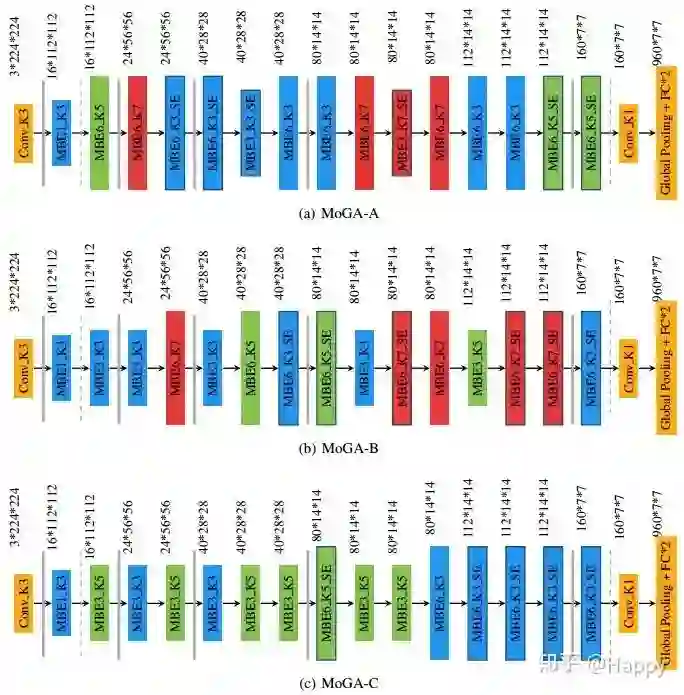
最终搜索得到的三个架构如下所示:
Conclusion
总而言之,作者讨论了手机端神经网络架构设计中的几个关键因素。首先,作者提出了首个手机端GPU模型解决方案(这是因为在实际产品中,因其第延迟,低开小,在GPU上运行网络更受欢迎,已有工作更多关注于CPU端模型设计);其次,过拟合并非手机端模型的主要考虑因素,因而可以释放出更多的表达能力以拟合其他约束;最后,作者在MnasNet与MobileNetV3基础上,采用NAS进行手机端架构搜索,得到一类SOTA性能的网络MoGA-A,MoGA-B以及MoGA-C。
-End-
*延伸阅读
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~