问答 | 怎么评价基于深度学习的deepvo,VINet?

这里是 AI 研习社,我们的问答版块已经正式推出了!欢迎大家来多多交流~
http://ai.yanxishe.com/page/question
(文末有福利哦)
社长为你推荐来自 AI 研习社问答社区的精华问答。如有你也有问题,欢迎进社区提问。
话不多说,直接上题
@幻象波普星 问:怎么评价基于深度学习的deepvo,VINet?
1.DeepVO: A Deep Learning approach for Monocular Visual Odometry;
2.VINet : Visual-inertial odometry as a sequence-to-sequence learning problem
3.VidLoc:6-DoF video-clip relocalization
来自社友的回答
▼▼▼
@Momenta小助手
这篇回答中,我们将主要介绍VINet深度神经网络架构。
高精度的车道级导航和定位是自动驾驶汽车的核心技术。常规的高精度定位手段,如差分GPS和惯性导航设备在一些GPS信号不佳的场合(如立交桥,隧道)误差较大。其次,这类设备的价格往往较高,并不适用于商用的无人驾驶汽车方案。相比而言,一些基于语义地图的匹配定位方案相对廉价,但是考虑到视觉语义感知的误差和语义地图中语义要素的稀疏性,此类方案并不能达到任意场景下的定位。作为语义地图匹配定位方案的补充,视觉惯性里程计(Visual Inertial Odometry)是一种融合图像视觉和廉价惯性数据的组合定位方法。它通过摄像头和惯性器件的廉价结合,既可以有效抑制惯性器件的漂移,又可以克服视觉里程计(Visual Odometry)中的尺度、相对运动和低帧率等问题,是实现低成本高精度定位的有效手段。
传统VIO的框架一般可分为三个过程,基于图像序列的光流估计、基于惯性数据的积分操作以及基于滤波和优化的运动融合。从文献披露的情况来看,深度学习在这三个子领域均已涉及。首先来说说光流估计的问题。光流是运动物体在像素空间中瞬时速度的体现,它需要结合相邻帧之间像素的对应关系。
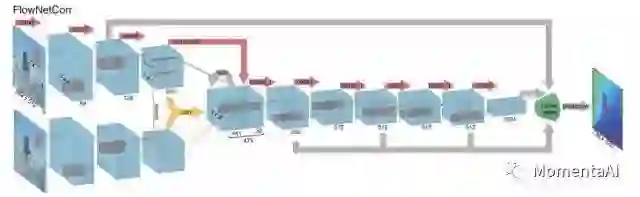
FlowNet 网络结构
Flownet 是目前用DL来做光流问题的state of art。与一般的深度卷积神经网络相比,Flownet有两点不同:首先它的输入是相邻帧的两张图像,其次它通过对来自于不同图像的feature map 做相关性操作来学习两帧图像之间的运动差异。
接着,来谈谈IMU时序数据的问题。众所周知,RNN和LSTM是DL领域数据驱动的时序建模大法。而IMU输出的高帧率角速度、加速度等惯性数据,在时序上有着严格的依赖关系,特别适合RNN这类的模型。
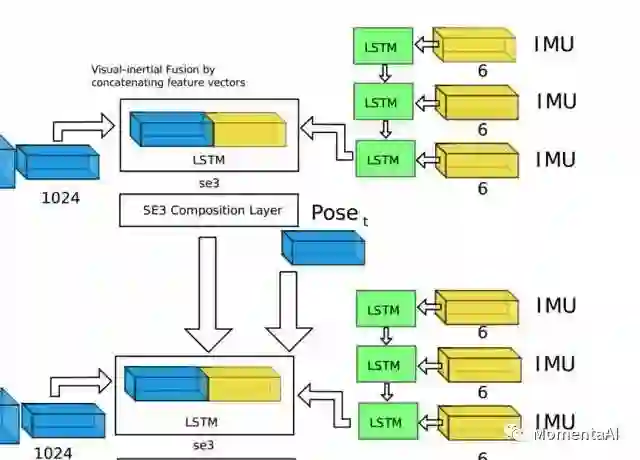
VINet中的IMU时序数据处理模块
因此,我们可以很自然的想到利用FlowNet和RNN来做结合,处理VIO的问题。
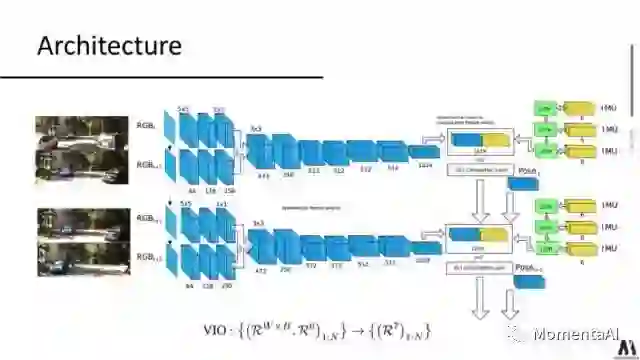
VIO 的网络架构
VINet正是基于这样的动机所设计,它的整个网络可以分为三部分。其中,CNN部分通过一个FlowNet来得到相邻帧间图像间的光流运动特征(1024维)。接着,使用一个常规的小型LSTM网络来处理IMU的原始数据,得到IMU数据下的运动特征。最后,对视觉运动特征和IMU运动特征做一个结合,送入一个核心的LSTM网络进行特征融合和位姿估计。
VINet中处理不同帧率输入数据的机制
值得一提的是,VIO问题中IMU数据的帧率与图像的帧率往往并不匹配,例如KITTI 数据中IMU的帧率是100Hz,图像数据的帧率是10Hz,这就要求神经网络能够对不同帧率的输入数据进行处理。在VINet中,小型的LSTM网络能够以较快的频率处理高帧率的IMU数据,而参数量较多的核心LSTM则和CNN一起以图像的帧率工作。利用LSTM对输入数据的不定长特性,完成了不同速率下的视觉和惯性数据的特征学习和融合。
有了融合的特征,那么问题来了,如何在神经网络中建模位姿呢?
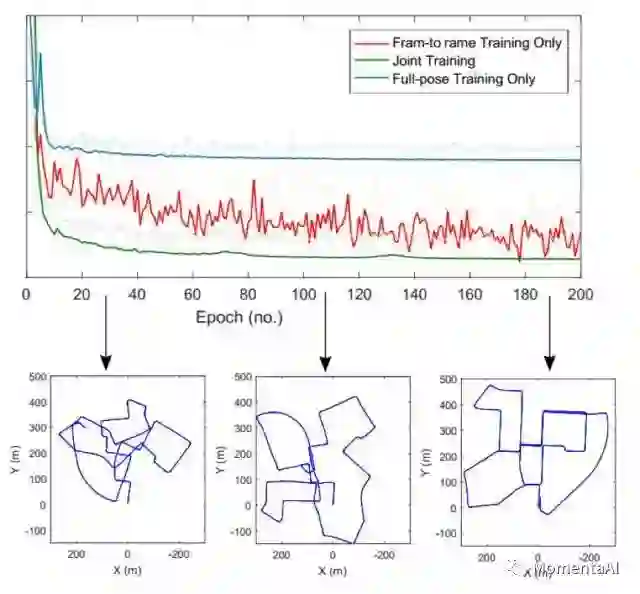
在机器人和计算机视觉中,位置姿态除了表达3D旋转与位移之外,我们还要对它们进行估计,为了做这件事,需要对变换矩阵进行插值、求导、迭代等操作,我们希望有更好的数学工具帮助我们做这些事,而李群与李代数理论正好提供了这样的工具。通常,我们用特殊欧式群SE(3)来表示相机的位姿。然而SE(3)中的旋转矩阵必须要求正交,这种特性在进行参数学习的过程中很难保证。为了解耦这种正交性,数学中可以用李代数 se(3) 来表示这种变换。数学上可以证明,李代数se(3)表达的正切空间和原来的SE(3)群相比,具有相同的自由度,更重要的是,通过简单的指数映射,我们可以很方便把se(3)中的变换向量映射回欧式空间中的变换矩阵。有了这种建模手段,我们至少可以得到如下两种损失函数。
一种是建立在SE(3)群上位姿约束(Full pose),另一种是建立在se(3)空间中的相对运动(Frame-to-frame)约束。实验结果表明,这两种损失函数在一起联合约束的时候,VINet所能达到的效果是最佳的。
在传统的VIO应用中,只要涉及到摄像头和惯性器件的数据融合,就无法避开两种传感器的联合标定。传感器之间的标定可分为时间和空间两个维度,在时间维度上称之为数据帧同步,在空间维度上称之为外参标定。传统VIO往往需要标定的效果近乎完美,否则算法很难正常工作。而VINet上的实验结果表明,当传感器的标定参数发生误差的时候,基于深度学习的VIO方法较常规方法而言,体现出了一定的鲁棒性。对于VINet这样的数据驱动的模型,往往有较大的潜力去学习来自于数据中的规律,因此对于标定误差这样的数据扰动,模型对其具有较强的建模和拟合能力,这也是数据驱动模型的最大魅力。
综合以上,我们介绍了VINet,它是一种端到端可训练的深度神经网络架构,用来尝试解决机器人领域视觉惯性里程计的问题。这种网络使用FlowNet来建模视觉运动特征,用LSTM来建模IMU的运动特征,最后通过李群李代数中的SE(3)流行来建模位姿,用帧间堆叠的LSTM网络来预测位姿。在真实的无人驾驶和无人机数据集上,VINet获得了与state of art 方法具有可比性的结果。同时,VINet在面对时间不同步和外参标定不准确的多视觉惯导数据时,表现出了一定的优势。就整体而言,VINet是首次使用DL的框架来解决VIO问题,目前所披露的实验表现出了一定的实用价值,值得我们后续的继续关注。




如果你还有更好的答案,欢迎你点击 阅读原文 ,和大家一起讨论哦!
【AI求职百题斩】已经悄咪咪上线啦,点击下方小程序卡片,开始愉快答题吧!





