面向SecDevOps七种武器

作者 简志,阿里高级技术专家
如果数字世界是一个江湖,技术人员则是自各门派侠士,例如:
拥有一双慧眼洞察一切蛛丝马迹的SecOps
手持各种脚本掌握线上大权的Net/Site Ops
以敲击机械键盘比拼手速为乐的DevOps
纵观他们的工作会有一些共同点:
关键(Mission Critical):一个命令决定生杀大权,一个操作决定业务走向。面对问题时需要作出关键决策与判断,压力巨大
数据驱动(Data Driven):坚持理性,天天与数据打交道,善于从数据中拿到客观公正结果
高危(With Responsibilty):“人在江湖走,哪能不挨刀”,谁没经过几个故障?没处理过几个攻击?被撸过几手羊毛?
与此同时,他们也在工作中Share非常多的问题与工具,与一致的目标(确保系统稳定运行):
Gartner 《Align NetOps and SecOps Tool Objectives With Shared Use Cases》提到:
Network operations (NetOps) and security operations (SecOps) teams coexist as largely separate entities in many organizations, but they share a common goal — a well-performing and secure network infrastructure that optimizes the end-to-end user experience for networked applications.
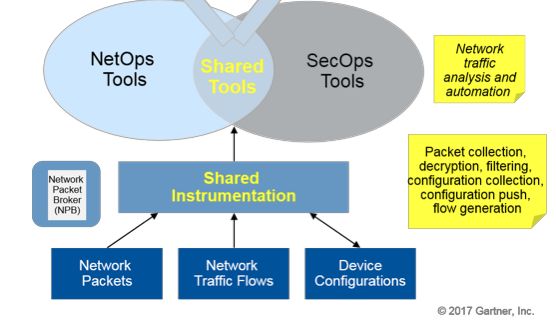
行走江湖靠本事,但过去几年行业/环境等都在悄悄变化,使得门槛越来越高:
1. 快速发展IT基础设施
IT领域一方面受到成本降低的反对力量的挑战,另一方面运营的复杂性在不断增加。近些年来可以看到如下趋势:
云原生或其他Serverless技术发展不断演化IT技术架构
架构和应用程序产生的数据量快速增长(每年增长2到3倍)
机器和人类生成的数据类型越来越多(例如指标、日志、网络数据和文档)
IT运营成本、运营的复杂性在不断增加,需要更短时间相应
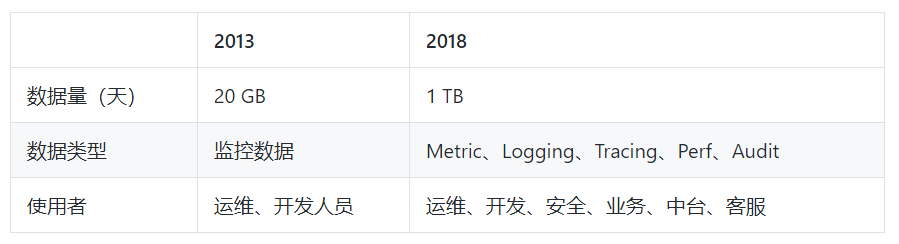
以一个典型计算类集群(固定大小)为例,2013年一天产生数据在2GB,类型以监控数据为主。随着自动化运维、运营水平提高数据量增长了50倍,参与者也在变多:
2. 业务稳定后的细节
航空航天中有一条著名定律:海恩法则(Heinrich's Law)指出: 每一起严重事故背后,必然有29次轻微事故和300起未遂先兆以及1000起事故隐患。按照海恩法则分析,当一件重大事故发生后,我们在处理事故本身的同时,还要及时对同类问题的“事故征兆”和“事故苗头”进行排查处理,把问题解决在萌芽状态。
与20世纪电力一样,今日信息技术已经成了社会运转的关键一环,而信息系统的稳定运转除了架构设计外,日常的运维与运营也是稳定性重要一环。 我们可以通过监控、日常分析、A-B Test 运转下的数据对比、质量测试等环节保障系统的稳定性。
3. 对工具能力更高要求
在处理海量、多样化和更低延时要求下,现有工具在数据量、延时和分析能力上收到了挑战:
3.1 更快的响应
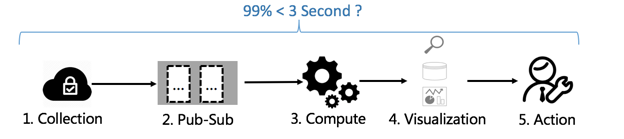
Ops面向是偏向真刀真枪的复杂业务,需要快速的洞察。何为快速?
快速采集线上数据
快速通过观察、假设、拿到分析结果
快速找到规律、发现异常
采取行动,止损
其中2、3是一个循环过程,为了贴近真相需要多次迭代。如果能把这三个过程控制在分钟、甚至是秒级,会大大加快速度。
3.2 更灵活的洞察
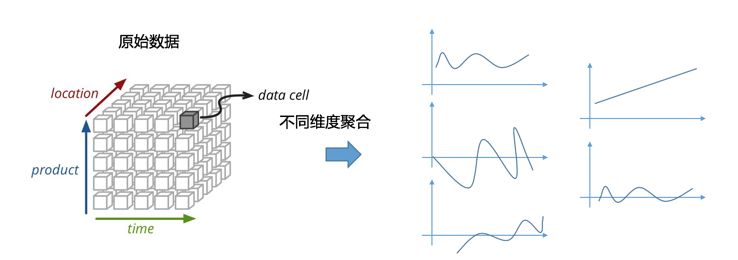
拿放大镜洞察到不易发生的现象,例如对于系统负载、延时、请求的Burst,往往会有被分钟级被平均,但在秒的精度下却波涛汹涌的景象;对于小业务而言,也经常会在线上遇到被平均的现象,命名有大量的失败,从整体大盘上看却又是正常。

能够灵活切换视角。例如对于安全攻击而言,攻击Pattern、来源、地址等信息都在不停地变化,预先定义的各种统计可能无效,因此要在分析过程中不断改变分析的模式,并且所见即所得拿到结果。解决这个问题的思路就变成了:尽可能全保留原始数据(不进行预聚合降低精度),通过即时方式来构建分析视图。
典型问题背后的七种分析手段
既然Sec、Dev、Ops 有着同样的目标,处理同样规模的问题,那么在工作中是否会Share相同的工具?
我们2009年开始写飞天第一行代码一刻起,就一直在经历和机器、系统、应用的搏斗过程。期间经历集群从70台增长到5000台过程,也经历了支撑W级用户背后的痛苦和摸索。
从我们的视角把日常工作中最高频的问题,抽象成了七种分析的手段,分别是:
查找
上下文探索
对数据统计
聚类
异常发现
根因分析
领域建模与本体构建(Knowledge Base)
1. 查找:Grep大法好
从业界统计
《50 Most Frequently Used Unix Command》看,Grep是使用最多的命令之一(排名第一的是tar、第二就是它),也是发现+定位问题最常用方法。Grep提供了一种“简单暴力”方式过滤掉无用的信息。由于是文本处理,它能适配于各种格式以最快的速度拿到结果。Grep与其他命令的组合与扩展也丰富了查找的场景能力,例如:
面对分布式场景时,可以通过pssh + grep方式来化解
面对实时场景时,tail -f | grep 组合似乎也不错
稍微复杂一些的条件,egrep扩展的正则表达式似乎也不错
面对组合条件时,grep + sed(行列转换)似乎也能解决问题
这么好的神器有哪些缺陷呢?
暴力:将数据从磁盘上读取,从头到尾过一遍消耗巨大资源。Grep诞生于90年代,O(N)的时间复杂度随着日志膨胀已开始延时不可控,并可能会给线上应用带来较大的开销。
不支持较复杂的逻辑组合:在grep命令中,有OR和NOT操作符的等价选项,但是并没有grep AND这种操作符。但表达能力是一维的,例如我们希望拿到 "A and B not C or D" 这样的逻辑就会比较难。
支持数据类型有限:主要基于文本表达上,例如对于数值类、布尔、JSON等格式就无法支持,只能退化成为简单的文本形式。例如我们希望拿到 (Latency>500000 and Method:Post ) not Type:internal 的结果时,大部分人是无能为力的。
复杂度从O(N)降低成为 O(1):把扫描变成搜索
提到搜索可能小部分人知道Lucene,但提到Elastic Search和ELK Stack应该大部分人都不会陌生。Lucene是Doug Cutting 2001年贡献(Doug也是Hadoop创始人),2012年Elastic Co这家公司把Lucene这套Apache基础库包装一遍,在2015年推出ELK Stack(Elastic Logstash Kibana)解决了集中式日志采集、存储和查询问题。从ES、Splunk近几年快速发展也能够印证“查找”从搜索引擎逐步变成DevOps常用操作。
我们在2013年开始在飞天平台研发过程中,为够解决大规模(例如5000台)上研发效率、问题诊断等问题研发面向日志、Metric、Event等存储的SLS产品,目前每日索引PB级数据,处理来自上万研发工程师的百万次查询。关于SLS可以参考《SLS vs ELK》。
2. 上下文(Tail/Less/More):线索的串联
有了grep定位到后,一个很自然的问题是原因(上下文)是什么?
上下文是围绕问题展开的线索:
一个错误,同一个日志文件中的前后数据
一行LogAppender中输出,同一个进程顺序输出到日志模块前后顺序
一次请求,同一个Session组合
一次跨服务请求,同一个TraceId组合
例如一个很常见操作是grep拿到文件后,跳转到对应机器用vim打开文件,上下翻阅查查找这些线索。在这个过程中,有不少程序员贡献过一些vim插件帮助标记(不同颜色标记error、info、level等级别)。纵观整个过程,我们为了拿到前后几行的数据,做了很多不必要的操作。
我们把上下文定义下:
在一个最小区分粒度上能够准确还原出最原始的序列,不受日志存储、采集等环节影响
最小区分粒度:区分上下文的最小空间划分,例如同一个线程、同一个文件等。在定位阶段非常关键,能够使得我们在调查过程中避免很多干扰
保序:在最小区分粒度下保证原子有序,及时一秒内有几万次操作,也要保证顺序是严格的
例如面向不同的数据源的最小区分粒度如下:
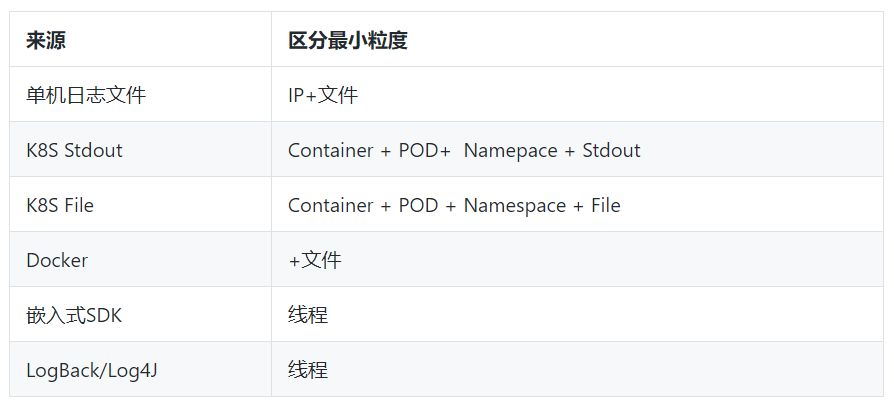
为支持上下文,我们在采集协议中对每个最小区分单元会带上一个全局唯一并且单调递增的游标,这个游标对单机日志、Docker、K8S以及移动端SDK、Log4J/LogBack等输出中有不一样的形式。
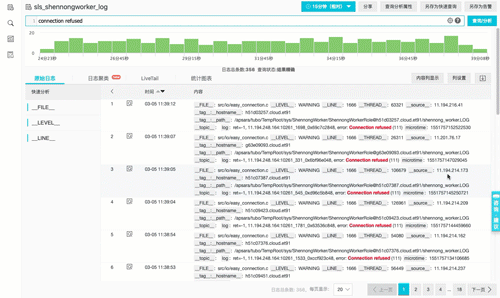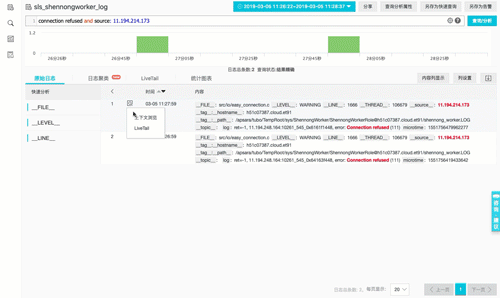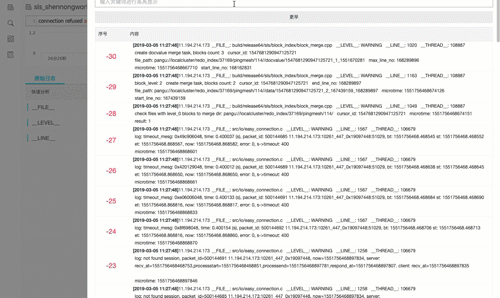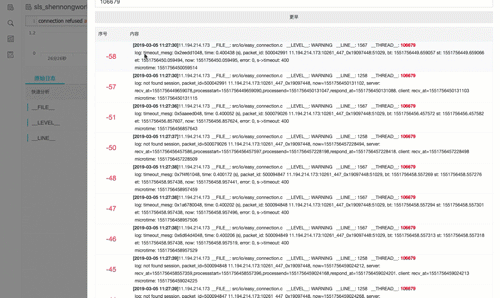
上下文功能1:上下文跳转
查找到具体错误后,不用登陆机器还原原始日志文件中前后内容
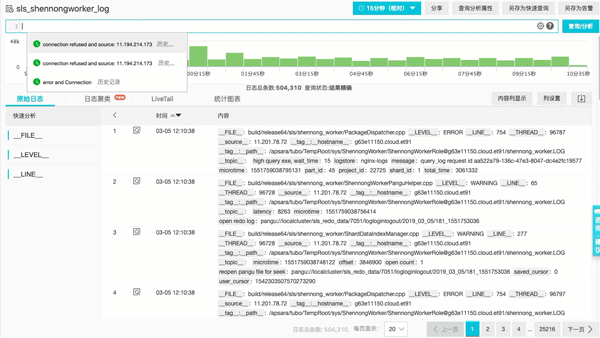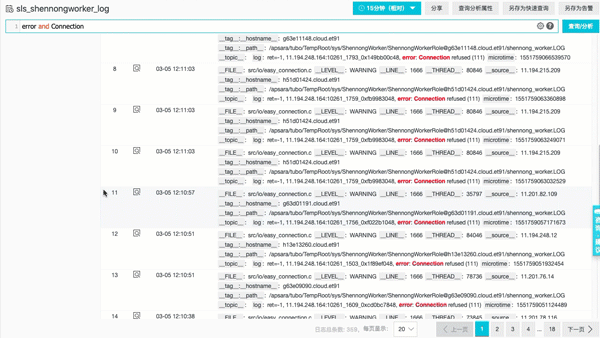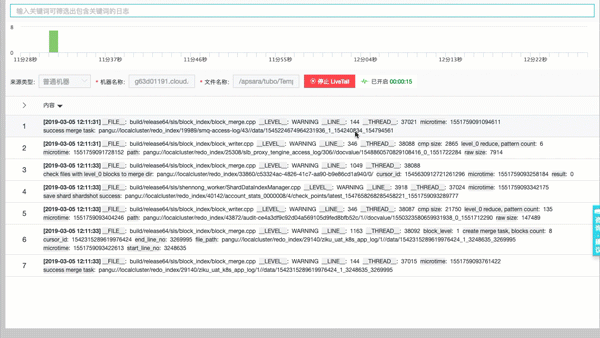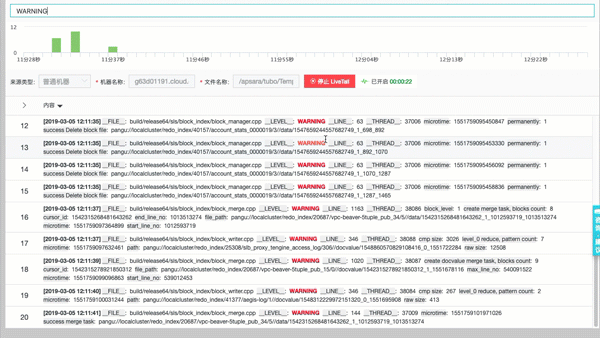
上下文功能2:实时下文(Livetail)类似 Tail -F
通过查找定位到具体日志后,可以直接tail -f 该机器上实时流日志数据。
3. 交互式分析:从统计中发现规律(AWK/SORT/SED/UNIQ)
在稍复杂一些场景中,我们需要对日志中的数据进行统计发现其中规律。在Linux理念中,任何复杂任务都是可以用一组命令的组合来达到(运维大法的一个入门的例子就是对Nginx访问日志进行命令行处理)。
例如单位窗口的访问Status统计:
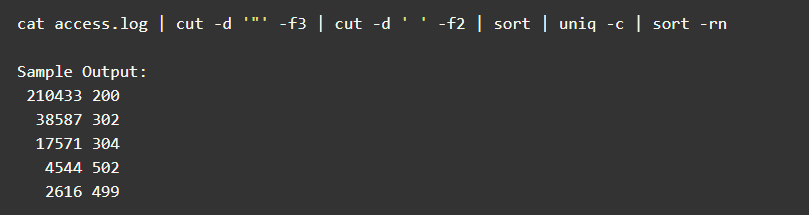
为了拿到效果也可以用awk:
awk '{print $9}' access.log | sort | uniq -c | sort -rn
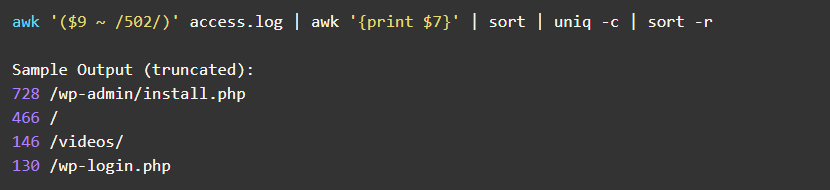
对于其中某些错误,例如502(bad-gateway),沿用如下的命令行分析获得页面:
这种方式虽然很灵活但无法水平扩展,在大部分场景已经逐步被基于流计算(Streaming)监控系统所取代,除此之外还有一种基于Ad-Hoc Querying的监控访问:
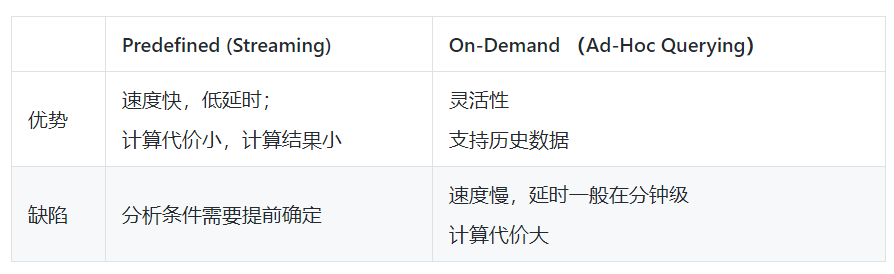
在监控场景中Streaming的模式足以胜任。但在DevOps排查工作中,一点都离不开On-Demand交互式分析。例如:
发生安全攻击时,我们需要根据攻击特征进行防御。例如在初始结果可以根据ClientIP来源进行策略防御,但当攻击者众多时,我们可能需要把分析视角放到某个目录、或页面上,是否可以拉黑或清洗。
线上有大量错误发生时,我们需要需要对这些错误各维度去聚合,是一个全局的错误?还是一个用户的错误?如果是用户的错误,是来自于某些省市的运营商?还是来自于用户的某个业务?每个推断后都是一个不断变化的SQL
SLS提供了一种实时查询技术应对这种需求:
低延时:数据产生、采集、存储到可以被查询 需要控制在1秒内(99% 情况)
灵活:支持SQL92标准查询,所见即所得
效率高:十亿级的数据可以秒查,秒出结果
低成本:查询免费
查询 + SQL分析 + 可视化(无任何预计算)
例子:加入Service条件,改变时间区间,在秒级计算该服务下的UV、PV和移动端分析数据并实时可视化。
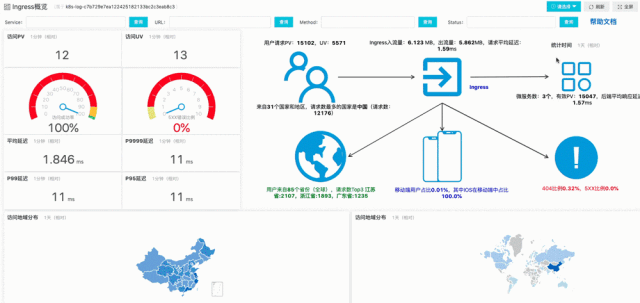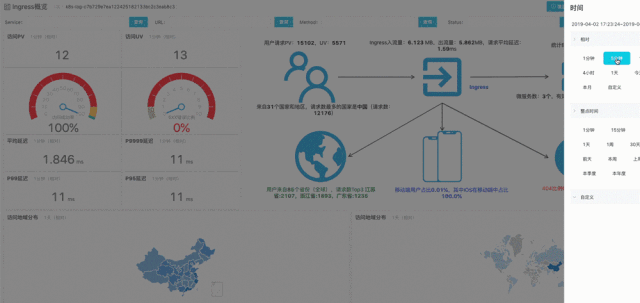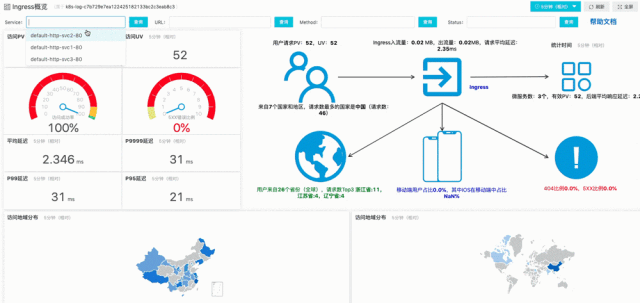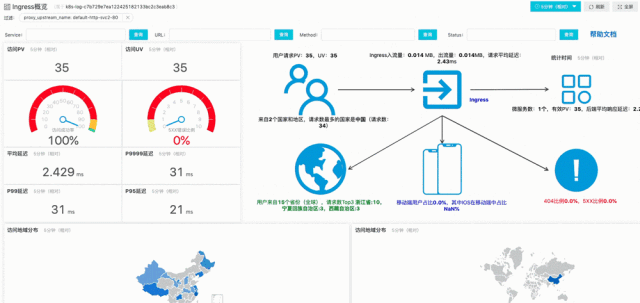
参考:查询分析函数
https://help.aliyun.com/document_detail/53608.html
4. 异常发现(1)聚类:个体与群体
查找、上下文,SQL统计可以帮助我们从不同视角进行数据排查。但如何从正常的数据中判断出异常,却很依赖于领域专家能力和经验:
以系统Latency作为例子,25ms是个绝对数值,只对特定场景有意义:25ms对于一个包大小为4KB 请求偏大,但对于一个2MB 大小的请求是合适的数值。
如何在缺乏领域专家知识情况下如何发现异常? 这时可以借助统计意义上的大数定律:
大数据定律通俗一点讲,就是样本数量很大的时候,样本均值和真实均值充分接近。例如从数据本身的分布规律来比较哪些是异常的。例如通过聚类我们可以快速将“相似”实例汇聚在一起,定位到“小众”的数据(但不一定是异常)。
例子1(时序聚类):数据中心中异常实例
以下是一个集群每天机器的网络流量曲线,我们可以看到大部分都呈现一定的相似性(早晚有高峰,日中比较平稳),但其中有几台机器的行为却和其他有很大的差别, 当个体数目变得更大时(例如每个人的网络流量,行为数据),肉眼已经无法甄别其中的差别,通过聚类的方法可以快速发现其中的分布,查找和群体不一样的机器流量。
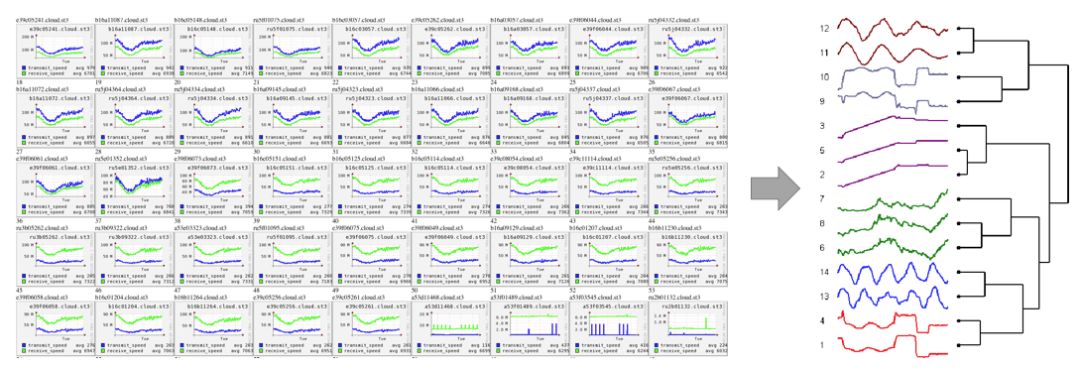
参考:实时时序聚类的文章
https://yq.aliyun.com/articles/662478
例子2(文本聚类):大量日志中容易淹没关键事件
对于不怎么规范的日志系统中调查问题,往往有一种在垃圾里翻找的无力感。因此我们需要有一种能够自动理解日志内容,对文本进行聚类能力。例如测试机器1天secure 日志 50MB(数量在百万级),但如果去除掉变量(例如IP、行数、用户名等),我们可以把日志转变为一种模式(Pattern),如果对模式进行归类后,一般只会有个位数的同类事件,这样就可以快速定位到细节问题。
例子:对1500W条syslog进行聚类后(自动识别变量,替换成*),生成个位数的Pattern结果。可以看到大部分都是重复Pattern日志,可以找到被遗漏的关键日志。
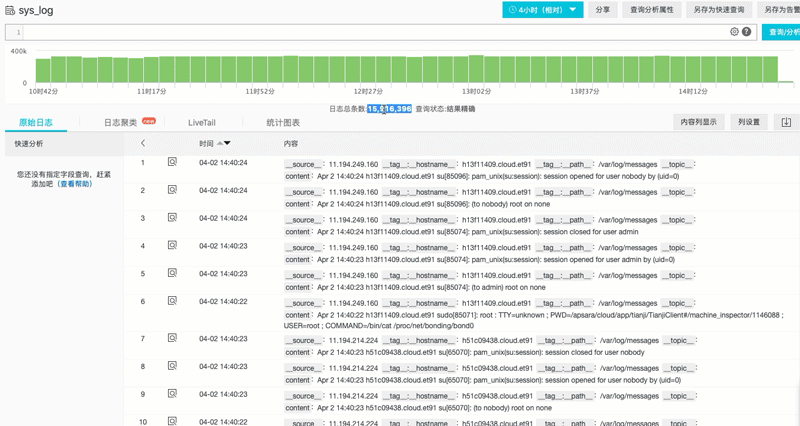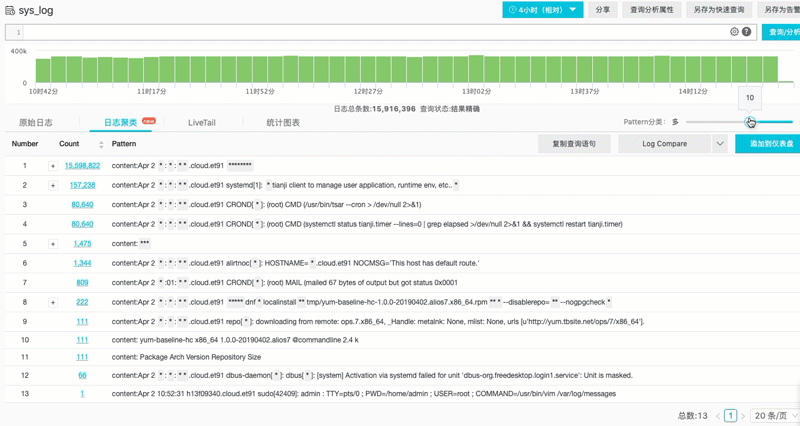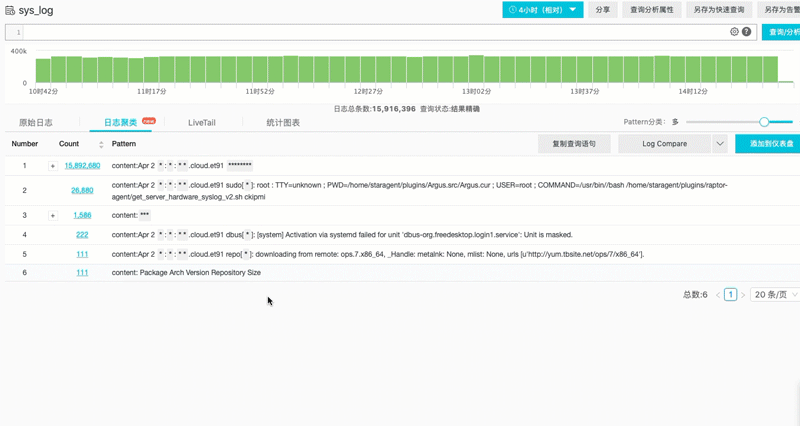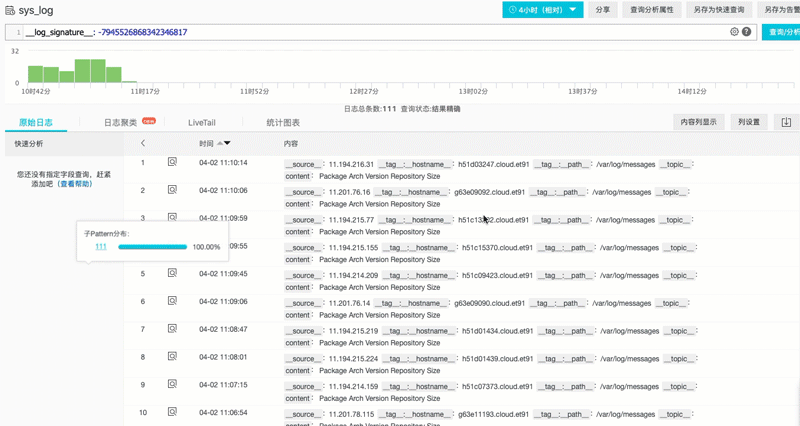
除此之外,还可以对两个时间段Pattern进行对比,观察是否有新的事件(Pattern)产生。
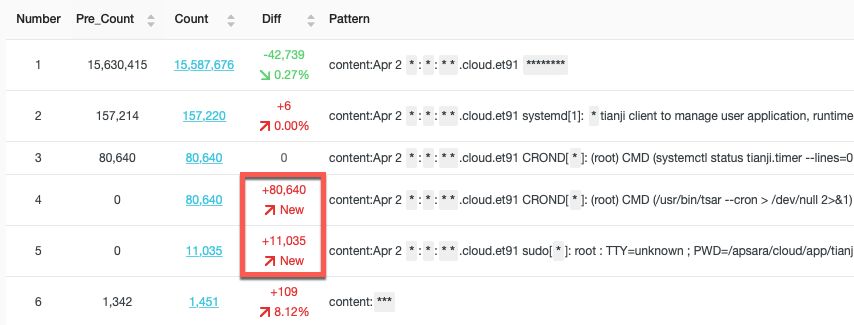
更多参见:
一眼看尽上亿日志-SLS智能聚类(LogReduce)发布
https://www.atatech.org/articles/125117
Demo:
智能文本聚类
https://1340796328858956.cn-shanghai.fc.aliyuncs.com/2016-08-15/proxy/demo/slsconsole/
时序聚类
http://47.96.36.117/redirect.php
5. 异常发现(2)预测与偏差:以史为镜
聚类解决了同一时刻不同实例下的异同点问题,但在很多场景下我们没有别的参照系。在缺乏专家经验情况下,一种简单方法是从历史角度来判别。
例如我们可以用环比和同比函数,和昨天(Yesterday),一周前(Week)和月(Month)进行对比,如果差别大于某一个Threshold(例如10%)可以认为是异常。
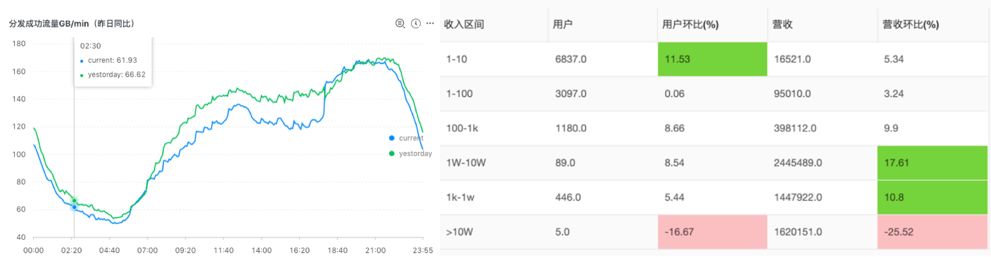
参考:同比环比函数
https://help.aliyun.com/document_detail/86661.html
这种方法看似简单直观,但面对复杂一些场景就会产生失效情况,例如“标准日历 vs 零售日历”缺陷:
在零售行业中节假日、周末会比工作日带来60%以上营收。因此每个月进行预测时,往往会随着月的大小周(例如5个周末 vs 4个周末)造成比较大的偏差。
因此对于非平稳序列数据,通过简单同比环比还不够,我们需要对数据规律进行更复杂的建模。例如可以自动排除数据中的噪声,学习数据的趋势、周期等规模,形成一个根据历史数据自动学习的基线。当前数据和基线有较大偏差时,可以认为就是异常。
例子1:用户使用习惯预测
以线上CPU和存储为例,通过智能时序建模,我们可以发现计算的规律,从而进行更有效的调度。
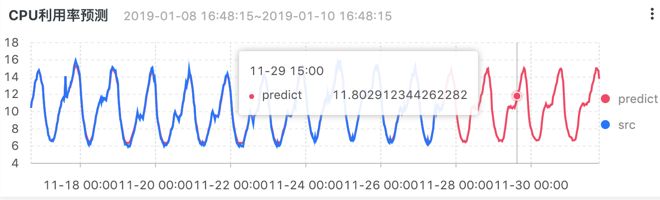
通过预测存储量的增长,可以提前备货:

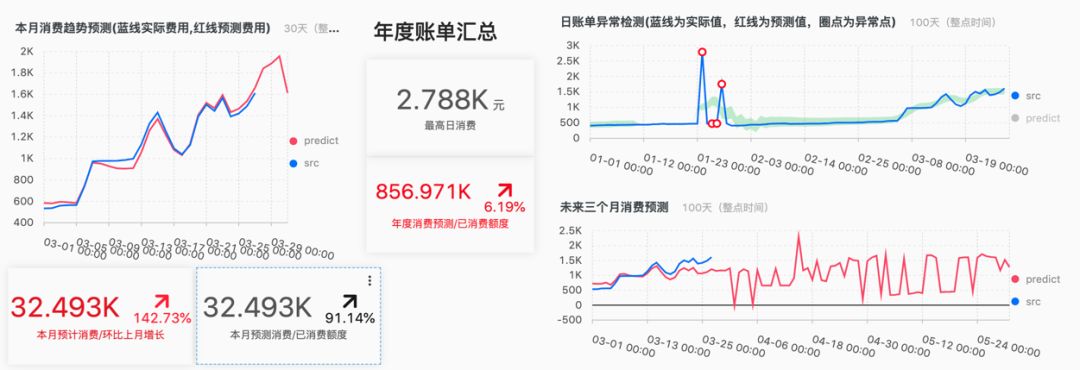
例子2:成本控制与规划
以最熟悉的云计算为例,我们可以把各产品历史账单导入:
通过趋势在月中就能预测本月的账单
预测全年的消费,与预算比例,进行更好的成本控制
对花费进行建模,如出现异常(例如某天费用上升)及时告警与提醒
参考:
时序统计建模
https://yq.aliyun.com/articles/658497
时序异常建模
https://yq.aliyun.com/articles/669164
最佳实践-时序预测
https://yq.aliyun.com/articles/669164
最佳实践-时序异常检测与告警
https://yq.aliyun.com/articles/670718
Demo:
异常检测
http://47.96.36.117/redirect.php
账单预测与分析
https://1340796328858956.cn-shanghai.fc.aliyuncs.com/2016-08-15/proxy/demo/slsconsole/
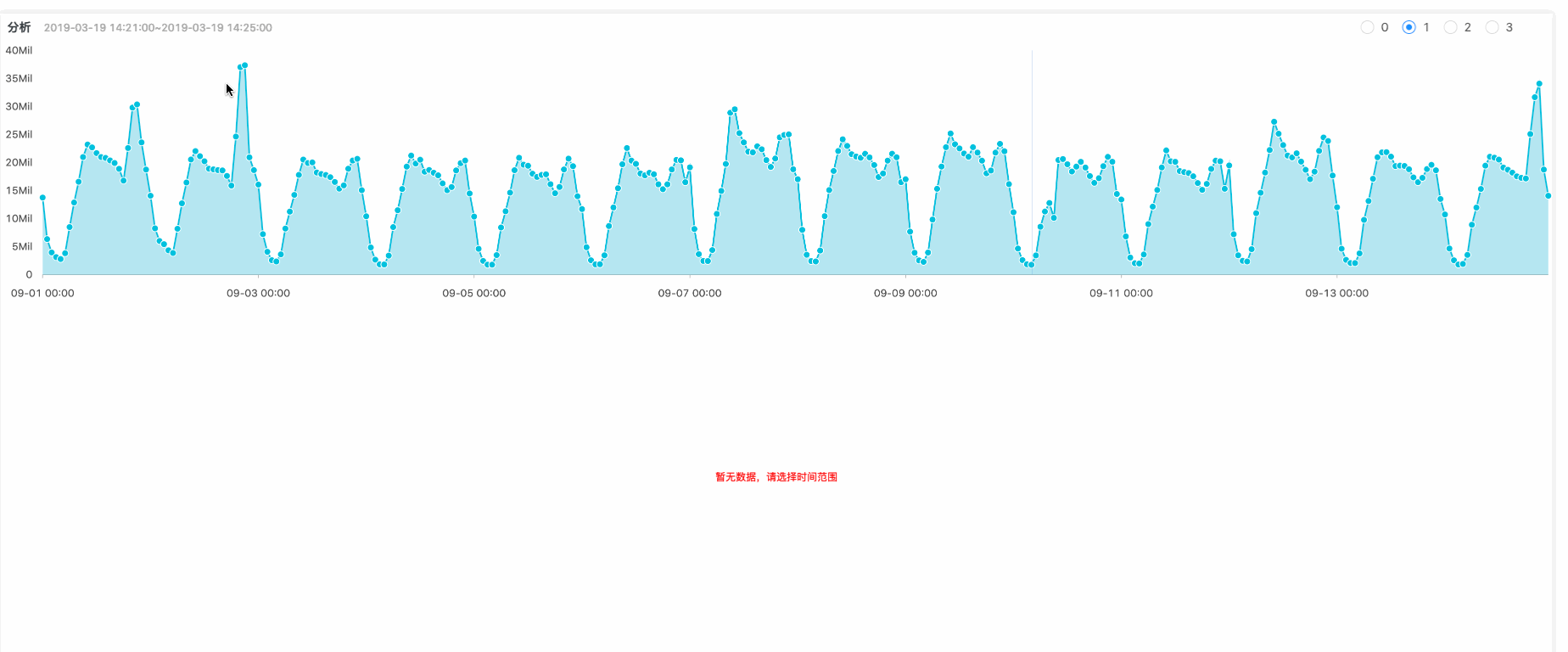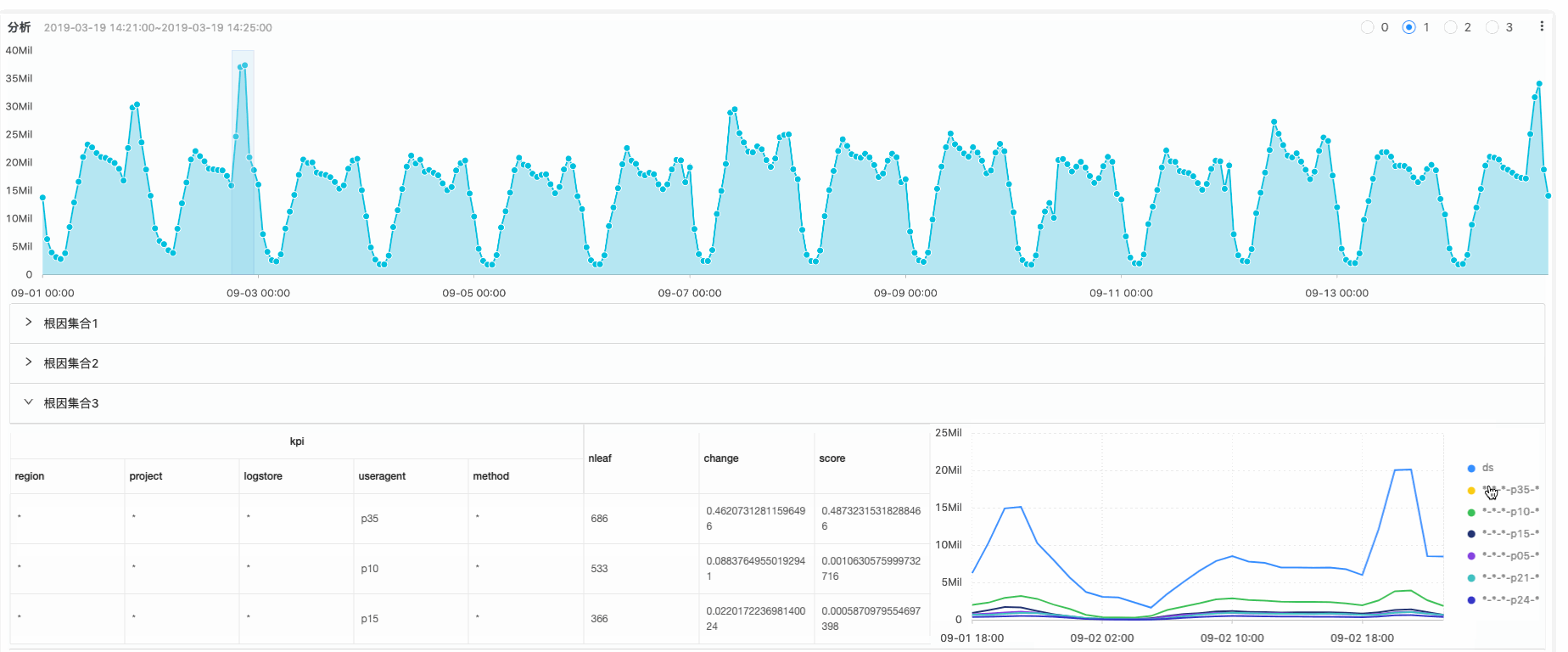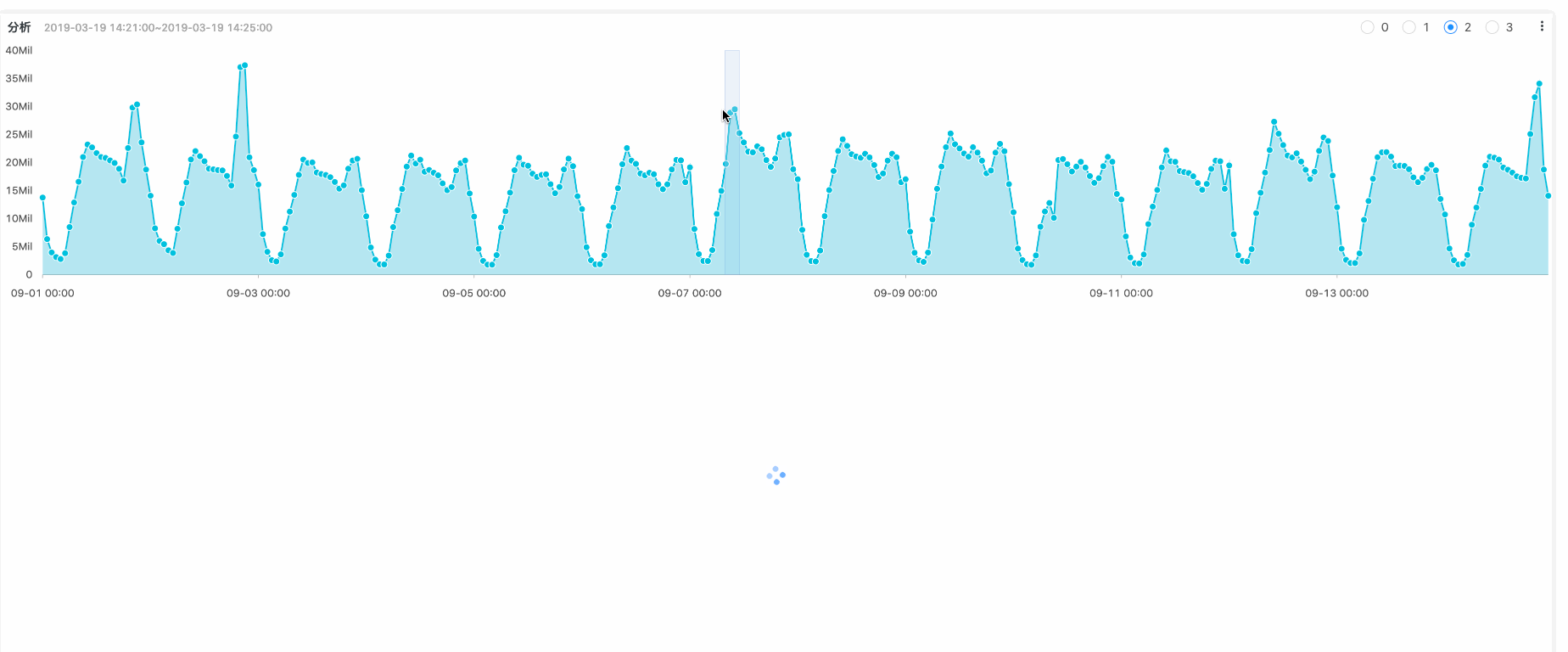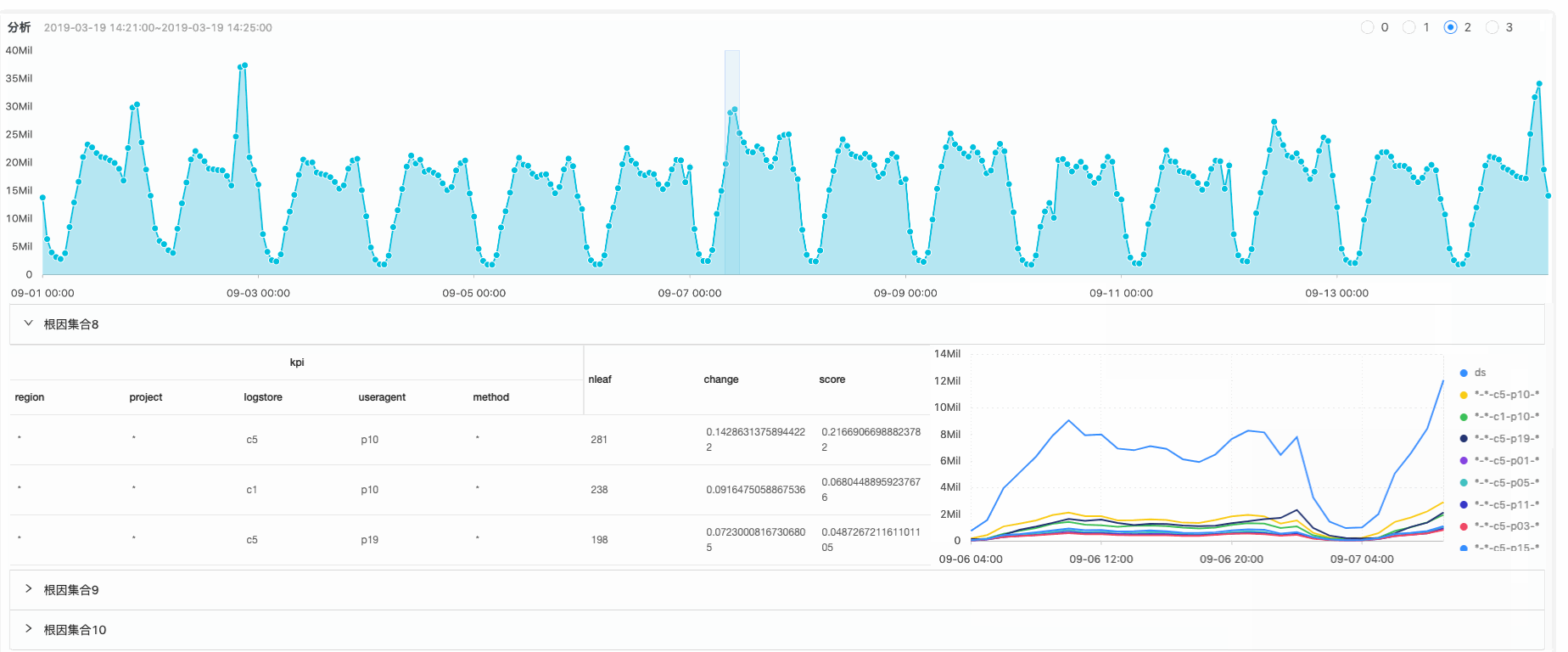
6. 根因分析推导
在监控到异常后,下一个要回答的问题就是找到根本原因(Root Cause Analysis)。例如线上有流量下跌时,是单个节点引发的因为,还是用户的问题,或是全局的问题?
有经验工程师一般会有一个猜疑链:
根据方法Group在一起,先看看Top10分布
没有规律,根据来源端IP进行Top10分布,是否是某些来源引起?
没有特征,把来源Ip做地域转换,看看是否某些省市引起?
感觉有点像,把来源Ip做地域+运营商转换,看看是否某些省市+运营商引起?
很有聚集性,和假设的方向一致,bingo!
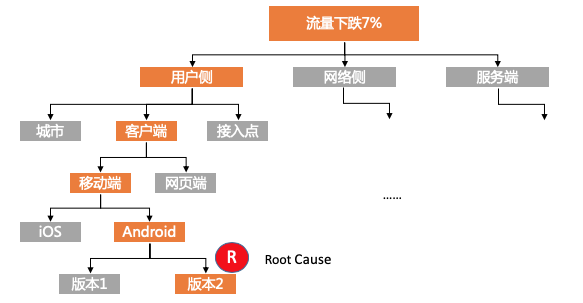
我们把猜疑链进行抽象的话,整个过程实际上是一个高维组合+搜索碰撞问题,既某些条件的组合是否覆盖问题所在:假设构成问题的维度有8个,每个维度里平均有10种组合。那可能构成问题的排列组合会有:8^15 = 1073741824 种。从监控角度来看不可能生成如此多维度的监控数据,并且短时间内巡检到最有可能的错误。因此我们需要寻求更有效的方法。
模式挖掘方法1:频繁集(啤酒和尿布)
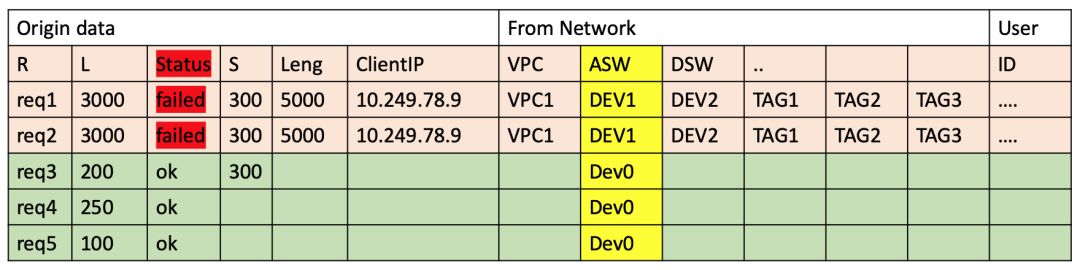
一个最简单的方法是,找到异常数据中的高频小集合:
以如下访问日志为例,我们拿到所有状态为Status为fail数据作为异常集合A
对所有维度组合统计出现在A中的频率:ASW这个维度下Dev1实例,对错误的支撑度为100%,很有可能错误和这个维度下这个属性是有关系的
通过FP-Growth算法,我们可以拿到一个高频组合(ASW=DEV1,Method=Get)和错误有较大关系

模式挖掘方法2:差异集
频繁集的算法有一个缺陷,既过度看中了频繁程度。拿以上例子来看,如果所有请求都在ASW=Dev1下,异常请求集合(A)与正常请求集合(B)中其实是没有差异的。一个改进算法是能够考虑两个集合中差异:
某个集合构成比例远远大于其他维度组合,并且该组合在对比集合(B)中的比例较低,A和B中差异明显。

根因分析方法:引入时间维度因素
模式挖掘方法从统计角度考虑频率的维度,如果数据有时间维度的属性,那我们可以有更多Feature可以提升准确性:
根因特征对陡升陡降的变化量影响?
根因特征贡献的绝对值与相对值
一个改进的根因分析算法:
线上流量有突增
将异常数据(突增)标记
根据搜索算法计算突增的影响根元素,例如Region是某个机房突增引起整体流量突增
参考:规则模式挖掘
https://yq.aliyun.com/articles/681621
Demo:流量抖动分析
https://1340796328858956.cn-shanghai.fc.aliyuncs.com/2016-08-15/proxy/demo/slsconsole/
7.领域建模与推理:心中有图
上述六种武器出发点是方法和工具,但一旦离开了人,这些好比是空中楼阁,因此我们如何把人对系统的经验和认知,能够固化成一种让计算机理解并推断的方式会非常重要,只有这样才能做到最后一公里的完全自动化。
从计算机历史上看,AI在上个世纪七十年代提出后经历过一次小高潮后,受限于数据量和计算规模在90年代后没有大的突破。因此2000后科学家把提升准确性的工作借助另一个方向:
万维网之父"Time Bernus Lee" 提出《Semantic Web》概念,希望能让互联网的内容都有标注,具备一定的语义性,从而使得机器能够去理解人类在互联网上留下的半结构化知识,并做更好的推理
2003年一篇著名Paper提出也提出了一个概念:构建一张不断更新,能够具备一定推理能力的网络,网络能够自动去识别可能的问题。
2005年后,各公司开始尝试通过知识图谱(Knowledge Graph)把知识更有效组织起来应用在各领域中辅助AI。以人脑为例,很容易解释Knowledge Graph:
一个有经验程序员去调查问题时,会有一定的背景知识。例如有大量请求发生错误时,他可能会从脑海里去查找过去是否有类似的现象。当聚焦点到某一个设备时,他可能会从脑海里去考虑设备对应的网络结构。
所谓的历史经验,问题所依赖的环境,环境背后的关联等就Knowledge,通过Graph这种结构能够把零散的Knowledge组成一张体系的图谱在脑海中存储。当有一个新问题来的时候,他可以根据过去的经验,问题背景(例如业务的架构)等作为判断因素,快速去做推理和假设。
与这个过程类似,我们正在构建一张异构,面向Ops场景,可自动更新的知识图谱(Knowledge Base),其中会包含:
各个厂商设备性能规格,参数
常见错误的解释与处理规则
能够引入CMDB、异构数据源数据
系统网络拓扑结构
线上历史数据自动更新(例如历史Pattern、最大值、平均值等)
局部一阶谓词逻辑推理能力
知识图谱可以用在什么地方?
异常推理与搜索,例如网络的拓扑结构对故障的影响
加快研发效率,错误日志可能对应什么原因
经验积累,过去是否有此类Pattern和行为
增强RCA自动化能力等等
(这件工具我们还在持续摸索中,欢迎感兴趣一起合作)
写在最后
作为工程师,充满挑战工作中会无处不在与Bug、异常、黑客、机器及自己的智商做斗争,因此我们必须要把自己从繁琐的体力劳动中解放出来,让算力来辅助我们解决一些典型、繁琐的问题。
今天我们抛砖引玉,把认为的最重要7种能力以产品方式开放出来。无论是问题、方法、还是产品只要给各位工作带来一点点启发就足够了,同时也非常欢迎大家来试用我们的产品,提出建议。
更多精彩









