数十亿次数学运算只消耗几毫瓦电力,谷歌开源Pixel 4背后的视觉模型
选自Google AI Blog
作者:Andrew Howard
机器之心编译
参与:王子嘉、Geek AI
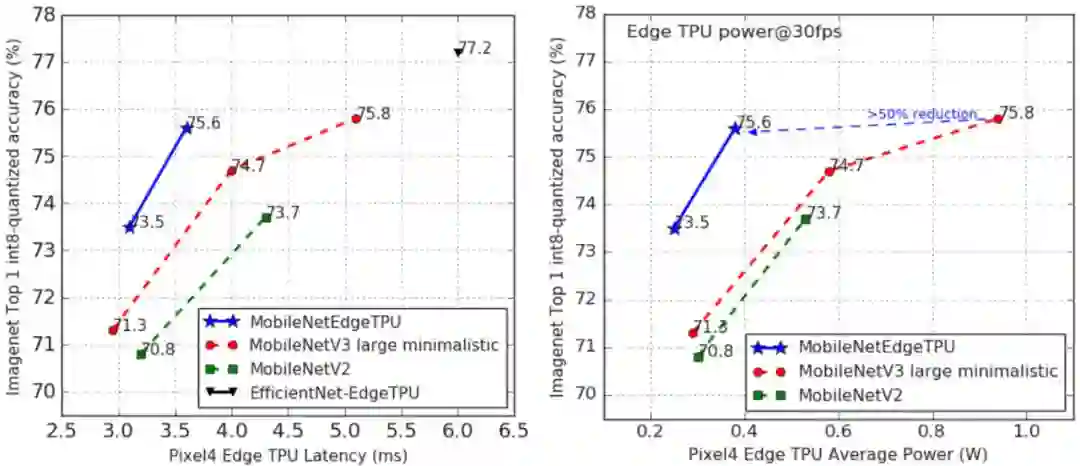
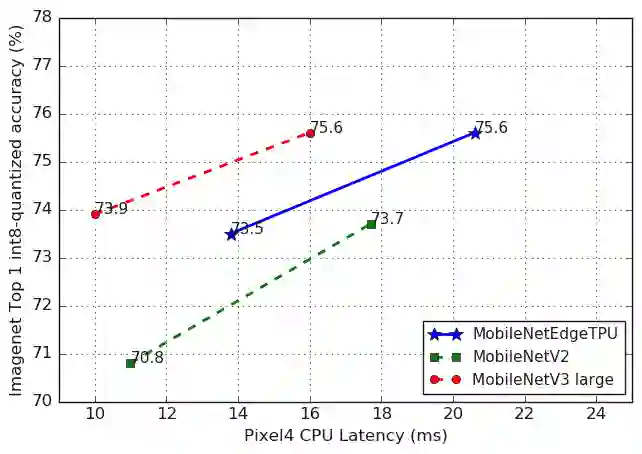
说到今年最热门的智能手机,一定绕不开谷歌重磅推出的 Pixel 4。而 Pixel 4 的强大性能表现在很大程度上还要归功于其背后用到的黑科技——基于终端设备的机器学习。前段时间,谷歌发布了 MobileNetV3 和 MobileNetEdgeTPU 的源代码,让我们一探究竟吧!

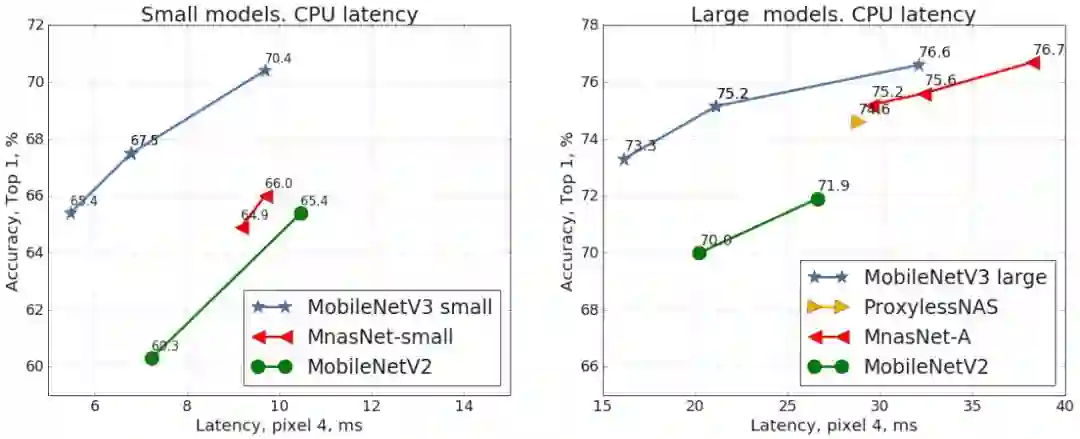
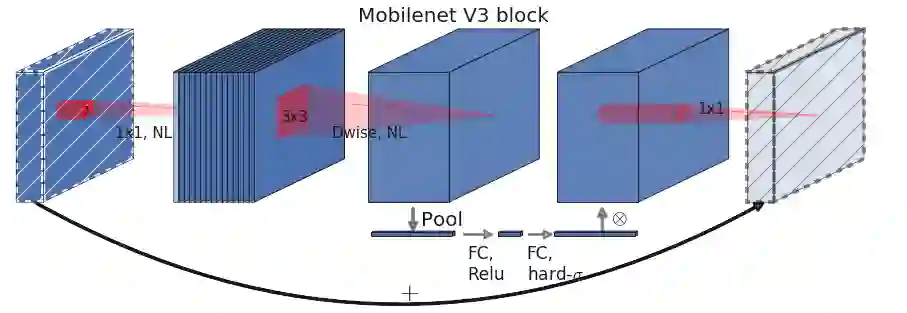
扩展层大小
挤压激励块压缩度
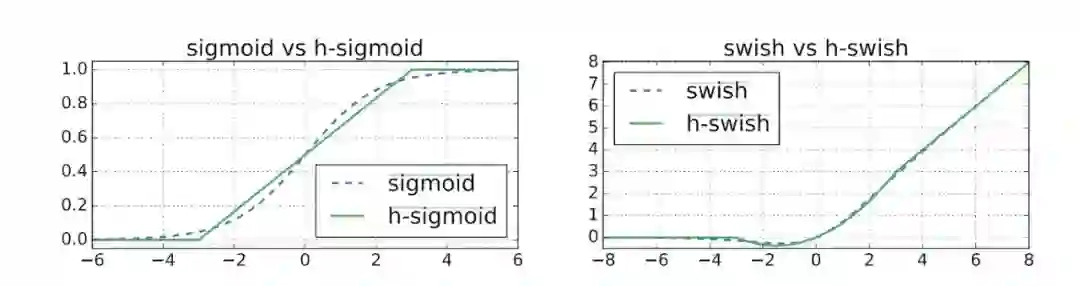
激活函数的选择:h-swish 或 ReLU
每个分辨率块的层数
登录查看更多
相关内容
相关主题



相关VIP内容
相关资讯
相关论文