WebAssembly 的核心语言特性与未来发展

WebAssembly (简称 Wasm) 是目前备受关注的一门新的计算机语言,本演讲从计算机语言技术的角度解析 WebAssembly 的语言特性,以及 WebAssembly 为应用提供安全沙箱机制的原理。我们将介绍 WebAssembly 在浏览器以外的主要应用场景和其带来的价值,以及目前 W3C 正在定义中的一些主要特性及其对未来的影响。
本文整理自英特尔中国有限公司高级技术经理王鑫在 DIVE 全球基础软件创新大会 2022 的演讲分享,主题为“WebAssembly 的核心语言特性与未来发展”。
分享主要分为七个部分展开:第一部分是 WebAssembly 的标准发展;第二部分和第三部分会分别介绍语言特性、字节码与内存模型;接下来第四部分则是程序的控制流与函数调用;第五部分会带大家了解类型系统与内存垃圾回收;第六部分会讲解模块的组件模型;最后一部分会介绍 WASI 与字节码联盟的情况。
以下是分享实录:

在 2015 年,WebAssembly 第一次被对外公布。2017 年 MVP (Minimal Viable Product) 规范完成,并在 Chrome、Edge、Firefox 和 Safari 等四个主流的浏览器上得到支持。到了 2018 年,W3C 工作组发布了三个公开的 Drafts,包含 WebAssembly 的 Core Specification、JavaScript Interface 和 Web API。在 2019 年,WebAssembly spec 1.0 正式发布。同年 10 月份左右,Bytecode Alliance (BA) 由 Intel、 Mozilla、Fastly、Redhat 四家公司成立,主要的目标是构建与推广基于 WebAssembly 以及 WebAssembly System Interface 的安全软件栈。到 2021 年,BA 正式成为非盈利性的组织,微软也加入成为协作会员,到目前已经有大概 30 多家的会员,发展情况非常良好。
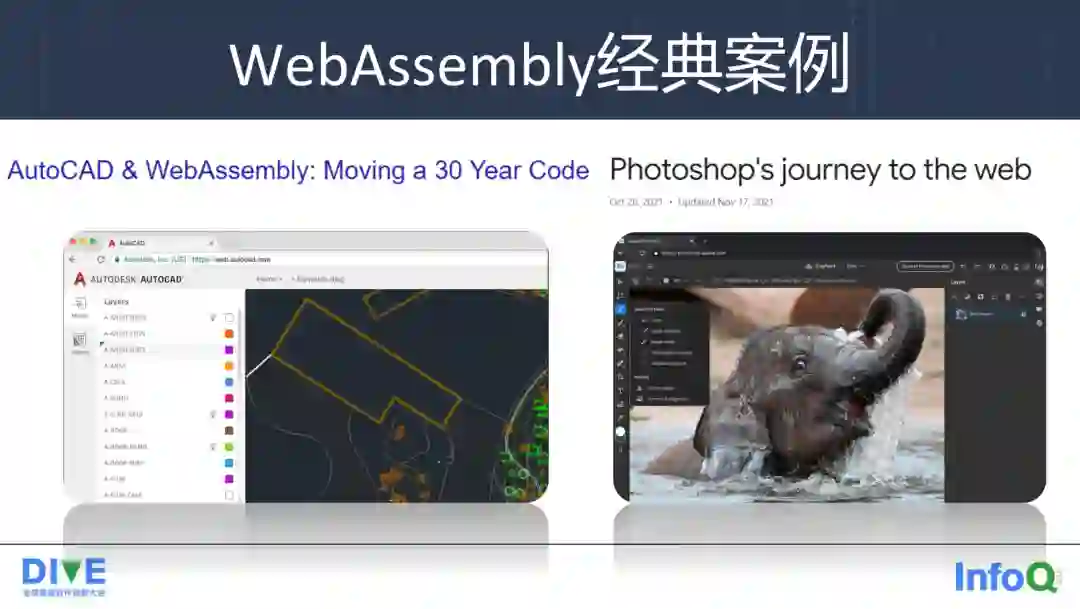
我们看下两个基于 WebAssembly 经典的使用案例。左边是 AutoCAD 在浏览器上运行,能把 30 年积累的桌面应用代码移植到到了浏览器上面,这主要归功于把大量的 C/C++ 代码转换成 WebAssembly。2021 年另外一个标志性的事件就是 Adobe 也把它的经典的软件 Photoshop 搬移到了浏览器上面。据相关技术分析,Photoshop 的 Web 版应用主要也是基于 WebAssembly,当运行应用的时候,可能会有高达 1G 左右的本地磁盘的缓存,只需下载 10 多兆的网络资源,启动时间大概 3 秒钟左右。整个应用充分地利用了 WebAssembly 和多核的技术,在运行一些操作的时候,最热的 20 个函数里面,SIMD 向量化计算的占有率约为 40% 左右,这说明通过类似于向量化计算的能力,WebAssembly 已经具备了支持开发强计算应用的能力。

我们这里首先对 Wasm 语言的特性做一个总结。它包含了二进制和文本的两种格式,它的执行模式是基于 Stack 的一种执行模式。它定义了四种基本的数据类型,就是 32 位、64 位的整数,32 位和 64 位的浮点精度。
Wasm 的内存设计也很有特色,包含了托管的内存和非托管内存类型。非托管内存也叫线性内存,一个 Wasm 实例可以有多块的线性内存。目前线性内存的布局是由编译器来定的。为什么要了解这个呢?因为现在 WebAssembly 是支持多种前端语言的编译,在每个编译器有自己的内存布局的时候,会导致不同语言模块之间静态链接的技术挑战。
Wasm 的流控是一个结构性的流控。它的函数调用需要使用函数表 (Function table)。如果和基于 C 语言编译的机器指令相比,机器指令里可以直接跳到目标的物理地址,这里是一个间接地址。Wasm 的函数调用操作码后面都跟着一个索引号,这个索引就是目标函数在 Function table 里面的索引值。如果是间接调用函数,则需要做函数类型检查。
Wasm 支持一系列关键组成元素的 Import and Export,一个 WebAssembly 程序会定义需要外部导入什么样的元素,也可以定义哪些元素可以暴露给外部来访问,为它的宿主环境,例如浏览器的 JavaScript,或者在独立 Wasm 引擎的调用者,提供了一个可以通过编程的方式,来控制和访问目标的 WebAssembly 应用对象的能力。
另外一个特性是对硬件向量化计算 SIMD 的支持,像刚才介绍到的,Photoshop 里面大量用到 SIMD 这种能力。
最后,它是个强类型的 Type system,它也定义了 GC 和组件的模型。
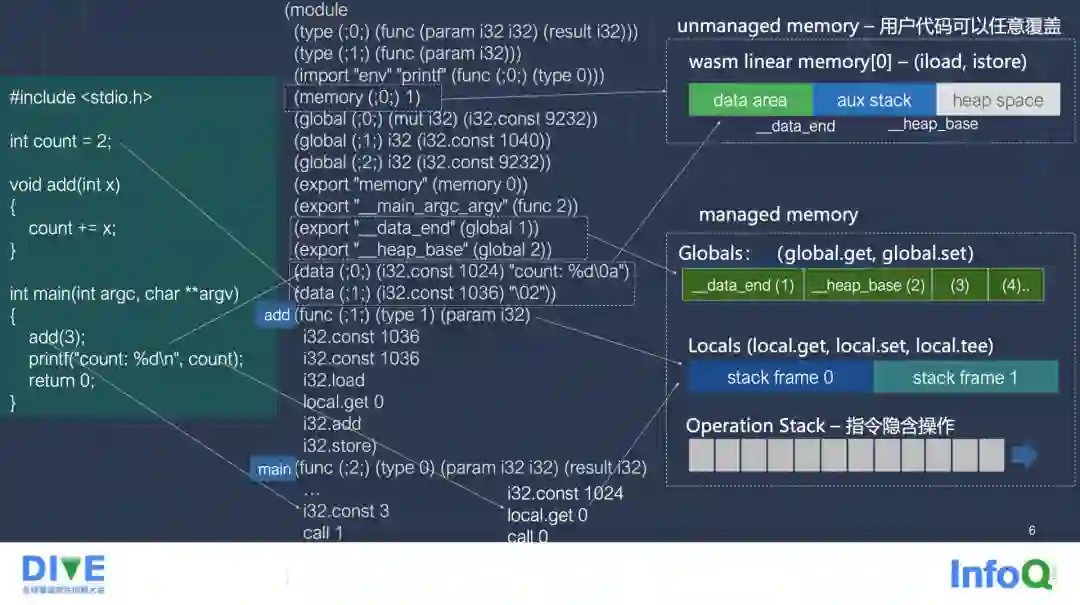
我们使用一个例子来介绍 Wasm 的字节码和内存模型。在最左边是一段 C 语言的源码,这段代码会被编译到屏幕中间 WebAssembly 的字节码,右边展示在运行态的内存布局。左边的源码定义了一个全局变量 count,一个函数 add,add 会把输入参数 x 再加上 count,把结果更新到 count。
在 main 入口函数里,调用 add(3),然后打印 count 值。中间这一段就是编译 C 程序后生成的 WebAssembly 编码。一开始包含几个函数的类型(type)定义,0 和 1 是 type 的索引值,你可以把它可以看成一个表,表里面有索引来标识了每一个类型。对应到所有引用到的函数,像代码中的 add、main、printf 函数。
下一行表示要 import 一个 printf 函数,这个函数在字节码里面本身没有提供实现,需要宿主环境来提供。接着定义了一个 Memory, 线性内存空间。再下面定义了三个 Global,Global 是 WebAssembly 定义的可以作用于全域的变量,不一定对应到源码里边的全局变量,这里可以看到源码里面的全局变量 count 并不是被映射到 WebAssembly 的 Global 里面的。每个 Global 也是有编号的,同时包含其原型的定义以及初始化的值,像 9232、1040 都是它的初始化的值。
接着 Export 它的 Memory 对象,通过这样宿主环境可以拿到 Wasm 程序的 Memory 对象进行访问。这个 Wasm 代码导出 (Export) 了三个对象,第一个 function #2,就是暴露给宿主环境的 main 函数。它还导出两个 Global,一个是 data_end,一个是 heap_base。
接下来的数据 (data) 表示 Wasm 程序的静态数据,每个数据有一个编号和线性地址位置,编号 0 就是 printf 打印的字符串的内容。第二个 2 是代表 count 的初始值,count 在 C 源码中是一个全局变量,它实际上是在线性内存的 data 区。
下面索引号为 1 的函数是由 C 源码 add 函数编译过来,包含了函数类型说明,和上面函数 type #1 是对应的。下面另外一个函数 (索引 #2) 对应到 main 函数,type #0 是它的类型的定义。
右边上部是一个线性内存,支持 Wasm 编程来任意访问其中的任何一个位置。线性内存的读写访问需要通过字节码 iload 和 istore。iload 把线性空间中的数据移动到操作栈,其具体过程首先将偏移量设到栈里边,调这个指令之后它会从栈里面取偏移量,从线性空间的偏移量去访问拿到值,再把值压回到栈里面。istore 指令则是执行一套反向的流程。
LLVM 编译 WebAssembly 的时候,有一个约定的内存布局,首先一开始是个数据(Data)区,主要是存放源码的全局数据和静态数据。Wasm 代码里面访问这些变量的时候,是通过使用静态的偏移量调用 iload、istore 来完成。中间的 Aux Stack 是 Wasm 程序运行中做辅助栈使用的,它与数据区的边界是有一个 Wasm Global 来指向的,叫 data_end。data_end 是个 Global,前面我们已经看到将它 Export 出去了。Wasm 程序调用 malloc 时从其自己的 Heap 里面分配数据,heap 区的起始位置是通过一个叫做 heap_base 的 Global 来指定的,它的初始值是编译器在编译时候已经计算好了,回到上面可以看到 Wasm 文件里包含其初始化的值。
线性内存之外的其余 Wasm 内存是受管内存 (Managed Memory),这些对象的目标地址不是用户完全来控制的。第一种是 Globals,可以把它看成一个一维的数组,这里 data_end 是索引值为 1 的 Global,heap_base 是第二个 Global,还会有其他的一些变量按顺序依次排下去。它的访问有专门的字节码,叫做 global.get,或者 global.set,这些字节码后面会跟随目标 Global 的索引值。
还有一种受管内存叫做 Locals,Locals 对应的字节码叫做 local.get、local.set,以及 tee。Locals 它是以当前的栈为基准的,在执行指令的时候,缺省就是当前的栈作为基础来进行访问和定位的。源码中基本类型的函数局部变量,可以使用 Locals 来映射,其他类型局部变量则会使用线性内存中 Aux Stack 来管理。和线性内存操作相比,Global 和 Local 操作目标的索引值是固定在 Wasm 文件中,说明其在编译时刻决定。而线性内存的访问地址是由 Wasm 程序逻辑本身在运行时来决定。
最后还有一种叫做操作栈 (Operation Stack),Wasm 许多操作码里边隐含操作栈访问,但没有任何操作码可以显式控制操作栈。比如说前面看到的 add 操作,它会自动在栈里面取两个数,把计算的结果再返回到栈里面去。

下面介绍一下 WebAssembly 程序的控制流,以及函数调用。
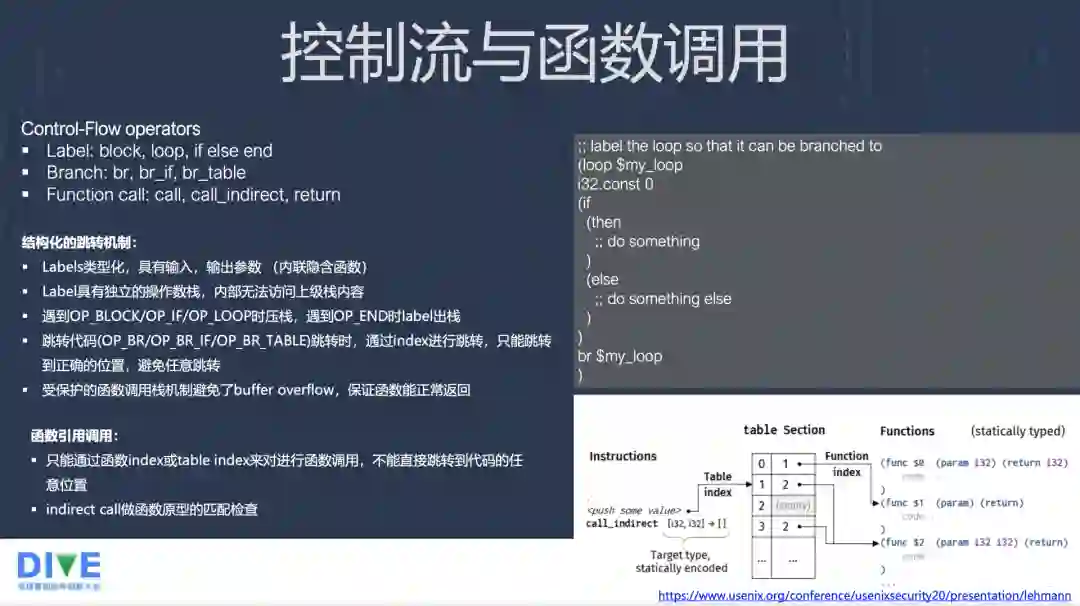
WebAssembly 设计一种结构化的控制流,它定义了几类相关操作码,第一类就是定义一个 Label,比如 block 是定义一个块,loop 定义一个循环块。第二类包含 if、else 和 end 三种操作指令,这种方式就更接近于源码的语义了,而非像 C 语言编译生成的条件跳转目标指令。第三类指令表示跳转,这种指令比较接近编译后的跳转机器指令。另外一类指令是 Branch,如函数的 call、call_indirect 和 return 返回。
在屏幕右边是一个 Wasm 文本方式表示的简单例子,它是一个循环,循环有个标识为 my_loop,对应到 Wasm 二进制里边是个索引号。代码中压一个常数 0 到栈里边,作为后面比较的条件。if 操作码后面跟随一组满足条件下执行的操作码,之后可能会跟随 else 操作码,else 后面会有一系列指令,else 结束后会有个叫 end 的指令。代码后面有一个 br 操作码,执行跳转到 my_loop。
Wasm 结构化跳转机制有几个特点,首先它的 Labels 是类型化的,它具有输入和输出的参数。所以在右边进 if 之前会压栈,进入这种 Labels 之后,会有它的一个独立的操作栈,它可以保证在里面有 pop 类的操作,不会把上级的栈破坏掉,而且退出栈的时候,它很容易回溯到上级栈的位置。
另外它的栈的跳转不能像 C 语言跳到一个任意的 Label,它只能向上返回跳转,它通过一个 Index 向上返回一级或者若干级,这种方式它很有效地避免了 Buffer Overflow 的可能性。
函数调用操作码后面带的是一个索引值,索引代表函数在 Table 里边的位置,Table 会真正指向函数它的物理位置。indirect call 会像 C 语言定义的函数指针的调用,它的索引不跟随在指令码里面,而是从栈里面取,这样可以通过压栈,相当于把函数指针传进来,再调用它。

刚才在字节码里面已经看到类型信息,它所有的函数都是有一个类型的定义,而且类型是有从 0 开始的索引编号。垃圾回收特性 (GC) 目前进入了文本可用的提案 2 的阶段,它包含着一系列的所依赖的 Spec,如引用类型 Reference Type,还有就是类型化函数引用 Typed Function Reference,类型导入这些提案等。
WASM GC 同时又引入了一些新的类型结构,在右下角可以看到,引入了类似于像函数和数组的类型结构。Wasm 的类型体系的特点是,它主要目标是描述低级的数据布局,并不有源码层面的信息,它的子类型,比如说 A 是 B 的子类型,它主要是指内存布局有覆盖关系,而不是类似于 C、C++ 或者是 Java 里语言层面的显式继承的定义。在语言层面可以没有任何的继承的描述,只要它符合子类型的条件,它类型就会类似一个父子关系。在生成的目标的指令里面,操作码后面会带操作对象的类型索引号。
如果大家熟悉 C 的编译的话,就知道 C 的生成目标里面是没有类型的,所有的类型都是在编译的时候,编译器知道所有的类型信息,但是不会在生成目标的机器码里提供类型信息。WebAssembly 把类型信息放到目标文件中,因为它要提供一种中间层,接近于底层的机器但是又不是真正机器底层的这么一种技术。
我们认为 Wasm 这么设计的确是有一些好处的。把类型信息直接传送到发行的模块里,这样有利于脱离编译器语言的依赖来实现模块的连接,即便都是从 C 语言源码编译过来,不同的编译器对于类型的定义有可能是不一样的,但是类似于结构还有数组,各自的理解或者约定是不一样的,更别提不同的语言它们之间的约定,语言层面也很难保证一致。所以我们都把目标的类型放到二进制的模块里面,这样不同的语言、不同的编译器它们之间的连接就会更加容易一些。
这样也会减少运行时刻对隐式类型的依赖,很多的类型都显式地告诉了 Runtime,Runtime 不再需要去做水面以下的部分。另外它会有利于在加载时刻(Loading Time)的类型验证,因为类型信息已经在字节码里边了,它很容易去做类型的推导和验证,看压栈或者是传参是不是符合它的目标类型,这样的话可以尽可能减少在运行刻的类型的验证,因为在运行刻做类型验证是非常耗 CPU 的,这样可以让它的执行效率大量的提升。
下面介绍在 GC 特性中引入的一些新的一些元素,首先是结构。结构的成员变量还是用索引号来访问的,比如说你 new 一个对象之后,get 或者 set 一个成员变量,成员变量通过 index 来访问。数组就是同样类型的多个元素的聚合,每个数组也是透过一个索引来进行访问的。另外函数就引入了一个类型化函数指针,叫 ref.func 和 ref.call_ref,可以让你直接传函数指针,而不是传一个索引。它的好处就是能够极大地加快函数指针调用的速度,对比目前因为要做大量的 Type Check,所以通过 indirect 效能不是很好。运行刻的类型引用,它可以从一个 Type 去生成一个 Type 的引用,Type 引用可以通过变量或者传参来进行传递。另外还有未装箱的标量,还有类型的测试和等价,子类型化,还有运行刻的类型强转等等这些元素。(注:最新的 GC 提案在此基础上有进一步改动,请读者以 w3c 的官方提案文本为准)
右边是一个关于结构的例子,首先下面它定义了 time、point 结构,time 包含一个 32 位整型和 64 位的精度的浮点成员。point 包含 3 个 64 位的浮点组成的 xyz 成员。下面是一个函数,它的传参是 point 结构的对象,因为 p 是它的传入的参数,get $p 就是把 p 它的指针放到栈里面,按它的 point 类型取 x 字段,x 最后是一个索引号,取到之后,把它放到栈里边。把 x 值从栈里面取出来,再赋到 y field 里边,这就是这个函数做的事情。再下面使用 struct.new 来对结构进行分配,struct.new 后面跟的是一个类型,后面会跟着每一个成员初始化的值,它会返回一个结构的引用对象。
WebAssembly 并没有真正定义 GC 本身实现,而是定义了完善的 GC 系统所需要的工具,它更想定义了一个工具箱,每个 Runtime 可以通过使用这个工具箱去实现自己的 GC。
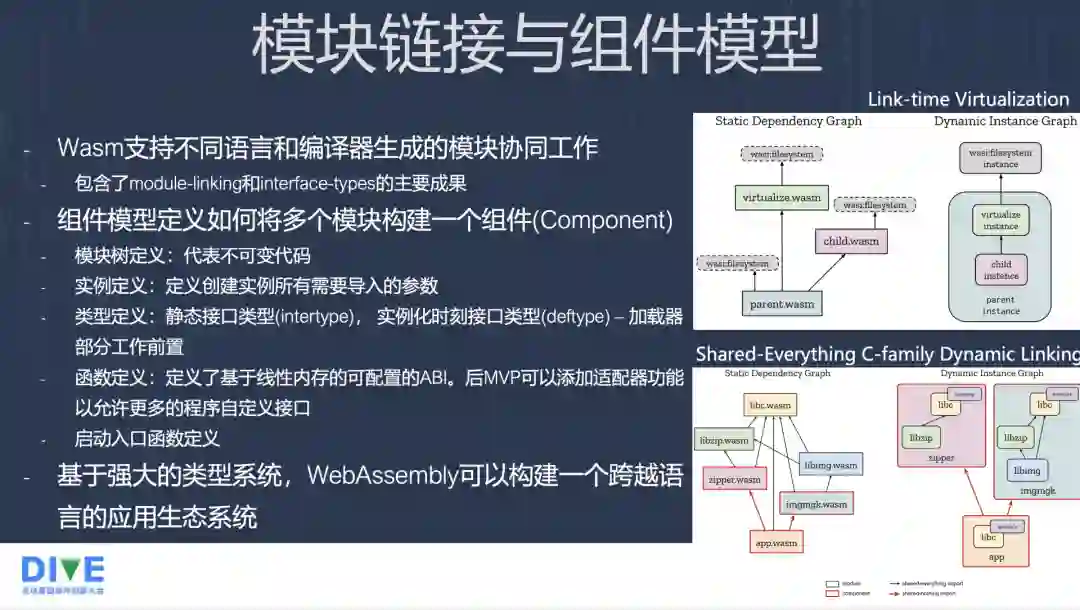
模块链接与组件模型,目前这块的规范也在制定之中。首先需要标准化模块之间的链接,module-linking 的 spec 定义了一些典型的链接的模式。屏幕右边是两种比较典型的链接模式,上面这种叫 Link-time Virtualization,描述了所有 WASM 模块之间的静态依赖,比如说 parent,它也会去访问 WASI 文件系统,child 也会访问文件系统,virtualize 模块也会访问。我们并不想用 child 能够真的去访问物理的内存,可以引入 Virtualization 模块,它会向 child 提供 WASI Interface,所以 child 说需要去访问 WASI Interface,实际上是让 Virtualization 去给它导出一个让它使用,Virtualization 模块中间会做一些转换或者一些检查,它会去实际访问真正的 File System 模块,这样对于 child instance 它所看到是个虚拟化的接口,这叫 Link-time Virtualization。
还有一种模式叫 Shared-Everything C-family Dynamic Linking,可以在动态的过程中,由不同的模块组成不同的实例。比如说 zipper,它也引用了 libc,它可以构建一个单独的一个实例,img 它可能也引入了一系列,包括 libc、libzip,但是它们可以组织成一个 instance,它有它自己的内存空间和一个实例所需要的元素,既具有很好的隔离性,又具有很好的灵活性。
组件模型一个组件会包含一系列的模块,它现在定义了一个组件有若干个组成的部分,一个是它的模块数的定义,主要就是静态的模块,它的实例定义。它会定义好有哪些实例,实例需要导入的是什么东西。然后是类型的定义,类型定义包括静态的类型定义,还有实例化时刻的类型的定义,实例化时刻的类型定义有点像如果用 Linux 系统的链接器,当你编译的时候,你只需要知道链接对象的引入符号就可以了,它引入什么你并不关心。但是当你实际加载,开始运行链接的时候,每一个被链接的链接库文件,它所依赖的这些符号也需要被解决,它要像一个链式一样去找它所有被链接的符号,最终程序才能跑起来,这个时候就引入了很多的不确定性。在这把后面那部分链接的过程,把整个链接链条都会定义到这个组件里面去。这样在实例化的时候,在定义的时候,就把部分在将来做的事前置。函数的定义目前主要还是基于一个线性内存的新的 ABI,但是它已经有一部分可配置的能力。目前还有一个叫 InterfaceType,这样给程序提供了更多的自定义这种接口的能力,
以上就是 GC 现在的一些大概情况。从上述的信息来看,基于 Wasm 的强的类型系统它有很大的灵活性,它就像一个积木式的系统,可以从不同的语言搭建出很多的模块,这些模块又可以搭建很多的组件,这样,在未来它会有非常好的潜力,去构建一个跨越语言的应用生态系统。如果一切像预期一样发展,我们可以预见在未来,也许 WebAssembly 是一个远远比现在要更加广泛的一种语言生态。

字节码联盟是一个以 WebAssembly 技术为中心的开源实现的非盈利组织,目前有非常多的程序员加入进来,而且加入的速度也是非常快的。目前在组织里面主要在做包含开源的 Runtime 项目,还有 WebAssembly System Interface (WASI),以及一些工具和组件生态的方案。最近字节码联盟 TSC 的章程发布了,本人作为技术委员会创始的成员参与了全程的章程的定义,这个章程兼顾了多方面的考虑。大概花了接近两个季度的时间才完成,也参考了很多目前比较成熟的社区的一些章程,大家有兴趣可以去看看。
字节码联盟目前 Runtime 开源项目主要有两个,一个是 WASMTIME,另外一个是 WebAssembly Micro Runtime,WebAssembly Micro Runtime 最早是由 Intel 开发的,在 2019 年贡献给字节码联盟了。目前除了 Intel 持续在上面开发之外,有很多企业如亚马逊、索尼、蚂蚁、小米、阿里巴巴在上面也贡献了很多特性和功能。
WASI 是什么?WASI 是标准化 WASM 的模块和 Native 宿主环境之间的一个调用接口,这个接口和上层的编程语言是无关的。其中的 wasi-libc 提供了 libc 的支持,把原来的像底层和 Kernel 对接 syscall 调用接口换成了 WASI 的 Interface,这样大家可以在 WebAssembly 里面继续调用类似于 FileOpen 这样的系统调用,可以在所有的 Runtime 上运行,达到一个很好的跨平台特性。
另外它定义了一个 Capability-based Security,很简单的说,启动一个实例的时候,可以给它指定一个目录,在实例里面 Wasm 应用无论怎么访问目录,它看到的根目录就是你指定的物理的目录,所以所有的一切操作都是在本机一个子目录里面运作,这样它就没有能力去访问整个磁盘上的其他的一些它不应该访问的文件系统。WASI 目前的发展是非常好的,有很多标准都在进行之中,大家有兴趣可以在 W3C 的网站上了解一下。

最后给大家快速介绍一下 WebAssembly Micro Runtime (WAMR) 开源项目,因为这个项目是我们团队从头到现在一直在参与的,也希望大家能更多了解。WAMR 是基于 C 语言实现的,它有两个解释器的实现,一个叫 Fast,一个 Classic,Fast 比 Classic 要快一倍左右。关于它的一些实现,我们之前也输出过一些文章,大家有兴趣可以去了解一下。
WAMR 支持 JIT 和 AoT,JIT 和 AoT 目前是基于 LLVM 框架来实现的,整个 Runtime 的特点就是说它的 VMCore 很小,在 100K 以内,但同时它的性能又非常好。一方面借助 LLVM 这个非常好的编译框架,它的性能和 GCC 相比,根据不同的 Workload,从 60%、70%、80%、90%,甚至还有快过 GCC 原生编译的。另外它的 AoT 也是个很特色的设计,因为它有个完全自定义的 AoT 的加载机制,不依赖于系统的 Loader,它可以在很多的平台上都可以用,像 Linux 或者 SGX 环境,甚至像一些 MCU 上的嵌入式操作系统,也可以使用 AoT 的 Loader。另外它支持向量化计算,对于 Intel SGX 和 TDX 这种安全的执行环境有非常良好的支持。它还支持多线程、pthread、Reference type 和 Multi-modules 等丰富的特性,欢迎大家能花点时间了解体验下。
点击底部阅读原文访问 InfoQ 官网,获取更多精彩内容!
60 岁周星驰招聘 Web3.0 人才,要求“宅心仁厚”;马斯克计划裁掉推特 75% 的员工;Linus 致开发者:不要再熬夜了 | Q 资讯
可能是最严重的云存储数据外泄事故之一:微软承认服务器错误配置导致全球客户数据泄露



