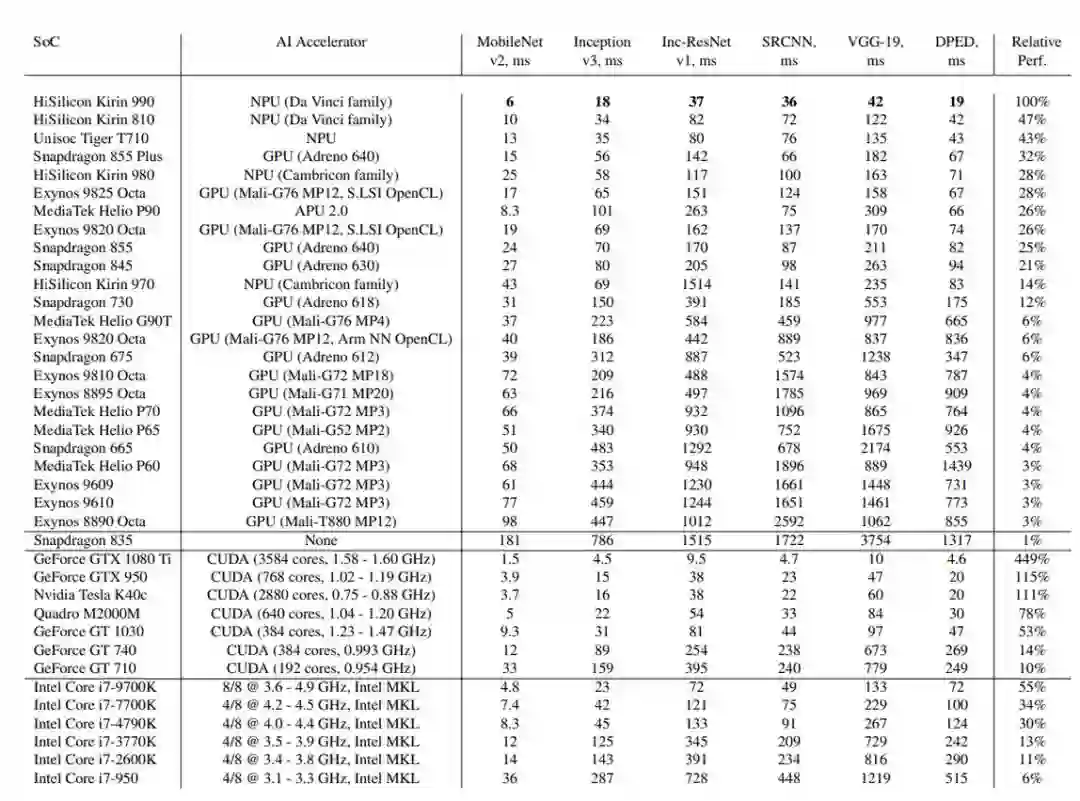
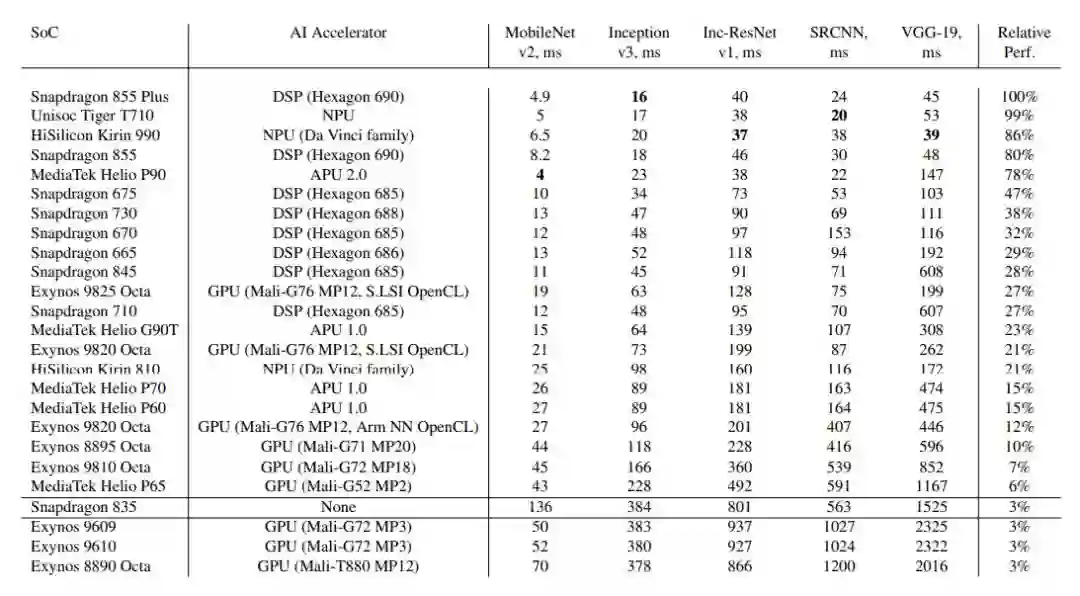
麒麟990远超骁龙855+,华为手机领跑前五:2019安卓手机A跑分出炉
选自arXiv
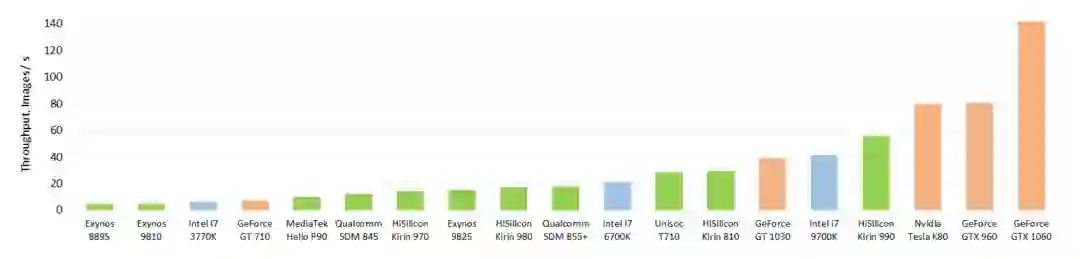
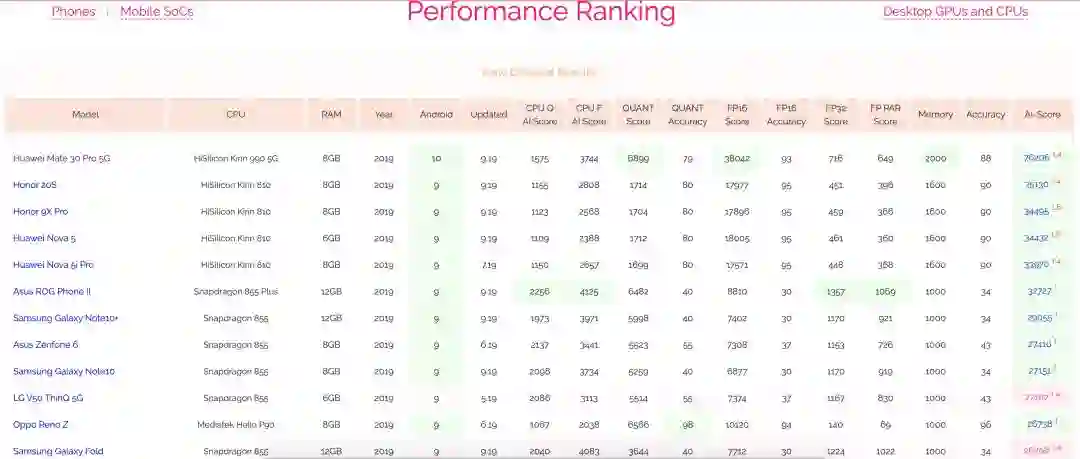
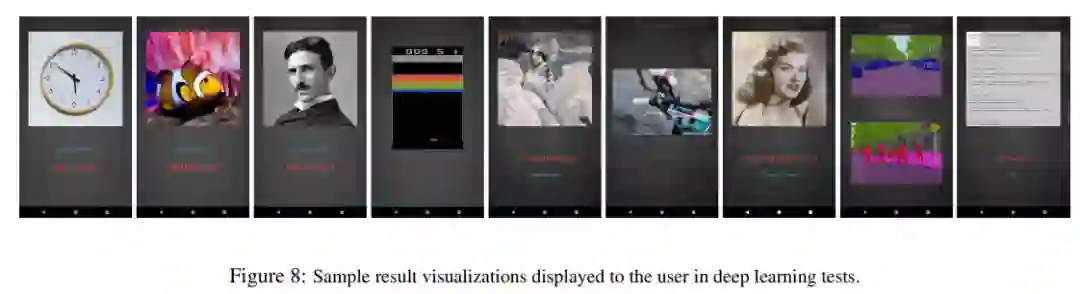
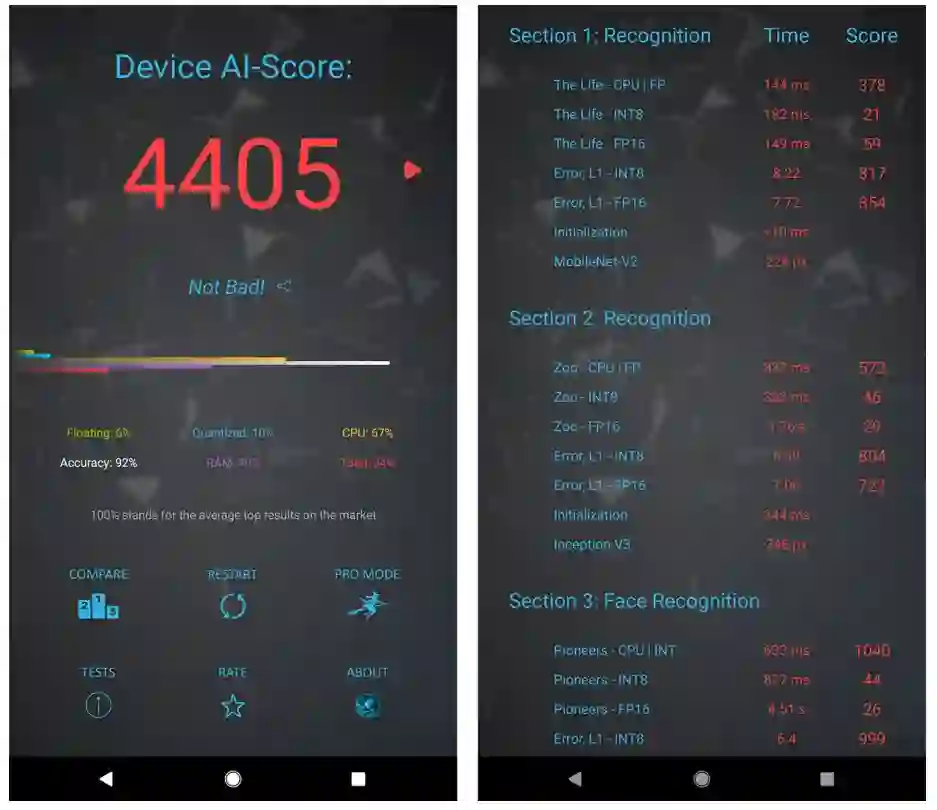
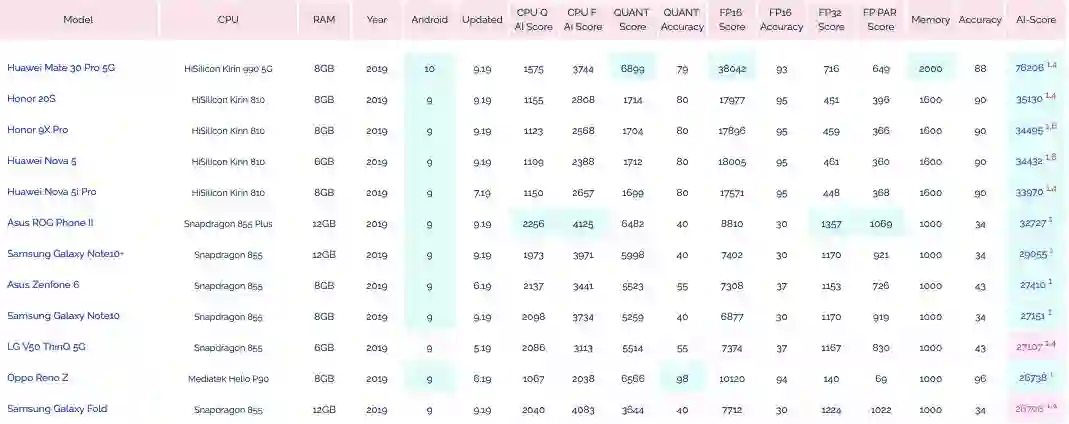
为了测试移动设备芯片的深度学习性能,瑞士苏黎世联邦理工学院去年开发了一款名为 「AI Benchmark」的应用,对多款搭载深度学习加速芯片的移动设备进行基准测试。最近,AI Benchmark 已经更新到了 3.0,研究者也发布了最新的测试结果。报告显示,麒麟 990(5G 版)的 AI 性能远超高通骁龙 855+,性能甚至接近常见云服务 GPU 英伟达 Tesla K80 的四分之三。
论文地址:https://arxiv.org/pdf/1910.06663v1.pdf
AI Benchmark 官网:http://ai-benchmark.com/index.html
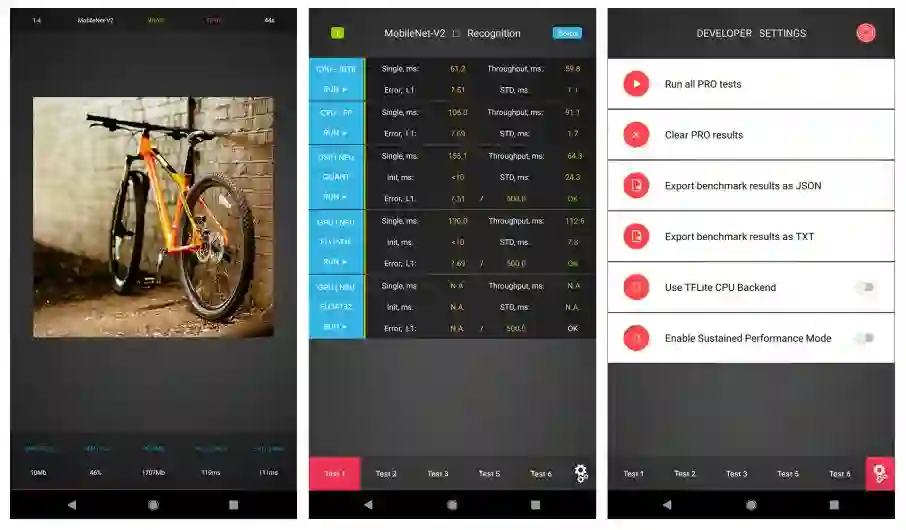
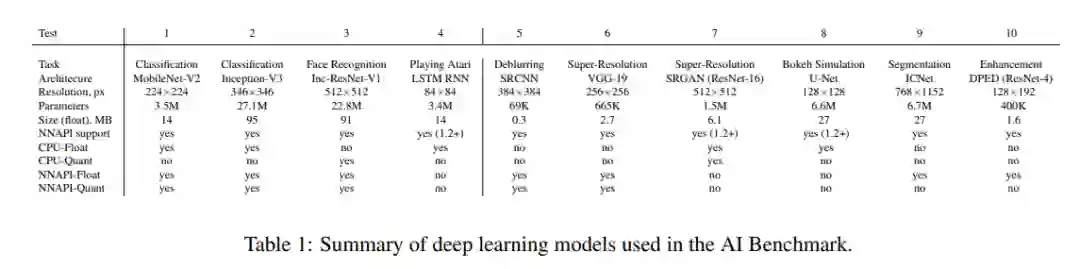
论文链接:https://arxiv.org/pdf/1810.01109.pdf


www.jiqizhixin.com/sota
PC 访问,体验更佳
登录查看更多
相关内容
Arxiv
3+阅读 · 2019年2月28日
相关主题





相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2019年2月28日