Webpack 的 Bundle Split 和 Code Split 区别和应用
(给前端大全加星标,提升前端技能)
作者:Oliveryoung
https://segmentfault.com/a/1190000017893334
Let's Dive in!
Webpack 文件分离包括两个部分,一个是 Bundle 的分离,一个是 Code 代码的分离:
Bundle splitting: 实际上就是创建多个更小的文件,并行加载,以获得更好的缓存效果;主要的作用就是使浏览器并行下载,提高下载速度。并且运用浏览器缓存,只有代码被修改,文件名中的哈希值改变了才会去再次加载。
Code splitting: 只加载用户最需要的部分,其余的代码都遵从懒加载的策略;主要的作用就是加快页面加载速度,不加载不必要加载的东西。
准备工作
在进行文件分离之前的准备工作,我们先写一些代码:
入口文件 src/index.js:
const { getData } = require('./main')
const { findMaxIndex } = require('./math')
let arr = [1,2,123,21,3,21,321,1]
findMaxIndex(arr)
getData('./index.html')
两个依赖模块:
src/main.js:
const axios = require('axios')
const getData = url => {
axios.get(url).then(d => {
console.log(d.status)
console.log(d.data.length)
})
}
module.exports = {
getData
}
src/math.js:
const _ = require('lodash')
const findMaxIndex = arr => {
let x = _.max(arr)
let r = Array.prototype.indexOf.call(arr, x)
console.log(r);
}
module.exports = {
findMaxIndex
}
增加一个 webpack 配置文件 webpack.config.js:
const path = require('path')
module.exports = {
mode: 'development',
entry: path.resolve(__dirname, 'src/index.js'),
output: {
path: path.resolve(__dirname, 'dist'),
filename: '[name].[contenthash].js'
},
}
文件分离之前打包效果
在 bundle split 和 code split 操作之前,我们先看一下当前默认打包的效果:
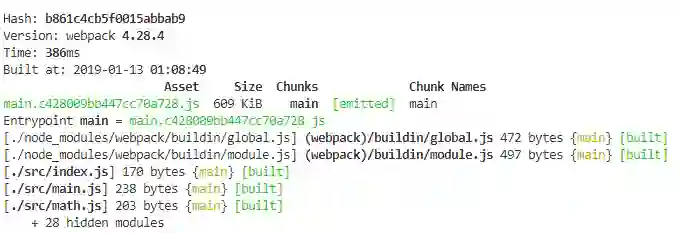
开始分离操作
Bundle Split
Bundle Split 的主要任务是将多个引用的包和模块进行分离,避免全部依赖打包到一个文件下
基本用法
Webpack 4 中需要使用到 optimization.splitChunks 的配置:
const path = require('path')
module.exports = {
mode: 'development',
entry: path.resolve(__dirname, 'src/index.js'),
output: {
path: path.resolve(__dirname, 'dist'),
filename: '[name].[contenthash].js'
},
optimization: {
splitChunks: {
chunks: 'all'
}
}
}
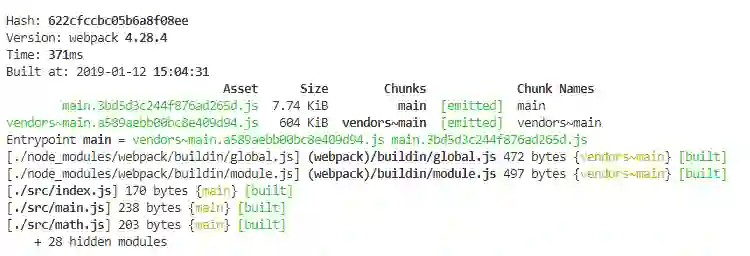
虽然说这样将第三方模块单独打包出去能够减小入口文件的大小,但这样仍然是个不小的文件;这个小的测试项目中我们使用到了 axios 和 lodash 这两个第三方模块,因此我们希望的应该是将这两个模块单独分离出来两个文件,而不是全部放到一个 vendors 中去,那么我们继续配置 webpack.config.js:
将每个 npm 包单独分离出来
这里我们需要使用到 webpack.HashedModuleIdsPlugin 这个插件
参考官方文档(https://webpack.js.org/plugins/split-chunks-plugin/#optimization-splitchunks)
直接上代码:
const path = require('path')
const webpack = require('webpack')
module.exports = {
mode: 'development',
entry: path.resolve(__dirname, 'src/index.js'),
plugins: [
new webpack.HashedModuleIdsPlugin() // 根据模块的相对路径生成 HASH 作为模块 ID
],
output: {
path: path.resolve(__dirname, 'dist'),
filename: '[name].[contenthash].js'
},
optimization: {
runtimeChunk: 'single',
splitChunks: {
chunks: 'all', // 默认 async 可选值 all 和 initial
maxInitialRequests: Infinity, // 一个入口最大的并行请求数
minSize: 0, // 避免模块体积过小而被忽略
minChunks: 1, // 默认也是一表示最小引用次数
cacheGroups: {
vendor: {
test: /[\\/]node_modules[\\/]/, // 如果需要的依赖特别小,可以直接设置成需要打包的依赖名称
name(module, chunks, chcheGroupKey) { // 可提供布尔值、字符串和函数,如果是函数,可编写自定义返回值
const packageName = module.context.match(/[\\/]node_modules[\\/](.*?)([\\/]|$)/)[1] // 获取模块名称
return `npm.${packageName.replace('@', '')}` // 可选,一般情况下不需要将模块名称 @ 符号去除
}
}
}
}
}
}
这里我们主要做了几件事:
这样 Bundle Split 的操作基本就完成了,让我们看看效果如何:
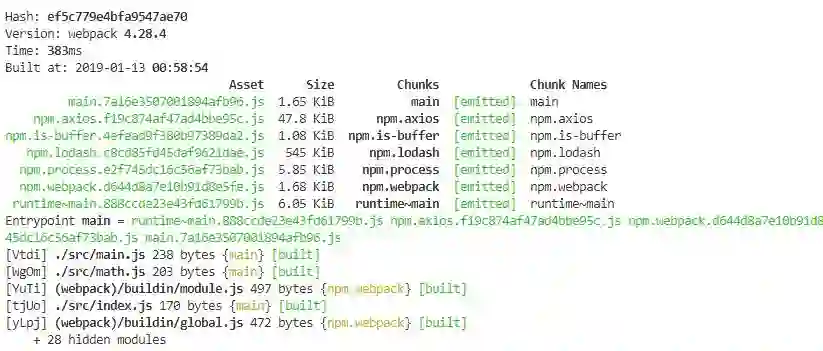
所依赖的几个模块都被分离出去了。
使用 HtmlWebpackPlugin 这个插件将 js 代码注入 html 文件中。
npm i -D html-webpack-plugin
修改 webpack.config.js 文件:
// 配置文件引入这个插件
var HtmlWebpackPlugin = require('html-webpack-plugin');
// ...
module.exports = {
// ...
plugins: [
new HtmlWebpackPlugin(),
new webpack.HashedModuleIdsPlugin() // 根据模块的相对路径生成 HASH 作为模块 ID
],
// ...
}
安装 http-server 或使用 vscode 的插件 Live Server 将代码放入一个本地服务器中,打开浏览器的调试窗口进入到 Network 面板:
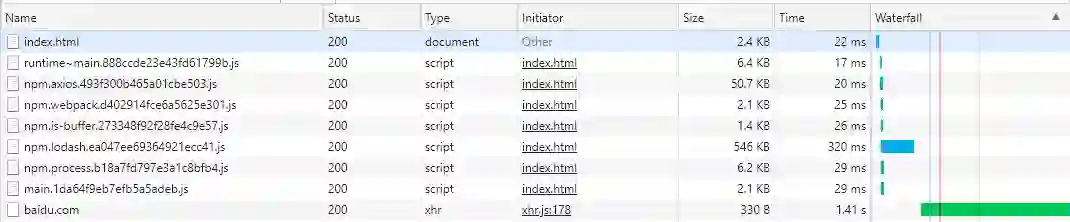
Code Split
代码分离实际上就是只加载用户需要使用到的部分代码,不是必须的就暂时不加载。
这里我们要用到 require.ensure 这个方法去获取依赖,这样 webpack 打包之后将会增加运行时代码,在设定好的条件下才会触发获取这个依赖。
修改我们的代码:
const { getData } = require('./main')
let arr = [1,2,123,21,3,21,321,1]
getData('./index.html')
setTimeout(() => {
require.ensure(['./math'], function(require) {
const { findMaxIndex } = require('./math')
console.log(findMaxIndex(arr))
})
}, 3000)
编译之后,打开调试面板刷新浏览器:
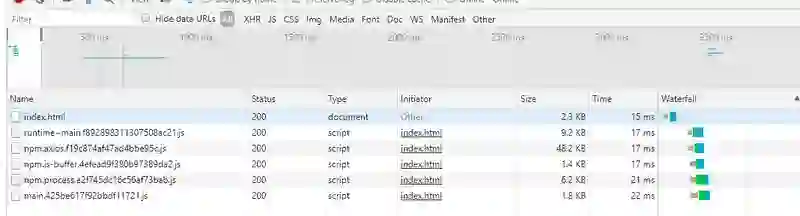
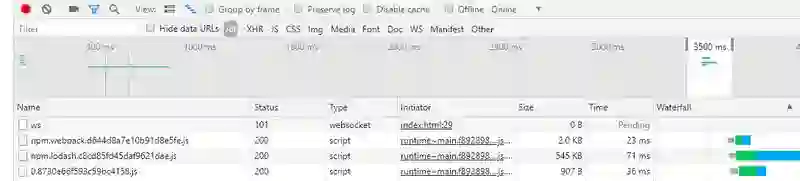
这样我们就完成了代码分离的操作,这样做的优势就是不需要第一时间加载的模块,可以推迟加载,以页面的加载速度。当然,上面的 timeout 定时器完全可以换成其他诸如按钮点击之类的事件来触发。
推荐阅读
(点击标题可跳转阅读)
觉得本文对你有帮助?请分享给更多人
关注「前端大全」加星标,提升前端技能

喜欢就点一下「好看」呗~




