北大95后学霸亲述:AI新算法媲美SGD,这是我第一次研究优化方法
新智元报道
新智元报道
编辑:肖琴、张乾
【新智元导读】由北大、浙大两位本科生为主开发的AdaBound算法,速度与Adam不相上下,性能媲美SGD,近期被ICLR 2019收录,网友惊呼太酷太强大。昨天,论文的第一作者、北大大四学生骆梁宸向新智元进行了详细解读。
本科生又一次刷新了AI的新成绩。
最近,来自北大和浙大的两位大四学生,开发了一种名为AdaBound的算法,能够实现更快的训练速度和更好的性能,速度与Adam不相上下,性能媲美SGD。
AdaBound算法相关论文Adaptive Gradient Methods with Dynamic Bound of Learning Rate已经被AI顶会 ICLR 2019收录。

值得一提的是,论文一作第一次在GitHub上公布AdaBound代码之后,就获得了300多赞,评论中无数人感叹:实在是太酷了!
昨天,论文一作、北京大学的骆梁宸向新智元解读了AdaBound算法。

以下是他的分享:
以随机梯度下降 (SGD) 为代表的一阶优化算法自上世纪50年代被提出以来,在机器学习领域被广泛使用,如今也是我们训练模型时最为常用的工具。
但是,由于SGD在更新参数时对各个维度上梯度的放缩是一致的,这有可能导致训练速度缓慢,并且在训练数据分布极不均很时训练效果很差。为了解决这一问题,近些年来涌现了许多自适应学习方法,包括 Adam、AdaGrad、RMSprop 等。其中 Adam 由于其快速的收敛速度,成为了如今最流行的 Optimizer 之一。
然而,在许多最新的State of The Art 中,研究者们没有使用新颖流行的自适应学习方法,而是仍然使用“过时的” SGD 或是其 +momentum 和 +nesterov 变种,这是为什么呢?事实上,Wilson 等人在其NeurIPS 2017的研究中指出,自适应方法虽然可以在训练早期展现出快速的收敛速度,但其在测试集上的表现却会很快陷入停滞,并最终被 SGD 超过。
ICLR 2018的最佳论文中,作者提出了名为 AMSGrad 的新方法试图更好的避免这一问题,然而他们只提供了理论上的收敛性证明,而没有在实际数据的测试集上进行试验。而后续的研究者在一些经典 benchmarks 比较发现,AMSGrad 在未知数据上的最终效果仍然和 SGD 有可观的差距。
我们每个人都希望在训练模型时可以收敛的又快又好,但似乎目前来看我们很难同时做到这两点,或者至少我们需要对现有优化算法的超参数进行精细的调整。机器学习和深度学习社区如今非常需要一个像 Adam 一样快,又像 SGD 一样好的优化器。
最早的对各类流行的自适应学习器和 SGD 进行系统的比较分析的工作来自上文提及的 Wilson 等,在他们的文章中,首次用系统的实验和样例问题指出了自适应方法的性能问题。Wilson 等同时猜测,自适应方法较差的泛化性能有可能是来源于训练后期不稳定的极端学习率。然而,他们并没有给出更多关于这一猜测的原因,包括理论分析或实验。
沿着这一思路,在Adaptive Gradient Methods with Dynamic Bound of Learning Rate 这篇文章中,作者首先进行了初步的实验来作参考:他们在 ResNet-34 中随机选取了 9 个卷积核和 1 个全连接层偏置向量,并从中再各随机取样一个维度的变量,统计其在 CIFAR-10 上训练末期的学习率。
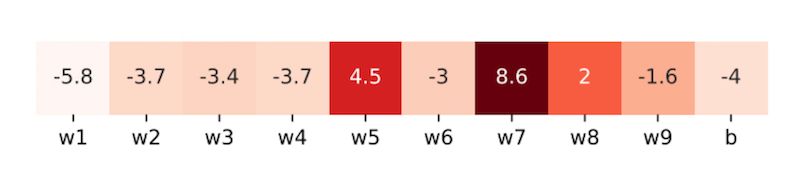
采样参数的学习率。每个单元格包含一个通过对学习率进行对数运算得到的值。颜色越浅的单元格代表越小的学习率。
我们可以看到,当模型接近收敛时,学习率中有大量的极端值(包含许多小于 0.01 和大于 1000 的情况)。这一现象表明在实际训练中,极端学习率是实际存在的。
而还有两个关键问题没有明确:
(1) 过小的学习率是否真的对模型收敛产生不良影响?
(2) 实际的学习率很大程度上取决于初始学习率的设定,我们可不可以通过设定一个较大的学习率还避免这一影响呢?
于是,作者继续给出了理论证明:

这一结果表明了极端学习率的潜在负面影响,在有效解决这一问题之前,我们很可能无法使用自适应学习器得到足够好的最终模型;需要设法对训练末期 Adam 的学习率做出限制。
为了解决这一问题,我们希望能有一种优化器可以结合 Adam 和 SGD 的优势,即分别是训练早期快速的收敛速度和训练末期好的最终性能。或者直观的形容,我们希望它在训练早期像 Adam,而在训练末期更像 SGD。
基于这一思路,作者通过对学习率进行动态裁剪,提出了 Adam 和 AMSGrad 的变种,AdaBound 和 AMSBound。这一方法受到在工程实现中非常常用的梯度裁剪技术的启发。只不过这时裁剪发生在学习率而非梯度上。考虑如下的裁剪操作:
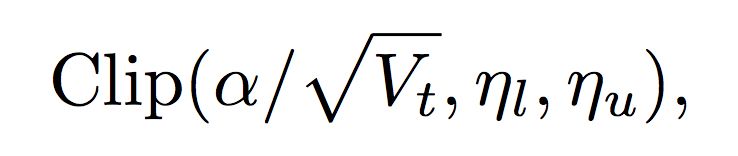
其中 Clip 可以将实际学习率限制在下界 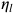
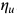
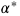
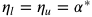
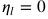
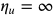
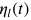
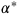
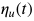
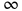
在这一设置下,在训练早期由于上下界对学习率的影响很小,算法更加接近于 Adam;而随着时间增长裁减区间越来越收紧,模型的学习率逐渐趋于稳定,在末期更加贴近于 SGD。AMSBound 可以对 AMSGrad 采用类似的裁剪得到。
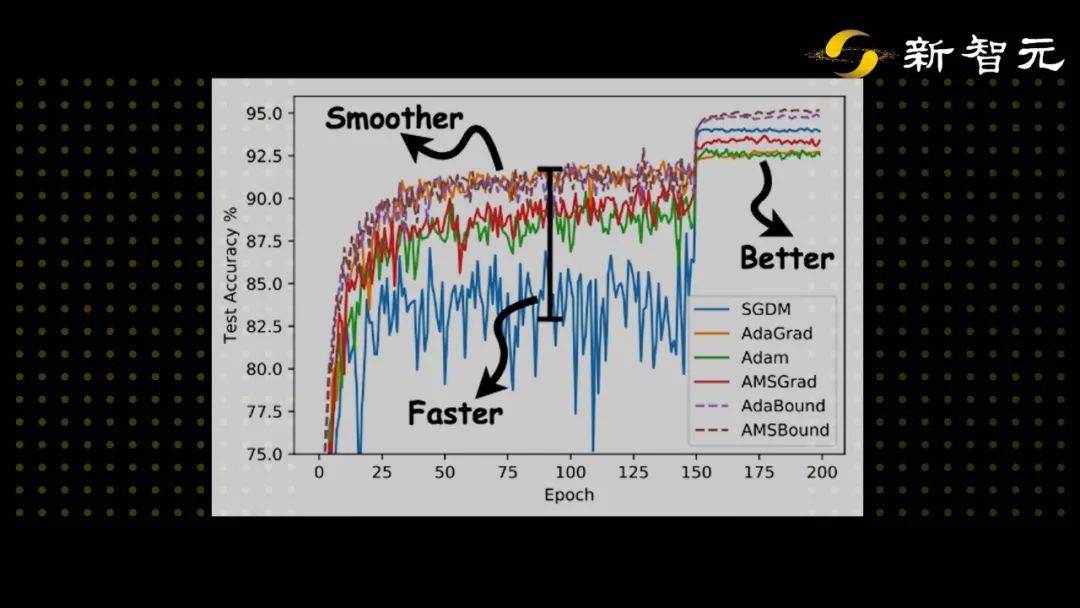
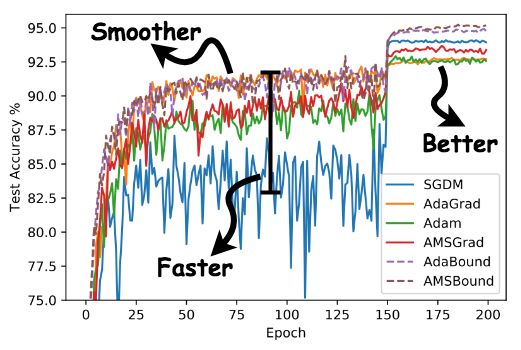
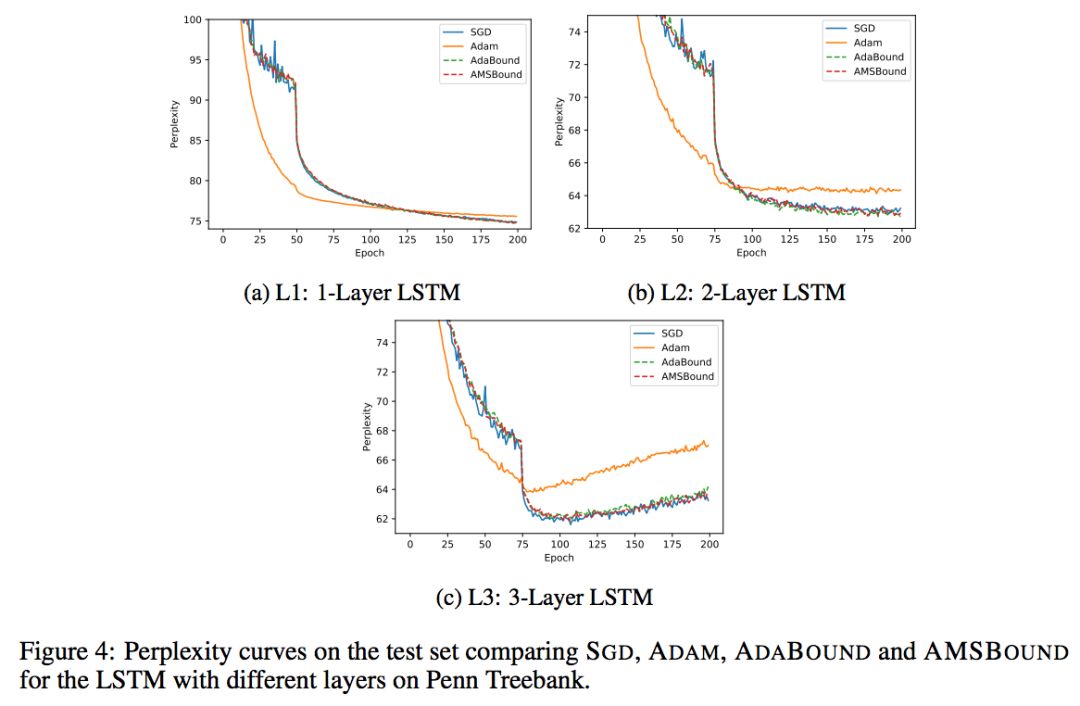
作者将 AdaBound/AMSBound 和其他经典的学习器在一些 benchmarks 上进行了实验验证,包括:SGD (或 momentum 变种)、AdaGrad、Adam、AMSGrad。以下是作者在论文中提供的学习曲线。
可以看到,在几项 CV 和 NLP 的 benchmark 任务中,AdaBound/AMSBound 都在训练前期可以快速且平滑收敛的情况下,同时在末期得到了优秀的最终性能,可以取得与 SGD 类似甚至更好的结果。
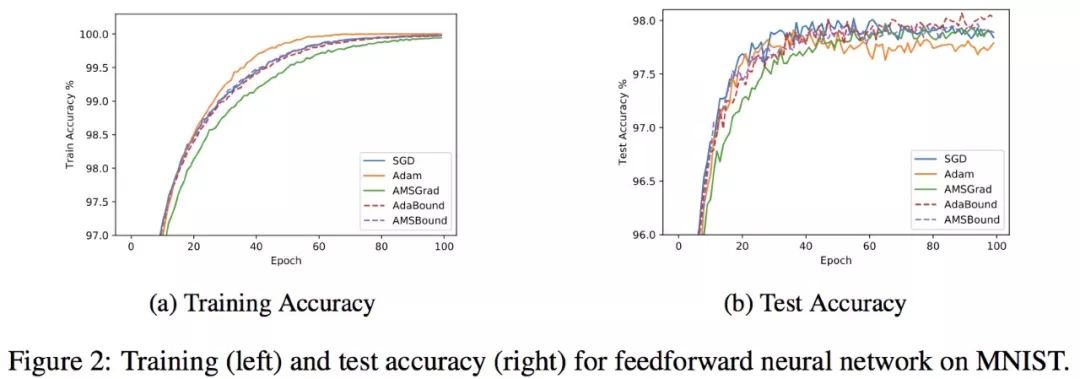
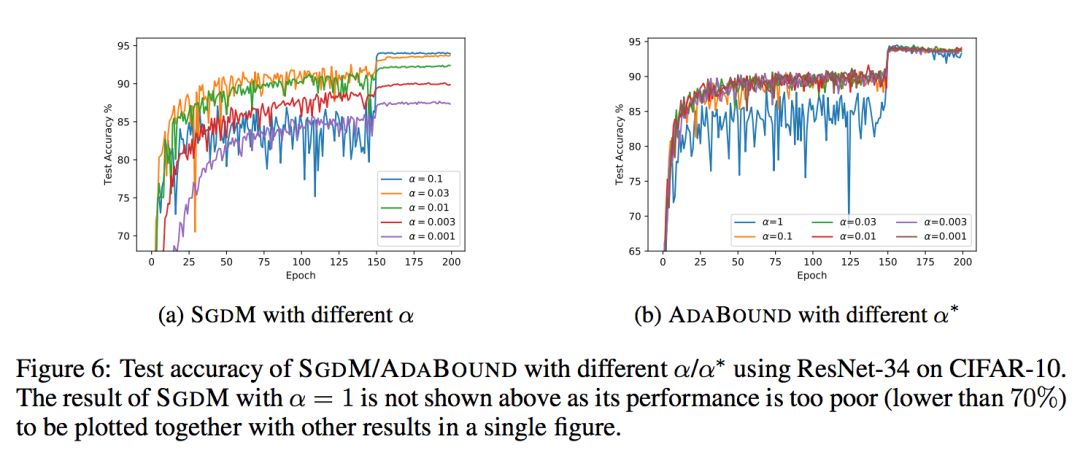
AdaBound还带给我们一个额外惊喜:它对超参数相对更不敏感,尤其是和 SGD(M) 比较。这一结果是非常意外也非常让人惊喜的,因为这意味着 AdaBound 有更高的鲁棒性。通过使用这一新型优化器,我们可能大大节省花在调整超参数上的时间。在常见的情形下,使用其默认参数即可取得相对优秀和稳定的最终结果。
当然,作者也同样指出,尽管 AdaBound 相对 SGD 更加稳定,但这并不意味着我们可以一劳永逸再也不需要调整超参了,机器学习没有银弹。一个模型的最终结果取决于方方面面的因素,我们仍然需要结合具体问题和数据特征具体分析,对 AdaBound 做出合适的调整。而 AdaBound 最大的优势在于,你很可能用在这上边的时间会比以前少很多!
AdaBound 的 PyTorch 实现已经在 GitHub 上开源。作者同样提供了可以简单只用 pip 安装的版本,大家可以像使用其他任何一种 PyTorch optimizer 一样使用 AdaBound。
此外,作者还提供了一个非常方便的可视化 Jupyter notebook 并提供了相应的训练代码,方便感兴趣的同学复现和直观比较新优化器的结果。
论文地址:
https://openreview.net/pdf?id=Bkg3g2R9FX
GitHub地址:
https://github.com/Luolc/AdaBound
以上就是作者的解读。
这个工作也在Reddit机器学习社区引起热议,不少人表示非常cool,也有人提出建议和疑问:有没有TensorFlow实现?能不能在更大的数据集工作?在GAN上的结果如何等等。
作者后来在Reddit帖子更新中表示:
正如许多人以及评审人员所建议的那样,在更多、更大的数据集上,使用更多模型测试AdaBound会更好,但很不幸,我只有有限的计算资源。我几乎不可能在ImageNet这样的大型基准上进行实验。如果谁能在更大的基准上测试AdaBound,并告诉我它的缺点或bug,那就太好了!这对于改进AdaBound和进一步的工作很有帮助。
我相信在计算机科学领域没有什么灵丹妙药。这并不意味着使用AdaBound你就不用调参了。模型的性能取决于很多东西,包括任务、模型结构、数据分布等等。你仍然需要根据具体情况决定使用哪些超参数,但是在这上面花的时间可以比以前少很多!
这是我第一次研究优化方法。由于这是一个由本科生、并且对这个领域来说完全是新人的团队做的项目,我相信AdaBound非常需要进一步的改进。我会尽我最大的努力把它做好。再次感谢大家的建设性意见!这对我有很大的帮助。:D
论文一共由四位作者完成,分别是:

骆梁宸,北京大学大四在读,1996年出生,目前为北京大学计算语言学重点实验室的研究助理,导师是孙栩教授。
个人主页:https://www.luolc.com/
Yuanhao Xiong,浙江大学信电学院信息工程专业,同样是大四本科生。他的研究兴趣是数据挖掘和机器学习,在发表这篇文章之前他已经在IEEE通信领域期刊发表一篇论文。

Yan Liu
Yan Liu,南加州大学计算机科学系副教授,南加州大学机器学习中心主任。Philip and Cayley MacDonald Endowed Early Career Chair。
个人主页:http://www-bcf.usc.edu/~liu32/

孙栩
孙栩,北京大学信息学院研究员,博士生导师。日本东京大学博士。研究领域包括:自然语言处理,机器学习,深度学习。
个人主页:http://eecs.pku.edu.cn/teaching/inservice/search/Detail/?ID=5469
论文的两位本科学生骆梁宸、Yuanhao Xiong今年都上大四。骆梁宸曾在微软亚洲研究院、DiDi AI Labs等机构实习过。他的研究兴趣是自然语言处理深度学习,尤其是对话系统和语言理解/表征。他也对机器学习理论有兴趣,比如优化算法。
作为一名本科生,骆梁宸已经在ICLR、AAAI、EMNLP等顶会发表4篇文章,其中3篇一作!体会一下:

后生前途无量啊!
【加入社群】
新智元AI技术+产业社群招募中,欢迎对AI技术+产业落地感兴趣的同学,加小助手微信号:aiera2015_2 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。



