携程机票ElasticSearch集群运维驯服记(附赠书)

本文根据许鹏老师在〖Gdevops 2017全球敏捷运维峰会北京站〗现场演讲内容整理而成。

(点击底部“阅读原文”获取许鹏演讲完整PPT)
讲师介绍
许鹏,携程机票大数据基础平台Leader,负责平台的构建和运维。深度掌握各种大数据开源产品,如Spark、Presto及Elasticsearch。著有《Apache Spark源码剖析》一书。
今天跟大家分享的是携程机票ElasticSearch集群的规划和具体设置,内容相对细致,同时也会涉及到集群的监控分享。

为什么采用ES作为搜索引擎呢?在做任何事情的时候,不要一上来就急着了解怎么做这件事情,而是去想想这件事情为什么值得去做。
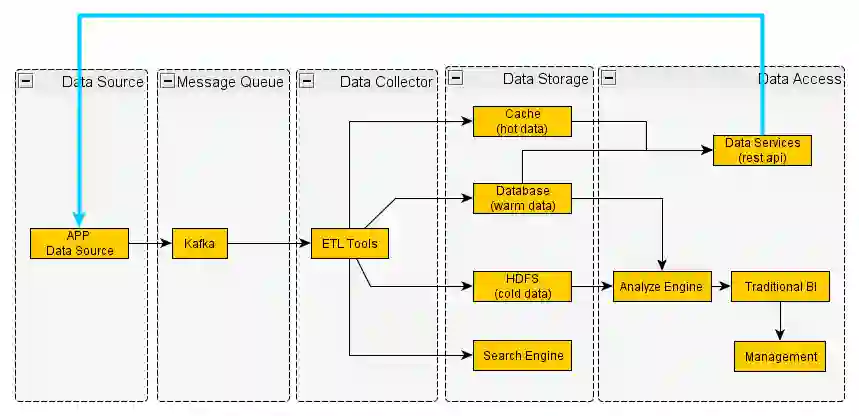
这个是比较通用的数据的流程,一般会通过Kafka分离产生数据的应用程序和后面的平台,通过ETL落到不同的地方,按照优先级和冷热程度采取不同的存储方式。一般来说,冷数据存放到HDFS,如果温数据、或者热数据会采用Database以及Cache,目前分布式Cache还没有明显的强者出现,这将会成为未来的一个竞争点。
一旦数据落地,我们会做两方面的应用,第一个方面的应用是传统BI,比如会产生各种各样的报表,报表的受众是更高的决策层和管理层,他们看了之后,会有相应的业务调整和更高层面的规划或转变。这个使用路径比较传统的,在数据仓库时代就已经存在了。现在有一种新兴的场景就是利用大数据进行快速决策,数据不是喂给人的,数据分析结果由程序来消费,其实是再次的反馈到数据源头即应用程序中,让他们基于快速分析后的结果,调整已有策略,这样就形成了一个数据使用的循环。
这样我们从它的输入到输出会形成一种闭环,而且这个闭环全部是机器参与的,这也是为什么去研究这种大规模的,或者快速决策的原因所在。如果数据最终还会给人本身来看的话,就没有必要更新那么快,因为一秒钟刷新一次或者10秒钟刷新一次对人是没有意义的,因为我们脑子不可能一直转那么快,基于数据一直的做调整也是不现实的,但是对机器来讲,就完全没有问题。
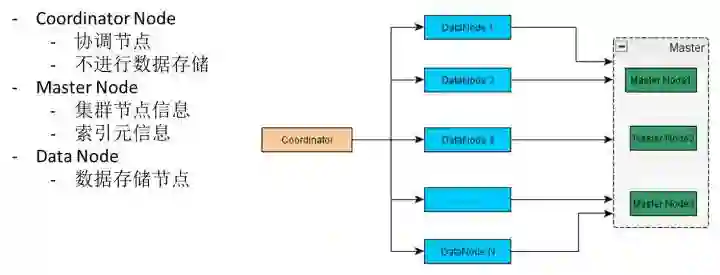
这是大体上的一个规划,当然,从左到右有一个结点,这个节点本身不存在数据的,你可以简单地认为它只是负责查询的入口。第二层用来承载具体的数据,然后这些数据的搜索本身会发生在这里。最后一层是MASTER的节点,主要是管理元数据,元数据包含有集群中的机器信息,以及写入到我的数据节点上的这些索引设置信息、索引Schema都是由Master管理。
我这里是以ES5.X版本为依据的,大家看ES文档,我这上面有一个节点没有写,就是没有写它的Ingest节点,它可以在数据真正写入到Index之前做一些转换。
下面要讲的设置就非常具体了,从三个层面来讲:第一个有关Linux的系统配置,第二是集群层面的参数设置,最后会涉及到存储到集群上的索引设置。
1、OS参数设置
像OS这个参数设置,首先提到的是内存相关的参数,由于ES采用Mapping机制,将文件映射到内存,在系统级别有一些相关的参数要设置。另一个就是文件数,假设我们所有都设置到最大65535。

这个设置之后还需要在下面加入加入login这个文件,这里讲得非常具体,可以说是一个教程。

这里我只是做了一个示例,在Ext4文件系统中,每一次访问一个文件或者目录时,其实OS级别会记录访问时间,如果只是在海量文件的情况,上述的记录信息就会对IO有影响。有一篇文章提到,关闭文件访问时间信息之后,系统IO性能可以提升20%—30%。
我们知道Linux里面文件信息,不是直接改一次之后就写入到磁盘,它会先有一个文件的缓存,文件的缓存什么情况下会被写入到disk里面?有两个相应的系统参数可以设置的,一个是vm.dirty_background_ratio,一个是vm.dirty_ratio,一旦缓存占据内存超过百分比(默认值是20%)之后,内核就停止其它方面的操作,而只做文件的缓存吐到disk的操作,这时效果有点像Java里进行垃圾回收一样,对外界停止响应。 vm.dirty_ratio就是当它缓存量达到20%时,它就其它的什么都不干了,只做数据同步到disk一件。
内存不够时,会使用swap空间, 内存很大的话,可以不用创建swap空间。默认值是60,但是我们把它设置为零的话,是跟swap off效果一样。但为了避免内核出现OOM, 只是将其设置为1。
2、ElasticSearch参数设置
刚才两个讲的都是系统级别的设置,一个是内存,另一个是系统级别的IO,下面讲的是针对ES—JVM的设置。

这里建议,不管物理内存有多大,分配给Elasticsearch的只设成32G,同时后面如果出现OOM,进程直接退出。
为什么说要把它改成这个呢?因为我们在使用一个集群时看到,有时因为聚合操作的原因,会导致某一台机器上的JAVA进程出现OOM,但是这个JVM进程还在,并没有退出,退出的话可以通过monit捕捉到,也可以进行重启。如果没有退出,而是一直挂在那的话,就不能提供正常的服务。 此外加上这个参数的话,需要升级一下JDK版本,JDK要求1.8.0_92, 从这个版本开始支持ExitOnOutOfMemoryError参数。
另外一种办法就是如果我们内存不能升级JDK、存在种种现实约束的话,可以在这个时候用另一种方式来实现,在JVM启动参数中加入
-XX:OnOutOfMemoryError="kill -9 %p"。

这里就是讲输入到ElasticSearch里面每个集群的一些参数,一些相对比较主要的一些参数。这里的参数配了一幅图,这幅图最想表明的意思是说,我的参数的配置要使得我从整个集群的角度上来看,它每一台机器上的shard数目基本是相当的。
这里有一点,参数设置能保证shard数目是基本相当的,但并不是保证每一个shard的大小相等,这两者还是有差异的。决定每个集群上shard相等的参数是由这个balance决定,它默认一个是0.5,把它往下调的话,就不可以倾斜;往上调的话对倾斜的容忍度相对比较高。
ElasticSearch是一个高可靠的系统,集群的一个节点挂掉了,另一个节点是可以继续的。挂掉的节点是进行恢复,为了避免恢复工作对集群造成太多影响,主要是避免大的I/O消耗,需要进行参数设置。比如集群中同时在进行恢复的索引可以是多少个,还有就是一个node上能允许shard在做恢复。 这两个参数是cluster_concurrent_rebalance和node_concurrent_recoveries。
如果要缩容、对某一台机器进行维护、将其从集群中拉出来该怎么办?这个时候可以设定exclude名单,名单可以通过ip地址或主机名来指定。一旦设置的exlude名单,该名单上节点中的索引数据被拉到别的机器上面,数据被拉完之后,就可以被这个集群拉出去的机器进行维护,避免维护带来的数据丢失。
3、索引参数设置

这是具体到一个索引参数的设置。在讲具体参数之前,我们可以先讲一下ElasticSearch索引参数的设置、输入以及中间发生的过程。当真正的数据请求到达ElasticSearch节点之后,它一方面会写入到内存中,另外一部分会写入到TransactionLog。
写入到内存并不意味着可以被搜索,要通过Refresh操作,才可以被搜索到。Refresh之后,数据可以被搜索到,此刻数据还在内存中,如果很不巧的话,在这个时候断电,或者出现其它故障不可用了,那么等到这台机器再恢复时,我刚才写的内容就丢失掉了, 因为并没有被持久化到磁盘。 为了持久化这个内容,需要进行一次FLUSH操作, flush的内容会被写到一个segment中。 可想而知,随着时间的推移,系统会产生大量的segments,这些segment需要把它合并成一个大的。不合并成一个大的会怎样呢?不合并成一个大的,就是说每一个segment都会吃掉一些文件句柄,文件句柄数是有限的。另一个带来的就是查询性能下降,因为查询的时候,要对所有segments进行访问,效率就比较低了。
有了刚才讲的三步之后,再来看下面的参数就比较容易好理解了。 Refresh_interval 过多久可以让你查询到,时间越短就可以被越快地检索到,但是意味着我相应的I/O也上去了,在有大批量数据导入时,这个数值会适当的调大。
在我们目前部署的集群中,高峰时候每秒写入量,有十几万。 为了应对这种场景,将refresh_interval设置为100多秒或者90秒以上。
Number_of_shards索引分片的数目,这个数目可以设置得大一些,还有每一个分片的副本,在大批量导入时,由于副本数目是可以动态调整的,副本数也可以先设置为零,等数据全部导入后,再设置为非0值。 副本数可以动态调整,但是分片数目是无法动态调整的,也就是说,除非重建另外一个索引,不然原先设置的是啥样就只能啥样。 这个FLUSH也可以调大,需要的时候可以设置得大一些。
下面就是做segments合并的线程数,如果是spin disk的话,就使用默认值1,如果是SSD的话,可以把它调大一些。 讲到SSD代码的话, 为了进一步优化性能,可以将系统的i/o scheduler设置为noop 。

这里是针对每个Index的Schema设置。假设事先并不能确定索引,大部分我们可以采用动态的template。 上述的动态模板表示的是, 如果字符串小于10915, 就采用keyword来存储。
下面一栏对应特别特别大的字段,如果我们只是存储这个字段的内容,不对这个字段做搜索也不做任何分词,可以将类型设置为object,enabled设置为false,即便包含嵌套信息也不会被解析。

前面讲的是一些设置方面的内容,下面讲如何放开这个ElasticSearch的使用。想法跟大的原则一样,尽量避免开发人员直接调用Elasticsearch的API来操作ElasticSearch,因为这样产生的问题不容易控制,毕竟每个人对ElasticSearch的熟悉程度不一样。 建议先统一入口,在包裹之后的API对ES进行操作。 利用BigQuery API对写入到Elasticserch的数据进行查询,开发人员直接写SQL语句。如果SQL语句本身有问题的话,在Elasticsearch-SQL一侧就可以将其挡掉。
1、监控内容

维护一个集群的话,肯定离不开对集群的监控。监控的内容,大体上来说分成OS层面还有ES索引层面的内容。
OS层面就是内存、CPU,索引层面就是分片还有它的Field Data以及其它占用的内存数。索引的话就是每个索引数设置得合理,这些分片数设置得合理与否,分片是否在每个集群里比较均匀地分布;针对每一个索引的话,它的查询量是不是过大,如果过大的话,那么整个集群也会有问题。ElasticSearch并不是一个能够很好地支持高并发查询的系统。每一个索引中包含的字段数不能过多。
2、监控工具
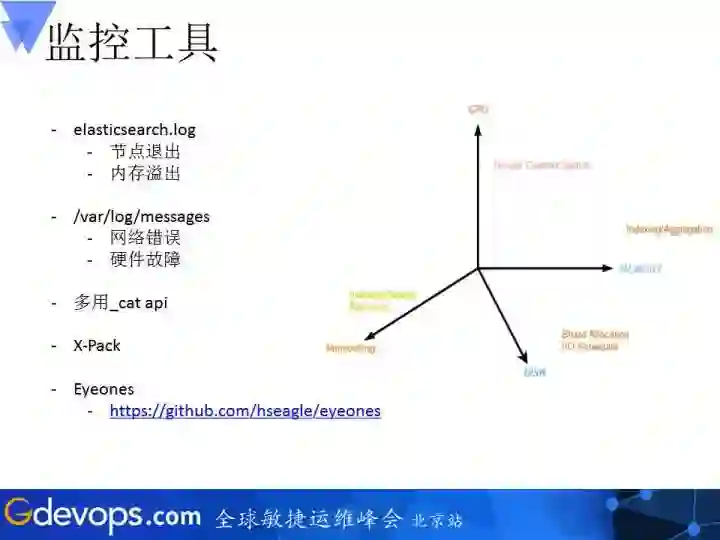
监控工具是eyeones,是我们自己写的一个工具, Elasticsearch 5.x中提供的x-pack基本版与elasticsearch 1.x中提供的marvel相比,精简掉了好多有用的信息,这是我们为什么自己写一个监控面板的原因。
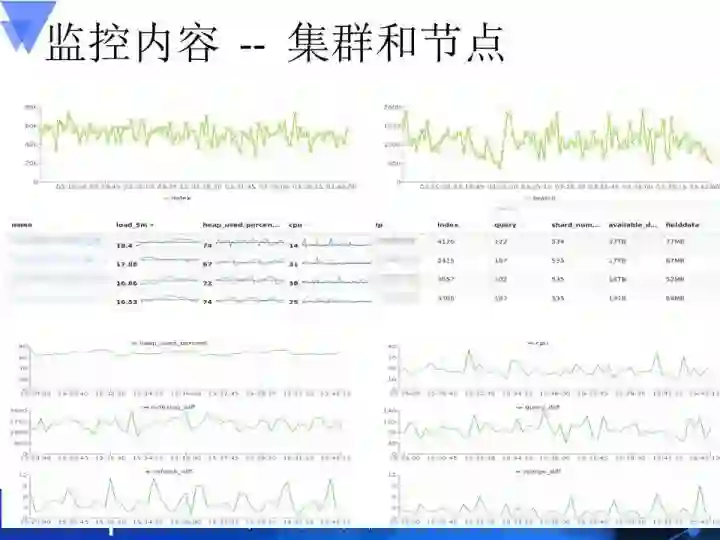
从这里你可以看到这是针对节点的负载情况,然后它的内存使用情况,还有就是我这上面所承载的索引数目、每个节点上的查询数、分片落了多少。
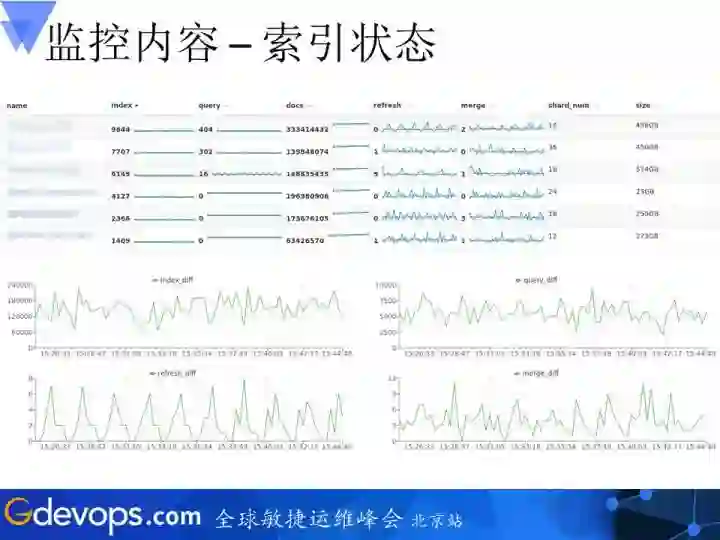
这是一个针对索引内容更加明细的量化指标,上面是索引的情况,点击任意一个具体的索引,都会有相关内容。
这个的话我们是把它放到Github,如果大家有兴趣可以在上面继续改造。
-AND-
更深度、更全面、更实用的ES运维战技
尽在2017 Gdevops广州站!
届时许鹏老师不仅会带来更精彩的演讲
还将开设《Elasticsearch从原理到实战》课程,购票优惠进行中,不容错过

赠书来了
在本文微信订阅号(dbaplus)评论区留下足以引起共鸣的真知灼见,并在本文发布后的隔天中午12点成为点赞数最多的一名,可获得以下好书一本~
特别鸣谢图灵教育为活动提供图书赞助。

近期热文:
用分布式日志优化单机数据库系统将成未来标配?
讲真,你真的懂JDBC吗?
如何从MongoDB迁移到MySQL?这有现成经验!
一张图概览如何打造运维平台一体化!
点这里下载干货PPT!






