独家 | 一探Stack Overflow工作搜索

作者:Aurélien Gasser
翻译:顾佳妮
术语校对:梁傅琪
全文校对:张冬阳
本文长度为6100字,建议阅读20分钟
Aurélien Gasser在本文中对Stack Overflow的工作搜索的发展历程作了详细的分享,主要是匹配算法的优化过程,包括算法特征的选择、算法和Elasticserach搜索引擎的配合使用等。
大约在两年前,Stack Overflow上发生了一件大事:Stack Overflow发布了一个叫做Providence的新系统。这个系统可以得知访问者对什么样的技术有兴趣,也可以衡量某个访问者和某个工作之间的匹配程度。
更通俗的说,Providence的发布可以被看作是Stack Overflow向“更智能”迈进以及在数据科学领域上持续投资的道路上的里程碑。如果想了解更多关于Providence的信息,可以参考下面这个系列博客(https://kevinmontrose.com/2015/02/04/providence-matching-people-to-jobs/)。
作为工作匹配团队中的一个开发者,我致力于用这个新的方法帮助大家找到新的、更好的工作。本篇博客大部分都是关于我如何完成这些的历程。
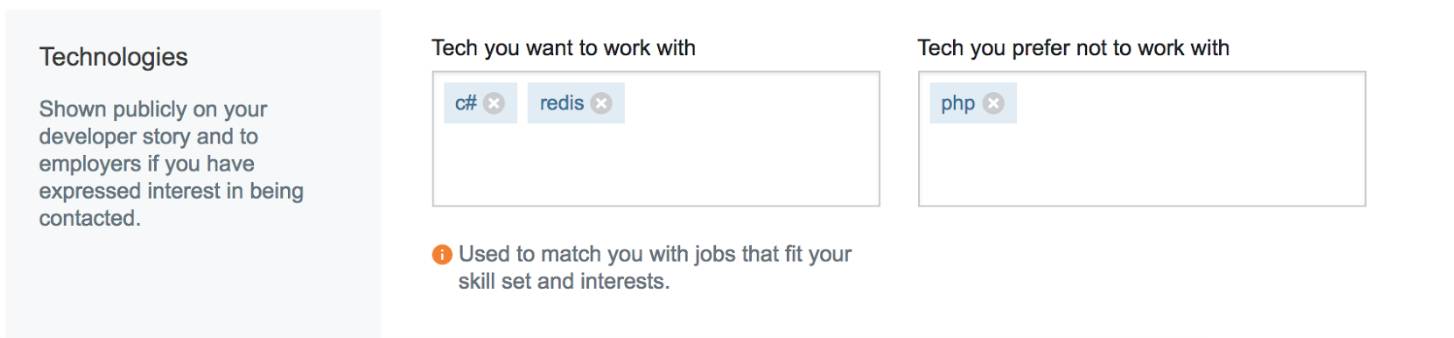
在你的Stack Overflow档案中,工作匹配偏好提供给我们有关你工作兴趣的线索
如何立即失败的
工作匹配、感兴趣的工作、工作推荐。不管我们怎么叫它们,核心都是要正确。每个人都对工作有不同的要求和不同的偏好。有的人想要从美国搬到挪威,有的人不会考虑离家超过5英里的工作。有的人不想在创业公司工作而有的人只想在创业公司工作。因此,我从中总结到的是:没有一个方案可以满足所有人,但是无论如何我们都会尝试着做到这一点。

每个人对工作的陈述信(cover letter)都是不一样的
在我们引入个性化的工作搜索结果之前,Stack Overflow Jobs(https://stackoverflow.com/jobs?utm_source=so-owned&utm_medium=blog&utm_campaign=gen-blog&utm_content=blog-link)上默认的方法是显示最近发布(的工作)。这是一个可以接受的方法,但远非一个好方法。它的其中一个问题是没有考虑到你的兴趣,甚至这份工作离你十万八千里远也会显示给你。对于这种情况,我们肯定可以做得更好。
有了Providence的帮助,我们的工具箱里有了新的工具。对每一份工作,我们都可以确定一个在0到1之间的分数来表示这份工作所需的技术和某个访问者之间的匹配程度。如果不显示最近发布的工作,为什么不干脆显示符合技术项的工作?尽管这种做法也不是完美的,但是至少通过这种方式选出的工作是和你相关的,所以工作匹配度会表现得会更好一些,不是吗?
好吧,并非如此。我们的首次A/B测试中点击率出现了骤降。大约不到原来50%的用户点击了工作搜索中给出的结果。首次尝试的时候把我们引向了一个似乎更难的问题。

大量失败的证据
什么因素让用户对一份工作有兴趣?
我们知道了单单只有Providence(从技术出发匹配用户和工作)是没有作用的。我们也知道了只显示最新发布也没有作用的,所以应该从什么地方再进行下去呢?
我们知道距离是一个重要的因素:大多数人都想在离家近的地方工作。我们也知道显示最近发布的工作也不差,毕竟比我们新的“Providence价值函数”表现得好。
所以我们做了如下尝试:我们把用户和对应工作之前的距离(可以从用户IP地址来获取这个数据)乘上工作发布的时间长短,通过这种方式我们可以得到一个工作的得分,然后用这个得分对工作进行排序。

这次,它行得通了!实际上,它的表现非常好。

结果好很多了,更多的人点击了工作申请(获得了42%的提升)
现在我们知道了两件事:
工作发布的时效性是重要的;
用户和工作地点之间的距离也是重要的。
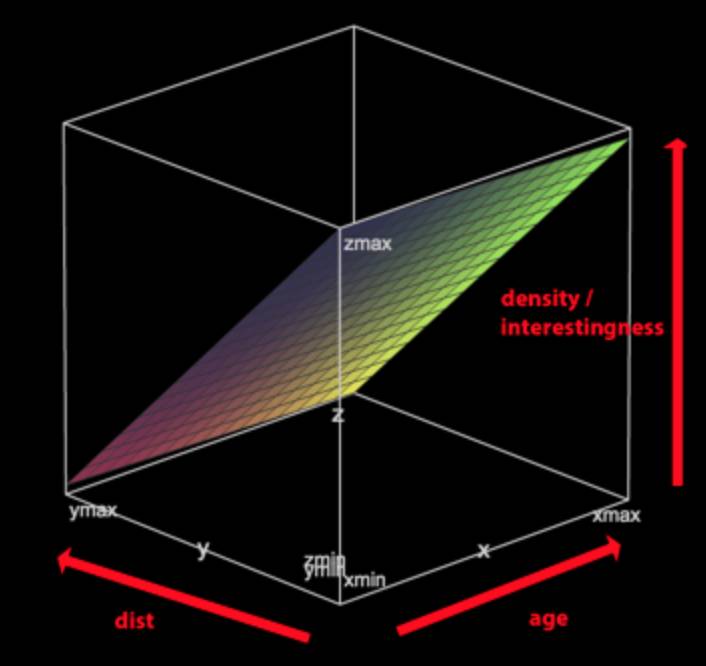
那么怎么评估两者之间的重要程度呢?距离是否和工作发布的时间长短一样重要?或者说距离是3倍重要于工作发布的时间长短? 为了回答这个问题,我们画了很多像下面这样的图表。
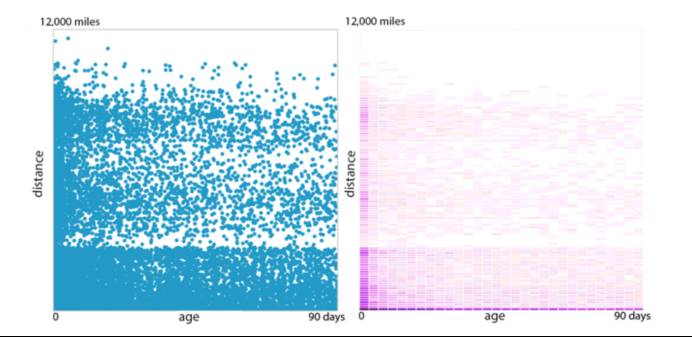
工作申请数的密度(美国访问者)
你会发现当超过一定距离之后,单位申请工作数就会变得非常少,这距离是纽约和洛杉矶之间的距离。
右边的图向我们表明申请人数的密度随着距离的增加而减小。这是合乎情理的:访问者更倾向于离自己近的工作。工作发布的时效性并不是那么重要的一个因素,除非这个工作是特别近发布的(在一天之内发布),也会有很多的申请者。
有了这个申请人数密度的数据,我们使用了线性回归(https://en.wikipedia.org/wiki/Linear_regression)基于距离和时效来预测用户可能申请的概率。
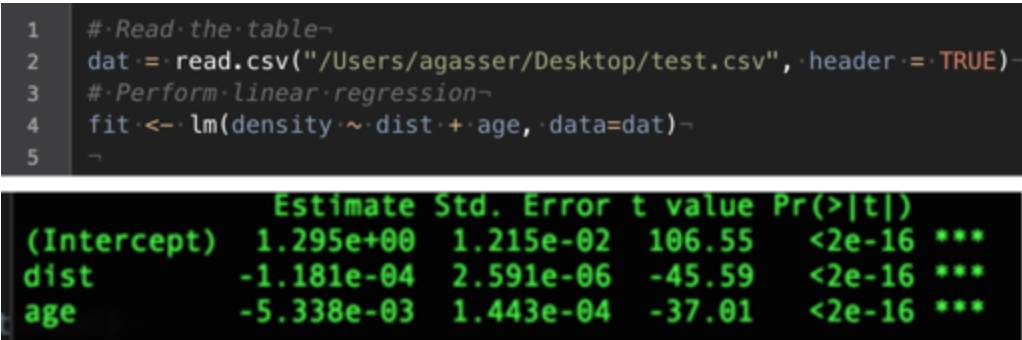
R(https://www.r-project.org/about.html)中源码和线性回归输出结果
通过线性回归获取的公式的绘图
由于申请人数随着距离的增加出现了指数级(而非线性)下降,所以我们使用的方程有带指数:

注意这仍然是一个线性回归的问题:只不过之前预测的是申请者人数,现在预测的是申请者人数的对数。
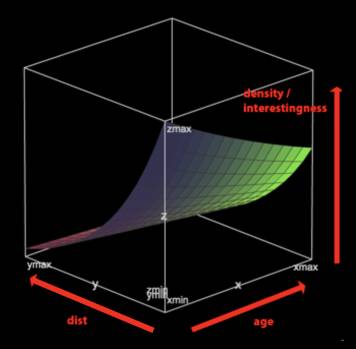
对某一个工作的兴趣度随着距离的增长急速下降
Providence,我们还没有放弃你
现在我们得到了一个基于实效性和距离的公式,基于这个公式可以给出与访问者相关的工作。非常棒!但是对感兴趣的工作的计算就没有能用到Providence(从技术项的角度匹配用户和工作)的力量的地方吗?
在没有能够正确使用Providence之后,我们暂时放下了Providence。 但是我们仍然相信最新的工具可以为我们带来新的视角审视来访问者。现在我们已经准备好了做第二次尝试。
这一次我们重新引入Providence,但只用于在我们的密度分析和公式中增加一个新特征。计算机仍然负责来判定三个特征的重要性:距离,工作时效,以及现在的Providence得分(同时我们也把线性回归换成了泊松回归(https://en.wikipedia.org/wiki/Poisson_regression):在预测一个自然数,即申请者人数时,它是更合适的技术)。
那么为什么只使用了三个特征?还有很多其他重要的因素决定了我们工作兴趣。

新的因素让匹配算法更佳“美味”
工作匹配偏好
我们知道还有很多其他的维度决定了一个工作是否与你相关,例如等级、工资、行业,开发类型(全栈或移动端)等等。为了表示这些,我们引入了工作匹配偏好(Job match preference)(https://stackoverflow.com/users/jobsearch/current?utm_source=so-owned&utm_medium=blog&utm_campaign=gen-blog&utm_content=blog-link)。
回想一下刚才我们提到的,兴趣度公式中的特征都有一个相关的权重。权重决定了每个特征对兴趣得分的影响。一开始,我们没有任何数据,:工作匹配偏好是全新的,几乎没有数据。由于缺乏数据,我们无法计算这些新的特征的权重(就像我们之前在泊松分布中做的那样)。所以我们先自己定了权重。
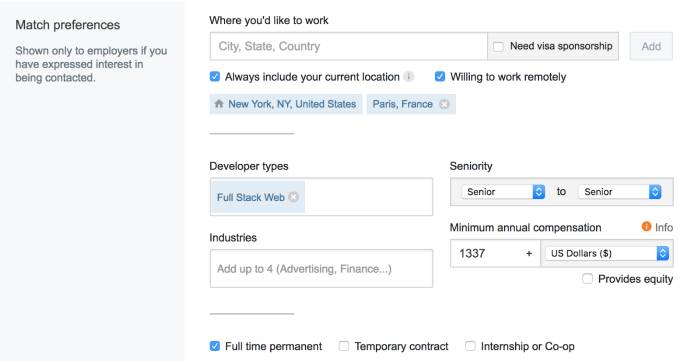
用工作匹配偏好来显示感兴趣的工作
然而过了一段时间以后,用户已经在系统中填入他们的匹配偏好了。这样我们就有足够的数据来发现用户的匹配偏好、工作列表和用户和工作申请情况之间的关系。我们可以用这些数据来训练泊松回归,计算出新的权重。
我们已经达到了我们的目的:不用去决定每个特征对一个工作兴趣度的影响,而是让数据分析自己决定。
但是我们仍然面临着一个问题:兴趣度公式会因为数据库中可供选择的工作而产生偏差。举个例子,假如我们的数据库中95%的工作申请是远程工作(允许员工在远程工作),那么我们的方法就会得出用户对远程工作兴趣要远超过非远程工作。但这并非必然正确!这只能说明我们的数据库中有更多的远程工作!按照这个道理,我们之前可能在兴趣公式中给某些特征太高(或者太低)的权重了。为了解决这个问题,我们根据可供选择的工作对申请者人数进行了标准化。
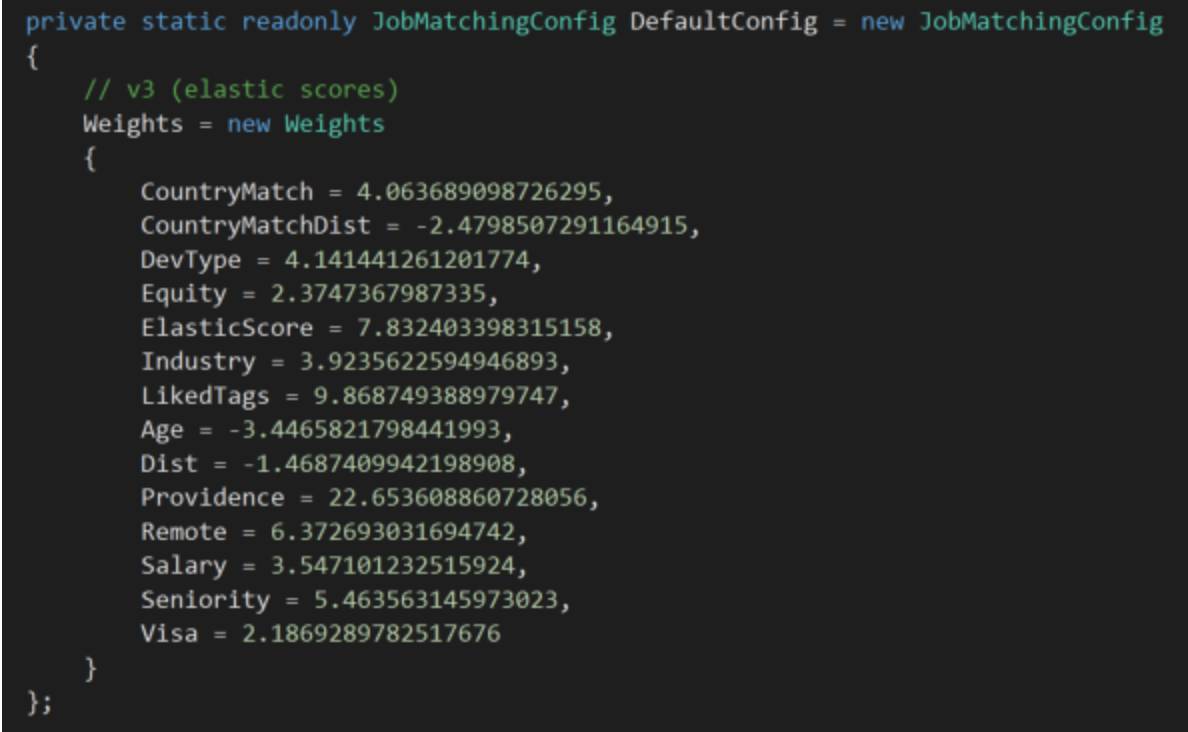
给每个特征分配的权重(这非常隐秘,请不要泄露)
模拟和遗传算法
匹配算法在渐渐提升,来浏览的用户变多了。
训练权重过程中未压缩的数据集接近800M
我们会定期地往匹配算法中引入一些变化(例如,增加像“工资”和“行业”这样的特征),或者修正产生输入数据集过程中的一些错误。
在这些情况下,我们重新运行了泊松回归的训练过程并获取了一系列新的权重。不过我们无法保证新的权重的效果就一定优于原本的,于是我们进行了A/B测试。这需要花费好几周来鉴别模型是否有提升,不过大多数的时间什么都识别不出来。我们对匹配算法的改进过程是很慢的,在这个过程中我们花费了很多时间。
因此,我们采取了一种新的方法,对数据中过去的工作申请,我们模拟了申请工作的访问者可能得到的搜索记录。
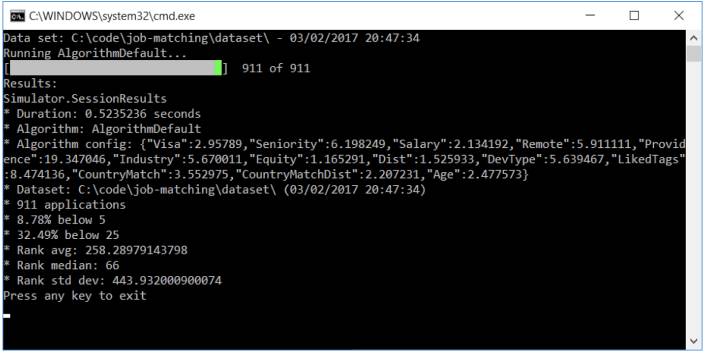
在这次工作匹配的模拟中,我们能够在32.49%的状况下把用户会申请的工作列在首页。相比于要花费两周的A/B测试,本次模拟只需要0.5秒。
下面是工作匹配的模拟过程:
设置一系列权重,例如{age: 0.2, distance: 1.42, industry: 3.08, …}
对每一份工作申请,我们用刚才定的权重计算申请进行时的工作列表中每一份工作的分数,比如:
score = 0.2 * AgeDays + 1.42 * LogDistanceMiles + 3.08 * IndustryMatch…
根据分数对工作进行降序排序,然后在排序后的列表中找到用户申请过的工作的位置。例如:“对123号申请人,他申请的工作在模拟结果中的第6个位置”;
计算所有被申请的工作的平均序号。
工作申请的平均序号给了我们一种衡量匹配算法表现的方法。这个平均序号越小,我们对工作的排序越好。我们可以通过不同权重组合来尝试不同的兴趣公式,然后在几秒钟就能通过模拟来衡量我们的工作排序的效果如何。远远好于等好几周来得到A/B的结果!
工作申请的平均排序数仅仅是我们测量匹配算法表现的其中一种方式。实际上,我们现在使用“此位置的工作会被点击的可能性”,这基于实际的点击数的排名。(见下图)
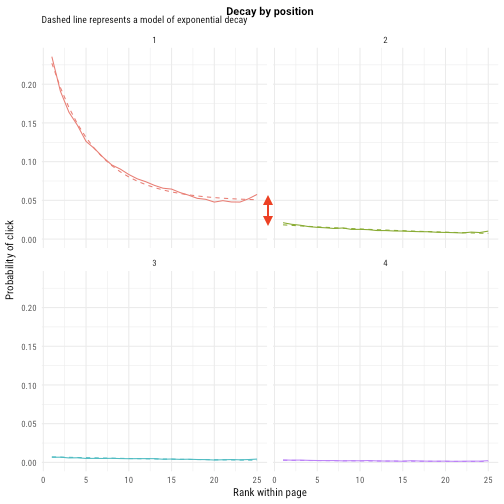
工作在结果中排的越靠前,被点击得就越多。上面的每一个图都代表了一页(第一页,第二页…)。我们发现在第一页的最后一个结果要比在第二页的第一个结果获得更多点击。
于是现在我们能够重新设一组权重,然后获得一个对性能的即时衡量。在这个基础上,我们能开发一个遗传算法(https://en.wikipedia.org/wiki/Genetic_algorithm)来尝试千千万万种可能的权重组合,然后在其中选出最好的一组权重。这都是我们用来获取实际应用中的匹配算法中的权重的方式。
在56个逻辑处理器的基础上运行遗传算法
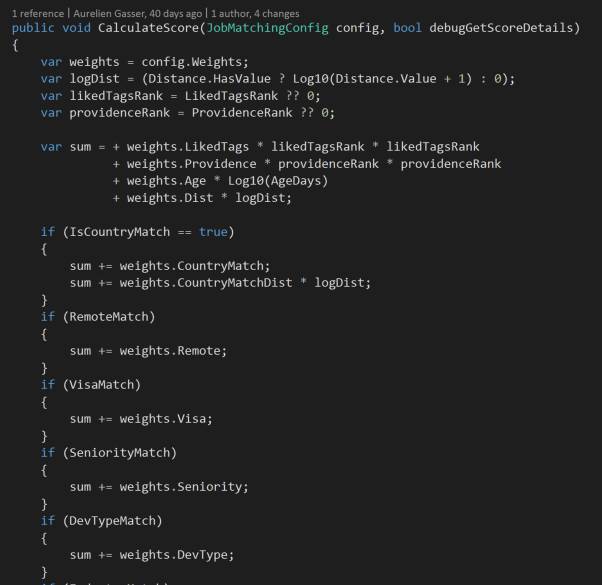
匹配算法:结合所有的特征来计算出一个工作的得分
匹配,哪里都是匹配
工作匹配成熟了以后,我们就能充分利用它了。我们比以往任何时候都对工作匹配的能够帮助我们的用户找到他们梦想工作的潜力充满信心。并且,我们知道它能给Stack Overflow Jobs带来竞争力。所以,我们也做了一些改变让工作匹配更加突出。
直到此时,匹配算法仅仅被用在了Stack Overflow Jobs的主页上。换句话说,当你在页面上键入像C++这样的关键字,或者筛选了高级工作,那么工作匹配算法就用不到了。工作会由后台的搜索引擎Elasticsearch进行排序。我们决定对所有工作的搜索结果默认用“按匹配(matches)排序”。A/B测试也证实了这种变化能大大增加工作的访问量和申请量。
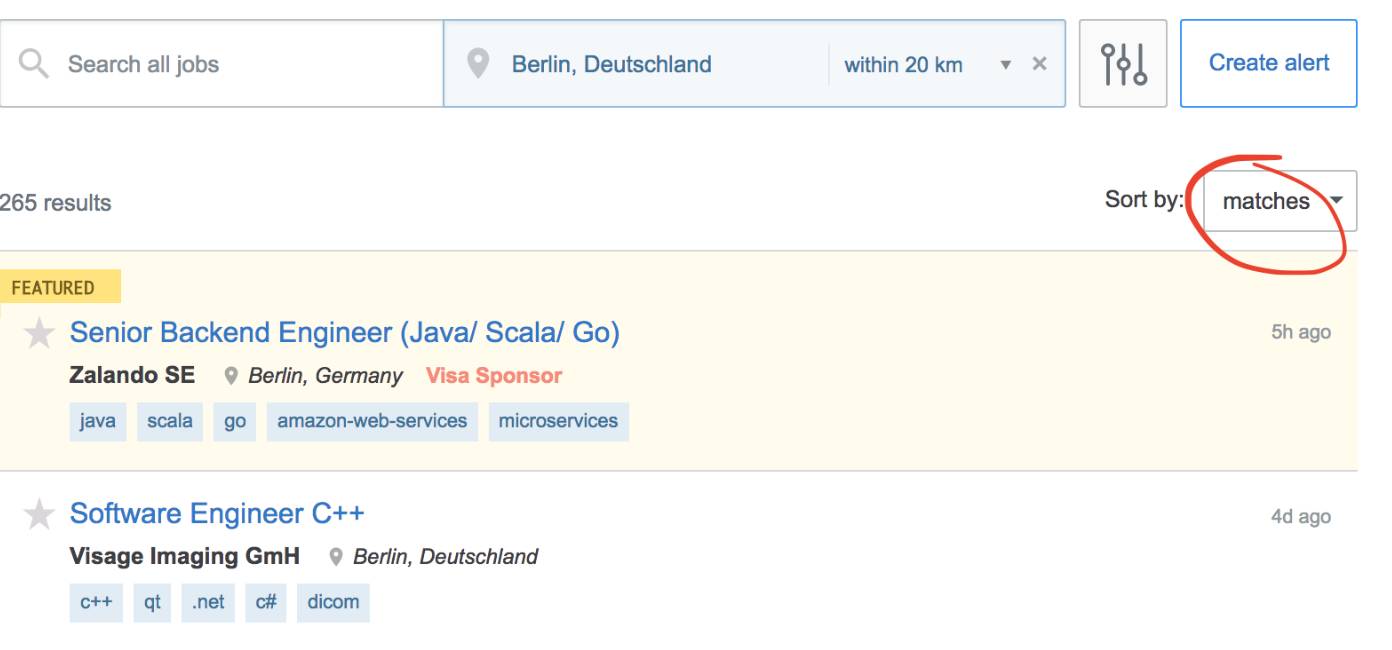
匹配算法得到的搜索排序结果
工作提醒(Job alerts)可以让你直接从电子邮件收件箱收到最新的工作列表,这个功能的新版本也用到了匹配算法。这意味着大多数你有兴趣的工作都会在邮件中先显示了。快来试一下吧,进入你的搜索标准(Search criteria)(https://stackoverflow.com/jobs?utm_source=so-owned&utm_medium=blog&utm_campaign=gen-blog&utm_content=blog-link)然后点击邮件提醒。
与此同时,在我们在工作搜索中也引入了其他一些改进(https://meta.stackoverflow.com/questions/336846/upcoming-improvements-to-job-search),包括大量新的筛选条件,和提升过,更有效率的UI.
R语言和优化
使用遗传算法来找到工作匹配中的最优权重的确很有用,但也是非常低效的。实际上,当我们发现了更好的替代做法时,我们才意识到这种做法确实非常低效率。
为匹配算法找到最优的权重组合是一个优化问题(https://en.wikipedia.org/wiki/Optimization_problem):我们的目标是最小化所有被申请工作在我们排序的列表中序号的中位数。这个中位数越小,就说明我们对用户将要申请的工作预测越好。有许多技术可以用来解决这个优化问题,这其中用的最好的是R语言中的optim(https://stat.ethz.ch/R-manual/R-devel/library/stats/html/optim.html)函数,它采用梯度下降(https://en.wikipedia.org/wiki/Gradient_descent)的方法。梯度下降的方法的表现要远远好于我们的遗传算法。这个方法找到的权重要更好一些,更重要的是它比我们的遗传算法快了70倍。具体地说,现在找到最用的权重组合只需要10分钟,以前用遗传算法需要12个小时。
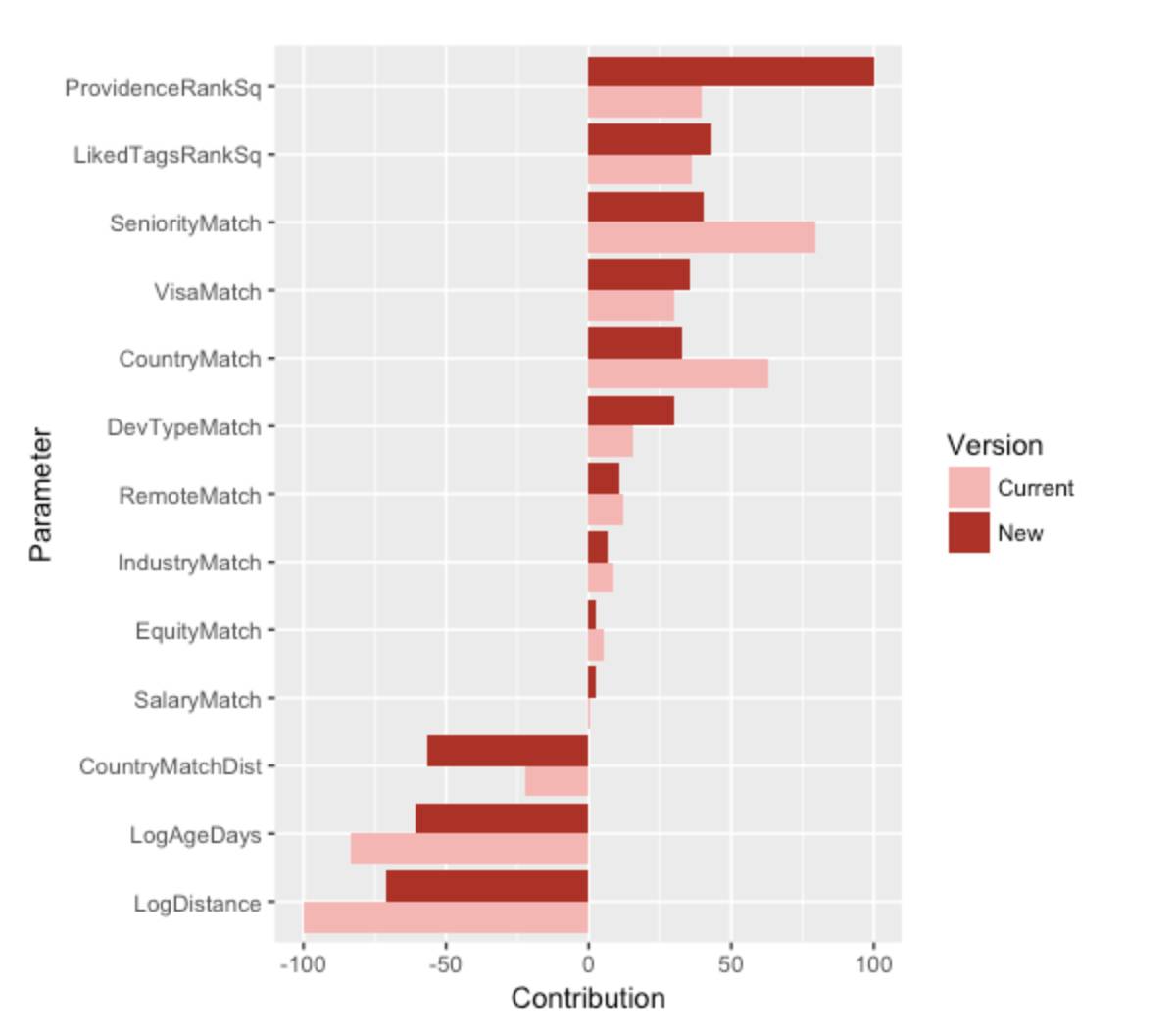
特征在兴趣度公式中的贡献度。Current和New指的是匹配算法的版本。
在C#中写我们自己的遗传算法不是一个好主意,因为这需要花费我们好几周来实现、测试和优化,更不要说花在等待结果上的时间了。R中的optim函数是可用的更好的的方法。因为我们没有做很好的研究,所以浪费了一些时间。
从C#的实施换到R上还有一些好处,比如说可以用R Markdown(http://rmarkdown.rstudio.com/)出产更漂亮的报告和使用本地矩阵运算来进行更快的模拟。实际上,兴趣度得分大多数是线性组合(score = a * Distance + b * Age + c * ProvidenceScore…),我们几乎可以一次性算出所有用户和工作组合的分数。
我们可以通过把用户和工作矩阵(M*N度)乘上权重向量(N维)其中:
M是我们数据库中的用户和工作对数。(M约等于1千5百万);
N是要匹配的特征的数量(N约等于14:距离,年龄,Providence分数等)。
一旦我们计算好了新的一组权重(新的版本),我们就能测试相比旧版本,它的性能怎么样。我们用在同一组数据集上进行两次模拟来做到上面这一点:一次用新的权重来模拟,一次用旧的权重来模拟。此外,我们一种叫作Bootstrapping(https://en.wikipedia.org/wiki/Bootstrapping_%28statistics%29)的技术,可以使得新旧两组权重在测试集的子集中进行多次比较,然后看哪个版本的权重更经常地表现更好。
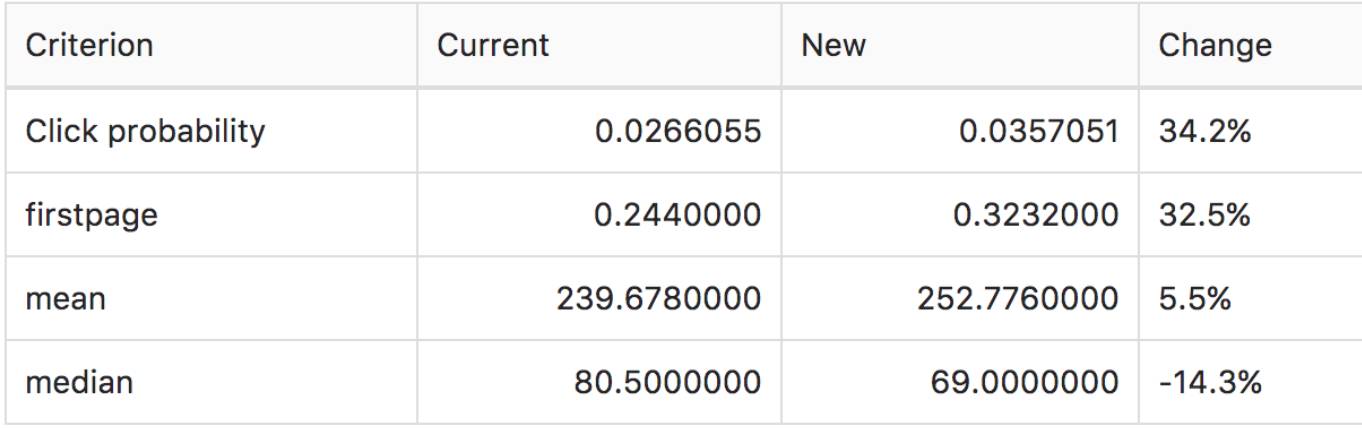
比较当前的权重设置和新的权重设置的性能。其中百分比的数字是通过Bootstrapping得来的。这里显示新的权重比老的权重好。
性能
在Stack Overflow中,性能是一个特征(https://blog.codinghorror.com/performance-is-a-feature/)。我们总是希望可以让我们的产品,当然也包括工作搜索,变得更快。
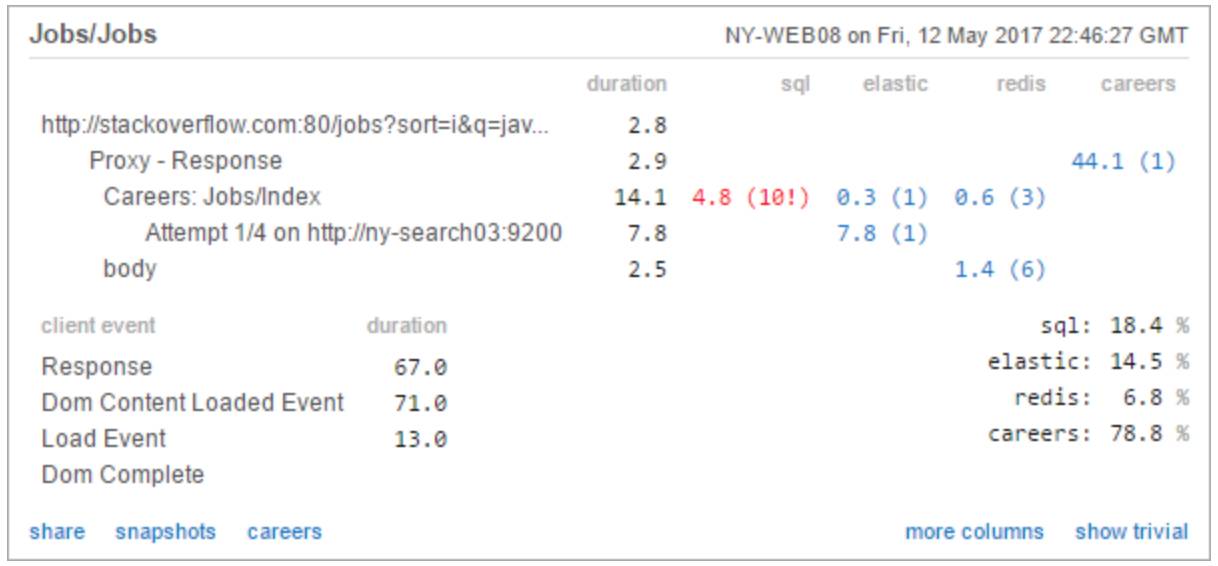
这里我们用MiniProfiler(http://miniprofiler.com/)来追踪请求时间
大概在两年前,我们从SQL Server转向了使用Elasticsearch(https://github.com/elastic/elasticsearch), 一个基于Apache Lucene的搜索引擎。这为我们提供了更棒的特征,比如词干(Stemming)(http://nlp.stanford.edu/IR-book/html/htmledition/stemming-and-lemmatization-1.html)和建议(Suggestions)(https://www.elastic.co/guide/en/elasticsearch/reference/current/search-suggesters.html)。在典型的工作搜索中,下面的步骤会被执行:
(0毫秒)把查询字符转化成表达树(例如 query=java&location=London);
(5 到60毫秒)把表达树传给Elasticsearch,然后返回匹配的工作(持续时间由结果数量决定);
(0毫秒)从缓存中检索工作细节,既可以从网页服务器里的内存中获得(L1),也可以从redis中获得(L2)。很明显L1更流行,因为它实际上是免费的;
(1到10毫秒)用匹配算法对内存中的工作进行排序,然后返回结果页面(持续时间由结果数量决定)。
从Elasticsearch引擎中检索工作是最耗时的工作。因为我们想要用匹配算法对工作进行排序,我们需要从Elasticserach中返回所有给定搜索的工作列表(而不仅仅是结果的前几页)。换句话说,用户最有兴趣的工作可能是任意一个Elasticserach返回的工作,我们毫无疑问需要得到所有的列表。我们计划把匹配算法作为插件加到Elasticsearch中来使整个过程变得更快,是我们能在单步执行中就完成第2,3,4步。
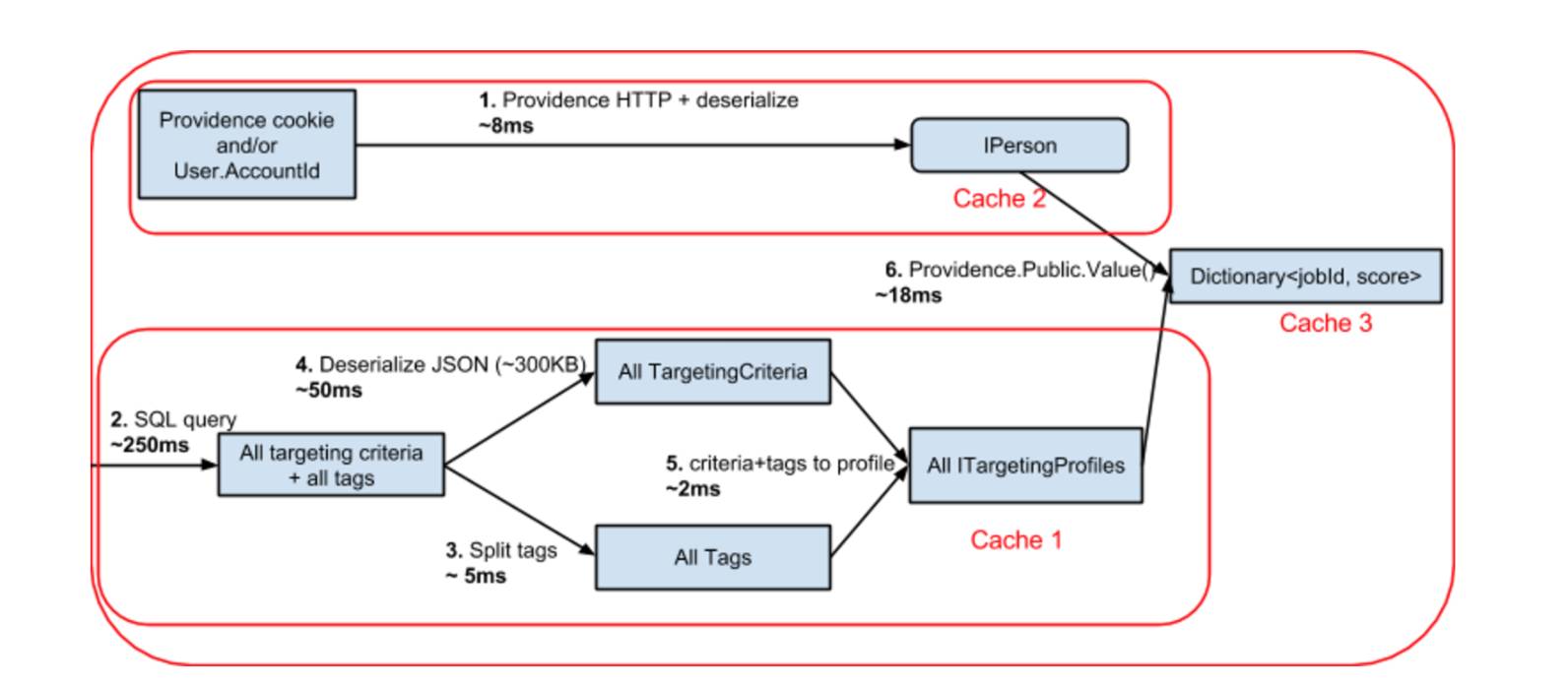
过去的性能优化环
几周以前,我们又加入了新的优化:我们把没有关键字匹配的搜索都放在网页服务器的内存(L1缓存)中执行,把几种需要Elasticserach的搜索放在一起。
也许有人会问关于用户的信息如何处理:
并行化的取出一个用户对工作的偏好(存在SQL中的JSON文件)需要不到1毫秒的时间;
并行化的取出用户访问Providence的记录(从内部API检索到的JSON)需要不到5毫秒的时间;
在上述两个情况中,数据都是被缓存在网页服务器的内存(L1)中的,所以接下来一系列同一个用户的检索请求都是不需要再花费时间的。
后续工作
Stack Overflow的工作搜索在过去的几年中经过了长足的发展,从不智能的算法发展到精妙的算法。但仍然还存在很多需要做的工作。
最近,我们尝试使用了基于标签同义词(Tag synonyms)(http://stackoverflow.com/tags/synonyms)的更智能的工作标签。我们也尝试了显示用户自从上一次访问以来所发布的工作。不幸的是,这些尝试都没有在显示更相关的结果中取得成功。
但是一些其它的主意成功了。
我们分析了一些最普遍的搜索项,然后优化了搜索结果,使得它能够包含同一短语的变形的结果。例如,搜索了“ML”(https://stackoverflow.com/jobs?sort=i&q=ml&utm_source=so-owned&utm_medium=blog&utm_campaign=gen-blog&utm_content=blog-link)会给出和搜索“Machine Learning”(https://stackoverflow.com/jobs?sort=i&q=machine+learning&utm_source=so-owned&utm_medium=blog&utm_campaign=gen-blog&utm_content=blog-link)同样的结果。除此之外,我们还把匹配算法和Elasticserach的内部分数整合到了一起,所以兴趣度分数还会考虑到工作列表和用户键入的关键词的匹配程度。
另外一个主意是充分利用用户Developer Stories(http://stackoverflow.com/users/story/join)中获得的经验标签。如果一个用户有使用redis的开源项目或者最近有Java相关的专业经验,那么用户对Java/redis的工作有兴趣的可能性将会大大提高。这些都是我们考虑了很久的事,但现在都是积压工作,这些工作将会在未来的6到8个星期内开展。
最后,是匹配算法对工作申请的优化:它会显示出我们认为你最有兴趣申请的工作,那么怎么能做到更好呢?我们可以通过雇用情况来优化。如果我们收集到了更多关于对工作的申请被雇用了的信息,那么我们不仅能列出你最优兴趣的工作,还能列出你最可能被雇用的工作。
非常感谢大家在Meta Stack Overflow(https://meta.stackoverflow.com/questions/tagged/jobs)上的反馈和指出我们的错误。这对我们来说是非常有价值的,我们很感谢大家的帮助。
想要找工作吗?来浏览一下Stack Overflow Jobs(https://stackoverflow.com/jobs?utm_source=so-owned&utm_medium=blog&utm_campaign=gen-blog&utm_content=blog-link)。
原文标题:A Dive into Stack Overflow Jobs Search
原文链接:https://medium.com/@aurelien.gasser/a-dive-into-stack-overflow-jobs-search-62bc6e628f83

顾佳妮,香港科技大学研究生,对数据挖掘和机器学习领域有极大的兴趣。目前就职Teradata从事数据挖掘与数学建模工作,擅长数学建模和数据库运维,致力于在数学科学的道路上发展。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
为保证发文质量、树立口碑,数据派现设立“错别字基金”,鼓励读者积极纠错。
若您在阅读文章过程中发现任何错误,请在文末留言,或到后台反馈,经小编确认后,数据派将向检举读者发8.8元红包。
同一位读者指出同一篇文章多处错误,奖金不变。不同读者指出同一处错误,奖励第一位读者。
感谢一直以来您的关注和支持,希望您能够监督数据派产出更加高质的内容。
转载须知
如需转载文章,请做到 1、正文前标示:转自数据派THU(ID:DatapiTHU);2、文章结尾处附上数据派二维码。
申请转载,请发送邮件至datapi@tsingdata.com

公众号底部菜单有惊喜哦!
企业,个人加入组织请查看“联合会”
往期精彩内容请查看“号内搜”
加入志愿者或联系我们请查看“关于我们”


点击“阅读原文”加入组织~