业界 | 一统所有AI芯片:Facebook揭秘深度学习编译器Glow
选自EE Times
作者:Rick Merritt
机器之心编译
机器之心编辑部
一名 Facebook 高管在最近的一次活动中证实,这家社交网络巨头正在招募芯片工程师,并已在设计至少一种 ASIC。在本周的 Facebook @Scale 2018 大会上,Facebook 宣布五家芯片公司将支持 Glow(这是一个开源的深度学习编译器),其中包括英特尔、Marvell、高通、Esperanto 和 Cadence。
「Facebook 确实正在组建芯片团队,不仅与芯片供应商合作,我们也在构建自己的芯片。当然,这不是我们的首要目标,」Facebook 基础设施副总裁 Jason Taylor 表示。这位高管称 Facebook 的目标并不等同于谷歌的深度学习加速器 TPU,但他拒绝透露发布时间节点等更多具体细节。
与多达 50 家 AI 加速器设计公司进行合作是 Facebook 新设芯片部门的工作重点。「目前市面上已有很多种加速芯片,」Taylor 表示,「最大的问题是,它们针对的工作负载是否是当前最重要的。」
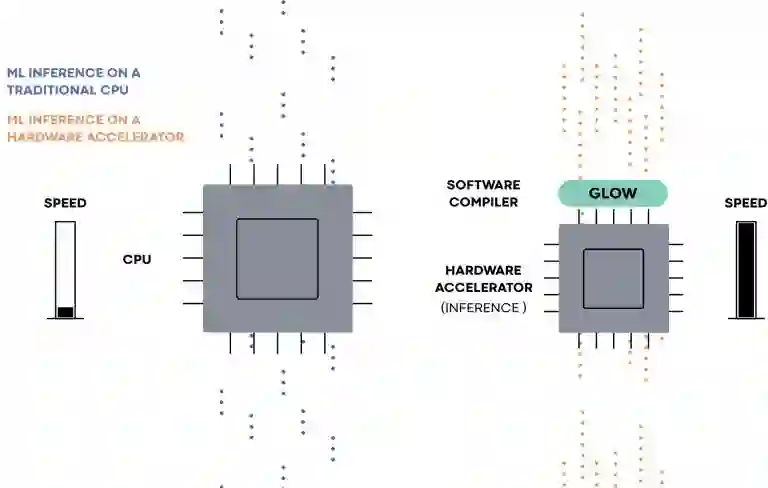
在 Keynote 中,Taylor 将 Glow 描述为一种通用编译器,可让开发人员针对所有新兴的深度学习加速器进行推理——在云端或者边缘网络。它不面向手机等客户端系统。
「我们预计深度学习加速器硬件也会出现碎片化的情况,我们在 Glow 上的工作是为了帮助机器学习专家设计神经网络,并让他们从对每种特定芯片的适配工作中解脱出来。」Taylor 表示。「我们知道碎片化即将到来,现在没有人知道哪种硬件资源的组合(如片上存储模块和乘法累加阵列)会最终取胜。所以我们让开发者聚焦于更高层级的计算图中,而无需动手动编码针对硬件的细节。」

Jason Taylor 将 Glow 描述为在云端和边缘网络上进行推断的编译器。(图源:Facebook)
Glow 采用 TensorFlow 或 Caffe2 等框架生成的 AI 图像,然后将它渲染成用于硬件加速器的字节代码,Taylor 解释道。该编译器包括多个工具,如用来生成用于芯片特定内存配置的指令排程器、线性代数优化器、内存分配器,以及用来测试硬件准确率的基于 CPU 的推断实现。
益华(Cadence)、Esperanto Technologies、英特尔、Marvell 和高通称它们未来的芯片将支持 Glow。Taylor 期待将其他芯片厂商也添加到支持 Glow 的厂商名单上。「这是开源 Glow 的好处之一。」
一名高级芯片专家将 Glow 描述为在生产系统中部署神经网络的框架。其输入是 TensorFlow 或 Caffe2 等框架创建的图。
一些著名的芯片厂商已经开始支持类似的软件。例如,英伟达的 Tensor RT 将来自框架的图作为输入,然后为 GPU 输出 Cuda 代码。
传统上,编译器是针对特定芯片进行严格优化的。但是 Taylor 表示,「当前编译器的编译范围要比过去大得多——Glow 中的优化类型要识别可以渲染给硬件加速器的图像中的很大一部分。」
在快速发展的深度学习领域,Glow 是努力弥补软硬件差距的最新例子。例如,英伟达的 Tensor RT 现在已经发展到第五代,尽管其第一代仅在一年前发布。一些加速器初创公司对支持各种软件框架及其变化所需的工作水平有些无能为力。
Facebook、微软等公司正在支持 ONNX,这是一种用权重表示图形的标准方法。去年 12 月份,Khronos 的团队发布了深度学习加速器的一个硬件抽象层——NNEF。
Glow 是 Pytorch 1.0 的一个组成部分,后者是一个开源项目集,包括合并的 Caffe2 和 Pytorch 框架。Pytorch 1.0 的第一次开发者大会将于 10 月在旧金山举行。
在另一个演讲中,Facebook 工程经理 Kim Hazelwood 展示了 Facebook 使用的十多个不同深度学习工作负载,它们部署在至少四个不同类型的神经网络上。每天 Facebook 生成超过 200 万亿次推断,翻译 50 多亿文本,并自动删除超过一百万虚假账号。
她说,Facebook 的一些推断任务需要的计算量是其它任务的 100 倍。如今,Facebook 在其设计的一小部分 CPU 和 GPU 服务器上运行这些任务。
Hazelwood 告诉 EE Times,从通用硬件转向定制硬件将需要针对那些仍在变化的工作负载定制芯片。她拒绝透露 Facebook 关于使用任何定制 AI 加速器的想法。

仅 Facebook 就在十几个深度学习应用中使用了至少五种神经网络。
一位观察者推测,Glow 将是一个理想的工具,使公司能够采用一些适合其各种工作负载的加速器。其半导体团队可以帮助公司精选芯片,也许还可以为其中一些公司提供定制芯片的建议。
另外,Facebook 发布了一篇博客,描述了它创建的一个新软件工具,该工具使用深度学习来调试代码。它说,SapFix 可以自动生成特定错误的补丁,然后将其提交给工程师审批并部署到生产中。
迄今为止,Facebook 已经使用 SapFix 加快了向装有 Facebook Android 应用程序的数百万台设备发送代码更新的进程。Facebook 表示将发布该工具的一个版本,但没有说明发布时间。

原文链接:https://www.eetimes.com/document.asp?from=groupmessage&isappinstalled=0&doc_id=1333716&page_number=1
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




