吴恩达新书《Machine Learning Yearning》中7个实用建议(附论文)

作者:Dan Clark, KDnuggets
翻译:顾佳妮
校对:丁楠雅
本文约2200字,建议阅读8分钟。
本文为你介绍吴恩达新书中的7个使用建议,致力于讲明白机器学习算法是怎样工作的,以及如何构建一个机器学习项目。
《Machine Learning Yearning》是人工智能和深度学习界的专家吴恩达写的一本书,这本书致力于讲明白机器学习算法是怎样工作的,以及如何构建一个机器学习项目。这里我们选取了这本书中7个非常有用的建议向大家介绍。
人工智能、机器学习和深度学习这些概念在飞速发展同时促使着工业界发生转变。吴恩达是这个领域的领军人物之一,他是Coursera联合创始人,百度人工智能团队的前负责人,以及谷歌大脑的前负责人。他正在写一本叫做《Machine Learning Yearning》的书来教大家怎样构建一个机器学习项目(网上可以得到免费的初稿)。
吴恩达在书中写道:这本书不在于教你机器学习算法,而是教你怎样使用机器学习算法。有些人工智能培训班会交给你一个工具,而这本书教你的是怎样使用这个工具。如果你想成为人工智能行业中的技术领袖,然后为自己的团队设定目标的话,这本书会给予你帮助。

我们读了初稿,然后从中选取了7个最有趣实用的建议:
一、优化指标和满意度指标
在评估一个算法时,你应该考虑使用多个衡量指标,而不是采用一个单一的公式。其中一个方法是同时使用优化指标和满意度指标。
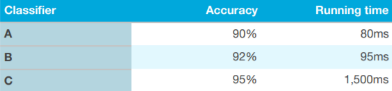
通过上面表格中的例子,我们先预设一个可以接受的执行时间比如小于100毫秒,这个执行时间的衡量标准就可以作为我们的满意度指标。分类器的执行时间只要在这个标准下就可以了。在这里准确率是一个优化的指标,这是一个评价算法的非常有效又简便的衡量手段。
二、尽快选定项目需要的验证集或测试集:
不要害怕后期是否需要替换
吴恩达表示当开始构建一个新项目时,他会尽快确定验证集或测试集来给团队一个定义明确的目标。起先会设定一个为期一周的目标,这个时候最好能够尽快想出方案然后推动项目往下进行,就算想出的方案不是那么完善也比顾虑太多要好。
话虽如此,要是你突然意识到一开始的验证集或测试集是错的,不要害怕去改正它。以下三个原因可能造成选出不正确的验证集:
真正要解决的问题的数据分布和验证集的分布大不相同。
验证集过拟合。
选择的衡量标准并不是这个项目真正想要的优化目标。
要记住做出变更并不是什么大问题,只要往下继续并让你的团队知道当下新的目标是什么就可以了。
三、机器学习是一个迭代优化的过程:
不要指望它一开始就能起作用
吴恩达说他做一个机器学习项目包括三个步骤:
从产生一个想法开始。
用代码实现这个想法。
做实验判断这个想法如何。
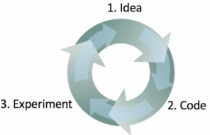
这个循环走得越快,项目的进展就越快。这也说明了为什么在一开始确定好验证集是非常重要的,因为这样可以在迭代优化过程中省下很多时间。衡量数据集上的表现也可以让你迅速知道项目是否在一个正确的方向上。
四、快速开发第一个系统然后迭代
正如第3点中所说,构建机器学习算法是一个迭代的过程。在吴恩达的书里有一章节的篇幅说明快速开发一个系统的好处:“不要试图一开始就去设计和开发出一个完美的系统,而是应该在几天内迅速发开训练一个基本的系统。就算这个初步的系统离你可以发开的最好版本还差得很远,检验这个基本系统的功能也是很有价值的,这样你可以迅速找到证据来确定值得你投入时间的最有保障的发展方向。
五、并行地评估多个想法
当团队对改进一个算法有很多想法时,你可以并行地高效评估这些主意。这里用识别猫咪图像的算法来举例,吴恩达介绍说当他想要过目100个被错误分类的验证集图片的时候,他会用一个电子表来记录然后一边检查一边填写。

上表中包括了每一张图片为什么会被分错类,还有额外注释便于日后的回顾。当完成这个表的时候,你就能获知哪些想法可以消除更多的误差,哪些想法应该被追踪。
六、考虑是否要修正错误标注的测试集
当你进行误差分析时,有可能会注意到验证集的某些样本是被错误标注的,例如图片在人工标注时被打上了错误的标签。如果你怀疑其中一部分误差是由这些错误标注造成,那可以在刚才提到的电子表格中多加一个类别。
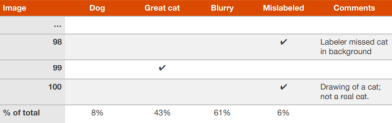
当表格快完成的时候,就可以考虑这些错误标注是否值得花时间修复了。书中给出了两个可能的场景来帮助我们判断这些错误是否值得修复。
例1:
测试集上总体正确率…………………… 90%(10%的总体错误率)
由于标错的样本造成的错误率…… 0.6% (6%的测试集错误率)
由于其他原因造成的错误率………… 9.4% (94%的测试集错误率)
“在数据集中,相比于9.4%可以改进的错误率,由于错误标注导致的0.6%的错误率是无足轻重的。当然修正这个错误标注没有什么坏处,但是也没有必要做。你的系统整体错误率是10%还是9.4%都是可接受的。“
例2:
测试集上总体正确率…………………… 98%(2%的总体错误率)
由于标错的样本造成的错误率…… 0.6% (30%的测试集错误率)
由于其他原因造成的错误率………… 1.4% (70%的测试集错误率)
“验证集上30%的错误是由于误标注造成的,已经对准确率的评估增加了极大比重的错误。这个时候就值得来改善测试集的标签质量了。处理好错误标注的样本可以帮你解决分类器的错误率是1.4%还是2%的问题,相对来说这两者有巨大不同。“
七、考虑把验证集分成小的子集
如果你在一个较大的验证集上有20%的错误率,那么值得把这个验证集分成两个子集:
举一个算法在5000个验证集上分错1000个样本的例子。假设我们想要人工检查100个错误样本(10%的错误样本)对其进行错误分析,那么应该从验证集中随机抽取10%然后放到一边,暂时称它为“引人关注的验证集”来提醒我们要看一下这部分验证集(在语音识别项目中,你需要听一下录音片段,这个时候可能将划出来的验证集称为引人关注的验证集)。这个需要关注的验证集中有500个样本,我们可以预期算法会在其中分错100个左右。
验证集的第二个子集叫做黑箱验证集,里面剩有4500个样本。可以用黑箱验证集中样本的的错误率来自动评估分类器的效果。可以用这个测试集来选算法或者调参数。而然,需要注意的是你应该避免具体去看这些样本。我们之所以使用黑箱这个词是因为我们只需要用这部分子集来评价分类器即可。
参考文献
Don’t learn Machine Learning in 24 hours
https://www.kdnuggets.com/2018/04/dont-learn-machine-learning-24-hours.html
A Basic Recipe for Machine Learning
https://www.kdnuggets.com/2018/02/basic-recipe-machine-learning.html
10 Free Must-Read Books for Machine Learning and Data Science
https://www.kdnuggets.com/2017/04/10-free-must-read-books-machine-learning-data-science.html
原文标题:7 Useful Suggestions from Andrew Ng “Machine Learning Yearning”
原文链接:https://www.kdnuggets.com/2018 /05/7-useful-suggestions-machine-learning-yearning.html
译者简介

顾佳妮,香港科技大学研究生,对数据挖掘和机器学习领域有极大的兴趣。目前就职Teradata从事数据挖掘与数学建模工作,擅长数学建模和数据库运维,致力于在数学科学的道路上发展。
翻译组招募信息
工作内容:将选取好的外文前沿文章准确地翻译成流畅的中文。如果你是数据科学/统计学/计算机专业的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友,数据派翻译组欢迎你们加入!
你能得到:提高对于数据科学前沿的认知,提高对外文新闻来源渠道的认知,海外的朋友可以和国内技术应用发展保持联系,数据派团队产学研的背景为志愿者带来好的发展机遇。
其他福利:和来自于名企的数据科学工作者,北大清华以及海外等名校学生共同合作、交流。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THU ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”拥抱组织





