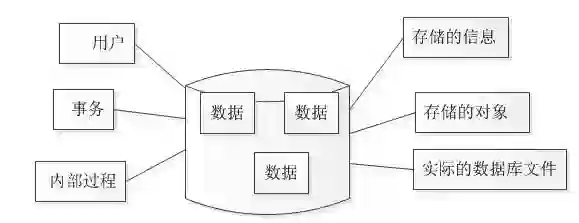
当我们谈数据库时,是在谈什么?


一直以来,数据库的核心研发团队都十分神秘,作为隐藏在幕后的隐士高人,他们对数据库发展以及数据库研发团队的看法是什么呢?本文我们就由巨杉数据库核心技术研发团队的“老司机”,向大家分享分布式数据库自研修炼之路。
数据库研发的最难点——技术基因与创新
数据库软件,特别是一款真正企业级产品,并没有大家想象的,只是开发一款软件那么简单。从技术上,数据库既要有技术基因传承又需要技术创新。
数据库技术到现在已经发展了40多年了。在技术的发展中,数据库软件/平台已经成为一个功能复杂、架构庞大、安全要求很高的庞大软件产品体系。因此,技术上既需要有技术的积累,也需要新的创新。
在应用层面,由于用户都是银行、政府等这些30年前就开始使用数据库的老客户,他们通常无法承担全盘迁移的风险,因此在业务技术架构上,难免保留了各个时代的历史遗留。比如说,北美一些银行的核心IT系统,直到目前仍然运行在40年前的技术平台之上。这也要求企业级Ready的数据库基础软件得有很强的兼容能力,不但可以保证旧业务的运行,还可以不断地推陈出新。
因为这些特点,基础软件特别是数据库的研发,和其他应用软件有很大的不同。其中最大的一个不同点就是开发语言和开发模式。
从计算机的发展来看,C是最面向机器语言(汇编代码)的,原则上每一行C代码都可以很精准地映射到一些汇编指令上,因此从对操作系统底层的操控来看最为精准。
而C++则是在C之上发展起来的面向对象语言。在底层编程中,C++的高级特性被使用得非常少,但是其设计模式对于模块化开发很有帮助。因此使用C++既可以兼顾对操作系统底层最精准的把控,也可以将一些面向对象的理念融入代码中,在复杂系统构建时起到重要作用。
而如今新的一些新型开发语言则不是面向对象,因此在设计模式上不适合大型复杂系统的开发。同时,这些语言简化了很多C/C++里最为重要的指针概念,使其对内存的精准操作变得不可能完成。指针这个概念用好了是神器,用差了是垃圾,大部分能力不高的程序员,或者没有非常完善测试框架的项目很难完美把握指针这类高级特性,使得大型项目开发里面内存泄露和崩溃漏洞遍地都是。
但是对于我们巨杉来说,有着DB2数据库内核的研发经验,从人员能力、到代码质量管理,到测试框架的完善,都能够完美驾驭这类高级特性,最大程度挖掘出操作系统和数据库底层的性能与处理能力。
数据库研发团队——技术基因与积累
IBM是最早提出“关系型数据库”这一概念和理论体系的公司,从技术上看,传统三大关系型数据库在发展过程中,其实已经具有很深远的技术储备了。DB2是三大传统关系型数据库中唯一的分布式产品,因此我们团队在分布式技术方面的积累是一脉相承的。
我在DB2的十几年里,感受最深的就是技术底蕴和沉淀。比如说,在Unix真正支持线程机制之前,针对多线程模型,甚至是针对不同的硬件设备,他们早已使用汇编语言实现了逻辑线程的切换和调用,这些机制在当时其实是相当领先的。
说到研发团队,IBM的实验室也是卧虎藏龙。从最初使用汇编语言开始的技术专家们,一直在参与数据库、操作系统和编译器底层的研发工作,可以说正是他们创造了最早的关系型数据库的概念,也是他们真正把数据库打造成为一个通用的软件平台。
因此,数据库核心研发团队的基因很重要。IBM数据库产品的沿袭,DB2团队就是以多位数据库老炮为核心,搭配有技术实力的资深工程师。 不像现在很多的开源新产品是以年轻创新团队为主。就像我上面提到的技术复杂度和产品历史跨度问题,数据库如果要在大型企业使用,技术团队必须要有传统数据库的开发经验,这也就是技术老炮存在的作用。
对比海内外的数据库研发团队,海外拥有人才的基础,也有像IBM Oracle这样的体系的沿袭,培养出了很多的技术人才和团队。所以北美现在很多的新一代基础软件产品团队还是围绕了老一辈的“老司机”构建的。
国内基础软件的人才积累还不够,因此基础软件领域还没有完全形成基础软件领域的武林门派,这也是近年来基础软件和AI领域国内企业疯狂往外招人的原因。但是数据库由于历史原因,国内无论是互联网还是科研团队想要形成独特的门派,还需要时间。
巨杉这边我们的团队拥有以王涛为代表的很多DB2团队的核心技术专家,以及来自华为的技术核心团队成员,是技术基因和技术创新很好的结合。
数据库发展方向
对于大部分应用程序来说,账户信息、配置信息、维度表这类数据量相对比较可控,真正爆炸性增长的是流水类数据。一个应用程序里面绝大部分表不会太大,真正特别大使得传统关系型数据库存不下的表相对来讲数量都是可控的,因此有很多Workaround都可以搞定这个问题,这也是为什么传统以来大家用分库分表虽然麻烦,但也不是解决不了应用问题。
数据库其实真正面临的痛点是“微服务”下数据服务的资源池化。
应用程序从传统烟囱式构建,向微服务转型的过程中,在每一个微服务都放上一个独立的数据库已经是不可能的事情了。这种情况下,数据服务资源池需要直接面向上层成百上千个,来自不同开发商、不同团队的,开发能力不一、应用类型不同、SLA安全级别不同等等的各类需求。
因此,资源池必须拥有弹性扩张、资源隔离、多租户、可配置一致性、多模式(支持各类SQL协议)、集群内可配置容灾策略等一系列功能,同时每个数据库实例的计算和存储能力需要做到能够无限扩张,毕竟有些微服务可能会涉及到极多的流水数据,不能限定每个数据库实例使用的资源仅局限于一台物理设备。
所以说,单纯为了分布式的OLTP只是解决了不构成刚需的问题(分库分表早可以解决),但是在微服务应用开发的环境下,数据库更是要从资源池化的角度对上层提供服务,同时资源池中的每个数据库实例内部也要支持分布式交易等一系列特性,做到与传统数据库的全兼容。
关于巨杉数据库
近期,我们会发布一个新的版本,其中OLTP场景选性能会有大的提升,同时对于SQL处理能力也会有很大提升。在分布式的交易型业务下,整体性能提升将比现在版本有2~3倍的提升,对比同类产品性能将高出5~6倍,也请期待我们接下来的系列技术专题和技术活动。
虽然我们团队很多都是来自IBM、华为的“传统企业级IT人”,大家都习惯低调地隐藏在幕后。但是现在是技术圈一个变革的新时代,SequoiaDB巨杉数据库已经开源了,所以我们之后也会让我们团队的技术大牛们多多参与社区活动,分享一下我们做数据库核心研发的心得,也和大家一起进步。
作者简介:巨杉数据库核心研发成员,资深数据库架构师Danny Chen。有超过20年的数据库核心研发经验,是一名数据库资深工程师和架构师,曾经作为IBM DB2 内核研发团队成员参与了DB2、DPF等产品的架构设计和研发工作。
System.out.println("点个在看吧!");
console.log("点个在看吧!");
print("点个在看吧!");
printf("点个在看吧!\n");
cout << "点个在看吧!" << endl;
Console.WriteLine("点个在看吧!");
Response.Write("点个在看吧!");
alert("点个在看吧!")
echo "点个在看吧!"
,。