【XPU时代】解密哈萨比斯投资的IPU,他们要分英伟达一杯羹
1 新智元推荐
来源:StarryHeavensAbove
作者:唐杉 编辑:序媛
【新智元导读】DeepMind CEO Demis Hassabis 投资了一家AI芯片公司Graphcore,与英伟达形成直接竞争。这家刚刚完成3千万美元融资的公司,研发了又一个xPU:IPU(Intelligence Processing Unit)。在最近的RAAIS会议上,Graphcore的CTO,Simon Knowles做了一个介绍,让我们可以一窥IPU设计背后的一些思考。本文介绍了其几大特性,包括:同时支持Training和Inference;采用同构多核(many-core)架构,超过1000个独立的处理器;采用大量片上memory,不直接连接DRAM。
几个月前注意到Graphcore这个公司,是因为他们的IPU处理器:Intelligence Processing Unit。但除了看到他们一系列非常漂亮的DNN Graph(比如上面这个对于ResNet Conv1的可视化处理)之外,一直没有更详细的信息。在最近的RAAIS会议上,Graphcore的CTO,Simon Knowles做了一个介绍,让我们可以一窥IPU设计背后的一些思考。
“We’ve created a completely new processor that’s the first to be specifically designed for machine intelligence workloads – an Intelligence Processing Unit (IPU) that will set a new pace of innovation. ” “The IPU has been optimized to work efficiently on the extremely complex high-dimensional models needed for machine intelligence workloads. It emphasizes massively parallel, low-precision floating-point compute and provides much higher compute density than other solutions.” - Graphcore

从目前看到的信息,可以看到Graphcore IPU的一些关键Feature:
1. 同时支持Training和Inference,对于这一点,Graphcore有自己的一些独特的看法。
2. 采用同构多核(many-core)架构,超过1000个独立的处理器。每个处理器核的处理能力和具体支持的操作还不清楚。支持all-to-all的核间通信,采用Bulk Synchronous Parallel的同步计算模型(又是上个世纪80年代提出的)。
3. 采用大量片上memory,不直接连接DRAM。这可能是他们的架构中最激进的一个选择。
其它一些feature,如下
1. Training or Inference
Graphcore’s machine intelligence processors support both training and inference. If you’re thinking about it in terms of training and inference, though, you’re probably thinking about hardware for machine learning in the wrong way.
可以看出,当被问及他们的IPU是用于Training还是Inference的(这是对各种PU最常见的一个问题)时候,Graphcore试图从另一个角度去解答,即这种分类本身就是不对的(是目前某些厂商提出的不合适的说法)。总的来说,他们认为先做Training然后做Inference的机制,未来一定会被Learning取代。也就是未来理想的机器智能应该能够在部署之后还能保持持续的学习和进化。对于这个问题,Graphcore专门有一篇Blog做了说明,大家可以参考我在知乎上给出的翻译(https://zhuanlan.zhihu.com/p/28053630)。
另一方面,他们认为,从计算上来说,Inference和Training也有类似的特征。因此,他们的模型是下图这样,其中并没有Training的模块。
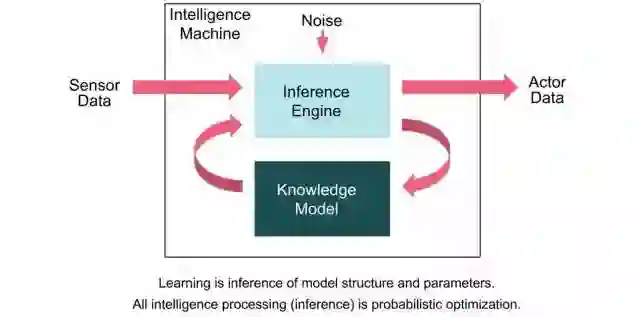
我的看法:
机器智能努力的方向之一就是Continuous Learning。如果在一个架构上能够同时很好的支持Training和Inference当然非常理想。不过从目前的实践来看,Deep Learning中的Training和Inference还是有较大的差异的,运算量的巨大差别,精度要求不同,算法差别,部署的Constraints等等。Graphcore最终推出的IPU能否很好的解决这些问题,还有待观察。
2. What Shall we bet is fundamental to MI workload

IPU的设计的基础是Graphcore对于机器智能的Workload的理解。“在所有形式的机器智能计算中,我们试图从数据中推断知识模型,然后使用这些学习的模型从其他数据推断出新的结果。所以在很大程度上,工作量是由知识模型的性质来定义的”。“知识模型和对它们执行推理所需的算法最自然地表示为图形(Graph)”。因此,他们用Graph来作为机器智能的基础表示方法。这种表示既适用于神经网络,也适用于贝叶斯网络和马尔科夫场,包括未来可能出现的新的模型和算法。
这些Graph的第一个特征,是它们规模很大,通常包括数千到数百万个顶点。这也意味着巨大的并行性。第二个特征是它们是稀疏的,大多数顶点只连接到其他一小部分顶点。因此,必须在架构上适应这种稀疏性,因为它对处理器之间的存储器访问模式和通信模式有重大影响。第三个基本特征是数据的统计近似值。从处理器设计的观点来看,这有利于低精度浮点运算。这可能是低精度数据的高性能计算的第一个主要应用,和传统的高性能计算(HPC)是非常不同的(或者说完全相反的?)。另一个特征是模型参数的重用性。简单来说,卷积是空间重用,而回归是时间重用。这种重用可以获取数据中的空间或时间不变性。同时,如果重用参数,则会将其作用于给更多的数据,从而更快地学习。最后一个基本特征是,图形结构可以被视为静态的 - 至少在很长一段时间内。这对于构建高效的并行计算至关重要,因为使得编译器可以在将程序映射到多核并行处理器时的三个NP hard任务有可能实现:1)平衡跨处理器核的计算任务;2)分区和分配内存;3)处理器之间的消息调度。
对于稀疏性,还可以更进一步的说明一下。当我们把图模型存储到物理可实现的存储器中的时候,存储器访问的有效稀疏度进一步增加了。例如,一个图中的顶点可能连接到同样接近的100个相邻顶点。但是,如果我将该顶点的状态存储在具有线性地址的存储器中,则它只能有两个直接邻居。在低维存储器中存储高维Graph的效果是使邻域分散在存储器中。这对于非常宽的向量机(如GPU)来说是一个潜在的问题。图处理有利于更细粒度的机器,从而有效地分散和收集(scatter and gather)数据。这就是为什么IPU拥有比GPU更多的处理器,每个处理器都设计用于处理较窄的向量。
基于上述对机器智能的Workload的理解,Graphcore提出了IPU的设计。

和CPU (scalar workload),GPU (low-dimensional workload)相比,IPU是为了high-dimensional graph workload而设计的。下面我们就看他们的一些比较有参考价值的设计上的考虑。
3. 架构设计的考虑
首先,他们也给出了一些会限制MI处理器的性能的因素,比如:1) Rate of arithmetic 2) Bandwidth or latency of data access (parameters, activitions, samples) 3) Rate of address calculation (high-dimensional models) 4) Rate of generation of random numbers (stochastic models)。但最后给出了最重要的限制因素,power。
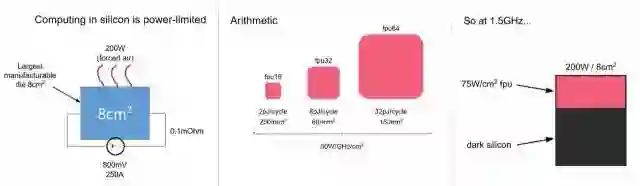
上图最左边说明一些功耗限制因素;中间对比了不同的浮点运算单元大体的面积和功耗;最后说明,如果给定功耗的面积的限制,芯片运行在1.5GHz,则芯片中只能有1/3的面积能够作为fpu(float point unit)运行。除非降低时钟频率,否则芯片中的很大一部分将无法工作(dark silicon)。
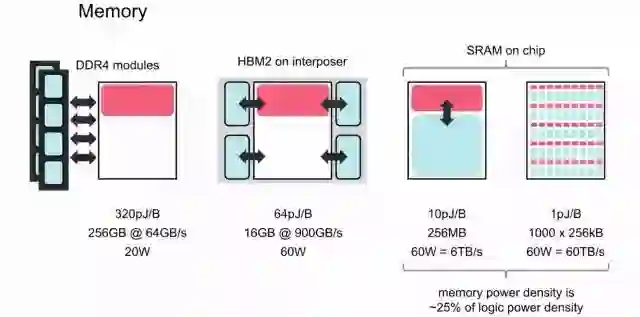
另外一个重要问题是存储。对于机器智能任务,GPU和CPU的性能受到其对外部存储器的带宽的限制。传统的外部DRAM系统(如DDR4或GDDR5)带宽太低,而且没有伸缩性。HBM在具有非常高的布线密度的硅衬底上使用垂直堆叠的DRAM die,其物理上非常接近处理器die。但它的生成困难,目前只用在最先进的芯片之中。此外,它把DRAM带入处理器的thermal envelope之中,因此处理器只能以较低速度运行。HBM2虽然能够提供更多的带宽(目标是1TByte/s),但仍然存在上述问题。最后一种类型的memory片上的存储SRAM,虽然相对性能好很多(访问速度快,功耗低,功耗密度相对逻辑电路也比较低),但是由于芯片面积主要用于逻辑运算,一般不会在芯片上使用太多SRAM。
但是,和常见的芯片架构不同,IPU采用了大量分布式片上memory的设计。这非常激进的方法,其目标是把所有的model都能够放在片上memory当中,如下图所示。具体来讲,IPU把大量的面积用于SRAM,所谓memory-centric chip,而适当减少运算单元fpu的面积,最终实现对power的充分利用。而GPU主要使用片外的memory,片上的面积中只有40%用于Machine Learning(fpu),而其它的50%的面积用于其它应用(Grahics,HPC)。由于GPU本身是面向多种应用的,这种设计也是很合理的。
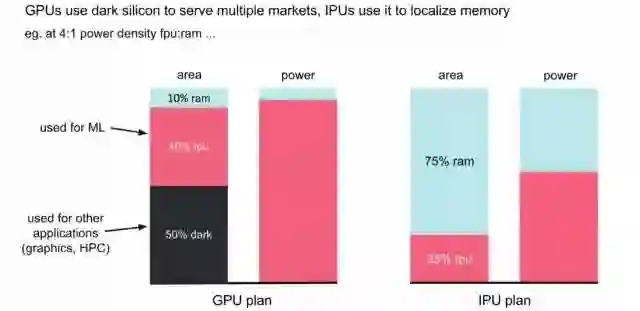
当然,即使在IPU上集成尽可能多的SRAM,容量也很难和GPU连接片外的DRAM相比。但是,对于很多模型来说,这个容量已经够用。而SRAM可以以100倍的带宽和1/100的延迟来访问,这种优势是非常明显的。技术模型的规模太大无法放到片上的memory中,还可以通过多个IPU互连来及解决问题。IPU采用的同构多核的方式,也让这种扩展比较简单。
另外,Graphcore看起来并不是非常担心内存容量的问题。他们的依据包括:
1. 目前对于减少机器智能的内存占用已经有不少好的方法,也有很大潜力。
2. IPU不需要用一些数学变换将卷积转换成矩阵乘法(貌似可以直接做卷积)。这些变换往往会增加存储的需求。另外,IPU不需要很大的Batch来提高并行的效率。
3. 可以通过重新计算来节省内存。例如,在GPU的DNN训练期间使用的大部分内存是存储正向传递中activitions,以便我们可以在反向传播期间使用它们。一个有效的替代方法是只保存定期快照(Sanpshot),然后在需要时从最近的快照重新计算这些activitions。这种方法可以减少一个数量级的存储,而计算只增加了25%。
我的看法:
之前和朋友讨论过在片上采用大量memory来保存所有模型参数的方法,不是很看好。Graphcore竟然采用了更激进的架构,甚至不直接外接DDR,还是比较出乎意料的。不过Graphcore给出的说明基本是可以支持他们这个架构选择的,也同时给了我们一个很不错的思路。希望后面能有更多细节和数据供我们分析。
4. Serialise computation and communication
Graphcore提出,“Silicon efficiency is the full use of available power”。因此,他们还提出一些更进一步优化效率的方法。其中比较有意思的是运算和通信的串行执行。这个提法听起来比较奇怪。我们一般都是希望运算和通信并行化,最好是能在Computation的过程中完成下一次communication,这也是很多架构优化的一个方向。但是,如果是在一个功耗受限的系统中,情况可能就不是这样了。
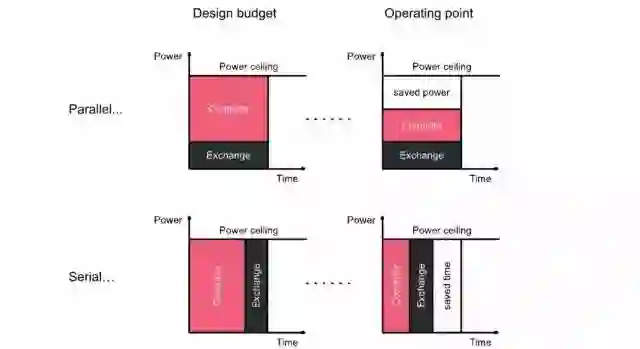
上图的上半部分是传统的方法。我们希望处理器间通信与计算重叠,因此可以根据预期的工作负载来分配这两者之间的功率预算。但是,在实际运行的时候,应用程序具有不同的平衡,结果往往是程序在一定时间内完成,但是消耗了较少的能力。这是因为通信或者计算部分在一定时刻可能成为瓶颈,而另一个则不能充分使用它的功率预算。
换一种思路,我们假定计算和通信串行执行,并不重叠,都充分使用最大的能量运行。那么,无论实际工作量如何平衡,该程序都有可能在最短的时间内完成。因此,这也是一种效率更高的方式。
5. 多核通信方式
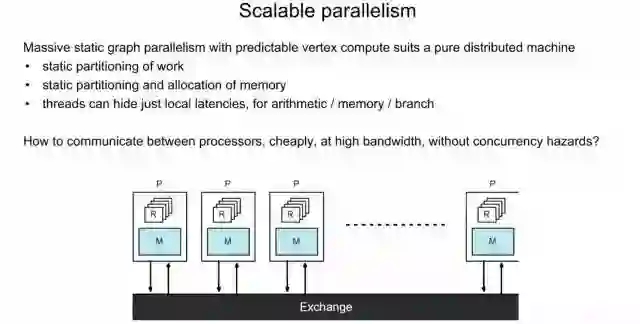
前面简单介绍了IPU采用了同构多核的方式,分布式的本地存储(没有共享存储)。另外,也介绍了它的“运算和通信的串行执行”的特色。那么在这种架构下,如何实现多个内核间的通信和同步呢?Bulk Synchronous Parallel的同步计算模型。
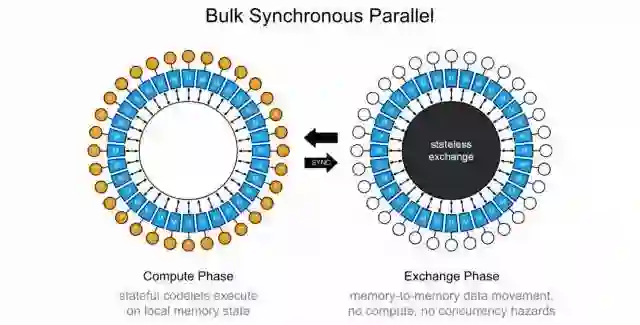
这又是一个上世纪80年代提出的技术。它的基本操作可以分为三个:1) 本地计算阶段, 每个处理器只对存储本地内存中的数据进行本地计算。2) 全局通信阶段, 对任何非本地数据进行操作,包括核间数据的交换。3) 栅栏同步阶段, 等待所有通信行为的结束。可以看出,这实际上和上一节介绍的 “运算和通信的串行执行”是一致的,也和IPU的多核local memory架构很一致。
6. 工具
Graphcore提供的工具叫Porlar,题图的图像就是这个工具生成的。
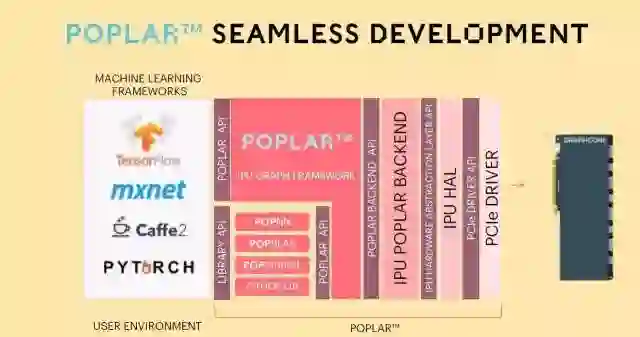
对于工具也不想多说了,一般大家承诺都不错,都是参照CUDA的配置,但实际效果。。。也只能试用了再评判。不过Graphcore目前只有50名员工,工具能否成熟还是有疑问的。
总结:
总的来说,从目前公布的信息来看,Graphcore的IPU在架构设计上还是有很多想法的, 非常值得讨论。不过,感觉上IPU这种同构多核架构在Cloud端应用应该更合适一些。虽然他们认为IPU的架构有很好的伸缩性,放到Edge 和Embedded应用也没问题,但我个人感觉是,这种架构顶多支持到自动驾驶,对于功耗成本要求更严苛的需求,还是更专用的架构(异构架构)更合适一些。
(本文来自公众号StarryHeavensAbove,新智元获授权转载,特此感谢!)
【号外】新智元正在进行新一轮招聘,飞往智能宇宙的最美飞船,还有N个座位
点击阅读原文可查看职位详情,期待你的加入~




