GAN用于无监督表征学习,效果依然惊人……
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:Jeff Donahue、Karen Simonyan
本文转载自:机器之心(机器之心编辑部)
无所不能的 GAN 又攻占了一个山头。
近年来,GAN 在图像合成领域取得了惊人的成果,例如先前 DeepMind 提出的 BigGAN。近日,DeepMind 提出全新的 BigBiGAN,引起了社区极大的关注。
该论文提出的方法建立在 SOTA 模型 BigGAN 之上,通过对其表征学习和生成能力进行广泛评估,证明这些基于生成的模型在 ImageNet 数据集的无监督表征学习和无条件图像生成方面均实现了 SOTA 效果。
机器学习社区众多研究者认为这是一篇极为有趣的工作,如 GAN 之父 Ian Goodfellow 在 Twitter 上表示,在他们写最初的 GAN那篇论文时,合作者也在做类似于 BigGAN 的表征学习研究。5 年后终见这样的成果。
论文:Large Scale Adversarial Representation Learning
论文地址:https://arxiv.org/abs/1907.02544
用 GAN 来做表征学习真的能行?
其实在 GAN 的早期,它也是能用于无监督表征学习的,只不过后来自编码器等自监督学习有了更好的效果。在这篇论文中,研究者表示图像生成质量的提升能大幅度提升表征学习的性能。并且相比自编码器等关注「底层细节」的模型,GAN 通过判别器能捕捉语义层面的差异,从而显著提升效果。
研究者所采用的的 BigBiGAN 方法是在 SOTA 模型 BigGAN 上建立的,并通过添加编码器和修改判别器将该方法扩展到表征学习领域。作者展示了一系列图像重构效果,这些图像都不是像素级的完美重建,因为模型甚至都不会有目标函数强制拉近像素间的距离。
但是用 BigBiGAN 做表征学习,用来重建图像有个优势:它能直观地理解编码器所学到的特征。例如当输入图像有「狗」或「人」等目标时,重建图像通常都会包含该类别的目标,且它们的姿势状态也差不多。下面我们可以看看 BigBiGAN 的重建效果,体会用来做无监督表征学习的优势。



真实图片(第一行)和针对真实图片重建的图片(第二行)。

随机挑选的生成图片。
GAN 为什么能做表征学习
GAN 框架中的生成器是一个从随机采样的潜变量(也叫「噪声」)到生成数据之间的前馈映射,学习信号由一个判别器提供,该判别器被训练用于区分真实和生成的数据样本。
很多 GAN 的扩展都在增强编码器的能力,并且有些研究发现 BiGAN 的行为类似与自编码器,它会最大化降低图像重构成本。然而重构误差是由参数化的判别器决定的,而不是简单的像素级度量,这就要比自编码器好得多。因为判别器通常都是强大的神经网络,因此我们可以期待它引入的误差度量是「语义」层面的差异。
这对于表征学习非常重要,因为我们希望隐藏表征能学习到最具语义信息的特征,而不仅仅是底层细节上的特征。鉴于这一点,用 GAN 来进行表征学习就非常合理与了。
尽管对于下游任务来说,基于 BiGAN 或 ALI 框架学习的编码器在 ImageNet 上是一种有效的可视化表征学习方法。然而,这些模型用到了一个 DCGAN 风格的生成器,生成器无法在该数据集上生成高质量的图像,因此编码器所能建模的语义非常有限。在本文中,研究者利用 BigGAN 作为生成器重新探究了这一方法。BigGAN 似乎能够捕捉 ImageNet 图像中的诸多模式和结构。研究者表明,在 ImageNet 上,BigBiGAN(BiGAN+BigGAN 生成器)的无监督表征学习能力能够达到当前最佳性能。
BigBiGAN 模型
BiGAN 或 ALI 方法都是 GAN 的变体,用于学习一个编码器,用于推断模型或作为图像的表征。
虽然 BigBiGAN 的核心与 BiGAN 的方法相同,但研究者采用了来自 SOTA BigGAN 的生成器和判别器架构。除此之外,研究者发现,改进的判别器结构可以在不影响生成效果的前提下带来更好的表征学习结果(见图 1)。也就是说,除了 BiGAN 或 ALI 中提出的联合判别器(该判别器将数据和潜在判别器连接到一起),研究者还在学习目标中提出了额外的一元项(unary term)。
尽管 BiGAN 或 ALI 的相关研究证明,原始的 BiGAN 目标已经强制要求所学习的联合分布匹配到全局最优,但这些一元项通过显式地强制执行此属性,直观地指导优化朝着「正确的方向」进行。例如,在图像生成任务中,一元损失项匹配原始的 GAN 目标,并提供了一个学习信号,该信号仅引导生成器与潜在输入无关的图像分布进行匹配。

图 1:BigBiGAN 框架的结构。
实验
研究者在未标注的 ImageNet 数据集上训练 BigBiGAN,冻结学到的表征,然后在输出中训练线性分类器,使用所有的训练集标签进行全监督。他们还衡量了图像生成性能,并以初始分数(IS)和 Fréchet 初始距离(FID)作为标准度量。
训练和数据集
研究者使用了和 BigGAN 相同的优化器——Adam,批大小为 2048,学习率和其他超参数也和 BigGAN 相同。在训练时,研究者对输入图像使用了 ResNet 风格的数据增强方法,但裁剪大小为 128 或 256,而非 224。
在表 1 的实验中,研究者随机采样了 10K 来自官方 ImageNet 训练集的图片,作为验证集,并报告准确率。这一数据集被称为「train_val」。表 1 实验运行了 500K 步,并基于 train_val 数据集上线性分类器的准确率进行 early-stop。
在表 2 中,研究者将 BigBiGAN 的训练次数提升到 1M 步,并报告验证集在 50K 张图像上的准确率。分类器训练了 100K 步,使用 Adam 优化器,学习率分别为 {10^−4, 3 · 10^−4, 10^−3, 3 · 10^−3, 10^−2}。
实验结果
研究人员将模型的最佳效果和最近的无监督学习结果进行了对比。
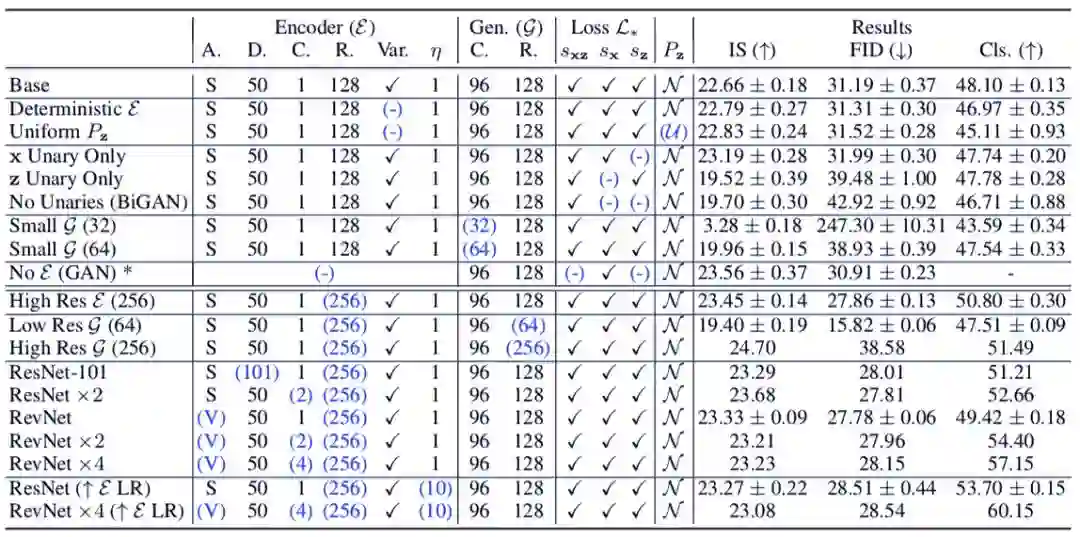
表 1:BigBiGAN 变体的性能结果,其中生成图像的初始分数(IS)和 Fréchet 初始距离(FID)、监督式 logistic 回归分类器 ImageNet top-1 准确率百分比(CIs)由编码器特征训练,并根据从训练集中随机采样的 10K 图像进行分割计算,研究者称之为「train-val」分割。
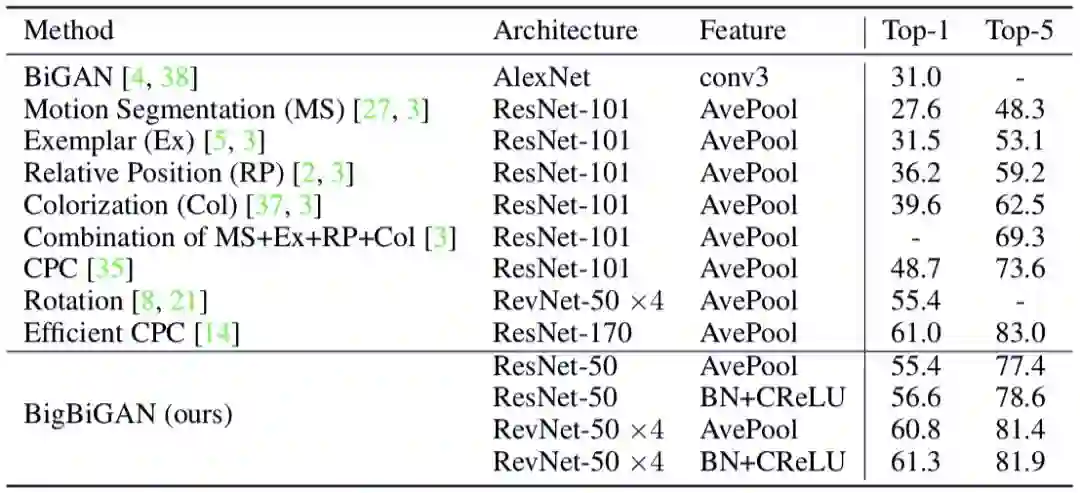
表 2:BigBiGAN 模型在官方验证集上与最近使用监督式 logistic 回归分类器的同类方法进行比较。

表 3:BigBiGAN 用于无监督(无条件的)生成 vs [24] 中的无监督 BigGAN 之前得出的结果。
CVer-GAN交流群
扫码添加CVer助手,可申请加入CVer-GAN交流群。一定要备注:研究方向+地点+学校/公司+昵称(如GAN+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!



