博客 | ACM MM最佳论文全文:通过多对抗训练,从图像生成诗歌


雷锋网 AI 科技评论按:多媒体信息处理领域顶级学术会议 ACM MM 2018(ACM International Conference on Multimedia)于 2018 年 10 月 22 日至 26 日在韩国首尔举行。
本次会议共收到 757 篇论文投稿,接收论文 209 篇,接收率为 27.61%;其中口头报告论文 64 篇,比例为 8.45%。投稿最多的领域是「理解-多媒体与视觉」、「理解-深度学习多媒体处理」、「理解-多模态分析与描述」、「互动-多媒体搜索与推荐」,投稿数量分别为 210 篇、167 篇、86 篇、79 篇。
获奖论文名单
10 月 24 日下午,大会现场公布了最佳论文获奖名单,雷锋网 AI 科技评论摘录如下
最佳论文一篇
Beyond Narrative Description: Generating Poetry from Images by Multi-Adversarial Training
超越叙事描述:通过多对抗训练,从图像生成诗歌
论文地址:https://dl.acm.org/authorize?N660819
论文中文全文见下文
最佳学生论文一篇
Understanding Humans in Crowded Scenes: Deep Nested Adversarial Learning and A New Benchmark for Multi-Human Parsing
理解密集场景中的人:深度内嵌对抗学习以及一个新的多人解析 benchmark
论文地址:https://dl.acm.org/authorize?N660810
最佳 Demo 论文两篇
AniDance: Real-Time Dance Motion Synthesize to Song
AniDance:从舞蹈动作实时生成音乐
论文地址:https://dl.acm.org/authorize?N660964
Meet AR-bot: Meeting Anywhere, Anytime with Movable Spatial AR Robot
来见见 AR-bot:与可以在不同空间移动的 AR 机器人见面,随时随地
论文地址:https://dl.acm.org/authorize?N660976
最佳开源软件比赛论文两篇
Vivid: Virtual Environment for Visual Deep Learning
Vivid:用于视觉深度学习的虚拟环境
论文地址:https://dl.acm.org/authorize?N660990
A General-Purpose Distributed Programming System using Data-Parallel Streams
一个使用数据并行流的通用分布式变成系统
论文地址:https://dl.acm.org/authorize?N660991
ACM TOMM 期刊最佳论文一篇
Learning from Collective Intelligence: Feature Learning using Social Image and Tags
从集体智慧学习:用社交图像和标签学习特征
论文地址:https://dl.acm.org/citation.cfm?id=2978656
最佳论文全文阅读
ACM MM 2018 最佳论文《Beyond Narrative Description: Generating Poetry from Images by Multi-Adversarial Training》(超越叙事描述:通过多对抗训练,从图像生成诗歌 )由京都大学和微软亚洲研究院合作完成。以下为微软亚洲研究院提供的论文中文版全文。
摘要
根据图像自动生成自然语言的技术引起了广泛关注。本文中,我们更进一步,研究如何从图像生成诗歌语言,进行自动的诗歌创作。这一工作涉及多项挑战,包括发现图像中的诗歌线索(例如,绿色中蕴含的希望),以及生成诗歌——既满足与图像的相关性,又满足语言层面上的诗意。为解决上述问题,我们通过策略梯度将诗歌生成工作划分成了两个相关的多对抗训练子任务,从而保证跨模态相关性和诗歌语言风格。为了从图像中提炼诗歌线索,我们提出学习深度耦合的视觉诗意嵌入,在其中,机器可以连带地学习图像中物品、情感 和场景的诗意呈现。本文还介绍了两种指导诗歌生成的判别网络,包括多模态判别器和诗歌风格判别器。为了便于研究,我们通过人工注解者收集了两个诗歌数据集,它们有如下性质:1) 第一个是人类注解的“图像-诗歌”对数据集(共8,292对),以及2)迄今为止最大的公共英文诗歌语料数据集(共有92,265首不同的诗歌)。我们应用自己的模型生成了八千张图像,进行了大规模的实验,其中一千五百张图像是随机选取来进行评估的。客观评估和主观评估均显示,该方法相对于目前最先进的图像生成诗歌方法,表现优异。我们请500名人类受试者来进行了图灵测试,其中30名评估者是诗歌方面的专业人士,测试结果证明了我们方法的有效性。
1 引言
近来,同时涉及视觉和语言的研究引起了广泛关注,关于图像描述(像图像标题技术和图像生成短文)的研究数量呈现出爆发式的增长。[1, 4, 16, 27]。图像描述的研究旨在根据图像生成使用人类语言描述事实的语句。在本文中,我们更进一步,希望完成更具认知性的工作:以诗歌创作为目的,根据图像生成诗歌语言。该工作已引起了研究界和行业的巨大兴趣。

图 1:示例-人类对相同图像写出的描述和诗歌。我们可以看到,这两种形式中相同颜色的用词有着明显差异。相对于描述图像中的事实,诗歌更倾向于捕捉图像中物体、场景和感情更深层次的含义和诗歌象征(例如,骑士与猎鹰, 猎和发与进食,以及待与站)。
在自然语言处理领域,诗歌生成问题已经得到研究。例如,在[11, 32]中,作者主要关注风格和韵律的质量。在[7, 32, 37]中,这些工作更多地研究根据主题生成诗歌。在行业内,Facebook提出了使用神经网络来生成英文韵律诗 [11],微软开发了一个叫作“小冰”的系统,其最重要的功能之一正是生成诗歌。不过,以端对端的方式从图像生成诗歌仍然是一个新的主题,面临着巨大挑战。
图像标题技术和图像生成短文的重点在于生成关于图像的描述性语句,而诗歌语言的生成则是更具挑战性的难题。视觉呈现与图像可激发的、有助于更好地生成诗歌的诗歌象征之间,距离更远。例如,图像描述中的“人”在诗歌创作中可以进一步使用“明亮的阳光”和“张开的手臂”象征“希望”,或使用“空椅子”和“黑暗”的背景象征“孤独”。图1举出了一个具体的例子,说明同一张图像,其描述和其诗歌之间的差异。
为了从一幅图像生成诗歌,我们尤其需要面临以下三个挑战:首先,与根据主题生成诗歌相比,这是一个跨模态的问题。从图像生成诗歌的一种直观方法是先从图像中提炼关键词或说明文字,然后以这些关键词或说明文字为种子,生成诗歌,正如从主题生成诗歌那样。但是,关键词或说明文字会丢失许多图像信息,更不用说对诗歌生成十分重要的诗歌线索了[7, 37]。其次,与图像标题技术和图像生成短文相比,从图像生成诗歌是一项更主观的工作,这意味着同一幅图像可以对应不同方面的多首诗歌,而图像标题技术/图像生成短文更多地是描述图像中的事实,并生成相似的语句。第三,诗句的形式和风格与叙述语句不同。本研究中,我们主要关注的是一种开放形式的诗歌——自由诗。尽管我们不要求格律、韵律或其他传统的诗歌技术,但仍要有诗歌结构和诗歌语言。在本研究中,我们将这一素质定义为诗意。例如,诗歌的长度一般有限;与图像描述相比,诗歌一般偏好特定的词语;诗歌中的语句应与同一主题相关,保持一致。
为了应对以上挑战,我们收集了两个人类注解的诗歌数据集,在一个系统中通过集成检索和生成技术来研究诗歌创作。为了更好地研究诗歌生成中图像的诗歌线索,我们首先研究了使用图像CNN特点的深度耦合视觉诗意嵌入模型,以及包含数千对图像-诗歌的多模态诗歌数据集(即“多模态诗集”)中的 skip-thought向量特点[15]。然后我们使用这一嵌入模型,从一个更大的图像单模态诗歌语料库(即,“单模态诗集”)中检索相关的和不同的诗歌。这些被检索的诗歌的图片,与多模态诗集一同,构成一个扩大的图像-诗歌对数据集(即“多模态诗集(EX)”)。我们还提出使用最新的序列学习技术,训练关于多模态诗集(EX)数据集的端对端诗歌生成模型。该架构保证我们能够从扩展的图像-诗歌对中发现并塑造大量的诗歌线索,这对诗歌生成而言至关重要。
为避免长序列(所有诗行一起)导致的曝光偏差问题以及无可用的特定损失函数来定量评测生成诗歌的问题,我们提出使用多对抗训练的诗歌生成递归神经网络(RNN),并通过策略梯度对其进行进一步优化。我们使用两个判别网络来对生成诗歌与给定图像的相关性以及生成诗歌的诗意提供奖励。我们对多模态诗集、单模态诗集以及多模态诗集(EX)进行实验,根据图像生成诗歌,然后以自动和人工的方式对生成的诗歌进行评价。我们定义了与相关性、新颖性和解读一致性相关的自动评价标准,并对相关性、连贯性和想象力进行了用户研究,来将生成的诗歌与通过基线方法生成的诗歌进行比较。本研究的成果如下:
我们提出以自动方式从图像生成诗歌(英文自由诗)。就我们所知,这是首个尝试在整体框架中研究图像生成英文自由诗歌问题的努力,它使机器在认知工作中能够具备接近人类的能力。
我们将深度耦合的视觉诗意嵌入模型与基于RNN的联合学习生成器结合,其中两个判别器通过多对抗训练,为跨模态相关性和诗意提供奖励。
我们收集了首个人类注解的图像-诗歌对数据集,以及最大的公共诗歌语料数据集。通过应用自动和人工评价标准(包括对500多位人类受试者进行的图灵测试),大量实验证明,相对于几个基线方法,我们的方法更为有效。为了更好地促进图像生成诗歌的研究,我们将在不远的将来公布这些数据集。
2 相关工作
2.1 诗歌生成
传统的诗歌生成方法包括基于模板和语法的方法[19, 20, 21]、约束优化下的生成归纳[32]以及统计机器翻译模型 [10, 12]。近年来,通过应用深度学习,关于诗歌生成技术的研究已进入一个新阶段。递归神经网络被广泛用于生成诗歌(读者难以分辨这些诗歌是机器生成的,还是诗人创作的) [7, 8, 11, 33, 37]。之前的诗歌生成工作主要关注诗歌的风格和韵律质量[11, 32],而近期的研究引入主题,作为诗歌生成的条件[7, 8, 32, 37]。对一首诗歌而言,主题仍然是没有具体场景的抽象概念。许多诗歌都是诗人处于特定场景并观看某些具体景色时创作出来的,受到这一事实的启发,我们更近一步,尝试解决视觉场景激发的诗歌生成问题。与之前的研究相比,我们的工作面临着更多挑战,特别是在考虑多模态问题方面。
2.2 图像描述
图像标题技术一开始被视为为一幅给定图像从数据集中搜索文字说明的检索问题[5, 13],因此不能为所有图像提供准确、适当的描述。为了解决这一问题,有人提出使用模板填充[17] 和卷积神经网络(CNN)与递归神经网络(RNN)范式[2, 27, 34]来生成可读性达到人类水平的语句。近来,生成对抗网络(GAN) 被用于根据不同的问题背景来生成说明文字[1, 35]。与图像标题技术相似,图像生成短文有着类似的发展。近期关于图像生成短文的研究主要关注的是生成语句的区域检测和层次结构[16, 18, 23]。但是,正如我们所说的那样,图像标题技术和图像生成短文旨在生成陈述图像事实的描述性语句,而诗歌生成处理的则是一种需要诗意和语言风格约束的高级语言形式。
3 方法
在本研究中,我们的目的是根据图像生成诗歌,让生成的诗歌与输入的图像相关,并满足诗意方面的要求。为此,我们将问题转化为一个多对抗训练学习的过程[9],并使用策略梯度对之进行进一步优化[30, 36]。CNN-RNN生成模型被用作智能体。该智能体的参数制定了一种政策,这种政策的执行将决定挑选哪些词语作为动作。当智能体挑选出一首诗歌中的所有词语时,它提供奖励。我们定义了两种判别网络,来判断生成的诗歌是否与输入图片相匹配,以及生成的诗歌是否具有诗意,并就此提供奖励。我们诗歌生成模型的目标是为一幅图像生成一首诗歌的连串词语,从而将预期的最终奖励最大化。对于许多没有不可微标准的任务而言,这种策略梯度已被证明极为有效[1, 24, 35]。
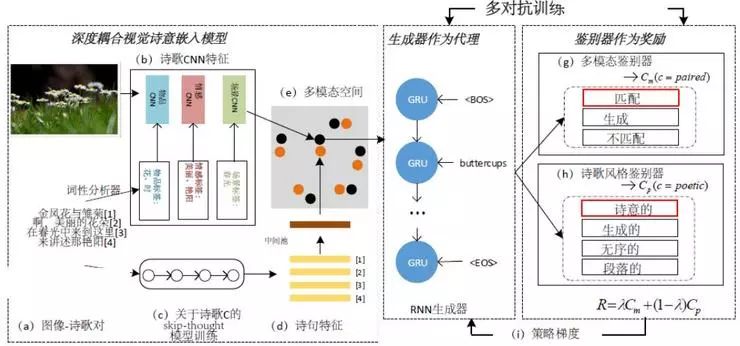
图 2:使用多对抗训练进行诗歌生成的架构。我们首先使用人类注解配对的图像-诗歌数据集(多模态诗集)中的图像-诗歌对(a)来训练深度耦合的视觉诗意嵌入模型(e)。词性分析器(斯坦福大学 NLP 工具)从诗歌中提取诗歌象征(例如物品、场景和情感),图像特征(b)即为使用提取的这些象征对 CNN 进行微调后取得的诗歌多 CNN 特征。诗歌的语句特征(d)是从受到最大公共诗歌语料库(单模态诗集)训练的 skip- thought 模型(c)中提取得到的。基于 RNN 的语句生成器(f)作为智能体得到训练,两种判别器(评判根据给定图像生成的诗歌的多模态(g)和诗歌风格(h))为策略梯度(i)提供奖励。词性分析器从诗歌中提取词性词语。
如图 2, 所示,架构包含几个部分:(1) 用来学习图像诗意呈现的深度耦合的视觉诗意嵌入模型(e) ,以及(2) 策略梯度优化的多对抗训练。两种判别网络(g和h)以RNN为基础,作为智能体,为策略梯度提供奖励。
3.1 深度耦合的视觉诗意嵌入
视觉诗意嵌入模型的目标[6, 14]是学习嵌入空间,在该空间中不同模态的点(例如图像和语句)可以得到映射。我们使用与图像标题技术问题相似的方法,假设一对图像和诗歌共享相同的诗歌语义,使嵌入空间是可习得的。通过将图像和诗歌嵌入相同的特征空间,我们能够使用一首诗和一幅图像呈现的诗歌向量来直接计算它们之间的相关性。此外,我们能进一步利用嵌入特征,将诗歌生成中诗歌线索的优化呈现初始化。
我们深度耦合的视觉诗意嵌入模型的架构如图2左边部分所示。对于图像输入,在进行图像生成诗歌重要因素的用户研究后,我们使用了深层卷积神经网络(CNN)——该网络与象征图像中重要诗歌线索的三个方面(即,物品(v1)、场景 (v2)和情感(v3)有关。我们观察到,诗歌中的概念通常是想象的和诗意的,而我们用来训练CNN模型的分类数据集中的概念是具体的和普通的。为了缩小图像视觉表达和诗歌文本表达之间的语义分歧,我们提出使用多模态诗歌数据集来微调这三种网络。我们挑选诗歌中与物品、情感和场景相关的常用关键词作为标签词汇,然后以多模态诗歌数据集为依据,为物品、情感和场景的检测分别建立了三个多标签数据集。多标签数据集建成后,我们分别在三个数据集中对预先训练的CNN模型进行了微调,通过等式(1)中所示的S形交叉熵损失进行了优化。然后,我们为CNN模型的倒数第二个完全连通层的各方面采用了D维深层特征,并获得了串联的N维(N = D × 3)特征向量v(v ∈ RN)来作为每幅图像视觉诗意嵌入的输入:
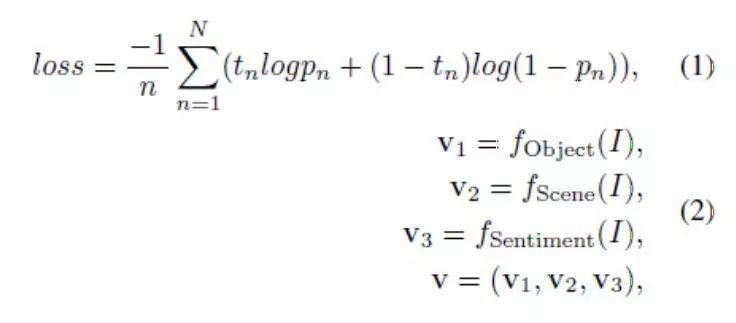
其中,我们将全连接层输出用作v1、v2、v3的特征。视觉诗意嵌入的输出向量x是K维向量,代表图像特征线性映射的图像嵌入:
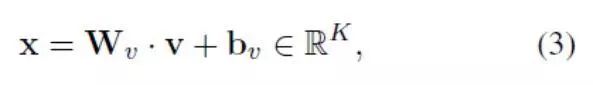
其中Wv∈RKxN是图像嵌入矩阵,而bv∈RK是图像偏差向量。同时,根据诗歌语句的skip-thought平均值计算出诗歌的表达特征向量[15]。我们使用有M维向量(被记为t∈RM)的Combine-skip,因为如[15]中所示,它显示出更好的表现。skip-thought模型在单模态诗歌数据集得到训练。与图像嵌入类似,诗歌嵌入被表示为:
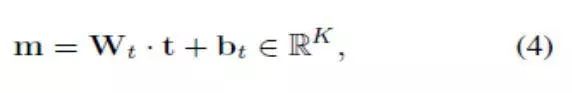
其中Wt∈RKxM表示诗歌嵌入矩阵,而bt∈RK 表示诗歌偏差向量。最后,使用点积相似性最大限度地减少每对的排序损失,从而将图像和诗歌一起嵌入:
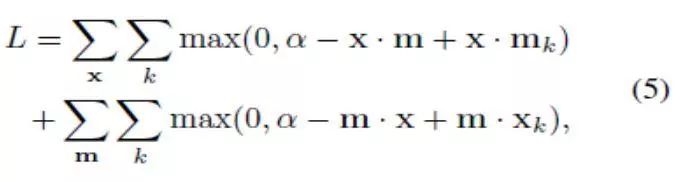
其中mk是用于图像嵌入x的比较研究(不相关,不成对)诗歌,而xk相反。α代表对比边际。因此,我们训练的模型在原始图像-诗歌对的嵌入特征之间会产生比随机生成对更高的余弦相似性(与点积相似定一致)。
3.2 诗歌生成器作为智能体
图像标题技术的传统CNN-RNN模型在我们的方法中被用作智能体。我们没有使用近期在图像生成短文中被用于生成多条语句的层次方法[16],而是通过将句尾标记作为词汇中的一个词语来处理,使用了非分层递归模型。原因在于,相比段落,诗歌包含的词语数量通常更少。此外,训练诗歌中语句之间的层次一致性更低,这使得句子间的层次更难学习。我们还将层次递归语言模型用作基线来进行了实验,我们会在实验部分展示其结果。
生成的模型包括图像编码器CNNs和诗歌解码器RNN。在本研究中,我们使用门控循环单元[3]作为解码器。我们使用通过第3.1 节中所示深度耦合的视觉诗意嵌入模型习得的图像嵌入特征,作为图像输入编码器。假设θ是模型的参数。传统上,我们的目标是通过将观察语句y = y1:T∈Y*的相似性最大化,来学习θ(其中T是生成语句的最大长度(包括代表语句开始的< BOS >和代表语句结束的< EOS > ),而Y* 代表所选词语的所有序列空间)。
令r(y1:t)代表时间t时取得的奖励,而R(y1:T)是累计奖励,即R(yk:T) =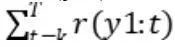
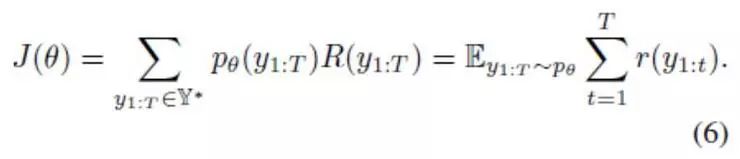
我们通过遵循其梯度,来将J(θ)最大化:
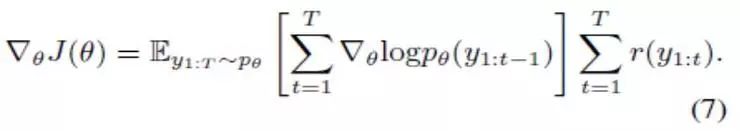
在实践中,期望梯度可以近似为使用一个蒙特卡洛样本,使用方法如下:按顺序从模型分布pθ(yt| y1:(t-1)中对每个yt进行取样,其中t等于1到 T。如 [24]中所述,可引入基线b来降低梯度估计的方差,而不改变预期的梯度。因此,单一取样的预期梯度近似等于:
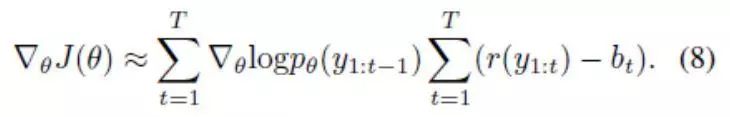
3.3 判别器作为奖励
一首好的图像诗歌必须至少满足两个标准:诗歌(1)与图像相关,且(2)在合适长度、诗歌语言风格和诗句一致性方面具有诗意感。根据这两个要求,我们提出了两个判别网络来指导诗歌的生成:多模态判别器和诗歌风格判别器。深层判别网络在文本分类任务中已经被证明具备很高的有效性[1, 35],特别是对不能建立良好损失函数的任务。在本文中,我们提出的两个判别器都有多个类别,包括一个正面类和多个负面类。
多模态判别器:为了检查生成的诗歌y是否与输入图像x相匹配,我们训练多模态判别器(Dm),来将 (x, y)分类成匹配、不匹配和已生成三个类别。Dm 包括一个多模态编码器、模态融合层以及一个有softmax函数的分类器:
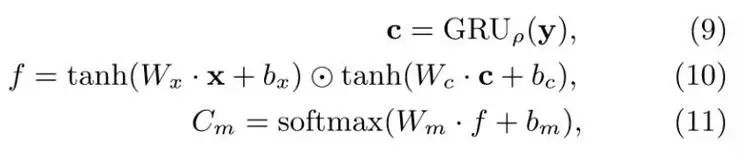
其中Wx、bx、Wc、bc、Wm、bm 是要学习的参数,⊙是元素级相乘,而Cm 代表多模态判别器的三种类型的概率。我们利用基于GRU的语句编码器来进行判别器训练。方程11提供了生成(x, y分类到每个种类,使用Cm(c|x, y)来表示)的概率的方法,其中c ∈{匹配,不匹配,已生成}。
诗歌风格判别器。与强调格律、韵律和其他传统诗歌技术的大部分诗歌生成研究不同,我们关注的是一种开放形式的诗歌——自由诗。但是,如第1节所述,我们要求我们生成的诗歌具备诗意特点。我们没有为诗歌指定具体的模板或规则,而是提出了诗歌风格判别器(Dp),将生成的诗歌朝人类创作的诗歌方向进行引导。在Dp中,生成的诗歌会被分为四类:诗意的、无序的、段落的和生成的。
诗意类是满足诗意标准的正面例子。其他三类都被视为反面示例。无序类是关于诗句之间的内部结构和连贯性,而段落类则是使用了段落句子,而被当成反面示例。在Dp中,我们将单模态诗集当做正面的诗意示例。为构建无序类别的诗歌,我们首先通过分割单模态诗集中的所有诗歌,建立了一个诗句池。我们从诗句池中随机挑选合理行数的诗句,重新构成诗歌,作为无序类的示例。[16]提供的段落数据集被用作段落示例。
完整的生成诗歌y被GRU编码,并解析到完全连通层,然后使用softmax函数计算被归到四种类别的概率。此过程的公式如下:
Cp = softmax(Wp • GRUη(y) + bp), (12)
其中η、Wp、bp是要学习的参数。生成的诗歌被归类到类别c的概率可以用Cp(c|y)计算,其中c∈{诗意的、无序的、段落的、生成的}。
奖励函数。我们将策略梯度的奖励函数定义为生成的诗歌y(根据输入图像x生成)被分类到正面类别(多模态判别器Dm的匹配类以及诗歌风格判别器Dp的诗意类)的概率的线性组合,然后经过加权参数λ加权:
R(y|•) = λCm(c = paired|x, y) + (1 - λ)Cp(c = poetic|y). (13)
3.4 多对抗训练
在对抗训练以前,我们使用图像标题生成技术[27]对生成器进行了预先训练,为生成器提供了一个更好的策略初始化。生成器和判别器以对抗方式进行迭代更新。生成器的目的是生成符合标准的诗歌,让两个判别器都获得更高的奖励,这样,在它们欺骗判别器时,判别器能够得到训练,学习如何分辨生成的诗歌和匹配的诗歌、诗意的诗歌。如上所述,生成的诗歌在两个判别器中被归为正面类别的概率被用作对策略梯度的奖励。
我们使用来自真实数据的正面示例(Dm中的匹配类诗歌以及Dp中的诗意类诗歌),以及来自生成器生成诗歌和其他真实数据的负面示例(Dm中的不匹配类诗歌以及Dp中的段落类诗歌和无序类诗歌)来训练多个判别器(本文中是两个)。同时,通过使用策略梯度和蒙特卡洛取样,生成器根据多种判别器提供的期望奖励进行了更新。由于我们有两个判别器,我们使用了多对抗训练,来同时训练两个判别器。


表 1:三个数据集的详细信息。前两个数据集由我们自己收集,第三个通过 VPE 扩展而得。
4 实验
4.1 数据集
为了促进根据图像生成诗歌的研究,我们收集了两个诗歌数据集,其中一个包含图像和诗歌对,即多模态诗歌数据集(多模态诗集),另一个是大型的诗歌语料库,即单模态诗歌数据集(单模态诗集)。我们使用自己训练过的嵌入模型,通过添加来自无冗余诗歌语料库中的三首邻近诗歌,扩展了图像和诗歌对,
表1:三个数据集的详细信息。前两个数据集由我们自己收集,第三个通过VPE扩展而得。并构建了一个扩展的图像-诗歌对数据集,称为多模态诗集(EX)。这些数据集的详细信息如表1所示。收集的两个数据集的示例可参见图 3。为了更好地促进图像生成诗歌的研究,我们将在不远的将来公布这些数据集。
对于多模态诗歌数据集,我们首先在Flickr上爬取了几个小组(这些小组尝试为人类写作的诗歌配上插图)的34,847对图像-诗歌对。然后我们请五位英语文学专业的人类评估员来评估这些诗歌是否与图像相关,评判的标准是:通过综合考虑物品、感情和场景,来判断图像是否能够准确地激发同组的诗歌。我们过滤掉被标示不相关的图像-诗歌对,保留了剩下的8,292对,构成多模态诗集数据集。
单模态诗集是从几个公开的在线诗歌网站上爬取的,比如Poetry Foundation、 PoetrySoup、 best-poem.net以及poets.org等。为实现充分的模型训练,我们对诗歌进行了预处理,过滤掉行数过多(大于10行)或过少(小于3行)的诗歌。我们还去掉了包含陌生文字、英语以外语言的诗歌以及重复的诗歌。
4.2 比较方法
为了研究拟议方法的有效性,我们使用不同的设置与四种基线方法进行了比较。我们选择了展示-辨别模型 [27]和SeqGAN [35],因为它们是图像标题技术的最新研究成果。我们选择了比较性图像生成短文模型,因为它在模仿多种图像内容方面有很强的能力。请注意,所有的方法均使用多模态诗集(EX)作为训练数据集,并能够生成多行的诗歌。具体的方法和实验设置如下所示:
展示-辨别(1CNN):仅使用物品CNN,通过VGG-16对CNN-RNN模型进行了训练。
展示-辨别(3CNNs):使用三个CNN特征,通过VGG-16对CNN-RNN模型进行了训练。
SeqGAN:使用一个判别器(用来分辨生成的诗歌和真人创作的诗歌的判别器)对CNN-RNN模型进行了优化。
区域层次:以[16]为依据的层次段落生成模型。为了更好地与诗歌分布保持一致,我们在实验中将最大行数限制在10行,每行最大词数限制在10个。
我们的模型:为了证明两个判别器的有效性,我们在四个背景中训练我们的模型(使用GAN、I2P-GAN的图像到诗歌):无判别器的预训练模型(I2P-GAN w/o判别器)、只有多模态判别器的训练模型(I2P-GAN w/ Dm)、有诗歌风格判别器的训练模型(I2P-GAN w/ Dp)以及有两个判别器的训练模型(I2P-GAN)。
4.3 自动评估标准
诗歌的评估通常是一项困难的任务,在现有的研究中没有既定的评价标准,对于根据图像生成诗歌这一新任务而言就更是如此了。为了更好地评价诗歌的质量,我们提出同时使用自动和人工的方式来进行评价。
对于自动评价,我们建议采用三种评价标准,例如,BLEU、新颖性和相关性。然后在标准化后根据三种标准计算总分。
BLEU。我们首先使用双语互译质量评估辅助工具(BLEU)[22]基于分数的评价来检查生成的诗歌与真实诗歌有多近似,正如图像标题技术和图像生成短文研究通常所做的那样。它还被用于一些其他的诗歌生成研究中[32]。对于每张图片,我们仅使用人类创作的诗歌作为真实诗歌。
新颖性。通过引入判别器Dp,生成器应从单模态诗歌数据集中引入单词或短语,并生成多模态诗集(EX)中不常出现的单词或短语。我们使用[31] 提出的新颖性来计算生成诗歌中观察到的低频词语或短语。我们研究新颖性-2和新颖性-3这两种N-gram尺度(例如,二元模子和三元模子)。我们首先对多模态诗集(EX)训练数据集中出现的n-gram进行排序,将前2,000作为高频。新颖性根据训练数据集中出现的n-grams比例进行计算(生成的诗歌中的高频n-grams除外)。
相关性。不同于那些对诗歌内容无约束或约束较弱的诗歌生成研究,在本研究中我们将生成诗歌与给定图像之间的相关性视为一个重要标准。生成说明文字更关注对图像的事实描述,与此不同的是,不同的诗歌可以在各种方面与同一幅图像相关。因此,我们没有计算生成诗歌与真实诗歌之间的相关性,我们使用我们经过学习的深度耦合的视觉诗意嵌入模型来确定诗歌和图像之间的相关性。通过我们的嵌入模型将图像和诗歌映射到相同空间后,我们使用余弦相似性来测量它们的相关性。尽管我们的嵌入模型能够大概地量化图像和诗歌之间的相关性,我们还是使用了主观评价来更好地研究我们生成人类水平诗歌的有效性。
总体。我们根据以上三个标准来计算总分。对于一个标准a的所有值中的每个值ai,我们首先使用以下方法将其归一化:
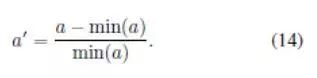
然后,我们得到BLEU(例如,BLEU- 1、BLEU-2和BLEU-3)和新颖性(例如,新颖性-2和新颖性-3)的平均值。我们通过对归一化值进行平均来计算最终得分,以确保不同标准的均等贡献。
但是,在这样一项开放性的任务中,没有特别适合的标准能够完美地评价生成的诗歌的质量。我们使用的自动标准在某种程度上可被视为指导。为更好地从人类感知角度来说明诗歌的质量,我们还进行了如下的扩展用户研究。
4.4 人类评价
我们在亚马逊土耳其机器人中进行了人类评价。我们以如下方式将三种任务分配给了AMT工人:
任务1:研究我们深度耦合的视觉诗意嵌入模型的有效性,注解者被要求根据一首诗歌与一幅给定图像之间在内容、情感和场景方面的相似性进行0-10分的打分。
任务2:本任务的目的是在各方面对根据一幅图像、使用不同方法(四种基线方法以及我们的四种模型设置)生成的诗歌进行比较。我们给定一幅图像,要求注解者根据四个标准对诗歌进行0-10分的评分:相关性(与图像)、连贯性(诗歌各行之间是否连贯)、想象力(诗歌对于给定的图像显示了多少想象力和创意)以及整体印象。
任务3:我们要求注解者在混杂人类创作和机器生成的诗歌中进行甄别,完成了图灵测试。请注意,图灵测试在两种设置条件下进行,即,有图像的诗歌和无图像的诗歌。
我们为每项任务随机挑选了1000幅图像,并分配给了三名评估员。由于诗歌是一种文学形式,我们还请了30位专业与英语文学相关的注解者(其中十位注解者是以英语为母语)作为专家用户,来进行图灵测试。
4.5 训练详情
在深度耦合的视觉诗意嵌入模型中,我们为每个CNN使用了D = 4,096-维度特征。我们从ImageNet[25]上经过训练的VGG-16[26] 提取物体特征,从Place205-VGGNet模型[29]提取场景特征,并从感情模型[28]提取感情特征。
为了更好地提取诗歌象征的视觉特征,我们首先取得了单模态诗歌数据集中至少达到五频次的名词、动词和形容词。然后,我们人工为感情(包括328个标签)挑选形容词和动词,为物品(包括604个标签)和场景(包括125个标签)挑选名词。至于诗歌特征,我们使用M = 2,048-维度(其中每个1,024维度分表代表单向和双向)为每句诗提取组合的skip-thought向量,并最终通过平均池化取得了诗歌特征。而边际α根据[14]中的实证实验被设为0.2。我们为一幅图片随机地挑选出127首诗歌作为不匹配诗歌,并将它们用作对比诗歌(等式 5中的mk与xk),并在每一期中对它们进行了重新取样。我们通过对结果为0.1到0.9的自动评价进行可比观察,根据实证将加权参数A设为A = 0.8。
4.6 评价


图 4:使用六种方法根据一幅图像生成诗歌的示例。
检索诗歌。我们根据三种诗歌与图片的相关性对它们进行了对比:真实诗歌、使用VPE检索,图像特征未微调的诗歌(VPE w/o FT),以及使用VPE检索,图形特征经过微调的诗歌(VPE w/ FT)。表2显示了这三种诗歌类型在0-10分范围内的对比(0分代表不相关,10分代表最相关)。我们可以看到,通过使用拟议的视觉诗意嵌入模型,检索诗歌的相关性评分能够达到平均分(即,5分)以上。而使用诗歌象征微调后的图像特征能够显著地提高相关性。

表 2:人类创作的三种类型诗歌与图像相关性的平均得分,评分范围 0-10 分(0 分-不 相关,10 分-相关)。单向方差分析显示,这些诗歌的评价具有统计学意义(F(2, 9) = 130.58,p < 1e - 10)。
生成的诗歌。表3展示有四种设置的拟议模型的自动评估结果,以及之前研究提出的四种基线的自动评估结果。比较有一个CNN和三个CNN的说明文字模型的结果,我们可以看出,多CNN确实有助于生成与图像相关性更高的诗歌。区域层次模型更强调诗句之间的主题连贯性,但许多人类创作的诗歌会覆盖多个主题,或为同一主题使用不同的象征。相比于只有CNN-RNN的说明文字模型,SeqGAN证明了应用对抗训练在诗歌生成方面的优点,但是它在诗歌中生成的新概念较少。我们使用VPE预训练的模型比说明文字模型表现更好,这说明VPE能够更有效地从图像中提取诗歌特征,从而更好地生成诗歌。可以看出,我们的三种模型在大部分标准下表现更好,每种在一个方面表现特别优异。仅有多模态判别器(I2P-GAN w/ Dm)的模型会引导模型生成真实的诗歌,因此它在BLEU上得分最高,强调了翻译方式上n-grams的相似性。诗歌风格判别器(Dp)的设计目的是引导生成的诗歌使用更具诗意的语言风格,I2P-GAN w/ Dm取得最高的新颖性得分证明,Dp有助于为生成的诗歌提供更新颖、更富想象力的措辞。总体上,I2P-GAN结合了两种判别器的优点,在BLEU和新颖性上取得了合理的中间分数,但与其他生成模型相比,仍然表现的更为出色。此外,我们使用两种判别器的模型生成的诗歌能够在我们嵌入相关性标准上取得最高的得分。
人类评价结果的对比如表4所示。在自动评价结果中,区域层次表现不佳,得分结果仅仅略微高于说明文字模型,但人工评价不同,这是因为所有诗句都与同一主题相关共容易获得用户的认可。我们的三种模型在所有标准中的表现都优于四种基线方法。与预训练的模型相比,两种判别器使诗歌具有更接近真人水平的内涵。使用两种判别器的模型生成的诗歌在相关性、连贯性和想象力方面质量更高。图4是使用三种基线方法和我们的方法,根据给定图片生成的诗歌的示例。通过我们的方法生成诗歌的更多示例可参见图5。




图 5:通过我们 I2P-GAN 方法生成诗歌的示例。
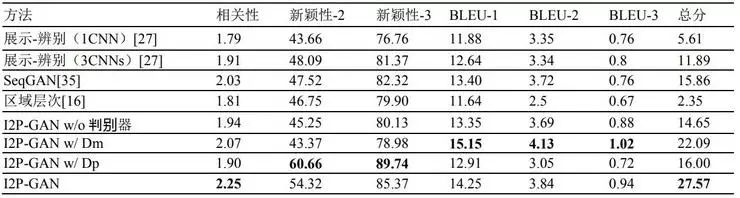
表 3:自动评价。请注意,BLEU 得分是比较人类注解的真实诗歌计算出的分数(一首 诗歌对应一幅图像)。总分是三种标准归一后的平均值计算得出的(等式 14)。所有得 分都是百分比(%)。
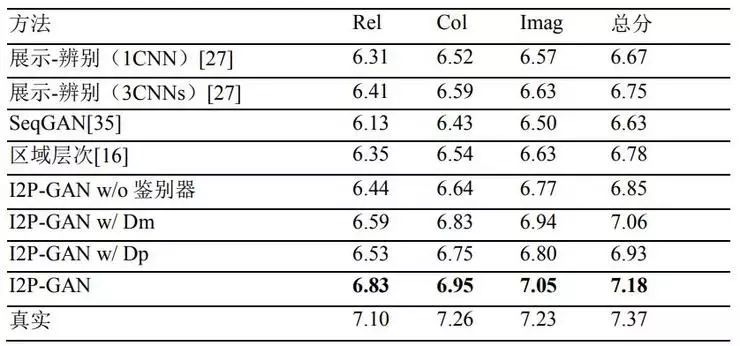
表 4:六种方法在四个标准下的人类评价结果:相关性(Rel)、连贯性(Col)、想象 力(Imag)和总分。所有标准的评分范围都是 0-10 分(0-差,10-优)。
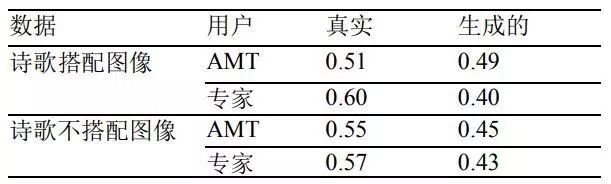
表 5:使用诗歌搭配图像/不搭配图像、对 ATM 用户和专家用户进行的图灵测试的准确性
图灵测试。对于AMT注解者的图灵测试,我们雇佣了548名工人,平均每名工人完成10.9项任务。对于专家用户的图灵测试,我们请15个人对带有图像的、人类创作的诗歌进行判断,请另外15名注解者对没有图像的诗歌进行测试。每个人被分配了20幅图像,我们请专家用户共完成600个任务。表5显示的是不同诗歌被判断成人类根据给定图像创作的诗歌的概率。正如我们所见,生成的诗歌无论是对普通注解者,还是对专家,都造成了混淆,尽管专家的判断比普通人更准确一些。一个有趣的观察结果是:专家在判断带图像的诗歌时准确率更高,而AMT工人则在判断无图像的诗歌时表现更好。
5 结论
作为从图像生成诗歌(英文自由诗)的首个研究,我们使用多判别器作为策略梯度的奖励,通过整合深度耦合的视觉诗意嵌入模型和基于RNN的对抗训练,提出了一种模拟问题的新方法。此外,我们引入了首个图像-诗歌对的数据集(多模态诗集)和大型诗歌语料库(单模态诗集)来促进关于诗歌生成的研究,特别是根据图像生成诗歌。大量的实验证明,我们的嵌入模型能够近似地学习一个合理的视觉创意嵌入空间。自动和人工评价结果证明了我们诗歌生成模型的有效性。
参考文献
[1] T.-H. Chen, Y.-H. Liao, C.-Y. Chuang, W.-T. Hsu, J. Fu, 及 M. Sun.展示、适应和辨别:跨域图像标题技术的对抗训练.ICCV, 2017.
[2] X. Chen与 C. Lawrence Zitnick.心灵之眼:图像标题技术的递归视觉表达.In CVPR,第 2422-2431页, 2015.
[3] J. Chung, C. Gulcehre, K. Cho,及 Y. Bengio.对序列建模方面的门控循环神经网络的实证研究.NIPS, 2014.
[4] H. Fang, S. Gupta, F. Iandola, R. K. Srivastava, L. Deng, P. Dollar, J. Gao, X. He, M.Mitchell, J. C. Platt,等人.从说明文字到视觉概念,再回到说明文字.In CVPR, 第1473-1482页, 2015.
[5] A. Farhadi, M. Hejrati, M. A. Sadeghi, P. Young,Rashtchian, J. Hockenmaier,及 D. Forsyth.每张图片都讲述了一个故事:根据图像生成语句.In CVPR,15-29, 2010.
[6] A. Frome, G. S. Corrado, J. Shlens, S. Bengio, J. Dean, T. Mikolov,等人.发明:深层视觉语义的嵌入模型.In NIPS,第 2121-2129页, 2013.
[7] M. Ghazvininejad, X. Shi, Y. Choi,及 K. Knight.生成主题诗歌.In NIPS, 1183,1191,2016.
[8] M. Ghazvininejad, X. Shi, J. Priyadarshi,及 K. Knight.Hafez:一个交互式诗歌生成系统.ACL,第 4348页, 2017.
[9] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu,Warde-Farley, S. Ozair, A. Courville,及Y. Ben- gio.生成对抗网络.In NIPS,第 2672-2680页, 2014.
[10] J. He, M. Zhou, 及 L. Jiang.使用统计机器翻译模型生成中国传统诗歌.In AAAI,2012.
[11] J. Hopkins与 D. Kiela.使用神经网络自动生成韵律诗.In ACL, 卷 1, 第 168-178页,2017.
[12] L. Jiang与 M. Zhou.使用统计机器翻译方法生成中国对联.In COLING, 第 377-384页, 2008.
[13] A. Karpathy, A. Joulin,及 F. F. F. Li.用于双向图像语句映射的深层片段嵌入.In NIPS,第 1889-1897页, 2014.
[14] R. Kiros, R. Salakhutdinov,及 R. S. Zemel.统一多模态神经语言模型的视觉语义嵌入.arXiv preprint arXiv:1411.2539, 2014.
[15] R. Kiros, Y. Zhu, R. R. Salakhutdinov, R. Zemel, R. Urtasun, A. Torralba,及 S.Fidler.Skip-thought向量.In NIPS,第 3294-3302页, 2015.
[16] J. Krause, J. Johnson, R. Krishna, 及 L. Fei-Fei.一种生成描述性图像短文的层次方法.CVPR, 2017.
[17] G. Kulkarni, V. Premraj, S. Dhar, S. Li, Y. Choi, A. C. Berg,及 T. L. Berg.牙牙学语:理解并生成图像描述.In CVPR, 2011.
[18] Y. Liu, J. Fu, T. Mei,及 C. W. Chen.让你的照片说话:通过双向注意递归神经网络来为照片流生成描述性段落.In AAAI, 2017.
[19] H. M. Manurung.韵律模式化文本的图表生成器.首届国际认知与计算机文学研讨会文集[32]第 15-19页, 1999.
[20] H. Oliveira.诗歌的自动生成:综述.Universidade de Coimbra, 2009.
[21] H. G. Oliveira.Poetryme: 诗歌生成的 多功能平台.创新计算、 [33] 概念创新,以及一般智能, 1:21, 2012.
[22] K. Papineni, S. Roukos, T. Ward,及 W.-J. Zhu.Bleu: 自动评价机器翻译的一种方法.InACL, 第 311-318页, 2002.
[23] C. C. Park 与 G. Kim.使用一系列自然语句表达一个图像流.In NIPS, 第 73-81页,2015.
[24] S. J. Rennie, E. Marcheret, Y. Mroueh, J. Ross,及 V. Goel.图像标题技术的自临界序列训练. arXivpreprint arXiv:1612.00563, 2016.
[25] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A.Khosla, M. Bernstein,等人.Imagenet 大规模视觉认知挑战.IJCV, 115(3):211- 252,2015.
[26] K. Simonyan与 A. Zisserman.大规模图像识别的甚深卷积神经网络. arXiv preprint arXiv:1409.1556, 2014.
[27] O. Vinyals, A. Toshev, S. Bengio, 及 D. Erhan.展示和辨别:一个神经图像文字说明生成器.In CVPR, 第 3156-3164页, 2015.
[28] J. Wang, J. Fu, Y. Xu,及 T. Mei.超远物品识别:使用深层耦合形容词及名词神经网络的视觉情感分析.In IJ- CAI, 第 3484-3490页, 2016.
[29] L. Wang, S. Guo, W. Huang,及 Y. Qiao.用于场景是别的 Places205-vggnet模型. arXiv preprint arXiv:1508.01667, 2015.
[30] R. J. Williams.简单统计梯度 - 用于连接增强式学习的跟踪算法.机器学习,8(3-4):229-256, 1992.
[31] Z. Xu, B. Liu, B. Wang, S. Chengjie, X. Wang, Z. Wang,及 C. Qi.通过有近似嵌入层的GAN产生神经相应.In EMNLP, 第 628-637页, 2017.
[32] R. Yan, H. Jiang, M. Lapata, S.-D. Lin, X. Lv, 及 X. Li. I, 诗歌:通过约束优化下生成归纳框架自动创作汉语诗歌.In IJCAI, 第 2197-2203页, 2013.
[33] X. Yi, R. Li,及 M. Sun.使用 rnn编码器-解码器生成中国古典诗歌.基于自然标注大数据的汉语计算语言学和自然语言处理,第 211-223页.Springer, 2017.
[34] Q. You, H. Jin, Z. Wang, C. Fang, 及 J. Luo.使用语义注意的图像标题技术.In CVPR,第 4651-4659页, 2016.
[35] L. Yu, W. Zhang, J. Wang,及 Y. Yu.SeqGAN:有策略梯度的序列生成对抗网络.In AAAI, 第 2852-2858页, 2017.
[36] W. Zaremba 与 I. Sutskever. 强 化 学 习 神 经图灵 机 - 修 订 . arXiv preprint arXiv.1505.00521, 2015.
[37] X. Zhang与 M. Lapata.使用递归神经网络生成中文诗歌.In EMNLP, 第 670-680页, 2014.
论文地址:https://dl.acm.org/authorize?N660819
雷锋网 AI 科技评论报道
全球AI+智适应教育峰会
免费门票开放申请!
雷锋网联合乂学教育松鼠AI以及IEEE教育工程和自适应教育标准工作组,于11月15日在北京嘉里中心举办全球AI+智适应教育峰会。美国三院院士、机器学习泰斗Michael Jordan、机器学习之父Tom Mitchell已确认出席,带你揭秘AI智适应教育的现在和未来。
扫码免费注册