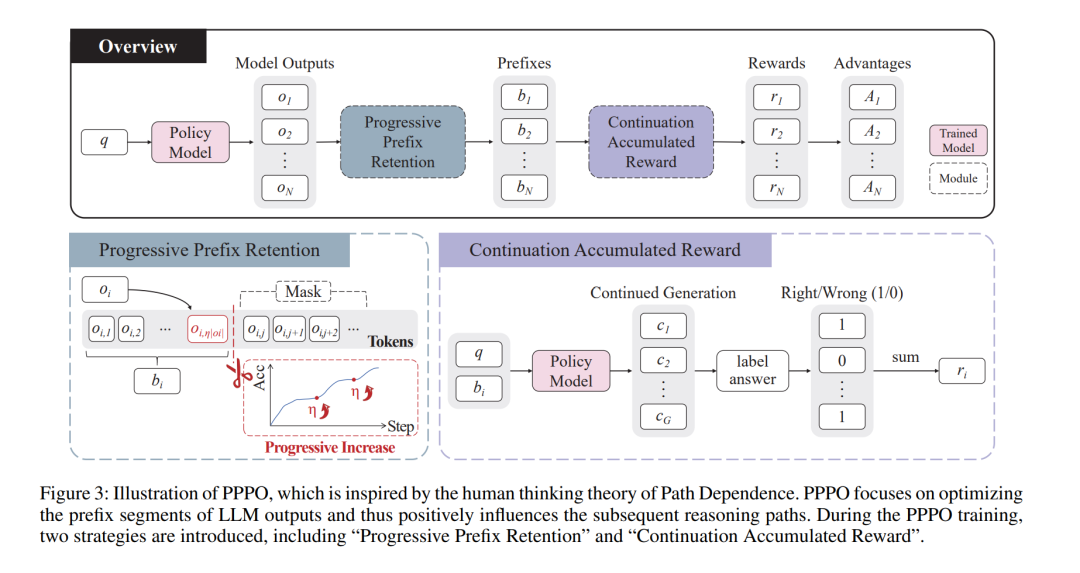
基于可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards,RLVR)能够显著提升大语言模型(Large Language Models,LLMs)的推理能力。现有的 RLVR 方法通常对模型生成的所有 token进行统一训练,但并未深入探究究竟哪些 token(例如前缀 token)对推理过程起到了关键作用。这种一视同仁的训练策略在低回报 token 上投入了大量优化资源,不仅削弱了高回报 token 所能带来的潜在性能提升,也降低了整体训练效率。 为解决这一问题,本文提出了一种新的 RLVR 方法——渐进式前缀 token 策略优化(Progressive Prefix-token Policy Optimization,PPPO),强调生成结果中前缀部分在推理过程中的重要性。具体而言,受人类思维中广泛认可的路径依赖(Path Dependence)理论启发——该理论指出早期阶段的思考会对后续思维轨迹形成强约束——我们在 LLM 推理过程中识别出一种类似现象,并将其命名为起始锁定效应(Beginning Lock-in Effect,BLE)。该效应表明,推理初期的生成内容会显著影响后续推理的发展方向。 PPPO 正是基于这一发现,将优化目标聚焦于 LLM 的前缀推理过程。这种针对性的优化策略能够对后续推理阶段产生积极影响,从而提升最终的推理结果。为了增强 LLM 学习“如何高质量地开始推理”的能力,PPPO 引入了两种关键训练策略:(a)渐进式前缀保留(Progressive Prefix Retention),通过在训练过程中逐步提高被保留前缀 token 的比例,构建一种渐进式的学习机制;(b)延续累积奖励(Continuation Accumulated Reward),针对同一前缀 token 序列采样多个不同的生成延续,并将其得分进行累积作为奖励信号,从而有效缓解奖励偏置问题。 在涵盖数学、物理、化学和生物等多种推理任务