

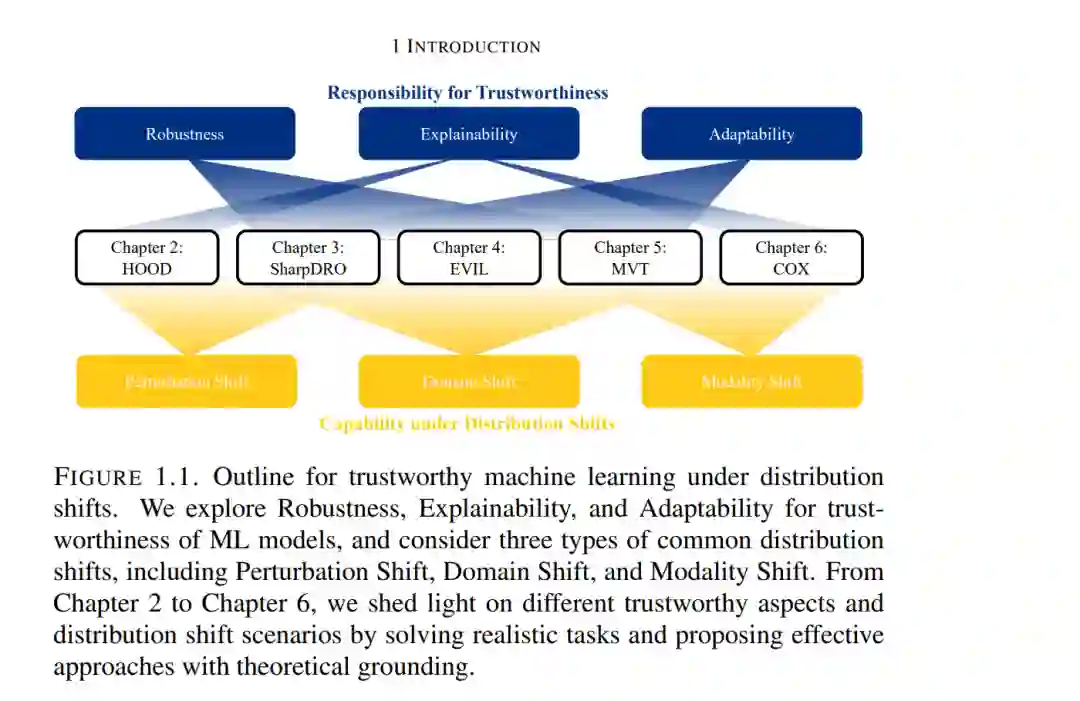
机器学习(ML)作为人工智能(AI)的基础课题,为其令人振奋的进展提供了理论基石与实践工具。从用于视觉识别的 ResNet 到实现视觉-语言对齐的 Transformer,AI 模型已展现出超越人类的卓越能力。此外,扩展定律(Scaling Law)使 AI 初步具备了通用智能,大语言模型(LLMs)便是其有力证明。至此,AI 已对社会产生巨大影响,并持续塑造人类的未来。 然而,分布偏移(Distribution Shift)始终是机器学习系统的“阿喀勒斯之踵”,从根本上限制了其可靠性与普适价值。随着 AI 深度融入现实世界的决策流程与社会基础设施,我们要求其解决的问题复杂度也在不断增加。这些复杂环境自然会引入多样且不可预测的分布偏移,从而导致模型性能严重下降。 此外,分布偏移下的泛化能力缺失也会引发 AI 的信任危机。例如,当跨地区部署医疗 AI 时,其表现可能差强人意甚至造成危害。因此,我们亦需关注 AI 的责任属性,即机器学习的可信度(Trustworthiness),旨在提升系统的可靠性而非仅仅关注准确率。 受此启发,我的研究聚焦于分布偏移下的可信机器学习,目标是扩展 AI 的鲁棒性、通用性、责任感与可靠性。我们深入研究了三种常见的分布偏移:(1) 扰动偏移(Perturbation Shift)、(2) 领域偏移(Domain Shift) 以及 (3) 模态偏移(Modality Shift)。针对所有场景,我们从 (1) 鲁棒性、(2) 可解释性 和 (3) 自适应性 三个维度对可信度进行了严谨调查。基于这些维度,我们提出了有效的解决方案与基础性见解,旨在强化效率、自适应性及安全性等关键机器学习问题。
成为VIP会员查看完整内容
