
现代空天防御系统日益依赖自主决策来协调大量拦截弹应对多重来袭威胁。传统武器目标分配(WTA)算法(包括混合整数规划与基于拍卖的方法)在需要类人推理与自适应优先级排序的动态不确定战术环境中显现局限性。本文提出一种大语言模型(LLM)驱动的WTA框架,将广义智能集成到协同导弹制导中。该体系将战术决策过程构建为推理问题,其中LLM评估拦截弹、目标与防御资产间的时空关系以生成实时分配方案。与经典优化方法不同,该方法利用威胁方向、资产优先级和接近速度等上下文任务数据动态调整并减少分配切换。专用仿真环境支持静态与动态两种分配模式。结果证明了其在一致性、适应性与任务级优先级排序方面的改进,为将广义人工智能集成到战术制导系统奠定基础。
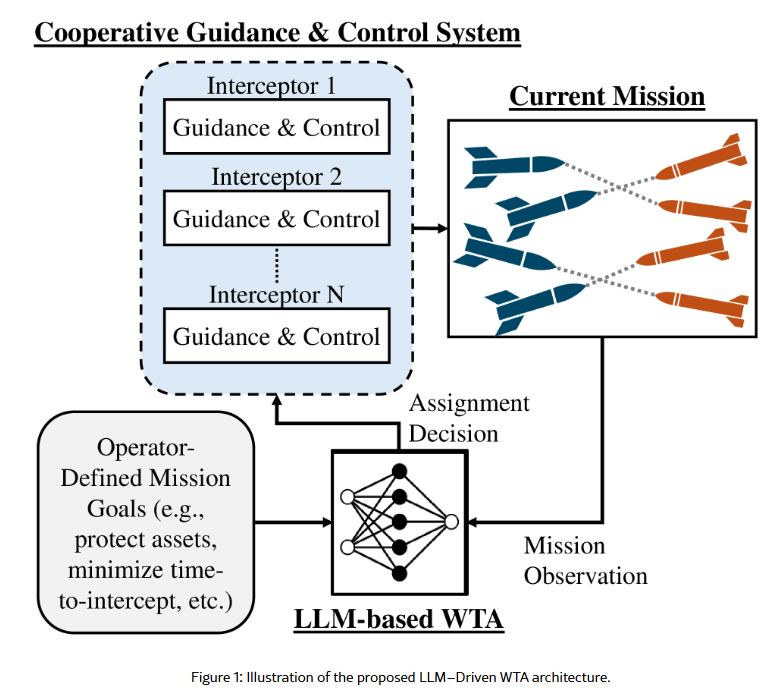
随着先进导弹技术、蜂群战术与欺骗策略的发展,现代军事交战日益复杂,使得防御资产的高效分配成为空天作战的关键挑战[Li2024]。武器目标分配(WTA)问题旨在作战、几何与时间约束下将一组拦截弹分配给一组来袭威胁以最大化任务效能。该问题最初被表述为组合优化问题[manne1958wta],后被确认为NP完全问题[Lloyd1986],导致针对静态与动态场景的精确、启发式与元启发式算法研究历史悠久[Li2024, bertsekas1988auction, pentico2007assignment]。在真实任务环境中,由于分配与制导的耦合、目标运动的不确定性以及时间紧迫的决策需求,该问题变得更具挑战性。
经典表述通常将分配与轨迹优化阶段解耦并顺序求解以保持可处理性。然此简化常限制最优性与态势适应性。近期研究引入集成优化框架,将目标分配与轨迹规划统一于单一决策过程[Jin2025]。通过将分配决策嵌入连续优化例程,这些方法共同考量几何、时序与动态可行性,展示了对交战问题分层协同推理的优势。
与优化进展并行,近期研究探索使用数据驱动与机器学习(ML)技术提升WTA适应性[Li2024]。强化学习与基于图的架构在动态分配中展现潜力,但其对大规模训练数据的依赖与有限可解释性限制了在安全关键任务中的部署[shokoohi2022rl]。这些局限推动了对融合算法精度与上下文理解及可解释性的混合推理系统的探索。
大语言模型(LLM)近年作为新型推理系统涌现,在自主决策中具应用潜力。基于大规模多模态数据预训练的LLM可联合处理数值与符号输入,使其无需显式成本函数定义即能执行高层推理与任务分解[Pallagani2024]。将其集成到控制与规划管道中为任务级决策支持开辟新途径,尤其在符号知识与数值优化相交领域。值得注意的是,近期研究表明LLM可直接嵌入机器人反馈环路以增强韧性与适应性[Tagliabue2023]。该工作中,LLM参与任务规划、状态解读与控制调整,即使在未建模动态下也能减少误差并防止不安全行为。此证据表明LLM可通过在传统模型受限处提供上下文推理来补充算法决策。
受此进展启发,本研究探索基于LLM的推理在动态武器目标分配与协同导弹制导中的应用。所提框架将分配生成视为上下文推理任务,其中LLM解读全局任务状态(包括几何、时序与优先级指标)并输出可行拦截弹-目标分配方案而无需预定义权重参数。通过将基于LLM的决策支持集成到分配-制导环路中,该方法保留经典制导律结构的同时利用LLM对动态任务上下文推理的能力。最终系统旨在弥合数值优化与人类级推理间的差距,为不确定条件下的多拦截弹协同提供可解释、自适应与情境感知的解决方案。

