
在模拟训练中达成专家级表现有赖于创建复杂、适应性强的场景——这一过程传统上费力且资源密集。虽然先前研究探索过军事训练的场景生成,但前大型语言模型时代的人工智能工具难以生成足够复杂或适应性强的场景。本文介绍了一种多智能体、多模态推理框架,该框架利用大语言模型生成关键训练产物,如作战命令(OPORD)。方法使用人工智能自动化和增强场景生成任务,显著减少人工工作量并加速开发。通过将场景生成分解为层次化的子问题来构建框架,并针对每个子问题定义人工智能工具的角色:(1)生成选项供人工作者选择;(2)产出候选产物供人工批准或修改;或(3)全自动生成文本产物。框架采用基于大语言模型的专用智能体处理不同子问题。每个智能体接收来自前置子问题智能体的输入——整合基于文本的场景细节和视觉信息(例如地图特征、部队位置)——并应用专门推理产生相应输出。后续智能体依次处理这些输出,保持逻辑一致性并确保准确的文件生成。在处理此类高度复杂任务时,这种多智能体策略克服了基础提示或单智能体方法的局限性。通过概念验证来验证框架,该验证生成作战命令的机动与移动方案部分,并预先估算地图位置与移动——证明了其可行性和准确性。结果展示了大语言模型驱动的多智能体系统生成连贯、细致入微的文件并能动态适应变化条件的潜力——推进了军事训练场景生成的自动化进程。
通过刻意练习达成专业技能掌握的过程受到构建真实训练场景的复杂性和成本阻碍。创建高保真的实兵、虚拟和构造性场景成本高昂且需要专门知识,限制了其数量和多样性。这对于像陆军“综合训练环境”(STE)这样旨在拓宽士兵体验式学习的努力尤为相关:使这些场景适应新地形、天气和假想敌目标的需求进一步加剧了该问题。早期研究探索了自动化场景生成,但以往的人工智能(AI)和机器学习(ML)工具无法产出既复杂又适应性强的场景。有些系统仅改变少数通过强化学习优化的参数(Rowe等人,2018),而其他系统则将认知任务分析模型与新奇性搜索相结合(Dargue等人,2019;Folsom-Kovarik等人,2019)。这些方法难以迁移到新情境并达到高级训练所要求的真实感。当前的大语言模型(LLM)预示着重大进展。通过利用深厚的数据集——包括历史作战、当前地缘政治背景和条令出版物——大语言模型能够创建动态适应变化约束的条件、情境丰富的场景。军方正在积极探索此潜力(Caballero等人,2024)。提出的益处包括通过生成反映场景内事件的模拟社交媒体信息流来增加虚拟训练环境的真实感,以及创建增强的“生活模式”实体(Hill,2024)。
然而,用单一大型语言模型替换完整的场景创作流程并不能真实反映那些为训练特定能力而设计、需要协作、角色专业化和评审的过程。因此,提出一种多智能体推理方法,将认知负荷分布到专门的大型语言模型智能体上,从而有效支持场景开发者,建立一种人机场景协同生成框架。该方法效仿了有效的人类团队合作(即智能体专注于特定任务,并通过组织结构引导信息共享),以在高维问题空间中保持连贯性,并克服单智能体提示的扩展限制。
为构建基于大型语言模型的场景生成多智能体推理框架,团队分析了陆军大学专家为大规模训练演习构建场景所采用的过程。该分析导致将场景生成过程分解为层次化的子问题,这将在“子问题层次结构”部分进一步讨论。此外,针对此层次结构中的每个子问题,定义了所提出框架将承担的角色:(1)生成选项供人工作者选择;(2)产出候选产物供人工批准或修改;或(3)全自动生成文本产物。此方法已应用于陆军大学“太平洋盾牌”场景中的“太平洋拳击手”训练,并展示了框架在“太平洋拳击手”样本子问题中的有效性。
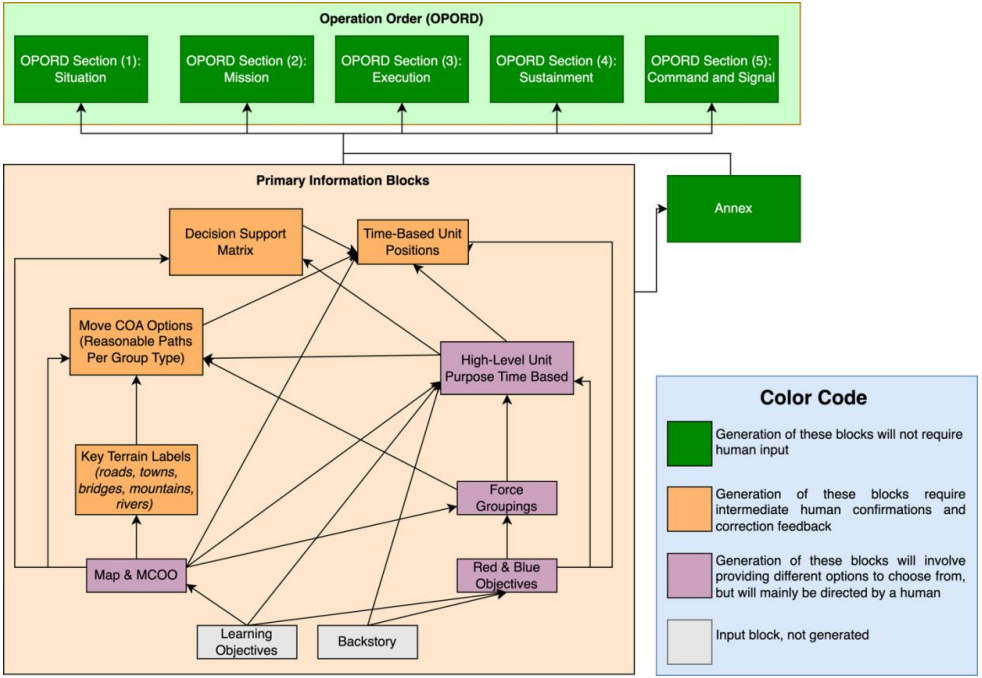
图1. 信息流图,展示了如何将学习目标和背景故事逐步扩展为有助于开发场景其余部分的概念的构建模块

