

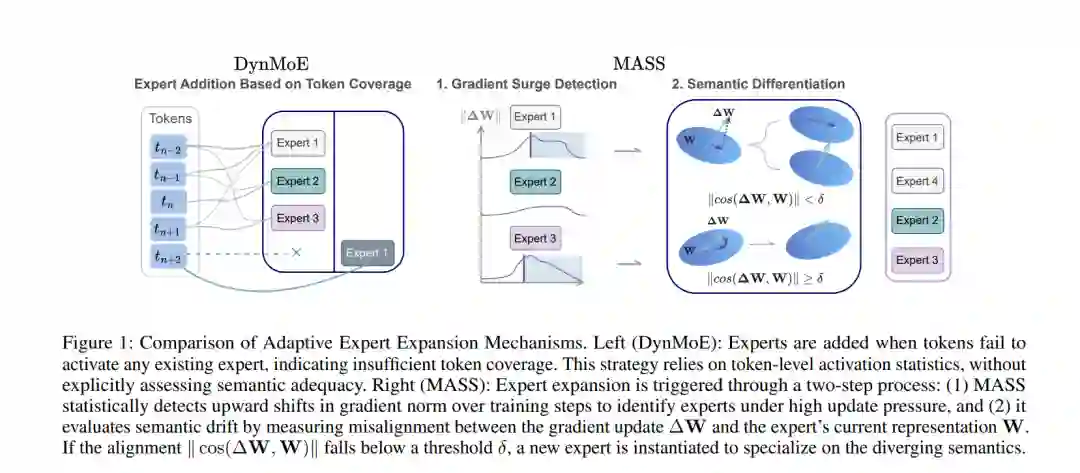
寻找能够最大化专家间语义差异化(semantic differentiation)的稀疏混合专家(SMoE)最优配置,对于充分挖掘混合专家架构的潜力至关重要。然而,现有SMoE框架要么严重依赖超参数调优,要么在调整专家池规模时忽视了专家间语义角色多样化的必要性。本文提出面向自适应语义专业化的混合专家模型(Mixture-of-Experts for Adaptive Semantic Specialization, MASS),这是一个具备语义感知能力的MoE框架,支持自适应专家扩展与动态路由。MASS引入两项关键创新:(i) 一种基于梯度的语义漂移检测器,当现有专家池无法充分捕捉数据的完整语义多样性时,该检测器会触发针对性的专家扩展;(ii) 一种自适应路由策略,能够基于令牌级路由置信度分布动态调整专家使用情况。我们首先在高度可控的合成环境中证明,MASS能够可靠地收敛至成本-性能权衡的最优平衡点,同时显著提升语义专业化能力。在语言和视觉领域真实数据集上的进一步实证结果表明,MASS持续优于多种强基线MoE模型,展现出其领域适应鲁棒性与增强的专家专业化能力。
成为VIP会员查看完整内容
